






人工智能基础知识及发展史
1.人工智能三大概念
人工智能(AI)
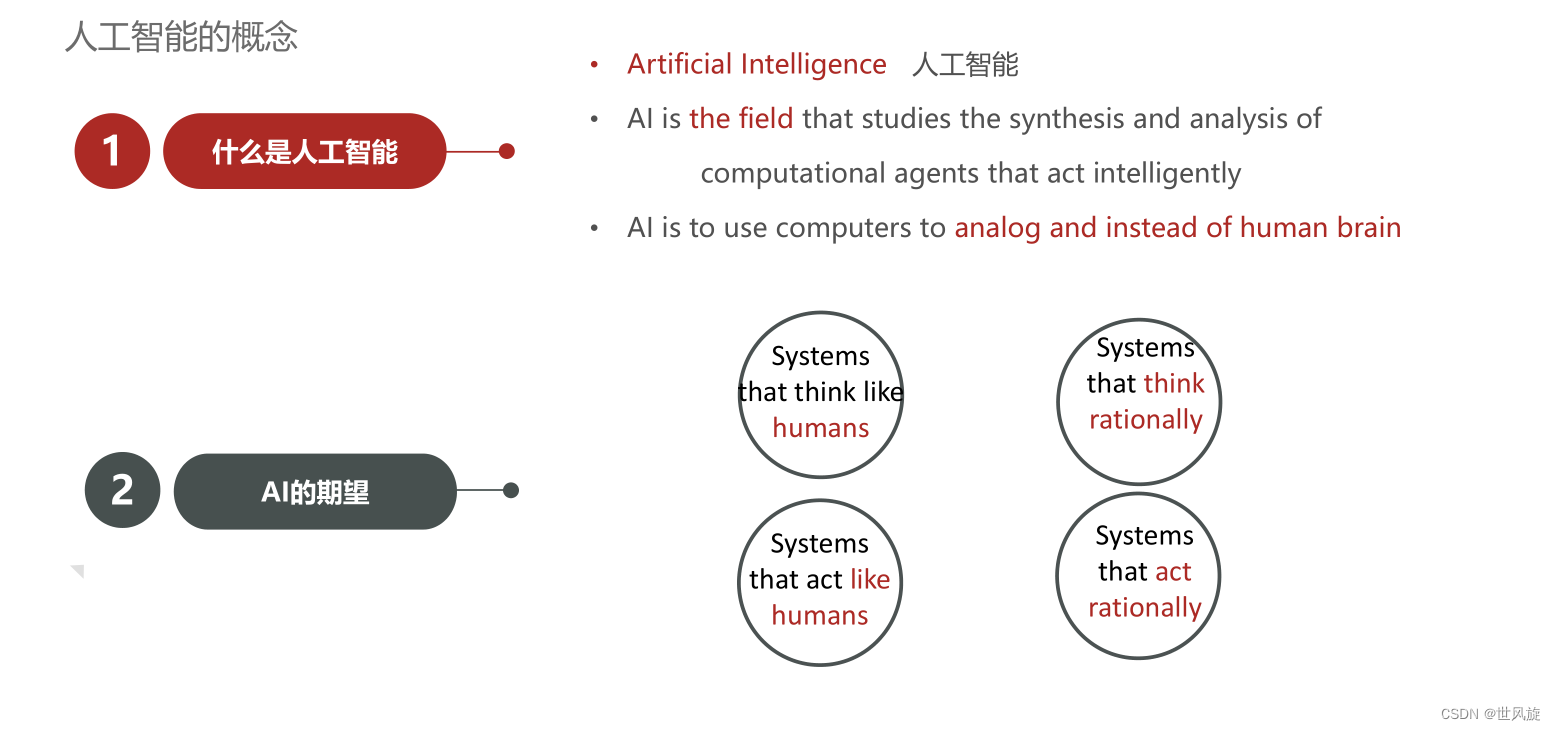
什么是人工智能:
(1)人工智能是研究综合和分析的领域智能行动的计算代理;
(2)人工智能是用计算机来模拟,而不是人脑;
即仿智,通过模仿生物或者人的智慧,赋予其思考和自我决断的能力。
AI的期望:
(1)系统像人类一样思考
(2)理性的系统像人类一样思考
(3)行动像人类一样灵活
(4)系统行动理性化
机器学习(ML)
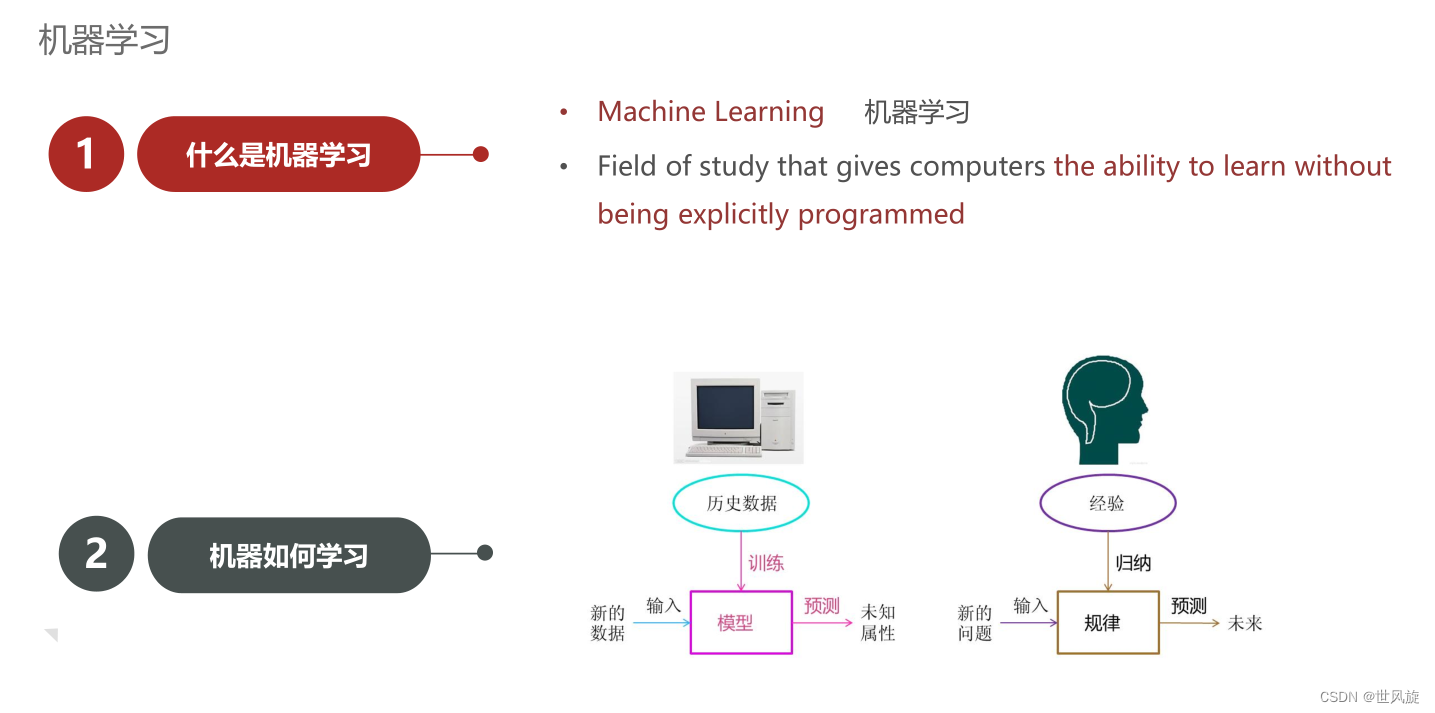
什么是机器学习:
使计算机具备无需明确编程即可学习能力的学科领域
