






全称:byte latent transformer
0.写在前面
· FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
· FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
· 之前的大语言模型(如Llama、GPT等)主要基于token-level的处理方式,依赖于固定的词汇表。
1.简介
是一个无token化的架构,和基于token的模型表现相当,但是更优化了推理成本、效率和鲁棒性。
具体的,BLT动态地学习如何将byte分组为一个长度不固定的小片段,比BPE分词更优化了计算内存的分配。即,一个patch能表示越多的byte,就能将更多计算资源分配到transformer中,增加size。
简易的模型架构:
lightweight local encoder(from bytes to patches) + big gobal latent transformer(get patch representations and predict next patch) + lightweight local decoder(from patch repres to bytes)
2.Patching
patch size 决定 latent transformer中的计算成本,所以本文的核心就是介绍patching function。
· entorpy patching:
训练了小的自回归语言模型(详见后面Entropy Model),通过计算下一个byte的熵,得到划分每个patch的边界。在dataloading阶段就执行了这一patch boundary的求解。
3.BLT架构
· big gobal latent transformer,称作G
作用:maps input patch repre into output patch repre. 即,对patch进行上下文的emb优化并做下步预测。
这部分消耗了大部分的FLOPs,因此要选择在合适的时间去调用这个模块。
通过Entropy Model识别高信息量区域,仅在必要时调用全局大模型,低熵区域使用轻量级本地模型。
输入:来自编码器的动态patch序列(每个patch长度可变,平均4-8字节)。
输出:更新后的patch潜在表示,传递给解码器生成具体字节。
· local encoder,lightweight trans-based
作用:高效 maps input bytes into expressive patch repre.
新增了cross attention和hash-embedding
· hash n-gram embedding
可以增强鲁棒性,将每一位bytes repre(Xi)结合之前的bytes信息。通过hash函数,将每个byte的n-gram(n=3~8)信息求和然后映射到一个index数字
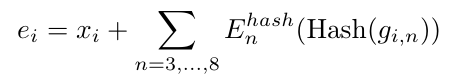 ,再与原来的位置的emb求和,得到增强后的bytes emb(Ei)。
,再与原来的位置的emb求和,得到增强后的bytes emb(Ei)。
· 多头交叉注意力
初始化查询向量:通过池化聚合patch内的bytes repres,线性投影为一个初始化的patch query。(just 来源于bytes emb)
仅允许每个patch query关注对应patch内bytes的KV,使用层归一化和残差连接,没使用PE。
最终生成动态长度的patch表示序列P,输入到全局Latent Transformer进行处理。
即,Q是patch repre,init from pooling bytes,而这个bytes还经过了hash的上下文增强。KV是byte repre。
· local decoder,lightweight trans-based
作用:和encoder相反
初始字节表示来自编码器最后一层的输出。
字节表示作为查询,全局patch表示作为键值。使用多头机制和残差连接。
生成更新后的字节表示。最后一层输出通过线性投影到256维字节空间,使用交叉熵损失进行训练。
4.实验设计
对比BLT和基于token的模型。
· 预训练数据
分为1、用于探索BLT的scaling law。2、用于和Llama3做下游任务的比较。
· Entropy Model
是动态划分字节序列为patch的核心机制。
熵的定义:衡量"预测下一个字节的难度",熵值越高表示预测越不确定,即uncertainty(信息量越大)。
核心逻辑:
* 高熵区域(如句首、生僻词):划分更细的patch → 调用大模型(Global Transformer)深度计算。
* 低熵区域(如单词后缀、重复模式):合并为长patch → 轻量处理(Local Models),节省计算量。
实现方式:
1. 单独训练一个小型字节级LM(100M参数,14层Transformer)预测每个位置的下一个字节分布。独立优化(不参与端到端训练)
2. 计算熵
3. 动态分割:通过阈值或相对变化检测熵突增点作为patch边界。
method1:全局熵阈值,当H(xi)>θg时标记为分块边界。
method2:近似单调性约束,当H(xi)−H(xi−1)>θr时标记为边界。
· 针对repetitive数据,修正了entropy的计算方式,防止因为熵过于小,而使用非常大的patch。
· FLOPs的计算方式
假设了在最初input byte embedding是O(1)复杂度的查表操作。并估计反向传播参数是正向传播参数的两倍。
最终,FLOPs=两个local+一个global+两个local中的cross attention。
· BPB计算方式
将x的交叉熵损失除以x的字节长度和常数ln2,进行正则化。
· transformer架构
同llama3,swiglu,rope,rmsnorm,self att使用了flash att,cross att使用了Flex att。
5.scaling trends
· BLT的scaling law
主要讲了,BLT和BPE-based的Llama模型在compute optimal regime的表现,即探索FLOPs和model size、data size、parameter size的关系?
最终结论是,FLOPs和patch size成反比。即,ps越大,模型计算量越小,因此可以将省下的计算量用于增大model size和data size,从而使模型表现提升。
· BLT的下游任务表现对比
主要体现了:在相同的硬件条件进行训练(即FLOPs),BLT能通过动态计算ps,更好利用资源。且,byte level的信息更优于token信息。
总结就是:验证了BLT架构的核心优势——通过动态分块节省计算资源,将节省的FLOPs重新分配到更大的模型容量。
6.证明了byte建模具有的强健性
7.消融实验
证明了BLT中所有的超参数和模型架构的选择都是正确的。
8.其他工作
讲述了字符级的RNN和transfomer的模型。
9.未来工作
有一个比较有趣:能否将entropy model 加入到全局中进行训练。
10.总结
· 流程
字节级(编码器,hash+n-gram局部增强)→ Patch语义(根据熵值动态分割,送入全局模型)→ 字节级(解码器)。
· 传统范式
Byte→Tokenizer→Token embeddings→Transformer→Byte
· BLT范式
Byte→encoder→Dynamic Patches→Latent Space→new and predict Patches+→decoder→Byte
· 熵驱动计算:
* 基于香农信息论,将计算资源分配给高熵(不确定性)区域。以微小的验证损失,换取至多50%的计算量减少。
* 公式化表达:
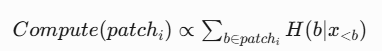
· 硬件友好性:
* 通过动态patch减少矩阵计算中的padding浪费。
* 利用FlashAttention加速patch序列的注意力计算。
11.问题
· 既然没有固定词汇表,那么最终CE做分类损失的时候,怎么知道总类数?
· 为什么decoder的 patch CA里面,Q和KV长度不一样。按道理global的输出应该多一个。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









