







 本文介绍了Q-learning算法的基本概念,通过具体步骤解释如何利用奖励矩阵进行迭代计算,以确定最优路径。算法从初始化的Q-table开始,通过多次尝试和更新,最终实现状态决策的优化。
本文介绍了Q-learning算法的基本概念,通过具体步骤解释如何利用奖励矩阵进行迭代计算,以确定最优路径。算法从初始化的Q-table开始,通过多次尝试和更新,最终实现状态决策的优化。
Q-learning
引入
给出下面的一个空间:
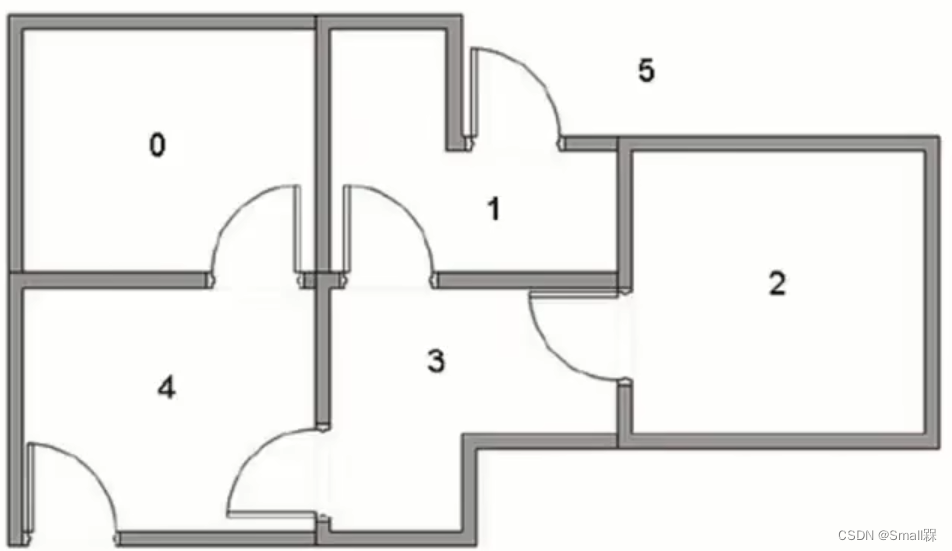
现在我需要从其中的一个房间走到房子外面(也可以说是房间5),每个房间都可以抽象成一个状态。
由此,可以把这个房子抽象成下列的一个图形结构,:
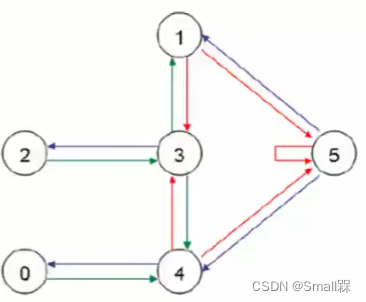
每个结点都表示一个状态,我如果在5状态就表示游戏结束。
那么我该如何才能让计算机走到状态5呢?那必然少不了奖励值的设定了。
能够到达5状态的奖励值设置设置得高,不能到达状态5的奖励值设置得低。如下:
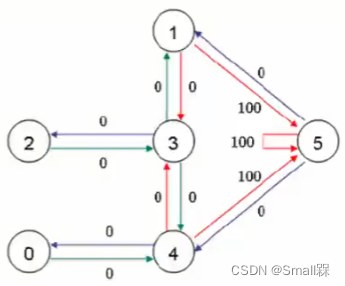
由此我们就可以将奖励值设置成一个reward矩阵。

迭代计算的具体步骤

如果我从状态3能够到达状态1和状态4,那我该走到哪个状态呢?
这就需要开始计算,首先R(s,a)是一个即时奖励,γ是折扣系数。我要选取一个能够达到的状态作为下一个状态,然后计算它的Q值,算完以后选取他们之中最大的一个值(最好的方向)然后乘上γ再加上即时奖励R。
图中每一行代表状态state,每一列代表一个行为action。
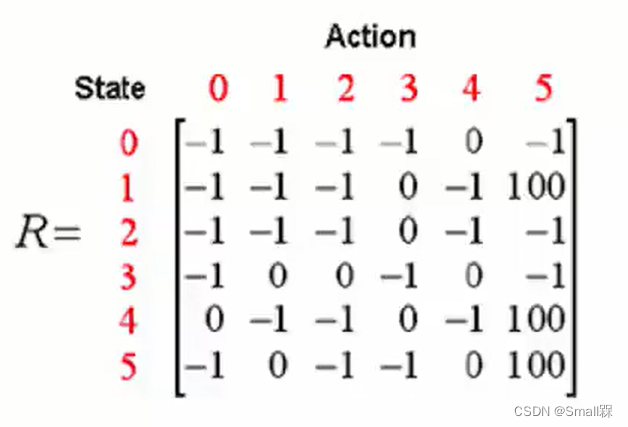
这是抽象出来的Reward矩阵,值为-1则代表无法在某个state做出某个action,0则代表可以,而100则代表游戏结束。