机器如何学习:
人:由新的问题-(输入)->大脑(大脑通过归纳总结得到规律)-(预测)->未来
机器学习通过模仿人的学习过程有一套相似的学习方式
机器:首先将历史数据-(输入)->模型(进行训练,通过将特征数据化,发现规律,调节参数);让后将新的数据-(输入)->模型 -(进行预测)->得到目标
深度学习(DL)
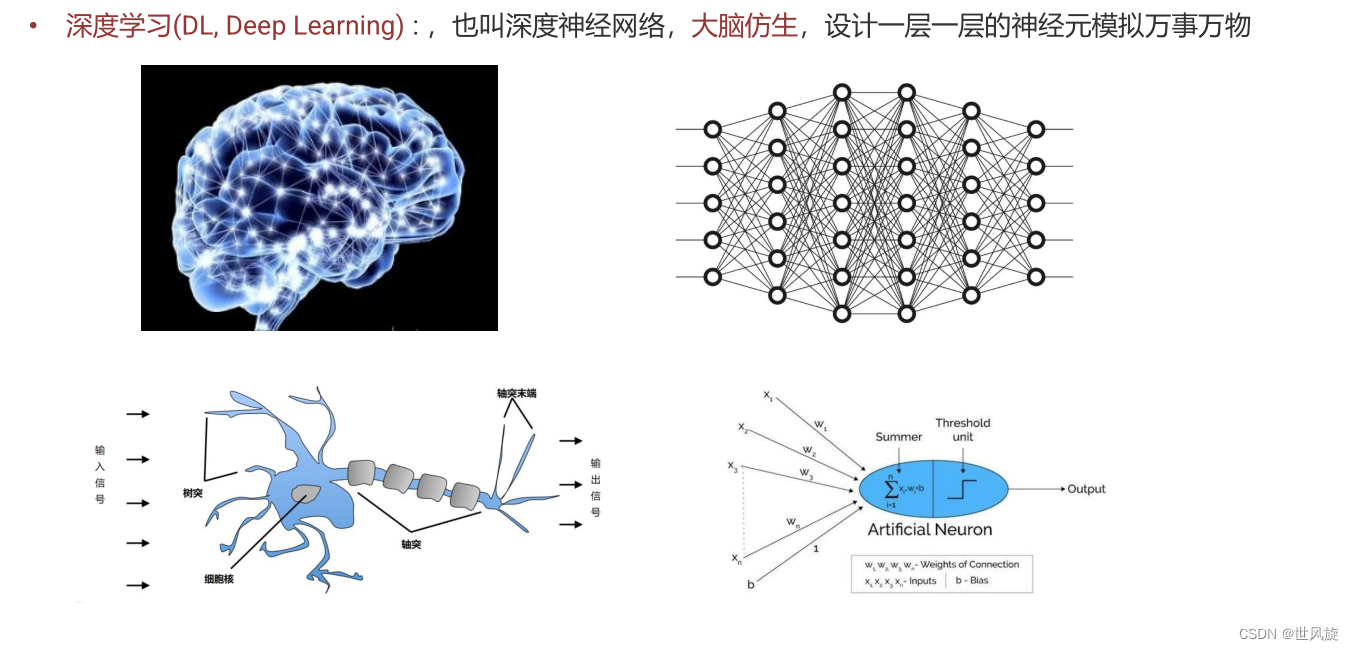
什么是深度学习:
Deep Learning (DL) :大脑仿生,设计一层一层的神经元模拟万事万物。
深度学习是机器学习领域中的一个重要研究方向,其目标是让机器能够像人一样具有分析学习能力,识别并理解文字、图像和声音等数据。