







系列文章目录
文章目录
目录
(2)在data文件夹下面创建mydata.yaml并添加代码
3.RuntimeError: result type Float can‘t be cast to the desired output type long int报错
前言
由于最近电赛训练题目涉及到视觉,考虑到性价比和性能优势,最终选择了树莓派,由于是小白,跟着大佬的博客踩了很多坑(太菜了不会操作),用此博客记录自己从开始配环境到最后成功运行模型的过程,其中用到的相关资源我也会给出链接
一、yolov5lite下载(1.4版本)
注意我们下载的是yolov5lite的1.4版本,yolov5lite是yolov5的轻量版,在树莓派上运行帧率更高,至于为什么是1.4版本,是因为我看的这位大佬的这篇博客中,最后在运行时会有报错,好像是高版本的yolov5lite在返回时的shapes与低版本不同,而实测用大佬的推理代码在1.4版本的yolov5lite转化的onnx模型可以运行,所以建议下载yolov5lite-1.4,这里我给出两种下载方式,一种是在Github官网的仓库下载,另一种可以在我分享的网盘文件下载
百度网盘,提取码:yolo
二、模型训练
1、采集训练数据(图片)
在树莓派上运行下面的捕获代码,每0.4s捕获一张,捕获的照片会存在images文件夹下,可以通过WinSCP把采集的图片从树莓派传回电脑,可以查找相关博客查看使用教程
import cv2
from threading import Thread
import uuid
import os
import time
count = 0
def image_collect(cap):
global count
while True:
success, img = cap.read()
if success:
file_name = str(uuid.uuid4())+'.jpg'
cv2.imwrite(os.path.join('images',file_name),img)
count = count+1
print("save %d %s"%(count,file_name))
time.sleep(0.4)
if __name__ == "__main__":
os.makedirs("images",exist_ok=True)
# 打开摄像头
cap = cv2.VideoCapture(0)
m_thread = Thread(target=image_collect, args=([cap]),daemon=True)
while True:
# 读取一帧图像
success, img = cap.read()
if not success:
continue
cv2.imshow("video",img)
key = cv2.waitKey(1) & 0xFF
# 按键 "q" 退出
if key == ord('c'):
m_thread.start()
continue
elif key == ord('q'):
break
cap.release() 2、训练集制作
我们需要用到一个工具labelme,这个工具的安装直接使用命令安装
pip install labelme使用时按下win+R,输入cmd调出命令行,输入命令labelme即可调出来,可能是由于我使用了清华的镜像源,所以是中文界面
首先需要打开你存放照片的文件夹
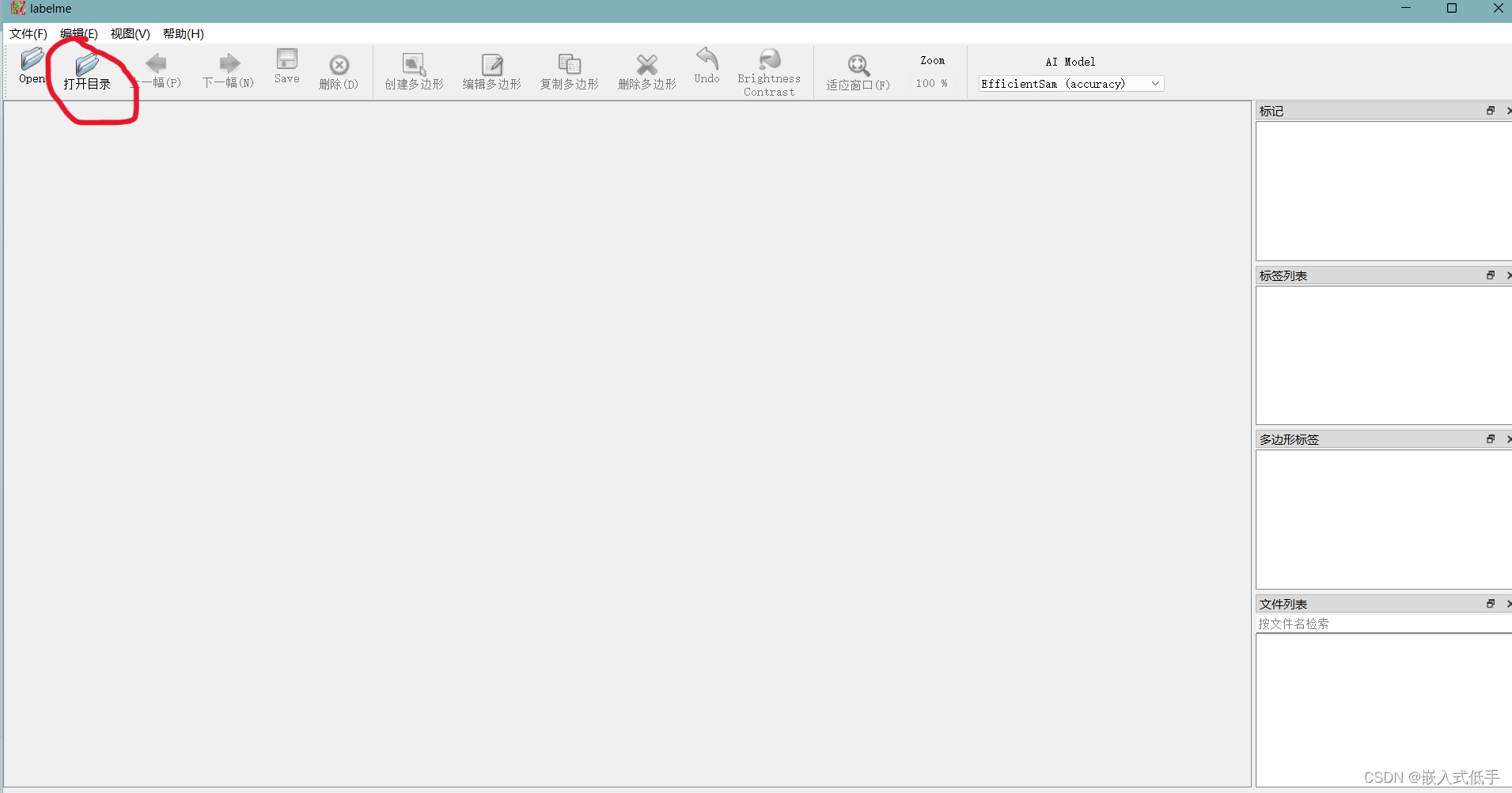
选择你存放图片的路径
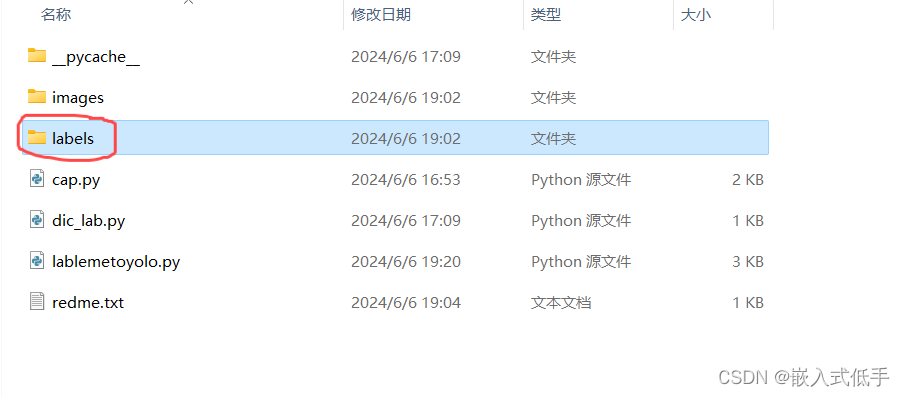
然后在存放图片的文件夹同级目录下创建一个labels文件夹,里面用来存放生成的JSON文件
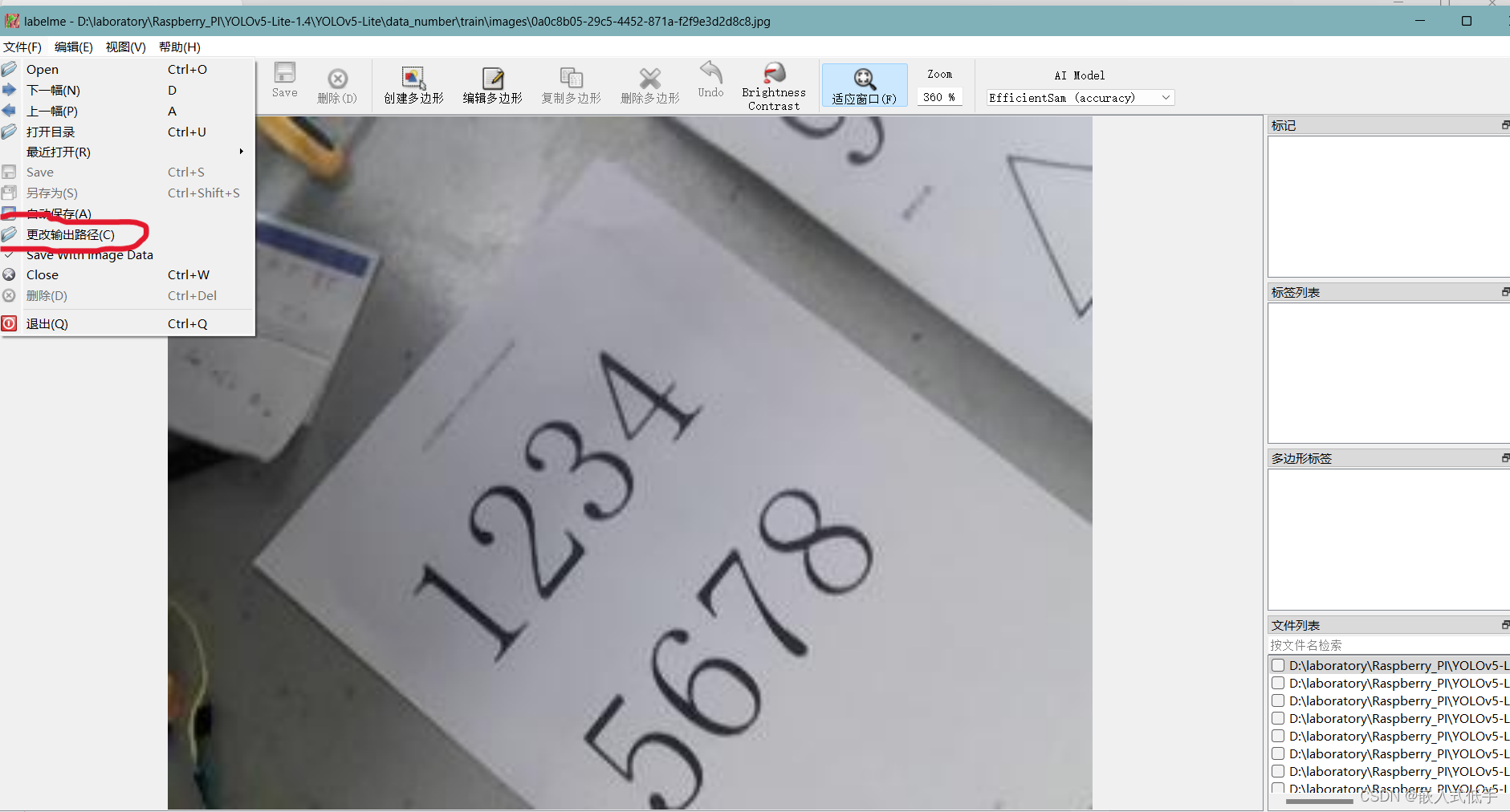
然后在labelme里面更改输出路径,更改为上面创建的labels文件夹,以及打开这个上面的自动保存
然后就是愉快的(费时间的)打标签工作了
快捷键Ctrl+R,画矩形框打标签
3、转换JSON文件为yolov5格式的txt文件
JSON格式不是我们训练yolov5需要的格式,下面我们就需要对JSON文件进行转换,变成我们需要的格式,当然,labelme也可以直接输出yolo格式,但是听说不一次性打完标签会有bug,所以还是建议使用JSON转txt,转换格式我们需要用到下面的代码