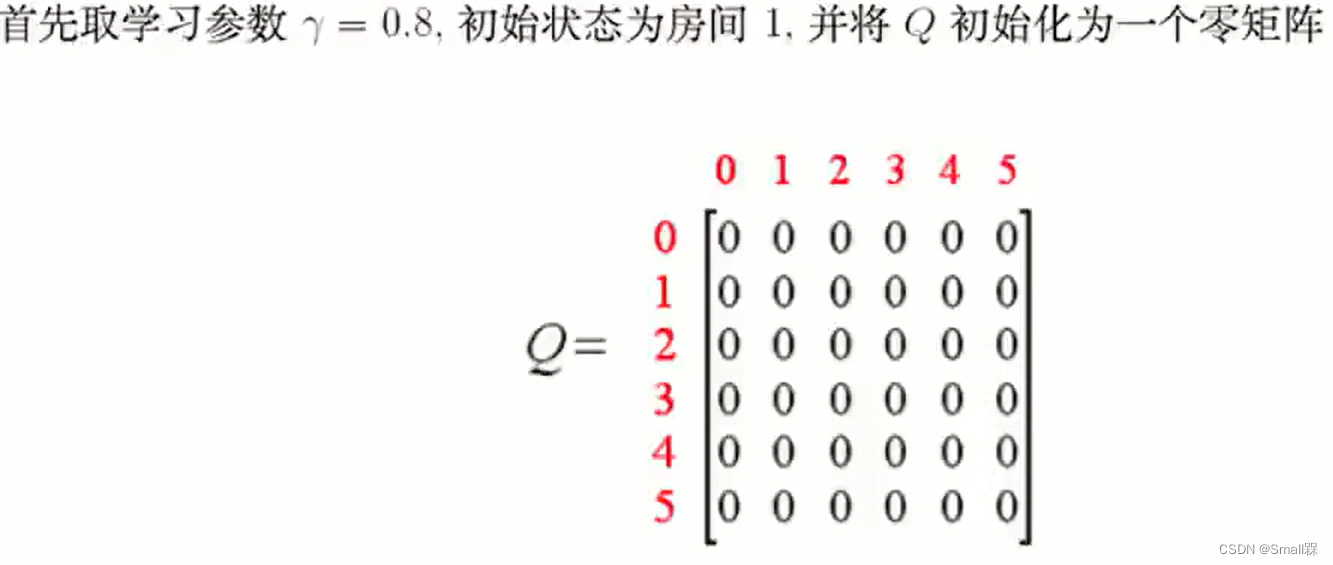
第一次迭代的时候,Q-table的值都是0,那么就可以对其进行更新,更新流程参考上述公式。
当然,只迭代一次是不够的,我们需要随机选择初始状态,然后进行多次尝试。

现在状态1是当前状态,但不是目标状态,需要继续探索并更新Q-table。。。。
如果我们执行更多的episode,矩阵Q最终就会收敛成以下形式:

现在数值看上去有些大,我们可以将它们进行归一化的操作。意思就是选择最大值500,让所有的数值都除以500并转化为百分号的形式。如下: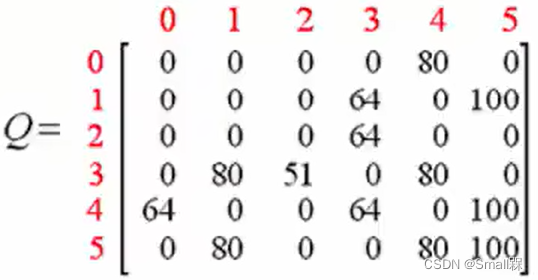
然后将数值标注在图上(这是为了为了更直观的展示)
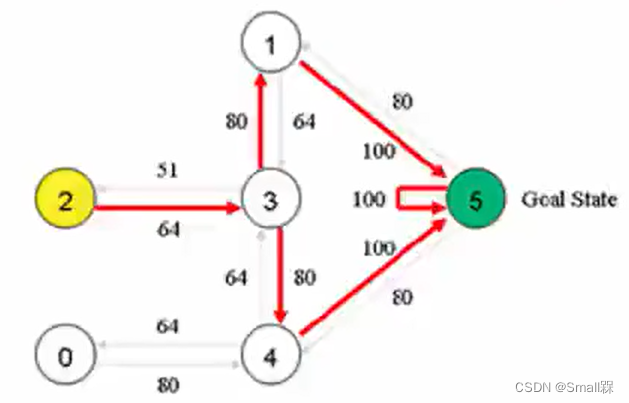
如此计算机就可以开始进行决策。如初始点选择2位置,由2进入到3位置,状态3进入1和4都是80,随机进入一个,假设进入4位置,在4位置挑选最大值100进入5,游戏结束。
总结
以上是我对Q–learning算法的理解,欢迎交流学习。















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