深度学习主要通过对大量样本的特征进行自学习,实现输入与输出之间的复杂函数逼近。其原理基于神经网络,通过反向传播算法训练网络参数,不断优化网络性能。深度学习在多个领域都有广泛应用,如计算机视觉、自然语言处理、语音识别、推荐系统、医学影像识别、金融风控等。
人工智能、机器学习和深度学习三者之间的关系:

可以理解为机器学习是实现人工智能的一种途径,深度学习是机器学习的一种方法。
算法的学习方式:
基于规则的学习
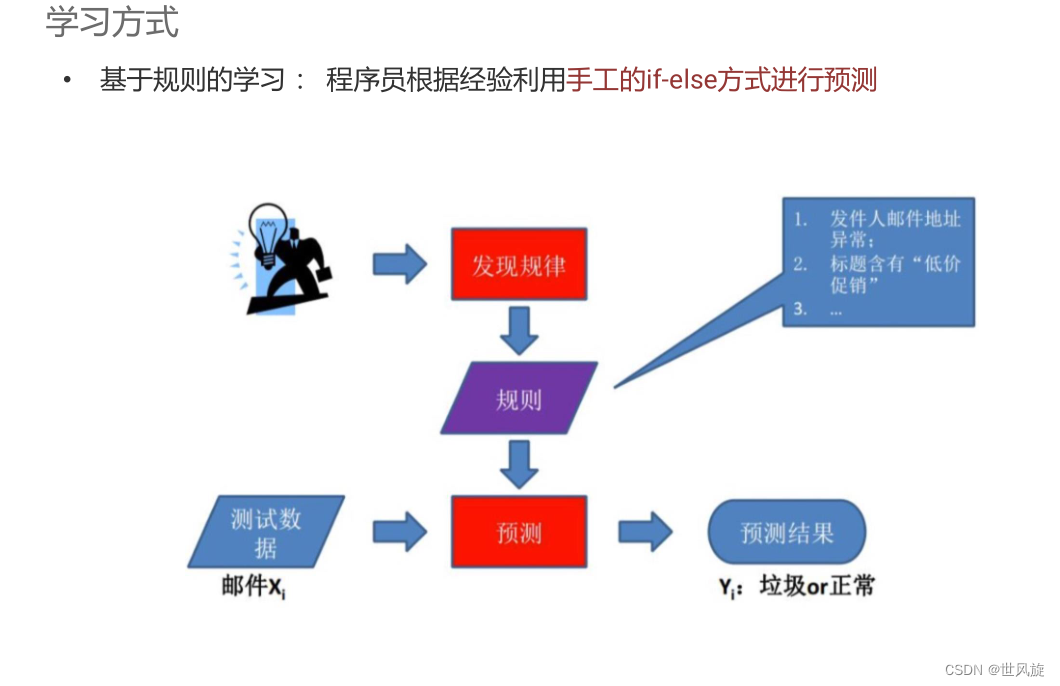
基于模型的学习

遇到这种无法用常规规律解决的问题,就需要从数据中自动学出规律

房价预测:

2.机器学习的应用领域和发展史
机器学习的应用领域:
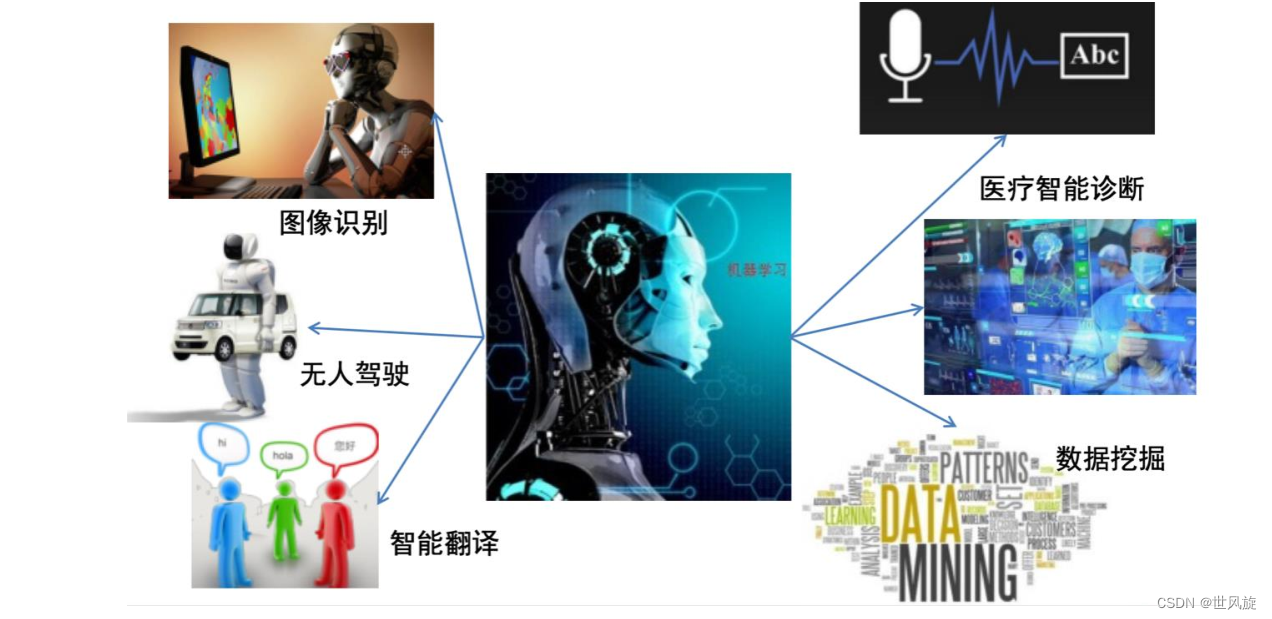
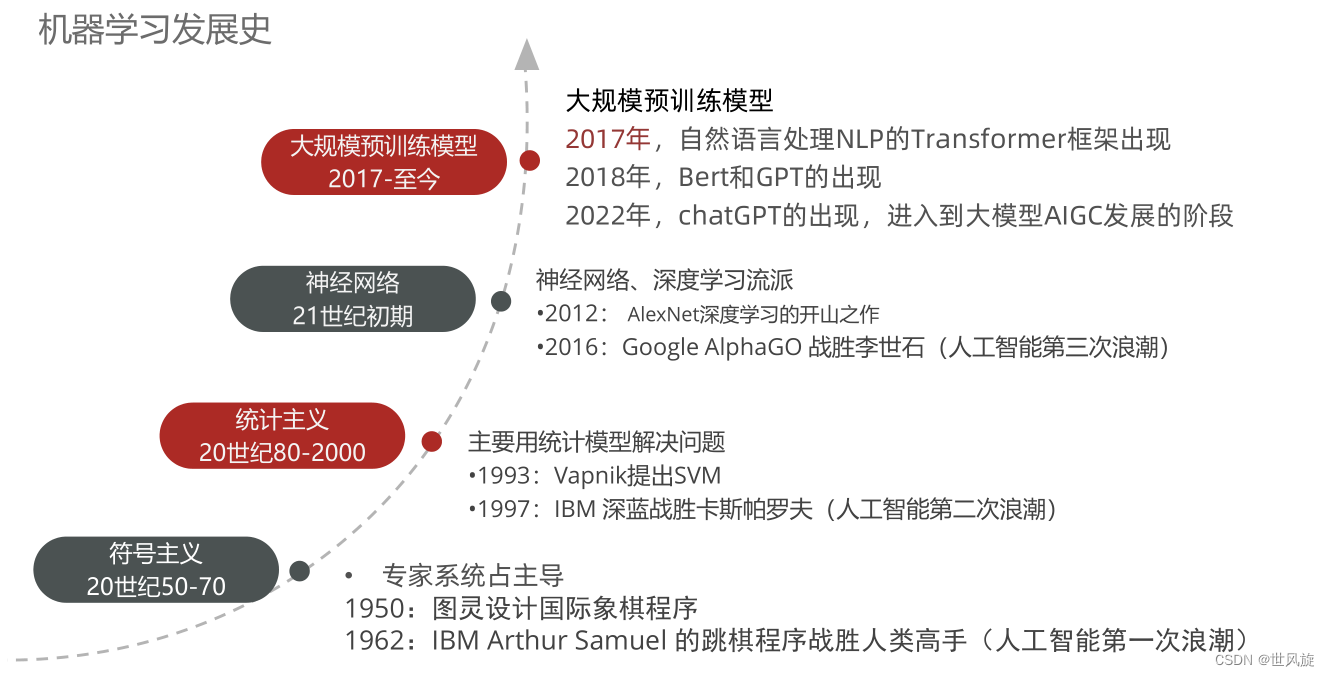
机器学习的发展史:
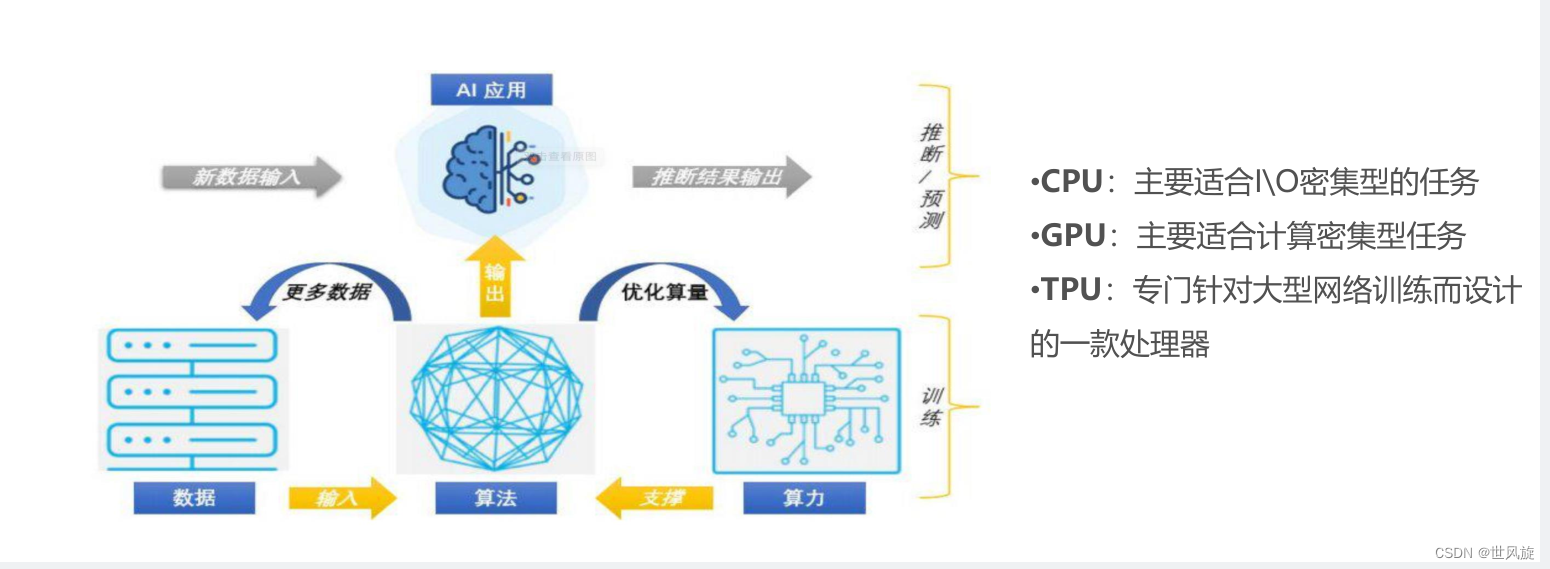
AI发展三要素:
数据、算法、算力三要素相互作用,是AI发展的基石。
3.机器学习常用术语
什么是样本、特征和标签:
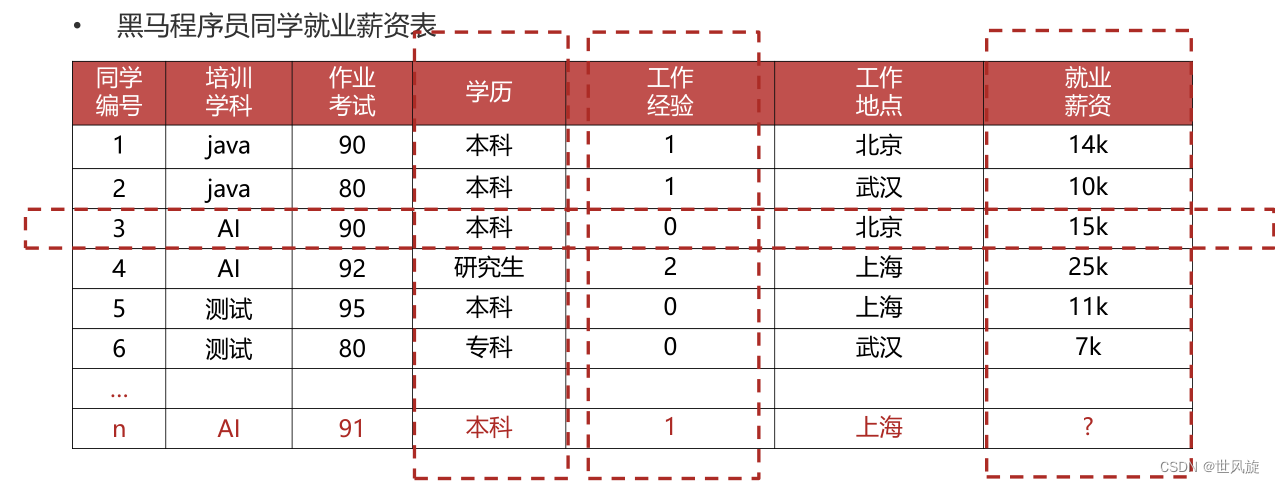
以这样的数据为例:
样本(sample) :一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录;