dic_lab.py,上面的''中的0-9是你打的标签,后面的0-9是这个标签在yolov5格式中的编号,ratio的0.9是把训练集和验证机集以9:1的比例分配
dic_labels= {'0':0,
'1':1,
'2':2,
'3':3,
'4':4,
'5':5,
'6':6,
'7':7,
'8':8,
'9':9,
'path_json':'D:/laboratory/Raspberry_PI/yolov5-lite train/cap image/labels', #这里是labelme输出路径
'ratio':0.9}labelmetoyolo.py
import os
import json
import random
import base64
import shutil
import argparse
from pathlib import Path
from glob import glob
from dic_lab import dic_labels
def generate_labels(dic_labs):
path_input_json = dic_labels['path_json']
ratio = dic_labs['ratio']
for index, labelme_annotation_path in enumerate(glob(f'{path_input_json}/*.json')):
# 读取文件名
image_id = os.path.basename(labelme_annotation_path).rstrip('.json')
# 计算是train 还是 valid
train_or_valid = 'train' if random.random() < ratio else 'valid'
# 读取labelme格式的json文件
labelme_annotation_file = open(labelme_annotation_path, 'r')
labelme_annotation = json.load(labelme_annotation_file)
# yolo 格式的 lables
yolo_annotation_path = os.path.join(train_or_valid, 'labels',image_id + '.txt')
yolo_annotation_file = open(yolo_annotation_path, 'w')
# yolo 格式的图像保存
yolo_image = base64.decodebytes(labelme_annotation['imageData'].encode())
yolo_image_path = os.path.join(train_or_valid, 'images', image_id + '.jpg')
yolo_image_file = open(yolo_image_path, 'wb')
yolo_image_file.write(yolo_image)
yolo_image_file.close()
# 获取位置信息
for shape in labelme_annotation['shapes']:
if shape['shape_type'] != 'rectangle':
print(
f'Invalid type `{shape["shape_type"]}` in annotation `annotation_path`')
continue
points = shape['points']
scale_width = 1.0 / labelme_annotation['imageWidth']
scale_height = 1.0 / labelme_annotation['imageHeight']
width = (points[1][0] - points[0][0]) * scale_width
height = (points[1][1] - points[0][1]) * scale_height
x = ((points[1][0] + points[0][0]) / 2) * scale_width
y = ((points[1][1] + points[0][1]) / 2) * scale_height
