






一.题目:
目前在我国水产养殖中,池塘养殖产量约占淡水养殖的70%。近年来,随着淡水生态系统水体污染和富营养化进程的加剧,经常导致有害蓝藻、轮虫等常见的浮游生物高密度发生,很容易诱发大面积水华。水华造成严重的环境污染及水体污染,对养殖业是一个严重的打击。
水华的发生不仅直接影响了养殖对象的正常生长发育,严重时大量排泄废水造成淡水资源污染,还会破坏养殖生态系统的平衡,导致养殖对象的不同程度死亡,造成巨大经济损失。为此我们通过研究淡水养殖池塘相关主要理化因子,主要浮游生物数据及鱼虾生成等数据分析水华发生的原因,控制并预测水华的发生,从而提高养殖产量,减小环境污染等。通过对水华发生的了解,加强大家环保意识。
根据附件1-8完成如下问题:
- 通过附件1中数据分析水体、底泥与间隙水中常见主要理化因子之间的关系,并分析原因。
- 通过附件2中数据对四个池塘水体质量进行评价及分类,分析虾池与鱼池对水体的影响。
- 建立主要理化因子和常见浮游生物致害密度发生关系的模型,给出水华发生时主要理化因子的范围,预测淡水养殖池塘水华发生 (1号池发生轻微水华)。
- 结合附件及以上分析,建立鱼类生长与体重相关模型。在养殖鲢鱼、鳙鱼等的生长过程中可以摄食浮游生物,净化某些藻类,构造一个与1号池相同大小的净化池,通过水循环,并放养鲢鱼或鳙鱼,放养多少才能净化1号池中的藻类,净化效果如何。
- 结合附件及通过查阅资料构建一种生态养殖模式,有利于池水养殖池塘水体的自净化。通过以上养殖从而使淡水养殖减少向江河湖海养殖废水排放。
二.第一问分析求解
1.题型分析:相关性分析
2.模型的选择:Pearson相关系数模型,典型相关分析
a.分析对象与指标的选取
间隙水:自由水,介于底泥和池水之间的水
---->分析垂直位置上相邻的池水与间隙水,底泥与间隙水之间理化因子的关系
理化因子:总磷、磷酸盐磷、 总氮、硝态氮、亚硝态氮、铵态氮
提取自附件一
Pearson相关系数模型
Pearson相关系数可以看作两个变量消除了量纲的影响,即将X,Y标准化之后的协方差
使用条件:
1.实验数据通常假设是成对的来自于正态分布的总体
2.实验数据之间的差异不能太大(Pearson系数受异常值影响非常大)
3.每组样本之间是独立抽样的
提示:使用Pearson系数之前一定要确定两个变量是呈线性关系的(画散点图或者折线图),如果两个变量本是是线性关系那么Pearson相关系数绝对值大的就是相关性强
步骤:1.数据描述性统计(数据最大最小值均值中位数等),可以使用Excel进行数据分析
2.判断数据是否具有线性关系(画出散点图或者折线图)
3.正态性检验:
大样本n>30时,使用正态分布JB检验
小样本3<n<=50时使用Shapiro-wilk夏皮洛-威尔克检验
4.计算Pearson相关系数和Pearson相关系数假设性检验(显著性检验)
斯皮尔曼和Pearson系数的选择
1.连续数据,正态分布,线性关系,数据之间差异不大(无异常值)---->使用Pearson相关系数
2.上述任一条件不满足---->使用spearman相关系数,不能用Pearson相关系数
b.
