






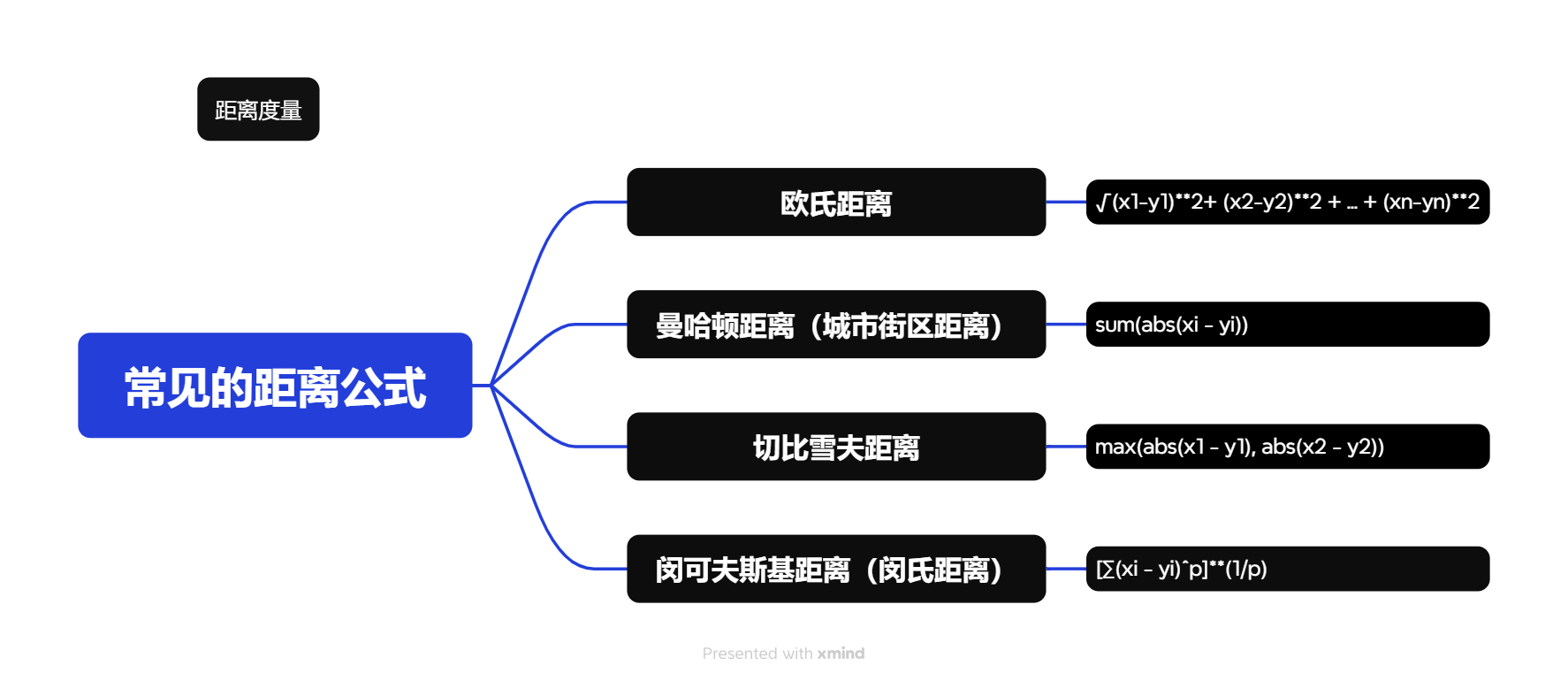
几种常见的距离公式
鸢尾花案例
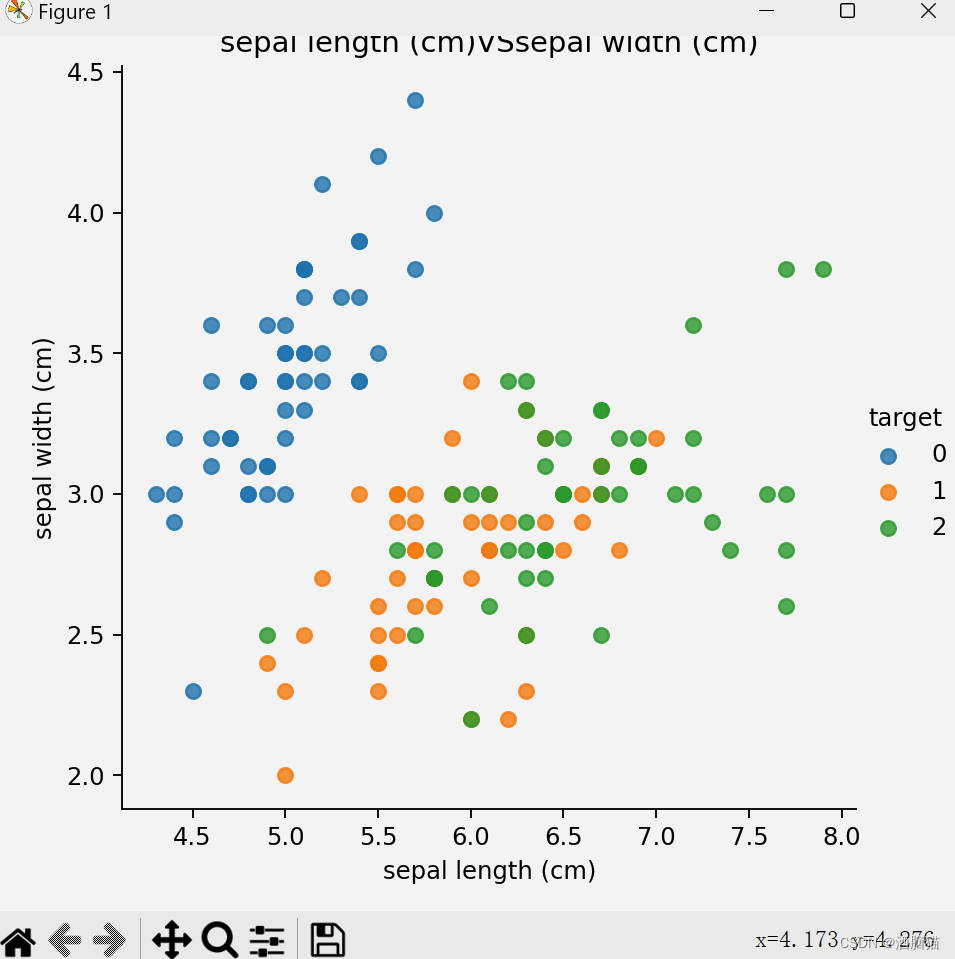
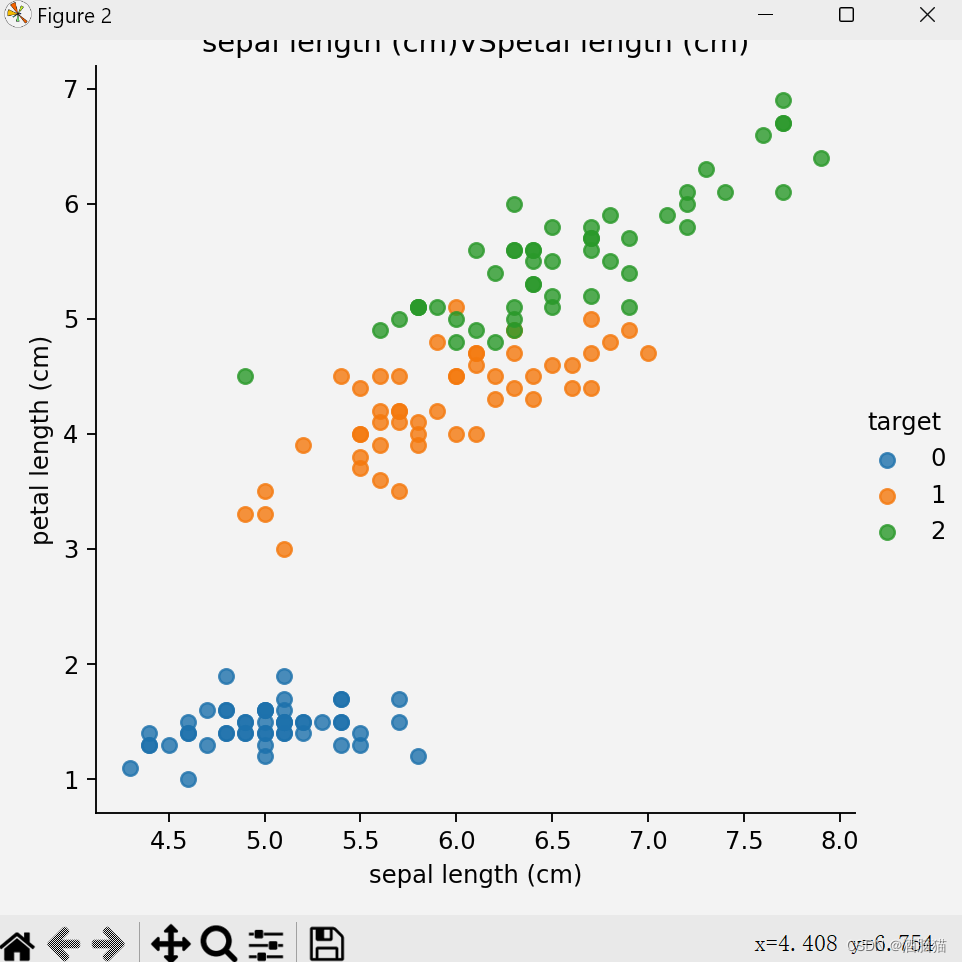
from sklearn.datasets import load_iris##导入鸢尾花的sk-learn内置数据包 import matplotlib.pyplot as plt import seaborn as sns import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier ##加载数据集 iris_data = load_iris() ##数据展示 def shujuzhanshi(): iris_df = pd.DataFrame(iris_data['data'],columns=iris_data.feature_names) print(iris_df) iris_df['target'] = iris_data.target print(iris_df) feature_names = list(iris_data['feature_names']) print(feature_names) for i in range(len(feature_names)): for j in range(i + 1,len(feature_names)): cc1 = feature_names[i] cc2 = feature_names[j] sns.lmplot(x=cc1,y=cc2,hue='target',data=iris_df,fit_reg=False) plt.xlabel(cc1) plt.ylabel(cc2) plt.title(f'{cc1}VS{cc2}') plt.show() ##数据基本处理,数据基本划分 x_train,x_text,y_train,y_text = train_test_split(iris_data.data,iris_data.target,test_size=0.3,random_state=32) ##特征化处理,数据标准化 mydata = StandardScaler() x_train = mydata.fit_transform(x_train) x_text = mydata.fit_transform(x_text) ##实例化 model = KNeighborsClassifier(n_neighbors=4) ##模型训练 model.fit(x_train,y_train) ##评估 score=model.score(x_train,y_train) ##预测 ce_data = [[5, 3, 1.5, 3.2], [6.3, 5, 3.5, 3]] ce_data = mydata.fit_transform(ce_data) predata = model.predict(ce_data) print(f'predate-->\n{predata}') shujuzhanshi()步骤及理解
1.加载数据集
2.数据展示
3.特征处理
这里用的是标准化,在此之前先进行了数据集划分(测试集,训练集)
4.实例化
这里的4是超参数
model = KNeighborsClassifier(n_neighbors=4)5.模型训练
model.fit(x_train,y_train)6.模型评估
score=model.score(x_train,y_train)##这是第一种 ##第二种 from sklearn.metrics import accuracy_score y_pre = model.predict(x_test) score = accuracy_score(y_test,y_pre) ##第二种的原理是:将测试集中的x_test放入模型中预测y值,与对应的y_test进行比较算出正确率 ##结果 ## 0.95238095238095237.预测
predate-->
[1 1]
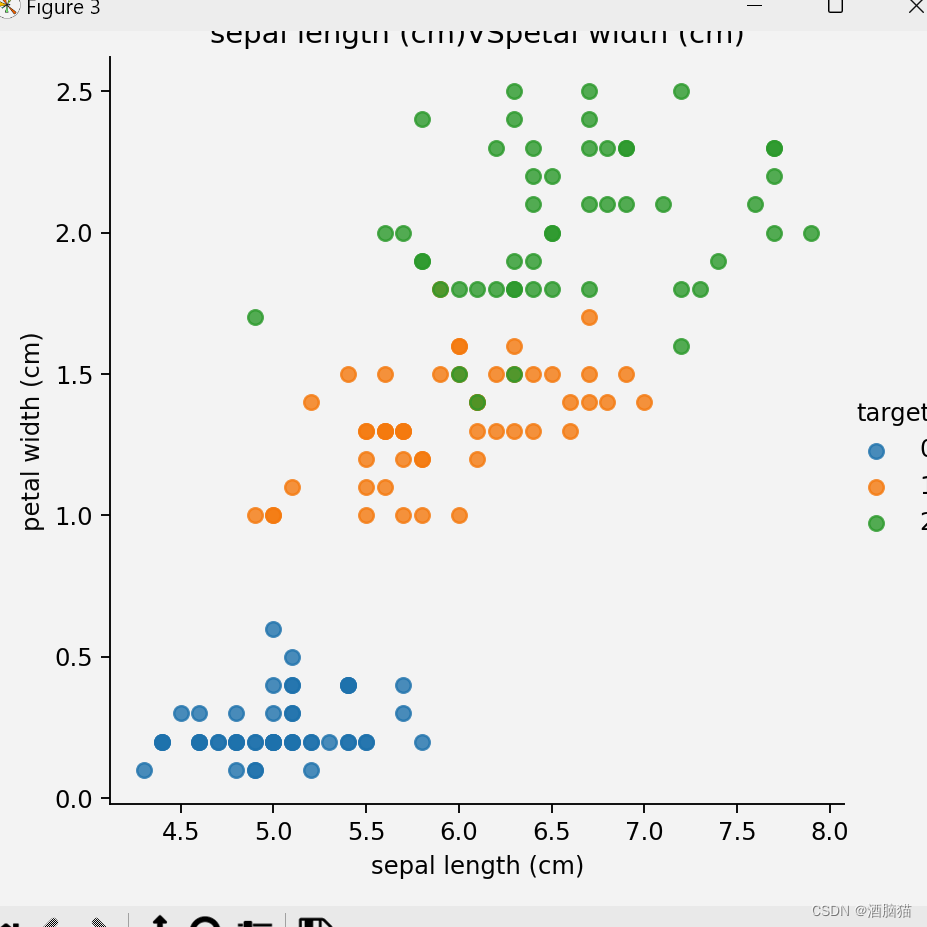
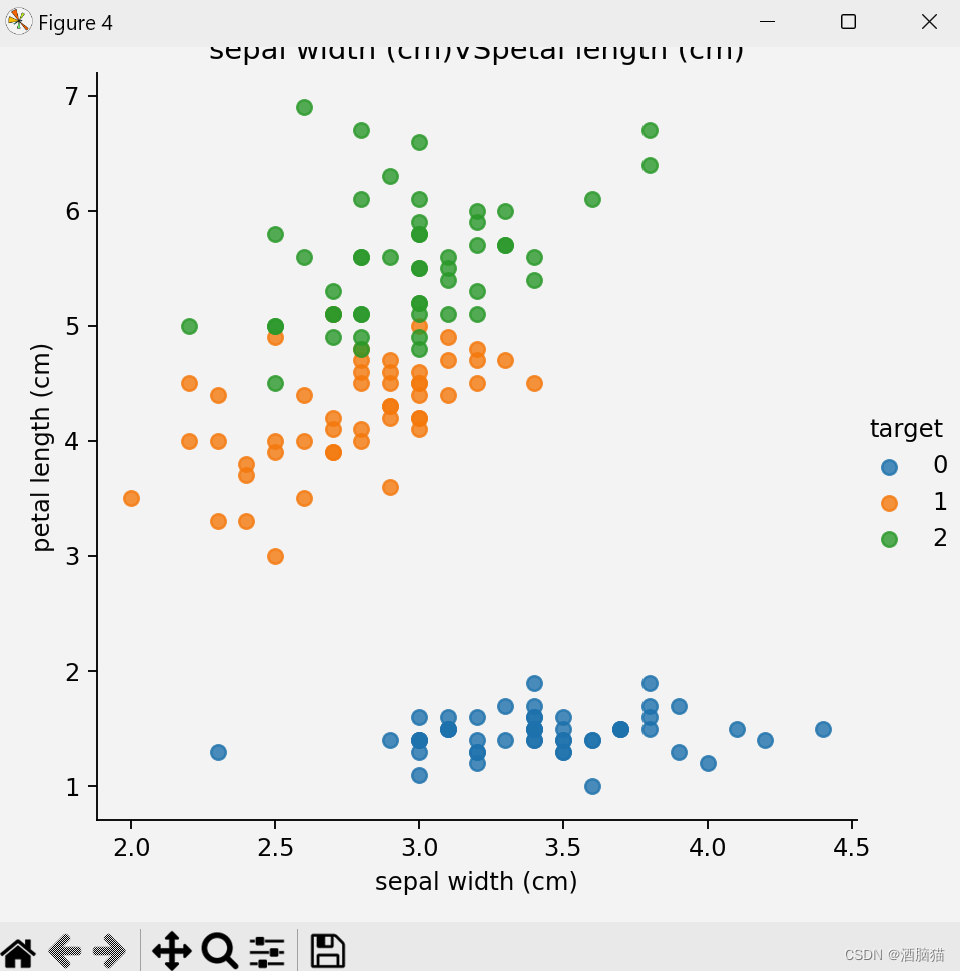
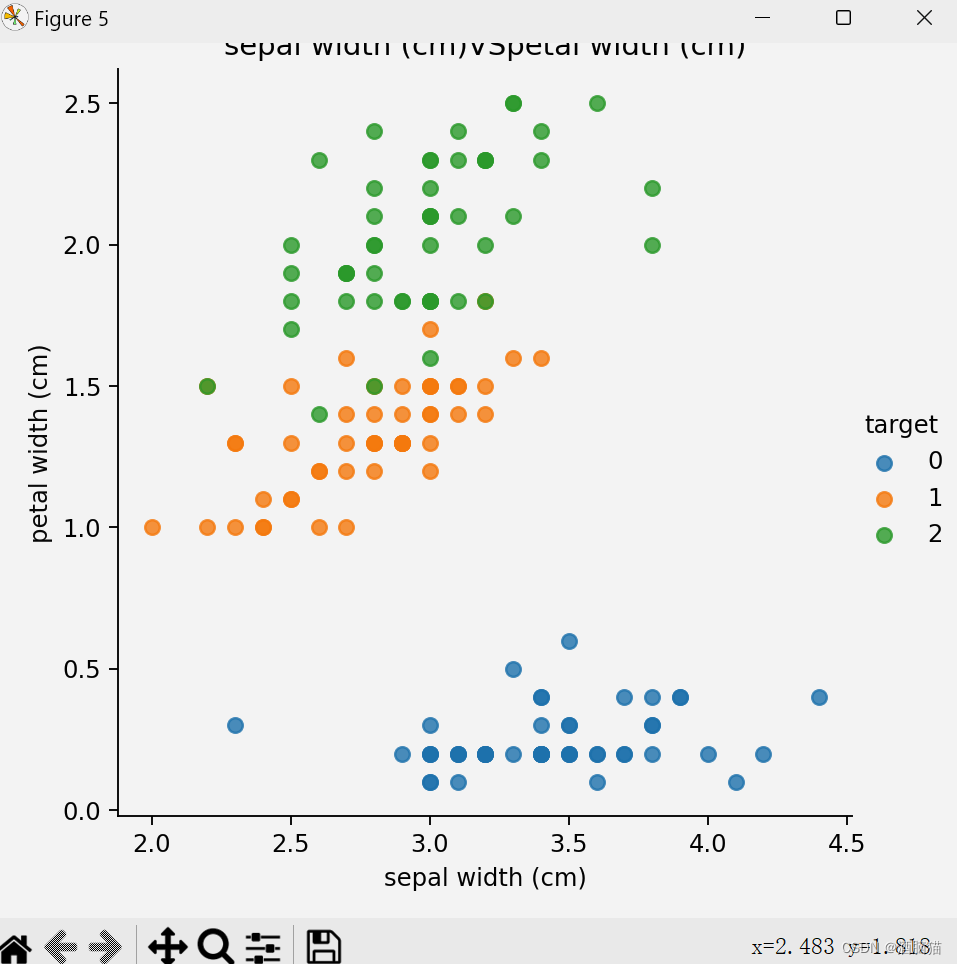
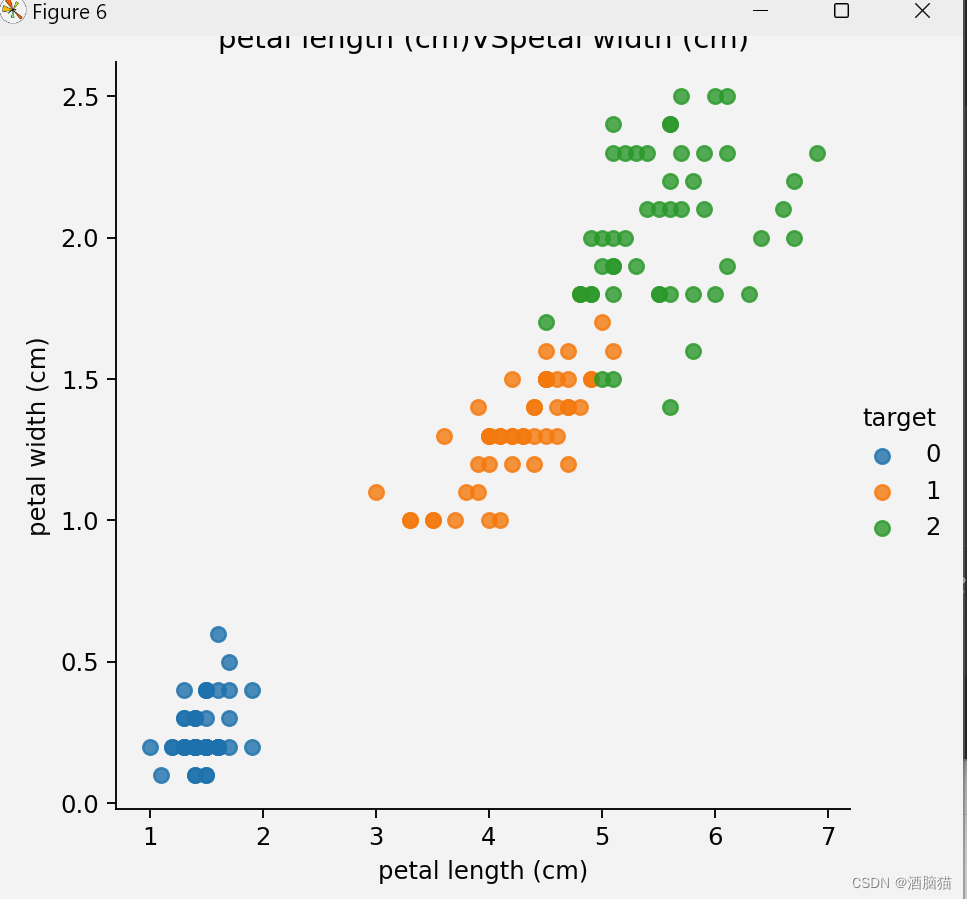
特征处理之标准化和归一化
标准化
正态分布
归一化
将各个特征最小值min设为0,最大值max设为1,将[0,1]区间等分为max-min份,其中某个特征归一化后为x(gui) = (x-min)/(max-min)
代码
from sklearn.preprocessing import MinMaxScaler##数据归一化 from sklearn.preprocessing import StandardScaler##数据标准化 def shuju_guiyi(): data = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]] x = MinMaxScaler() data = x.fit_transform(data) print(data) def shuju_biaozhunhua(): data = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]] x = StandardScaler() data = x.fit_transform(data)















 2664
2664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