object_class = dic_labels[shape['label']]
yolo_annotation_file.write(f'{object_class} {x} {y} {width} {height}\n')
yolo_annotation_file.close()
print("creat lab %d : %s"%(index,image_id))
if __name__ == "__main__":
os.makedirs(os.path.join("train",'images'),exist_ok=True)
os.makedirs(os.path.join("train",'labels'),exist_ok=True)
os.makedirs(os.path.join("valid",'images'),exist_ok=True)
os.makedirs(os.path.join("valid",'labels'),exist_ok=True)
generate_labels(dic_labels)
运行labelmetoyolo.py即可完成格式转换
4、在电脑上安装yolov5lite训练所需要的环境
如果你电脑带有英伟达的独显,可以跳过这一步,直接看修改代码配置处,因为用GPU训练建议将包安装在虚拟环境,也会走一次这个流程,只是一个在系统环境,一个在虚拟环境,当然CPU训练也可以将包安装在虚拟环境,自行选择
建议安装环境之前先将pip换源到国内的镜像源,提高下载速度
找到你下载的yolov5lite-1.4,打开到看能到requirements.txt文件为止
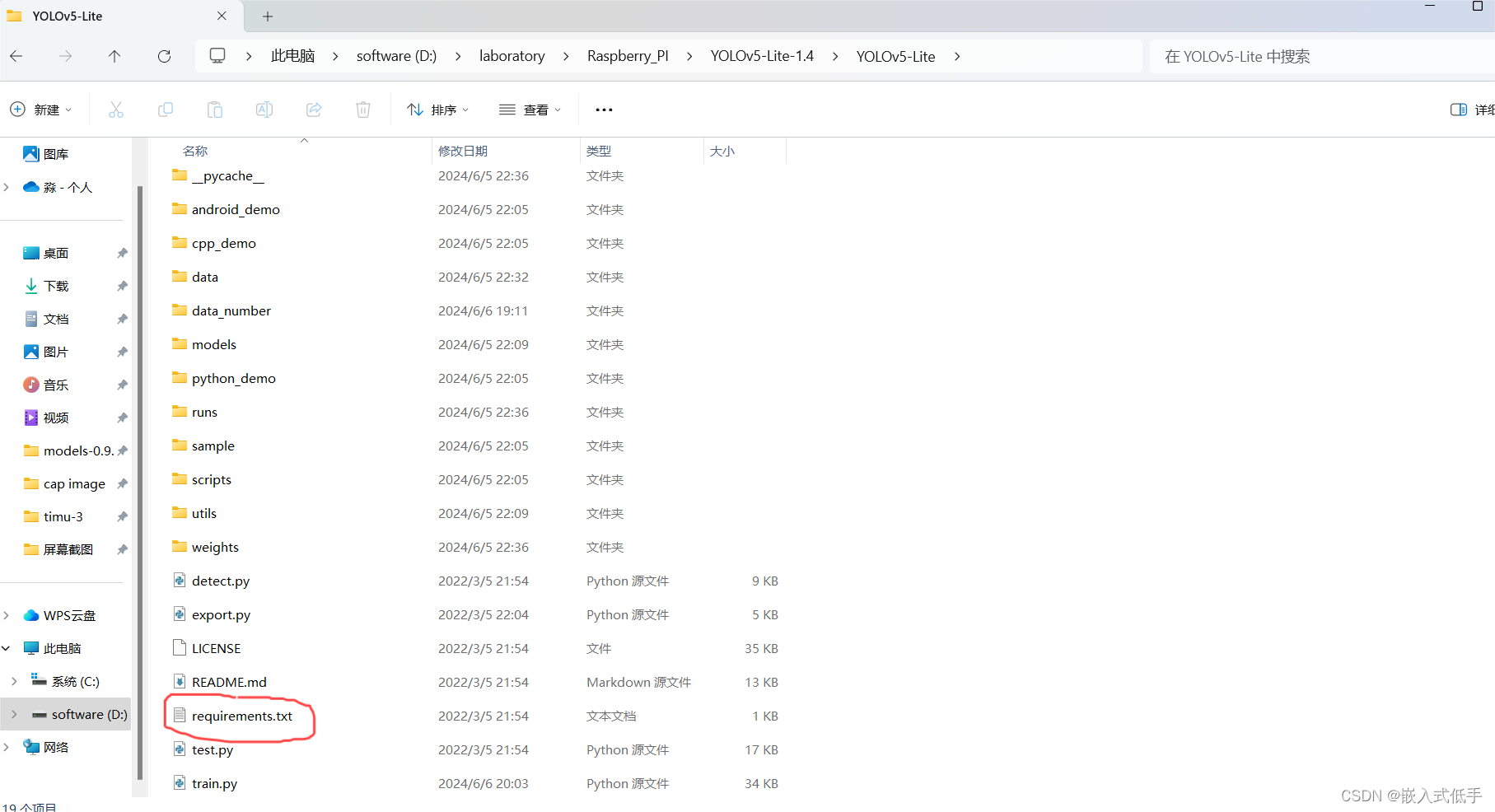
然后复制当前路径
然后打开开始菜单,搜索Winsows PowerShell并打开
然后运行命令,后面替换为自己刚刚复制的路径
cd D:\laboratory\Raspberry_PI\YOLOv5-Lite-1.4\YOLOv5-Lite进入文件夹后运行命令
pip install -r requirements.txt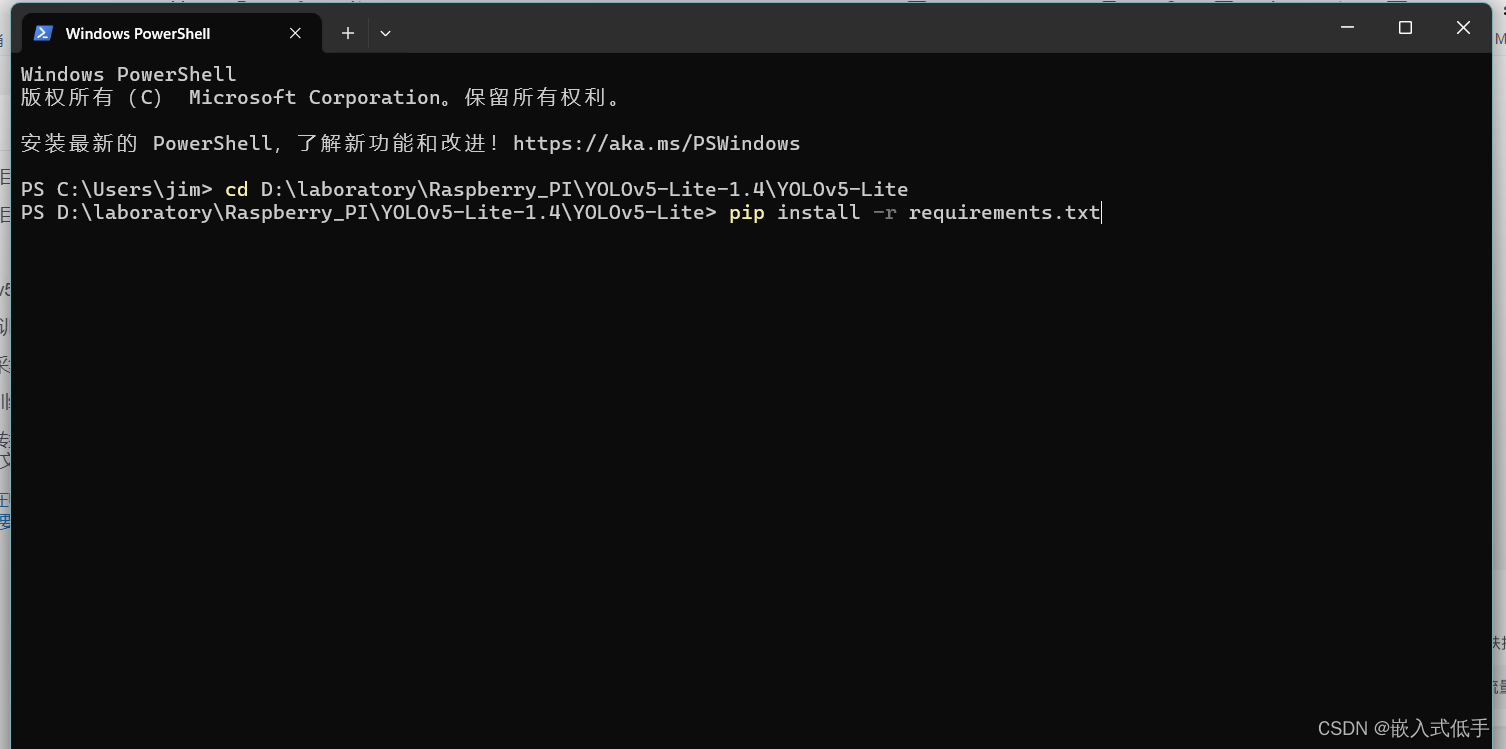
此命令会安装yolov5lite相关的依赖包,安装完成后,此时的numpy库的版本应该是高于yolov5lite所需要的版本,此时卸载numpy库,运行命令
pip uninstall numpy然后安装numpy 1.23版本,运行命令
pip install numpy==1.23此时训练的环境已经安装完成
5、修改代码配置以及报错解决
1.CPU篇
(1)修改train.py
打开train.py,找到主函数,修改与训练相关的配置
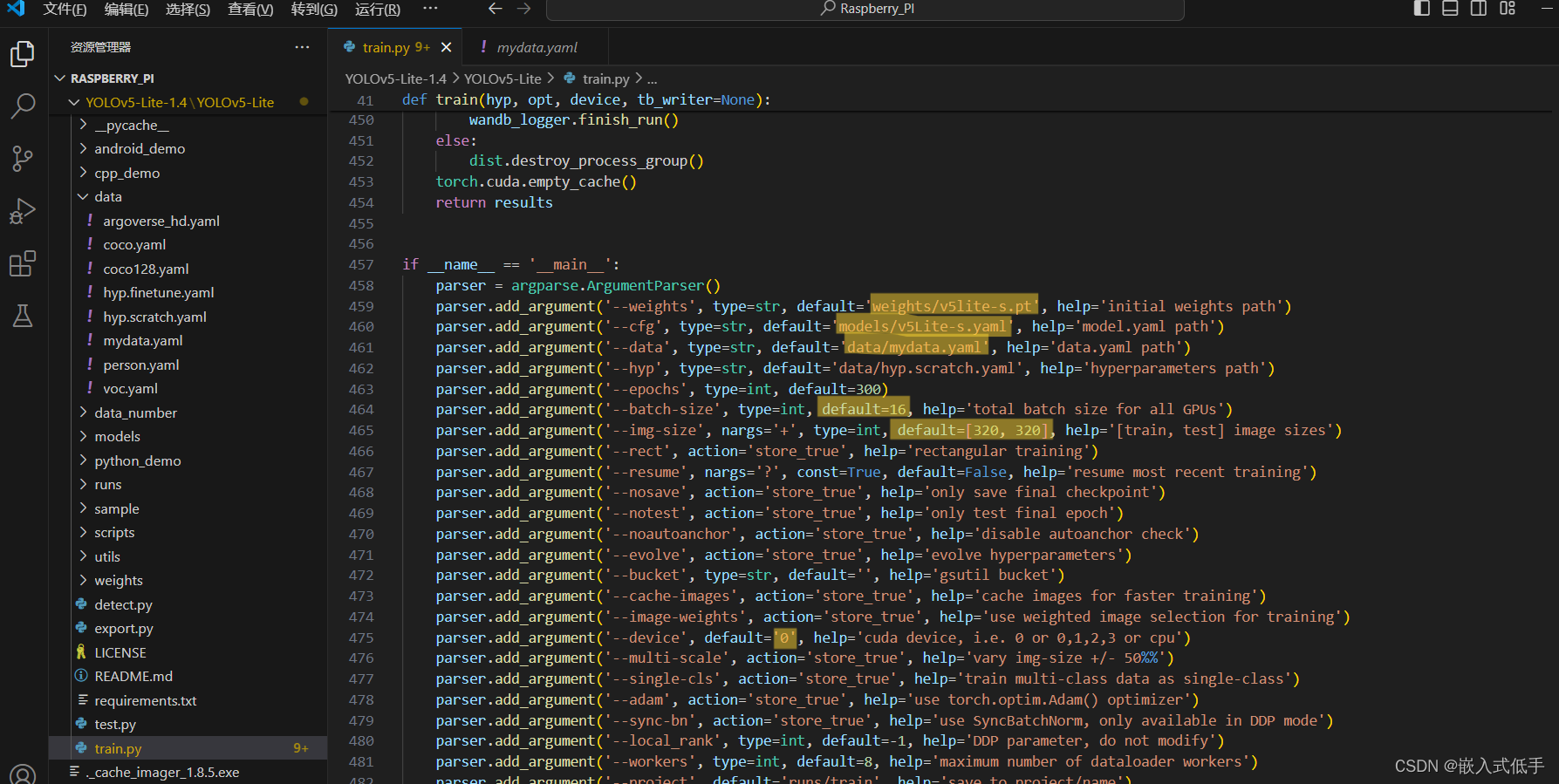
weights---weights/v5lite-s.pt
cfg---models/v5Lite-s.yaml
data---data/mydata.yaml
batch-size---16 这个好像会影响训练需要的虚拟内存,我也不是很清楚,一般取8的倍数,但是不是8的倍数也可以,提示虚拟内存不足可以尝试把这个值改小
img-size---320 这个根据你自己采集用来训练的数据集图片尺寸来选择,我采集的是320X320
device---cpu 用cpu训练
(2)在data文件夹下面创建mydata.yaml并添加代码
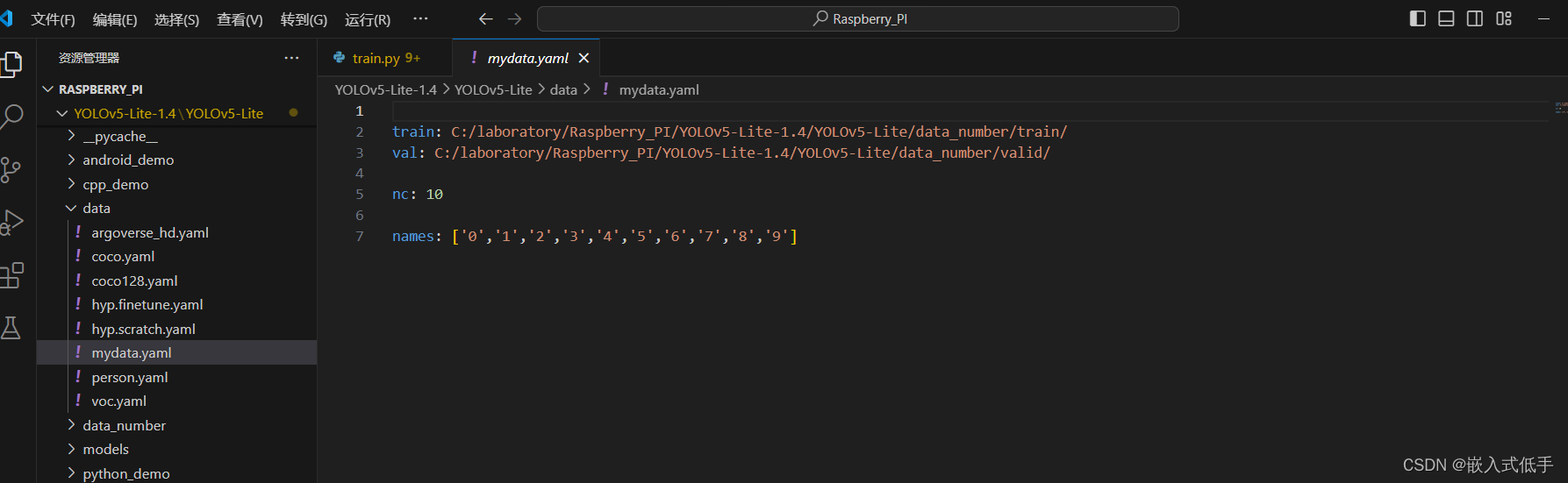
train: C:/laboratory/Raspberry_PI/YOLOv5-Lite-1.4/YOLOv5-Lite/data_number/train/
val: C:/laboratory/Raspberry_PI/YOLOv5-Lite-1.4/YOLOv5-Lite/data_number/valid/
nc: 10
names: ['0','1','2','3','4','5','6','7','8','9']train:训练集的路径
val:验证集的路径
nc:标签总数
names:标签
训练集和验证集可以在第三步转换JSON文件为yolov5格式完成后找到
(3)下载权重文件并放到yolov5lite文件夹下
这一步路径注意一定要对应
下载权重文件:权重文件
将权重文件所在的文件夹放在train.py的同级目录下
现在就可以运行train.py来训练模型了!