特征(feature) :一列数据一个特征,有时也被称为属性;
标签/目标(label/target) :模型要预测的那一列数据。本场景是就业薪资;
就业薪资 与 培训学科、作业考试、学历、工作经验、工作地点 5个特征有关系;
特征如何理解(重点):特征是从数据中抽取出来的,对结果预测有用的信息 eg:房价预测、车图片识别等。
理解数据集划分的方法:

数据集在训练模型时使用,往往被分为训练集和测试集两部分,比例:8 : 2,7 : 3(有些模型训练时还会加上验证集);
训练集(training set) :用来训练模型(model)的数据集
测试集(testing set):用来测试模型的数据集
#验证集(validation set):用于评估模型泛化能力
一些常规代码名称:
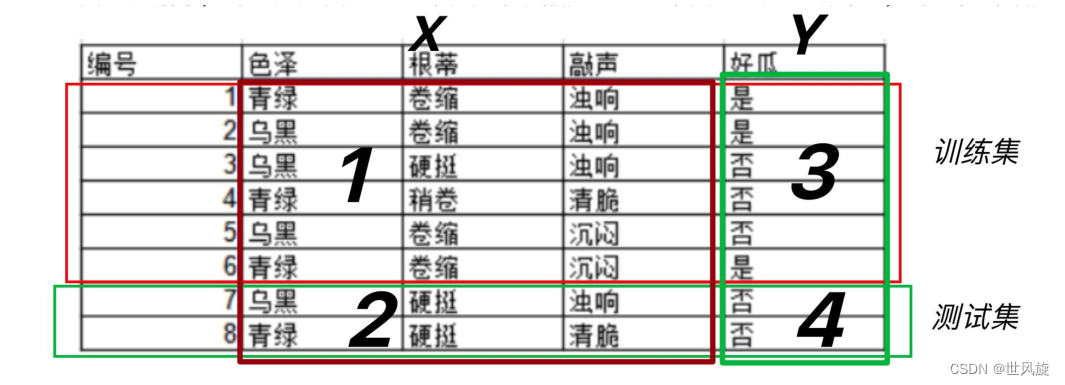
x_train 训练集中的x,x_test 测试集中的x,y_train 训练集中的y,y_test 测试集中的y
4.机器学习算法分类
有监督学习:
- 特点:数据集通常带有人工标签,提供了一组输入输出对,以便学习一个将输入映射到正确输出的中间系统。
- 应用:常见的应用场景包括垃圾邮件识别、文本情感分析和房价预测等。
- 区别:与其他学习方式相比,有监督学习依赖于带有标签的数据集进行训练,其目标是使模型能够对新的、未见过的数据进行准确的预测。
无监督学习:
- 特点:不依赖标签数据进行训练,而是从未标记的数据中发现模式、结构和规律。
- 应用:常用于聚类、降维或关联规则挖掘等任务,以便从数据中学到有用的信息。
- 区别:与有监督学习相反,无监督学习不依赖于标签数据,而是通过探索数据中的内在结构和关系来进行学习。
半监督学习:
- 特点:介于监督学习和无监督学习之间,同时使用有标签和无标签的数据进行训练,以更好地泛化到未见过的数据。
- 应用:能够充分利用未标记数据,减轻对大量标记数据的依赖,从而在某些场景下提高模型的性能。
- 区别:半监督学习结合了有监督和无监督学习的特点,通过同时利用带标签和不带标签的数据来训练模型,以期望达到更好的泛化能力。
强化学习:
- 特点:是一种学习如何从状态映射到行为以获取最大奖励的学习机制,涉及agent与环境之间的交互,并通过反复实验和延迟奖励来进行学习。
- 应用:常用于机器人控制、游戏AI和自动驾驶等领域,其中agent需要不断从环境中进行实验,并通过环境给予的反馈来优化其行为。
- 区别:与其他学习方式不同,强化学习没有明确的监督者,而是依赖于环境的反馈来进行学习,其目标是通过不断试错和优化来最大化累积奖励。
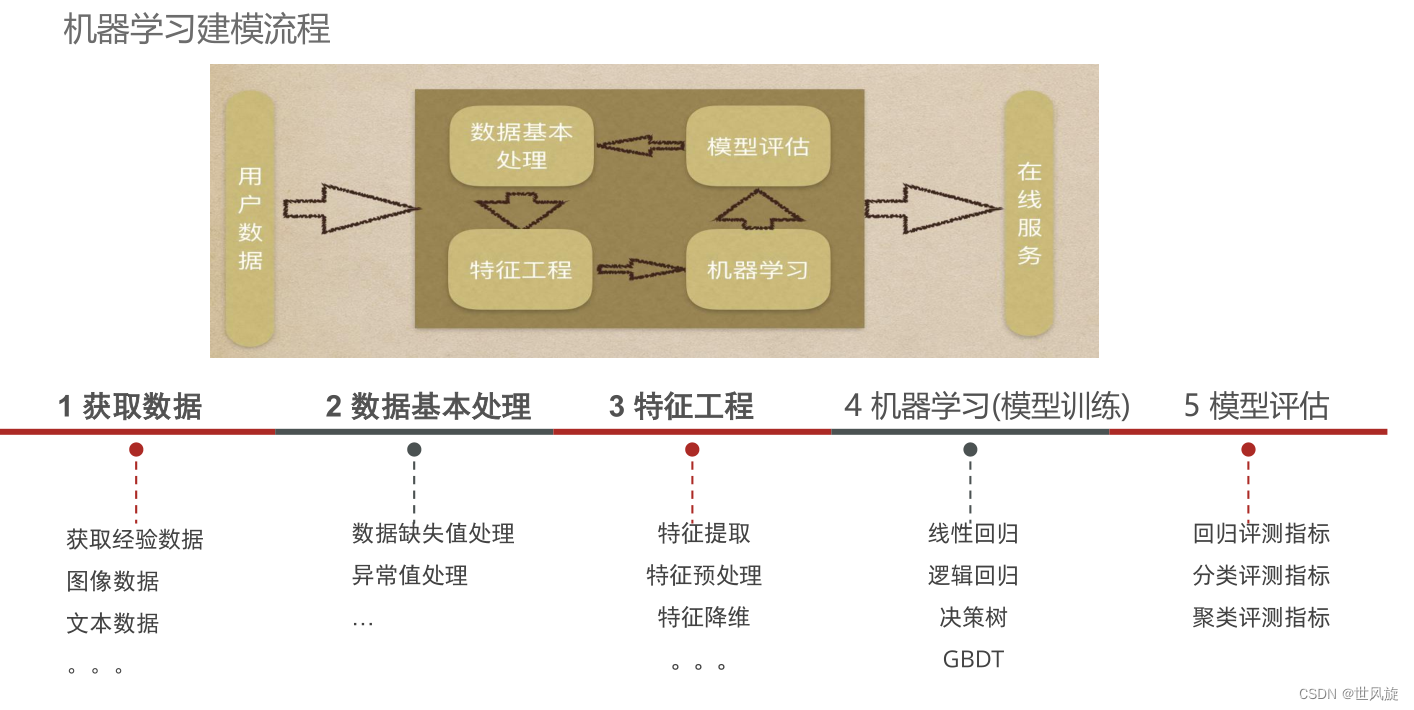
 5.机器学习建模流程
5.机器学习建模流程
















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