数据描述性统计:

画出折线图:
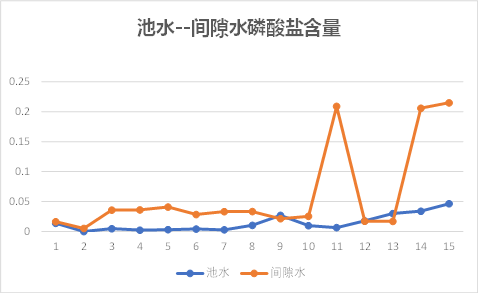
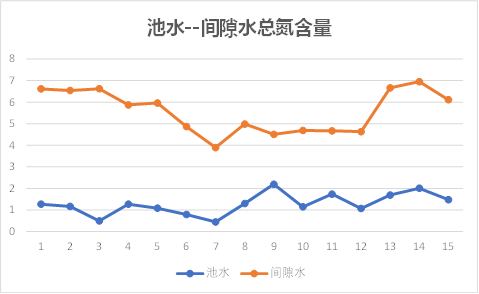
池水---间隙水
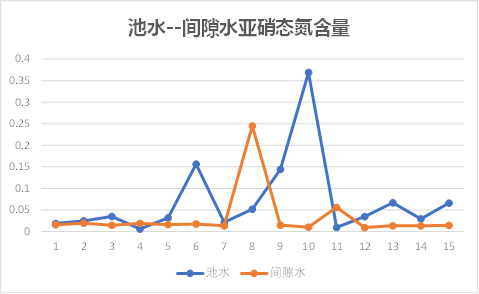
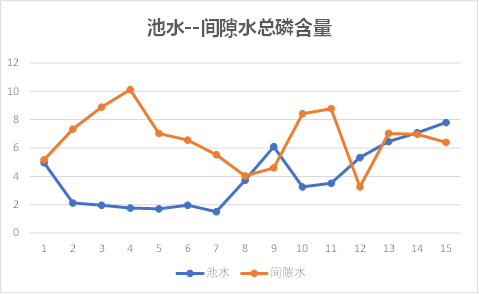
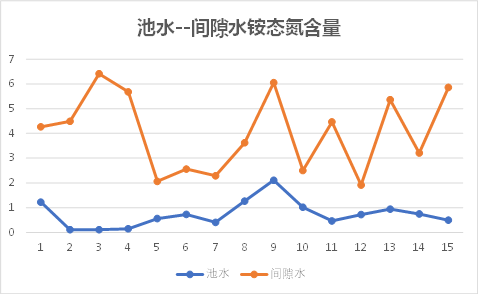
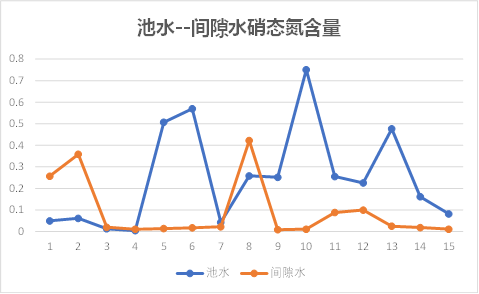
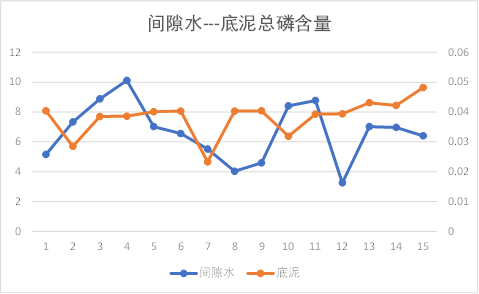
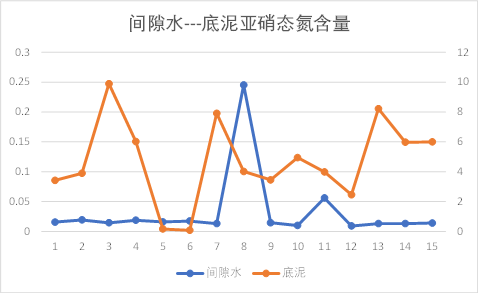
底泥---间隙水
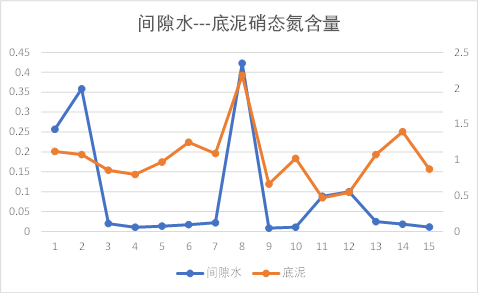
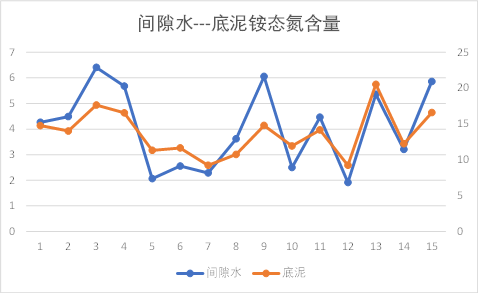
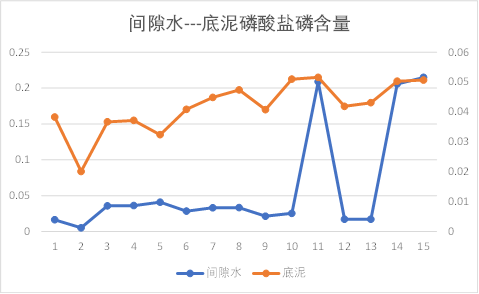
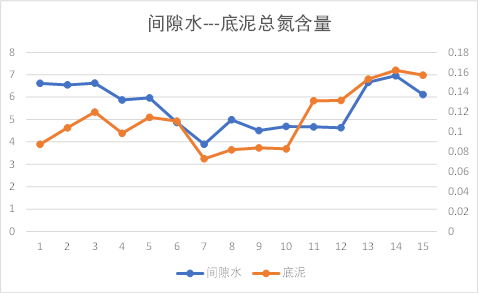
折线图分析:
观察上图可以发现,池水与间隙水之间的总磷、总氮含量有相同的趋势性,其他理化因子的关系无规则可循;
间隙水与底泥之间的理化因子除销态氮外,基本都有相同的趋势性。
因此初步知道间隙水与底泥之间理化因子相关性较大,池水与间隙水之间几乎没有关系。
正态分布检验:
H0(原假设):随机变量服从正态分布 H1(备择假设):随机变量不服从正态分布
池塘一A采样点:样本数15---->Shapiro-wilk检验P值进行正态性检验
检验方法:spss-->分析--描述统计--探索--图--含检验的正态图(勾选)
当检验结果显著性(P值)小于0.05时,拒绝原假设,数据不服从正态分布