如果有报错:RuntimeError: result type Float can‘t be cast to the desired output type long int,请移步报错解决
2.GPU篇
使用GPU加速比CPU更复杂,主要涉及anaconda创建虚拟环境来训练模型和CUDA的相关下载,pytorch的版本也与cpu版本不同,让我们看看如何操作
(1)下载和安装anaconda
可以参考这篇博客anaconda下载和安装
(2)安装CUDA
可以参考这篇博客CUDA安装
(3)创建虚拟环境
在开始菜单搜索anaconda

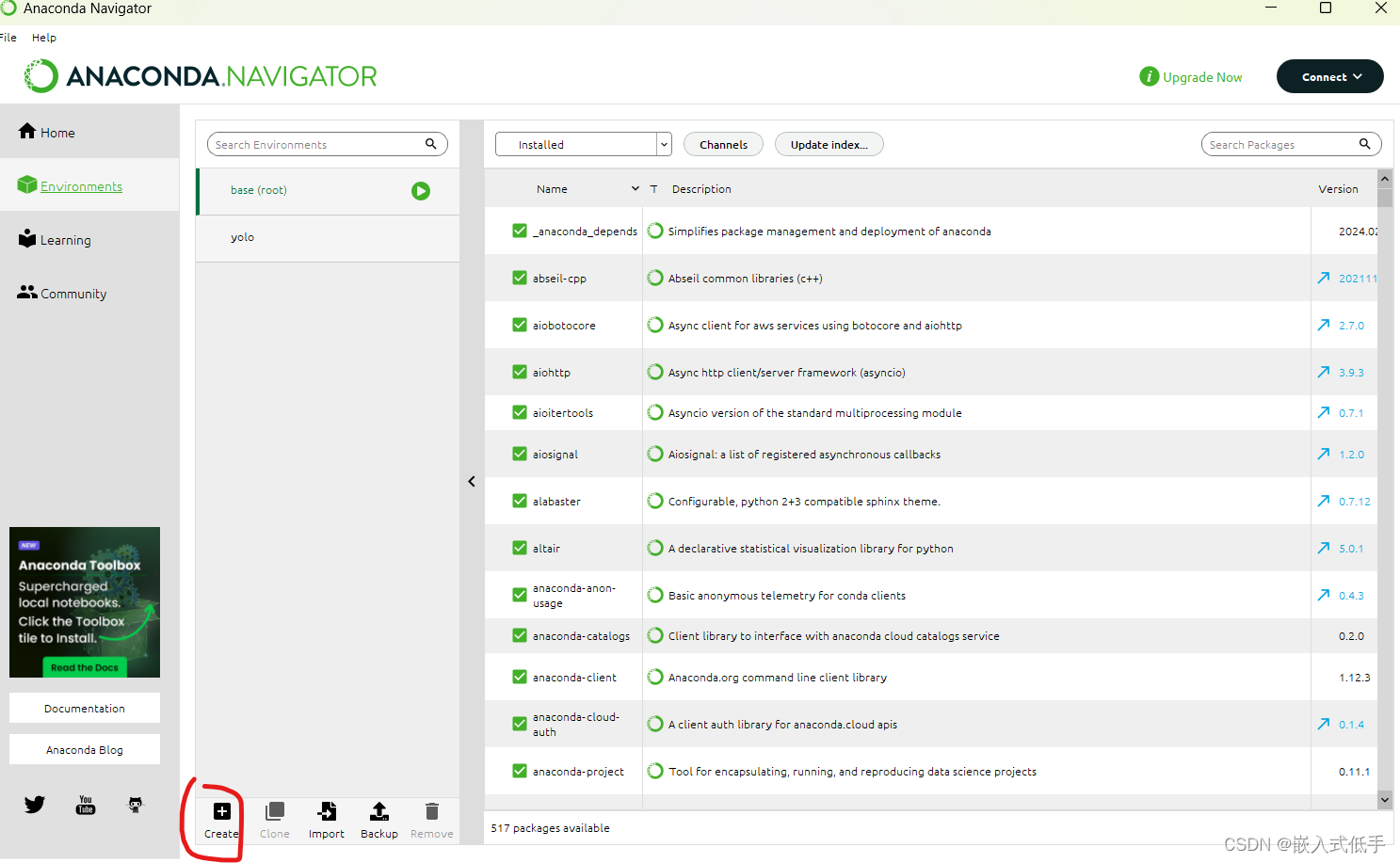
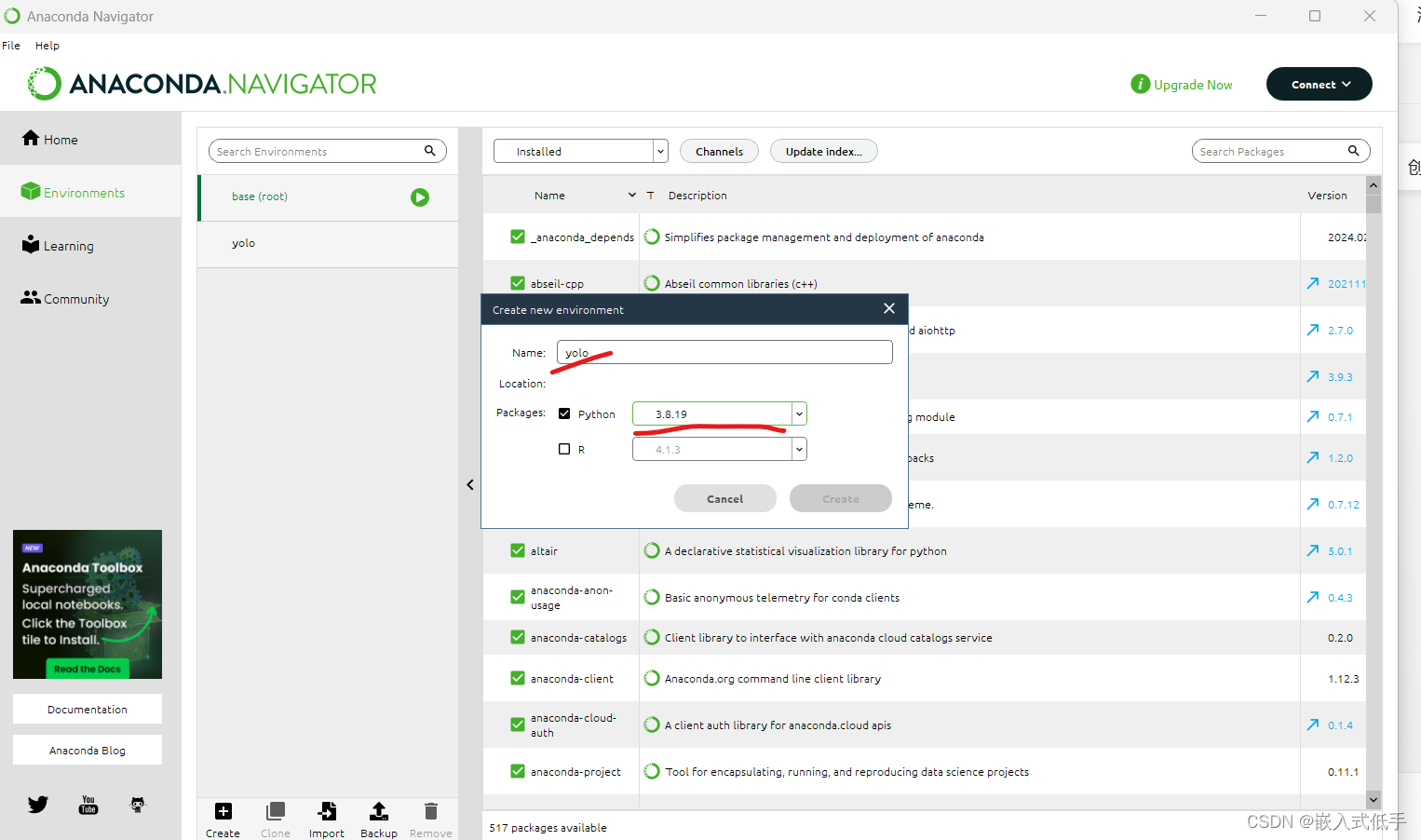
name为虚拟环境的名字
下面为虚拟环境中的python版本,我选择3.8.19
(4)在虚拟环境中安装训练所需要的环境
注意conda中的pip也需要换源,否则下载很慢
在开始菜单搜索anaconda
打开虚拟环境的命令窗口,此时可以看到我们处于系统环境下(base)
运行命令激活虚拟环境
activate yolo(创建的虚拟环境的名字)
安装pytorch(gpu版本)
可以去到pytorch的官网复制命令,可以防止自己使用命令下载使得版本不匹配
https://pytorch.org/get-started/previous-versions/
找到CUDA版本对应的命令
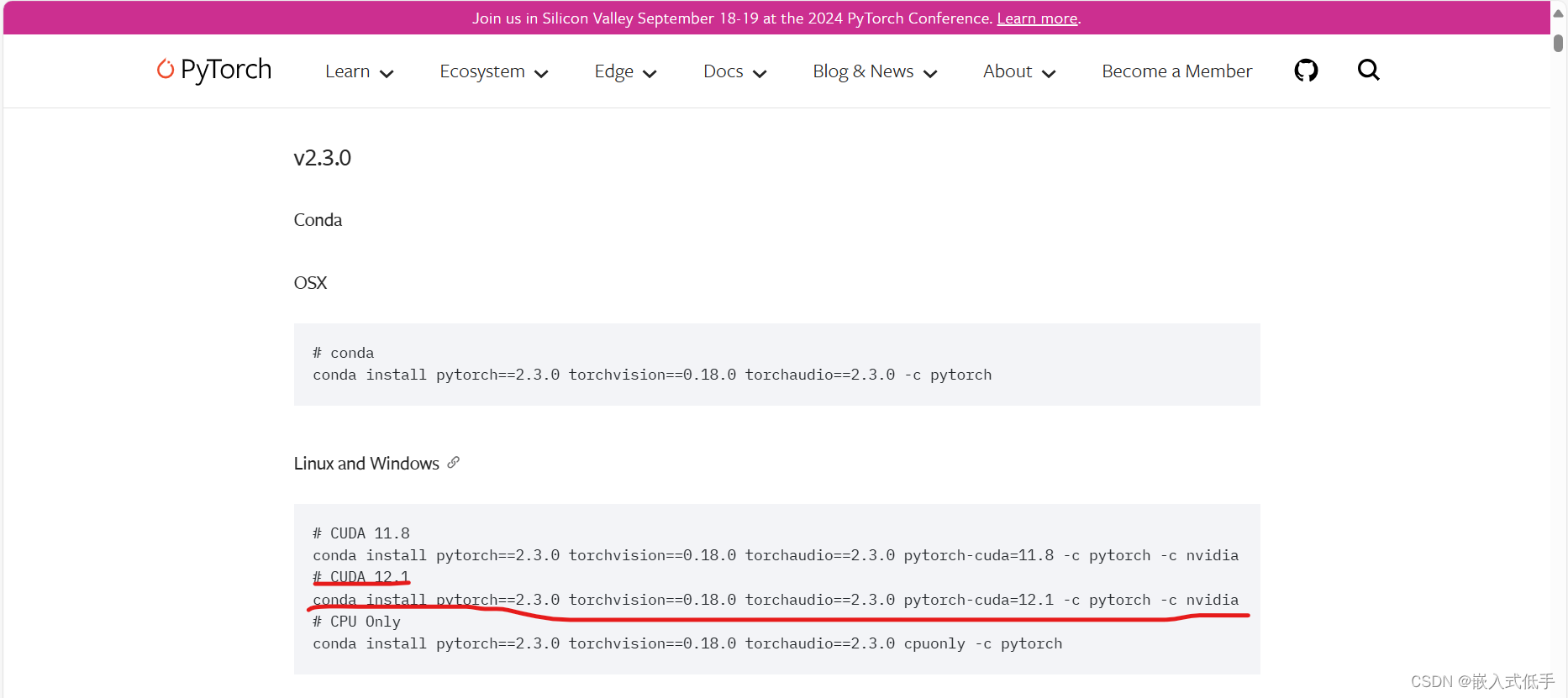
然后复制命令在虚拟环境运行
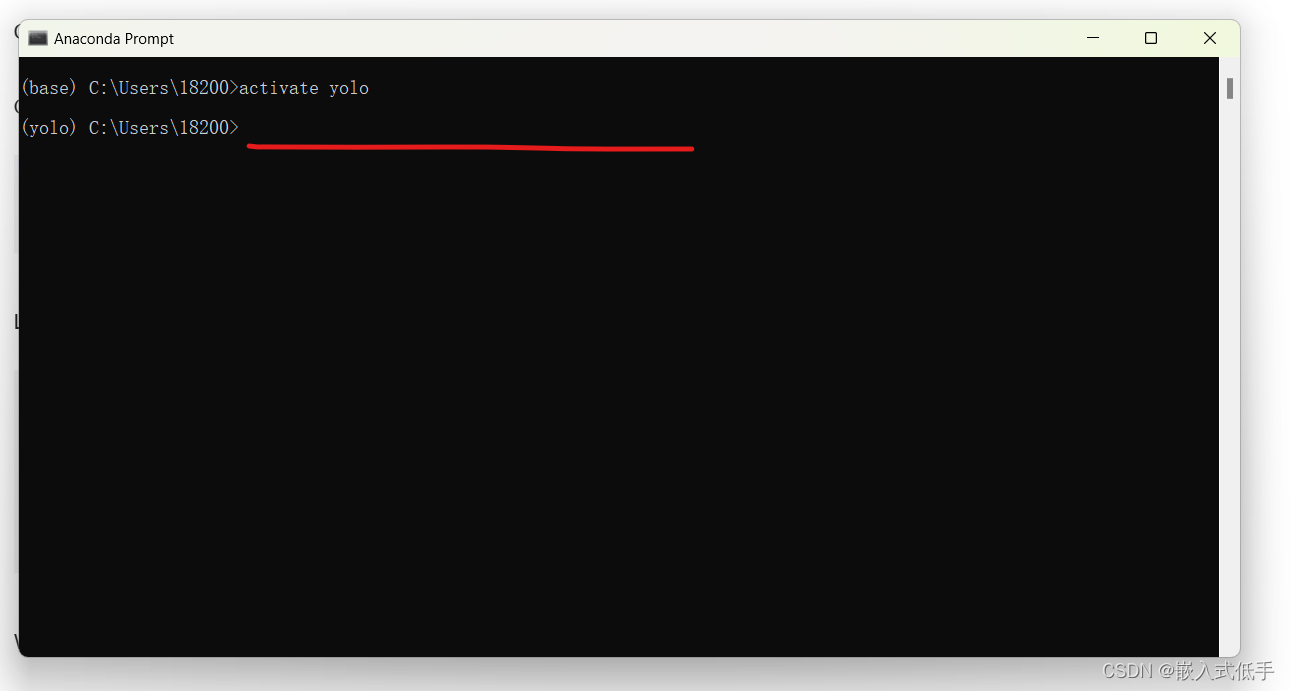
在这里运行
这也是我建议下载12.1版本的CUDA的原因
一定要检查自己当前版本的显卡驱动是否支持CUDA12.1版本,如果不支持请更新显卡驱动
查看当前显卡驱动支持的CUDA版本:
按下WIN+R,输入cmd打开命令行窗口
输入命令:
nvidia-smi
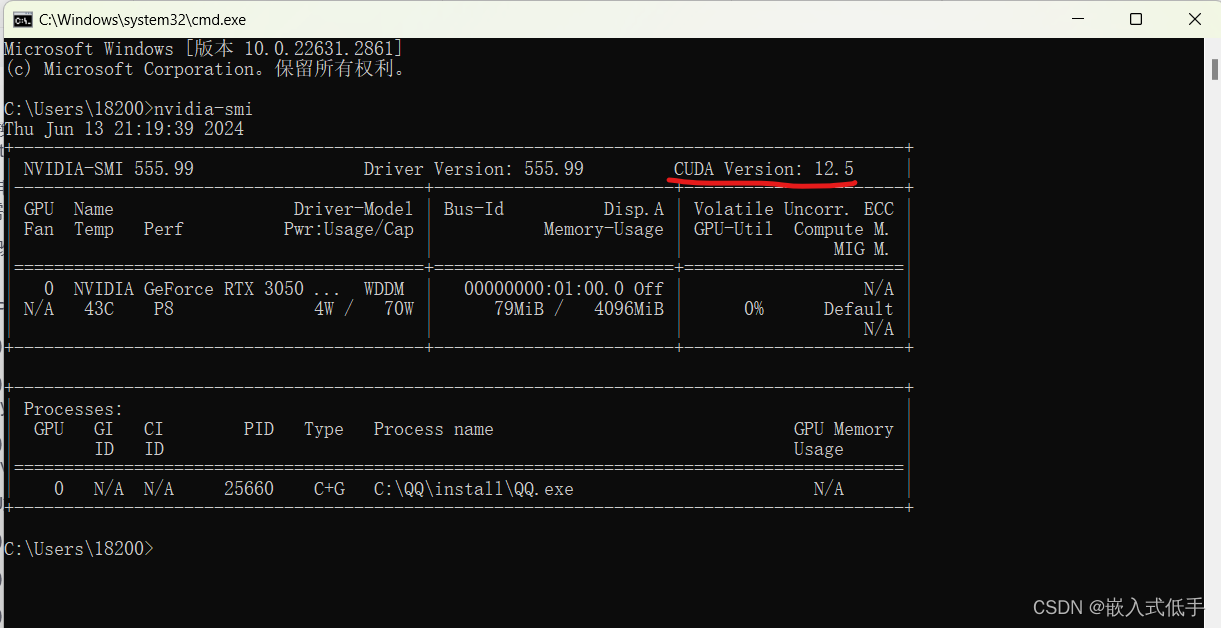
这个就是你当前驱动支持的最大CUDA版本
上述操作都完成之后,检查cuda是否可用
在虚拟环境下以此输入命令
python
import torch
print(torch.cuda.is_available())如果返回为True,则没问题了,如果为False,那就自己找找问题吧哈哈

与上面的安装环境类似,只是所有操作都在虚拟环境下进行,所以主要以文字给出
激活虚拟环境
找到你下载的yolov5lite-1.4,打开到看能到requirements.txt文件为止
然后复制当前路径
在虚拟环境的命令行串口运行
cd 你复制的路径
进入文件夹后运行命令
pip install -r requirements.txt此命令会安装yolov5lite相关的依赖包,安装完成后,此时的numpy库的版本应该是高于yolov5lite所需要的版本,此时卸载numpy库,运行命令
pip uninstall numpy然后安装numpy 1.23版本,运行命令
pip install numpy==1.23此时训练环境搭建完成,GPU的训练速度真是比CPU快多了,我用cpu训练迭代一次10多秒的模型,gpu1秒多就迭代一次,不得不说gpu加速是真的好用
3.RuntimeError: result type Float can‘t be cast to the desired output type long int报错
打开utils文件夹
打开loss.py
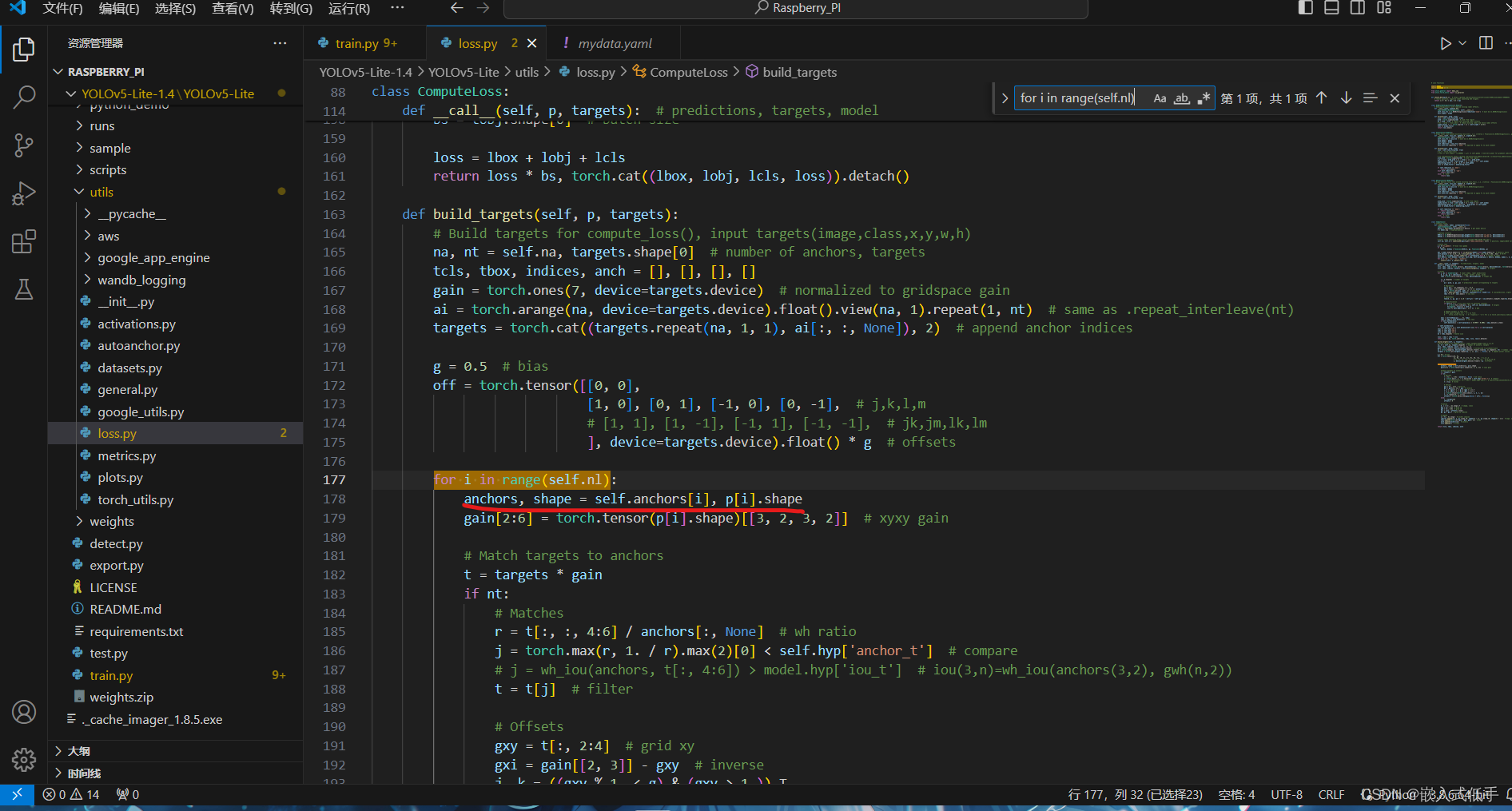
按【Ctrl】+【F】打开搜索功能,输入【for i in range(self.nl)】找到下面的一行内容
用下面的代码替换红线部分,上图已经替换过
anchors, shape = self.anchors[i], p[i].shape 按【Ctrl】+【F】打开搜索功能,输入【indices.append】找到下面的一行内容
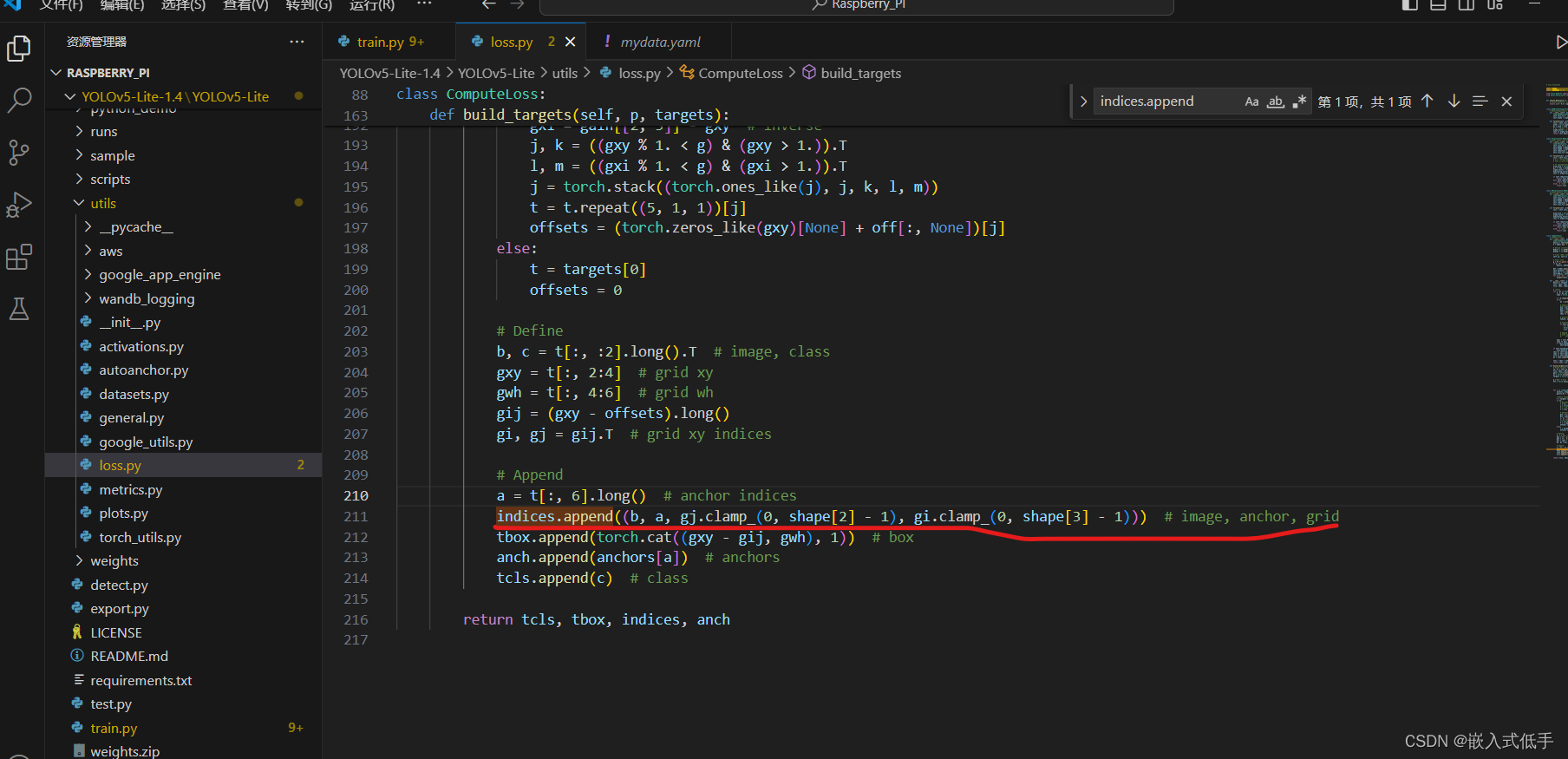
用下面的代码替换,上图已经替换过
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid此时再运行train.py,已经不会出现这个报错了
三、将训练好的模型部署到树莓派
1.将训练好的模型转换为onnx模型
找到export.py,复制所在文件夹路径
1.CPU篇
如果你的模型是用cpu训练的,那么在开始菜单搜索Windows PowerShell
打开这个窗口,输入命令进入export.py所在文件夹
cd 你刚刚复制的路径
2.GPU篇
如果你是用GPU训练的模型,那么在开始菜单搜索anaconda Prompt,打开窗口
先激活虚拟环境
activate 你的虚拟环境名字
输入命令进入export.py所在文件夹
cd 你刚刚复制的路径从这里开始cpu和gpu的操作一样
找到你训练的模型所在的文件夹,并复制路径
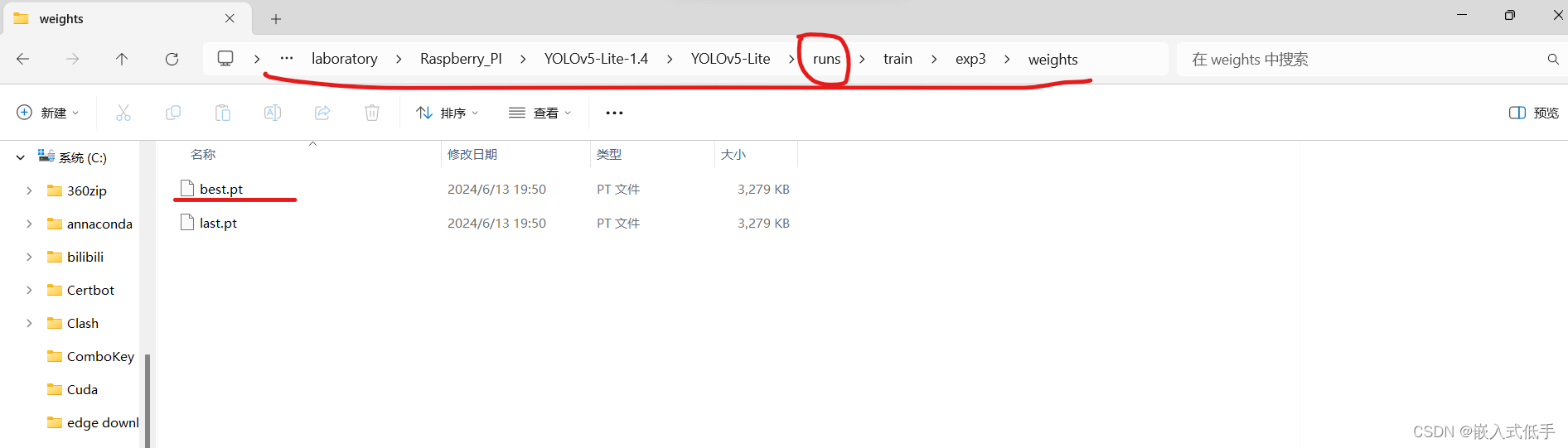
在export.py的文件夹下运行命令,记得替换成自己的路径
python export.py --weights C:\laboratory\Raspberry_PI\YOLOv5-Lite-1.4\YOLOv5-Lite\runs\train\exp3\weights\best.pt(这里是模型的绝对路径,记得去掉双引号) --img 320 --batch 1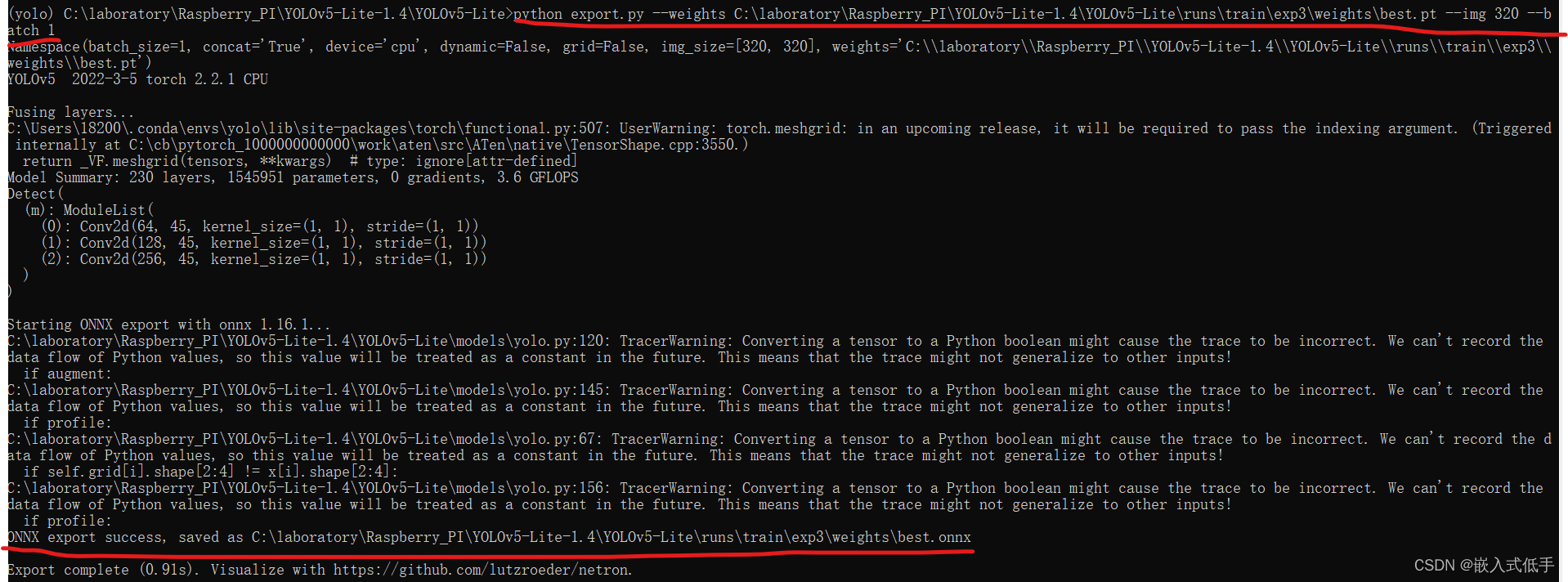
完成后会有提示,还会告诉你模型的导出路径,如果运行命令提示没有onnx库,使用pip下载
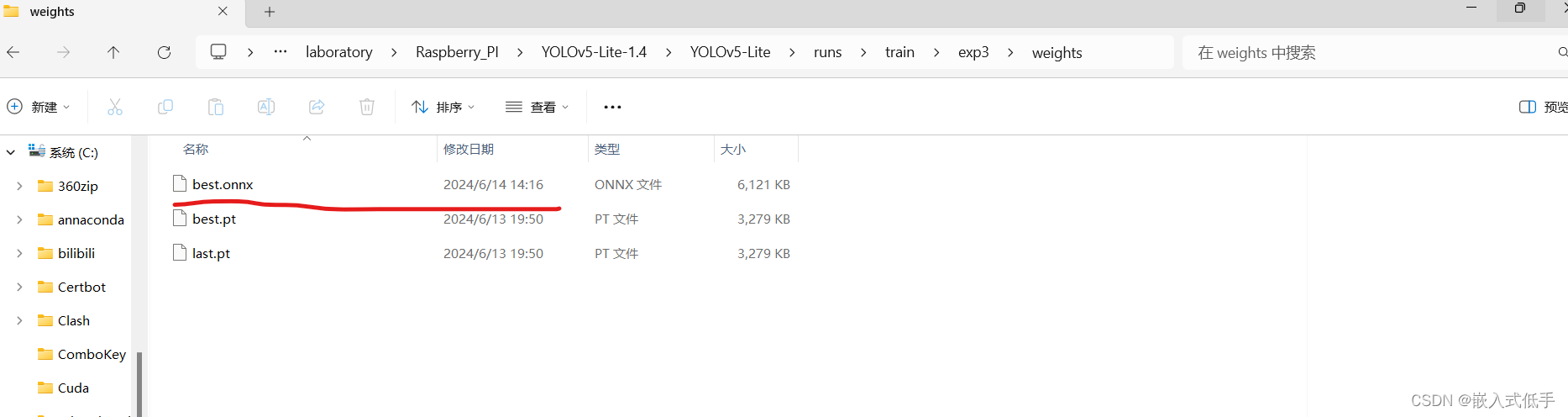
pip install onnx现在就可以看到转换好的模型了
2.把onnx模型从电脑传到树莓派
可以使用u盘传,也可以使用winSCP软件传,注意onnx的路径,最好你自己创建一个文件夹,和推理的代码放在同一个路径下面
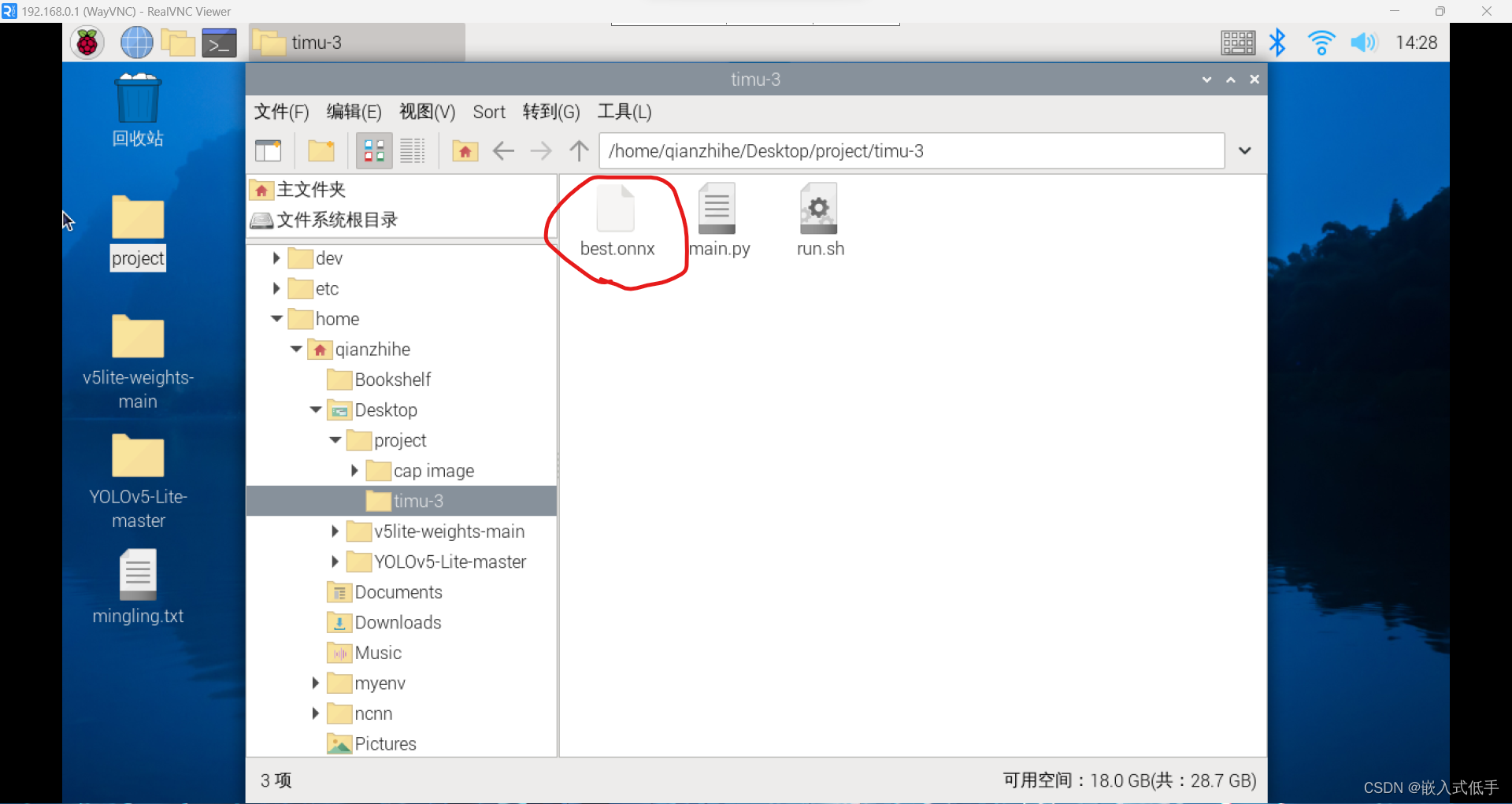
后面的mian.py是推理文件,run.sh是自启动文件,实现树莓派开机运行这个main.py的
3.安装树莓派运行onnx模型需要的依赖库
由于新版的树莓派系统为了避免pip下载器与自带下载器apt等起冲突,会强烈建议不要使用pip,所以这里建议在虚拟环境安装依赖库,注意pip换源