当检验结果显著性(P值)大于0.05时,不能拒绝原假设,数据服从正态分布

使用SPSS软件对样本数据进行正态分布检验,发现P值大于0.05,所以接受原假设,样本数据服从正态分布
计算Pearson相关系数
Pearson 相关系数用来衡量两个数据集合是否在一条线上面,也就是衡量定距变量间的 线性关系。当两个变量都是正态连续变量,而且两者之间呈线性关系时,经常选用Pearson 相关系数刻画二者的相关程度。
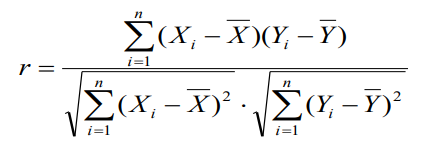
r 代表相关系数,n 为样本个数,Xi 与 Yi 分别表示第 i 个样本的两组属性值。
r = 1 时,称 X,Y 完全相关,此时 X,Y 之间具有线性函数关系;
r > 0.8 时称为高度相关;
r < 0.3 时称为低度相关,其它时候为中度相关。
计算相关系数
matlab代码:
R = corrcoef([data1,data2])
R(1:6, 7:12)
R = corrcoef([data2,data3])
R(1:6, 7:12)代码解释:
% 假设 pool_data 和 gap_data 是两组数据,每组有6个理化因子
% 每一列代表一个不同的理化因子
% 使用corrcoef计算相关系数矩阵
correlation_matrix = corrcoef([pool_data, gap_data]);
% correlation_matrix是一个12x12的矩阵,包含两组数据之间的相关系数
% correlation_matrix(1:6, 7:12) 包含了池水和间隙水中的理化因子之间的相关系数
结果:

Pearson相关系数假设检验(显著性检验)
1.为什么进行显著性检验:
因为相关系数通常是根据样本数据计算出来的,而样本一般是随机的,所以相关系数是一个随机变量,其取值具有一定的偶然性。