安装创建虚拟环境需要的库
# 安装python3-venv包
sudo apt-get install python3-venv创建虚拟环境
# 创建一个新的虚拟环境(yolo是虚拟环境名)
python3 -m venv yolo激活虚拟环境
source yolo/bin/activate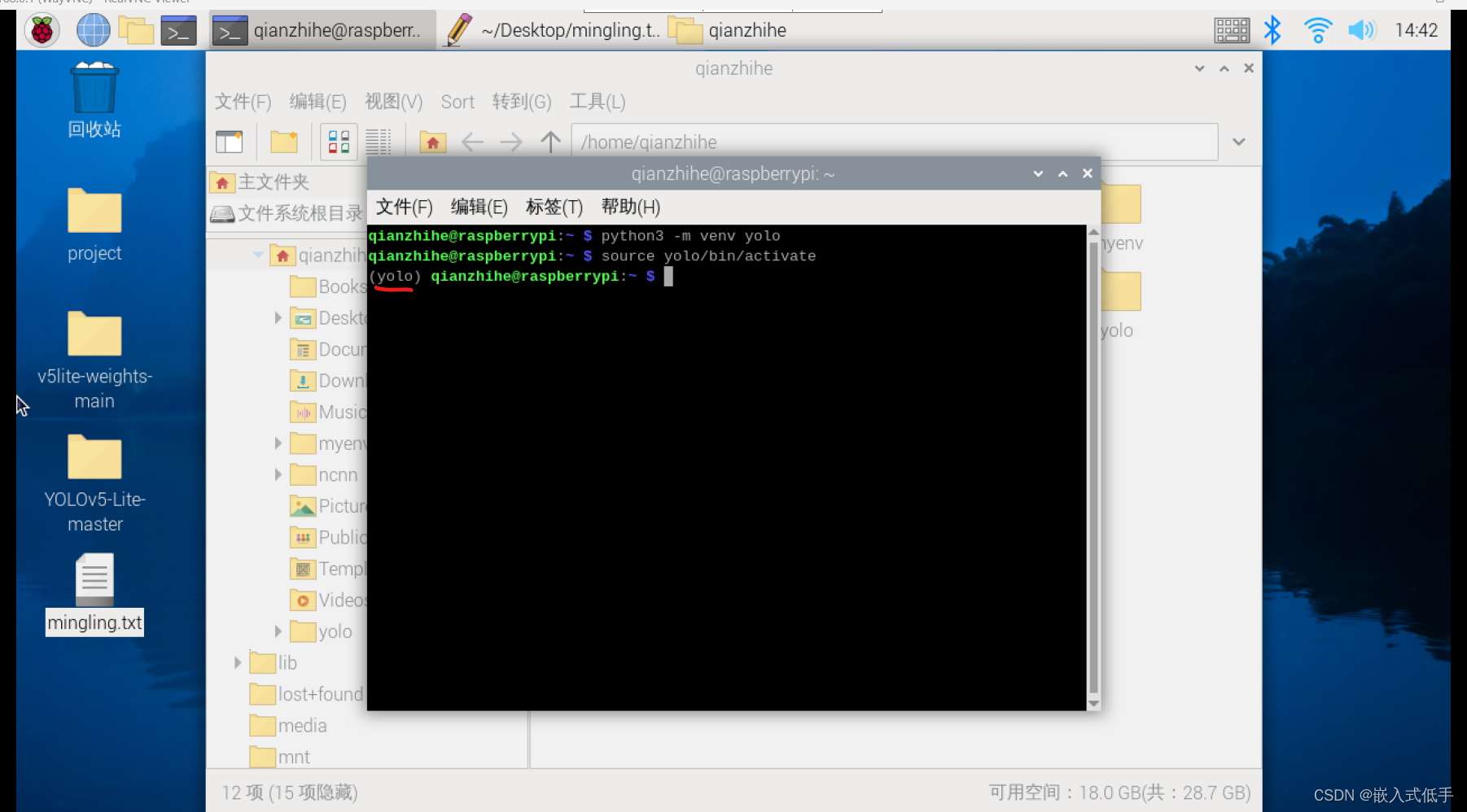
如果需要退出虚拟环境,可以运行命令
deactivate安装onnxruntime
pip3 install onnxruntime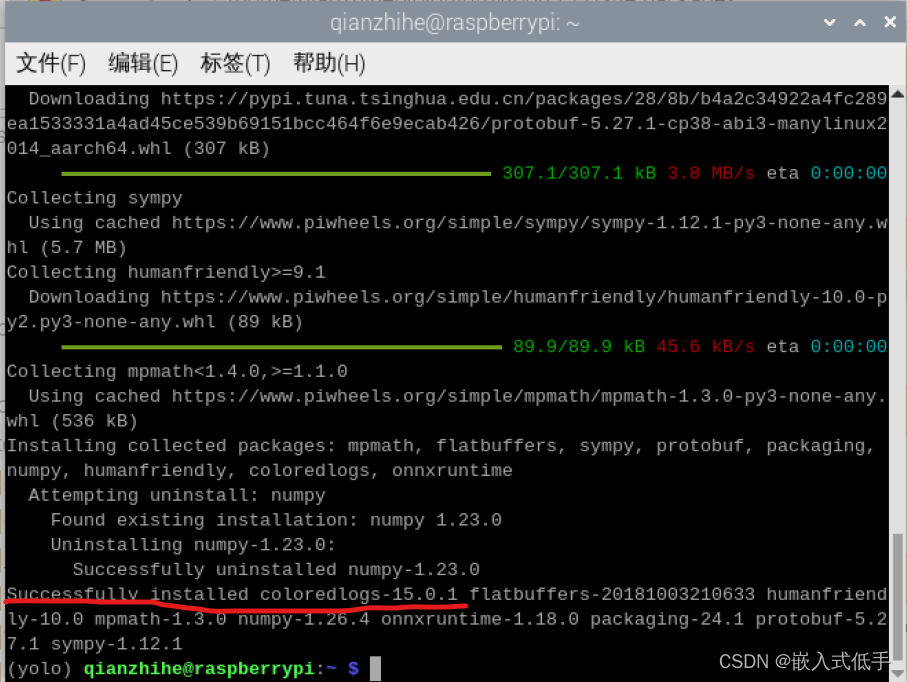
安装opencv库
运行命令
pip3 install opencv-python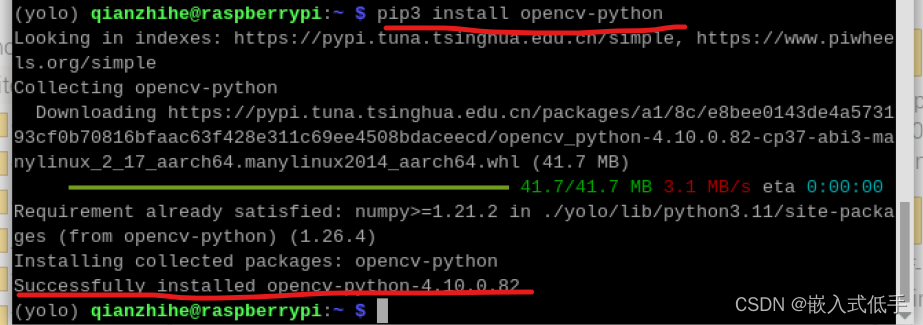
此时依赖库安装完成
4.修改推理代码
我先给出推理代码,是另一位大佬的,实测支持yolov5lite1.4版本,这也是建议下载1.4版本的原因,我之前用1.5版本的yolov5lite运行会出现返回shapes不匹配的问题
import cv2
import numpy as np
import onnxruntime as ort
import time
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
def _make_grid( nx, ny):
xv, yv = np.meshgrid(np.arange(ny), np.arange(nx))
return np.stack((xv, yv), 2).reshape((-1, 2)).astype(np.float32)
def cal_outputs(outs,nl,na,model_w,model_h,anchor_grid,stride):
row_ind = 0
grid = [np.zeros(1)] * nl
for i in range(nl):
h, w = int(model_w/ stride[i]), int(model_h / stride[i])
length = int(na * h * w)
if grid[i].shape[2:4] != (h, w):
grid[i] = _make_grid(w, h)
outs[row_ind:row_ind + length, 0:2] = (outs[row_ind:row_ind + length, 0:2] * 2. - 0.5 + np.tile(
grid[i], (na, 1))) * int(stride[i])
outs[row_ind:row_ind + length, 2:4] = (outs[row_ind:row_ind + length, 2:4] * 2) ** 2 * np.repeat(
anchor_grid[i], h * w, axis=0)
row_ind += length
return outs
def post_process_opencv(outputs,model_h,model_w,img_h,img_w,thred_nms,thred_cond):
conf = outputs[:,4].tolist()
c_x = outputs[:,0]/model_w*img_w
c_y = outputs[:,1]/model_h*img_h
w = outputs[:,2]/model_w*img_w
h = outputs[:,3]/model_h*img_h
p_cls = outputs[:,5:]
if len(p_cls.shape)==1:
p_cls = np.expand_dims(p_cls,1)
cls_id = np.argmax(p_cls,axis=1)
p_x1 = np.expand_dims(c_x-w/2,-1)
p_y1 = np.expand_dims(c_y-h/2,-1)
p_x2 = np.expand_dims(c_x+w/2,-1)
p_y2 = np.expand_dims(c_y+h/2,-1)
areas = np.concatenate((p_x1,p_y1,p_x2,p_y2),axis=-1)
areas = areas.tolist()
ids = cv2.dnn.NMSBoxes(areas,conf,thred_cond,thred_nms)
if len(ids)>0:
return np.array(areas)[ids],np.array(conf)[ids],cls_id[ids]
else:
return [],[],[]
def infer_img(img0,net,model_h,model_w,nl,na,stride,anchor_grid,thred_nms=0.4,thred_cond=0.5):
# 图像预处理
img = cv2.resize(img0, [model_w,model_h], interpolation=cv2.INTER_AREA)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
# 模型推理
outs = net.run(None, {net.get_inputs()[0].name: blob})[0].squeeze(axis=0)
# 输出坐标矫正
outs = cal_outputs(outs,nl,na,model_w,model_h,anchor_grid,stride)
# 检测框计算
img_h,img_w,_ = np.shape(img0)
boxes,confs,ids = post_process_opencv(outs,model_h,model_w,img_h,img_w,thred_nms,thred_cond)
return boxes,confs,ids
if __name__ == "__main__":
# 模型加载
model_pb_path = "best.onnx"
so = ort.SessionOptions()
net = ort.InferenceSession(model_pb_path, so)
# 标签字典
dic_labels= {0:'drug',
1:'glue',
2:'prime'}
# 模型参数
model_h = 320
model_w = 320
nl = 3
na = 3
stride=[8.,16.,32.]
anchors = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
anchor_grid = np.asarray(anchors, dtype=np.float32).reshape(nl, -1, 2)
video = 0
cap = cv2.VideoCapture(video)
flag_det = False
while True:
success, img0 = cap.read()
if success:
if flag_det:
t1 = time.time()
det_boxes,scores,ids = infer_img(img0,net,model_h,model_w,nl,na,stride,anchor_grid,thred_nms=0.4,thred_cond=0.5)
t2 = time.time()
for box,score,id in zip(det_boxes,scores,ids):
label = '%s:%.2f'%(dic_labels[id],score)
plot_one_box(box.astype(np.int16), img0, color=(255,0,0), label=label, line_thickness=None)
str_FPS = "FPS: %.2f"%(1./(t2-t1))
cv2.putText(img0,str_FPS,(50,50),cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),3)
cv2.imshow("video",img0)
key=cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key & 0xFF == ord('s'):
flag_det = not flag_det
print(flag_det)
cap.release() 模型需要修改的地方
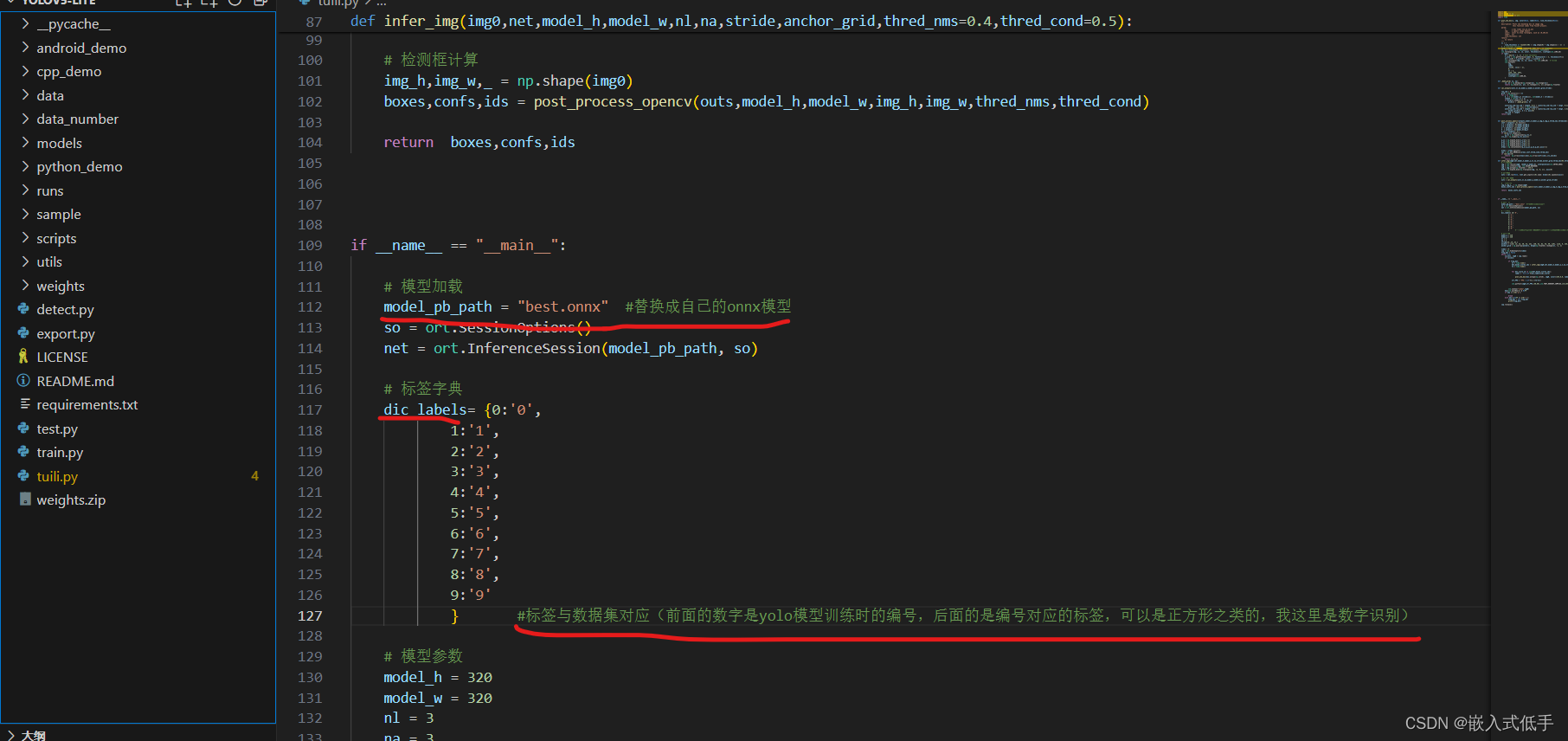
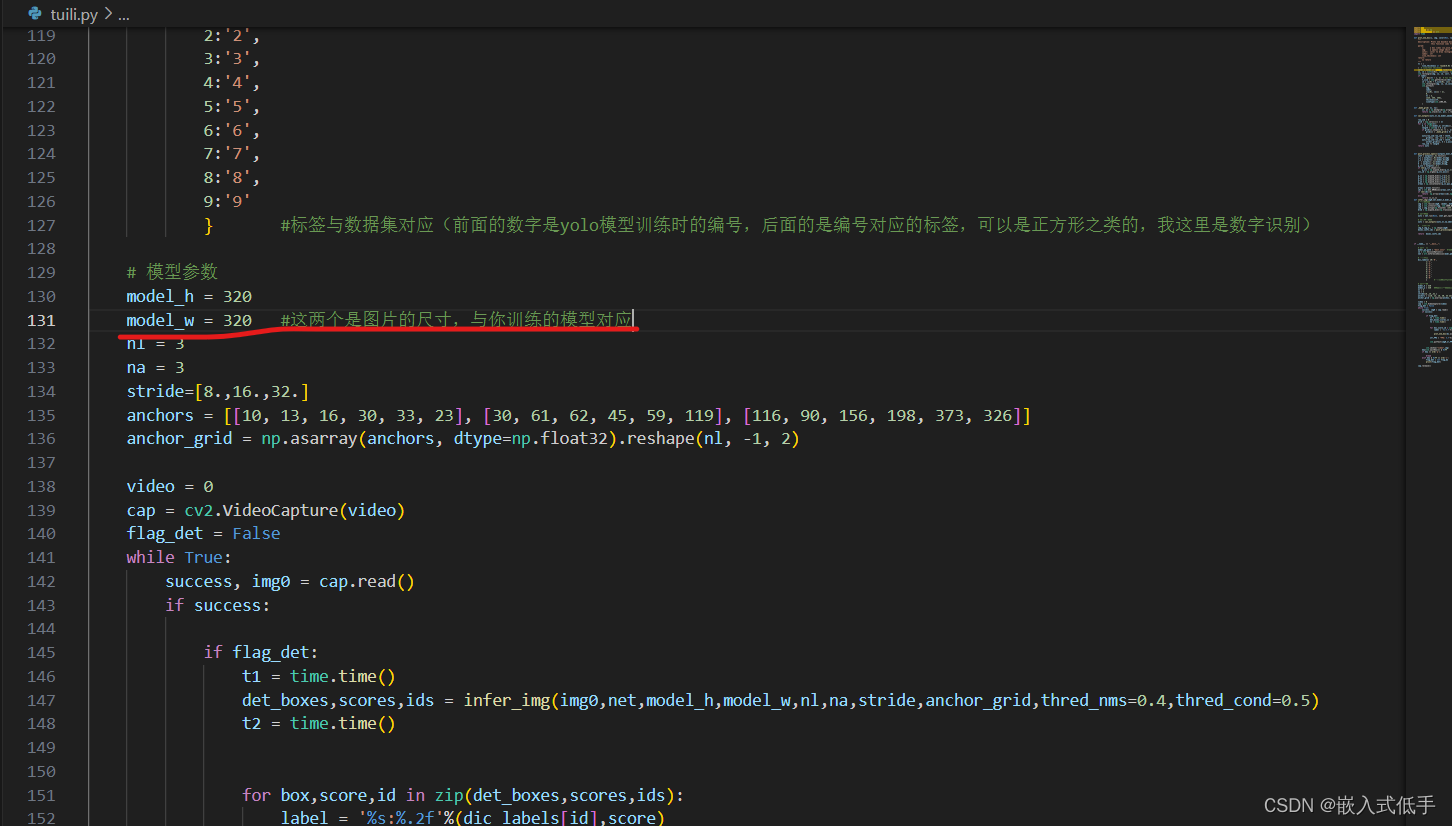
此时已经可以运行python文件了
5.运行代码
激活虚拟环境,如果激活不了就填写全部路径
source yolo/bin/activate进入推理代码的文件夹,替换成自己的路径
cd /home/qianzhihe/Desktop/project/timu-3最后,运行代码
python3 main.py四、效果

总结
现在也算是把电赛视觉的训练题跑通了,后面尝试优化一下,有缘再更

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