两个不相关的变量,根据样本计算的相关系数也可能较高,这在统计上称为虚假相关。要从样本相关系数判断总体中是否也有这样的关系,则需要对相关系数进行统计检验后才能得出结论。
显著系数p:p值即概率,反映某一事件发生的可能性大小。统计学根据显著性检验方法所得到的p 值,一般以p < 0.05 为有统计学差异,p<0.01 为有显著统计学差异,p<0.001为有极其显著的统计学差异
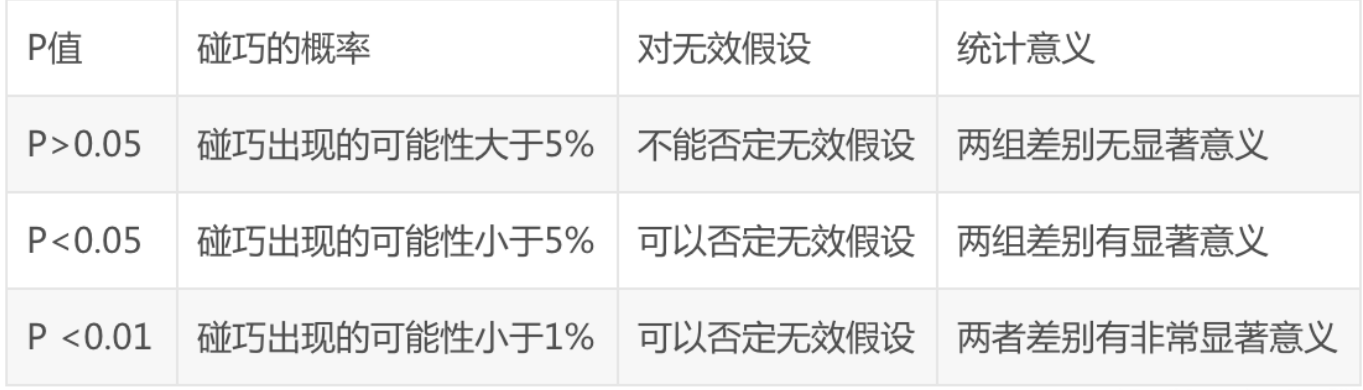
2.皮尔逊相关系数可以构建一个统计量t
其中n为样本的数量,r就是我们计算得到的皮尔逊相关系数,这个统计量被证明是符合自由度为t-2的t分布的。这里我们就可以使用t分布进行相关性的检验
公式:
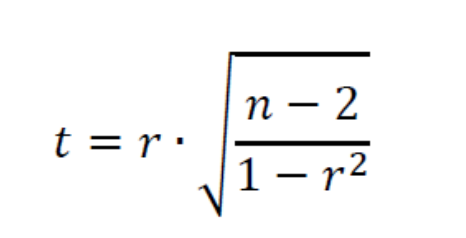
使用matlab计算
p = (1-tcdf(t,n-2))*2 %双侧需要乘2
另一种方法求P(推荐)
[R,P] = corrcoef([data2,data3])
P_need = P(1:6, 7:12)
P_need< 0.01 % 标记3颗星的位置
(P_need < 0.05) .* (P_need > 0.01) % 标记2颗星的位置
(P_need < 0.1) .* (P_need > 0.05)P返回的就是每个相关系数对应的显著性检验结果
P<0.01: ***在0.01水平上显著(双尾)
0.01<P<0.05:**在0.05水平上显著(双尾)
0.05<P<0.1: *在0.1水平上显著(双尾)
双尾:两侧拒绝域
求解结果:
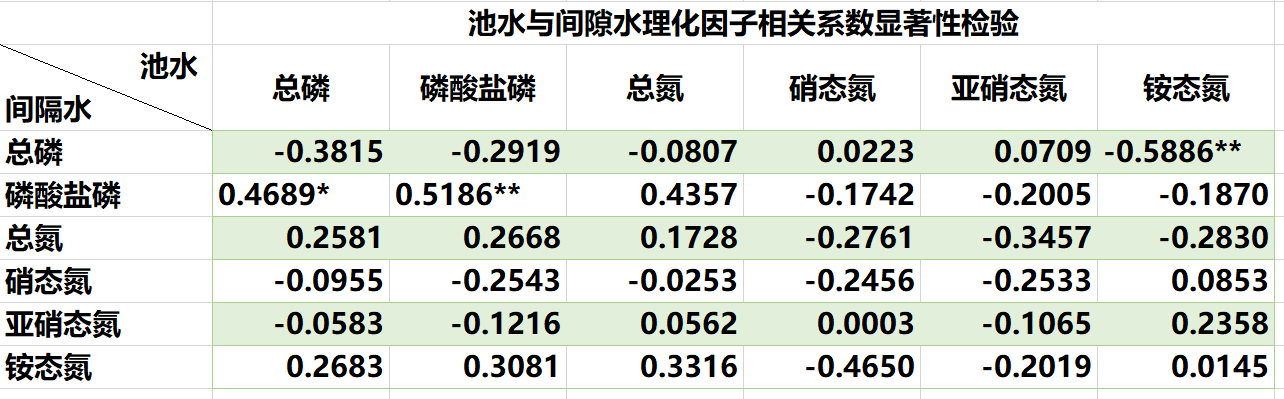
注:***为在 0.01 水平上显著(双尾),**为在 0.05 水平上显著(双尾),*为在 0.1 水平上显著(双尾)。
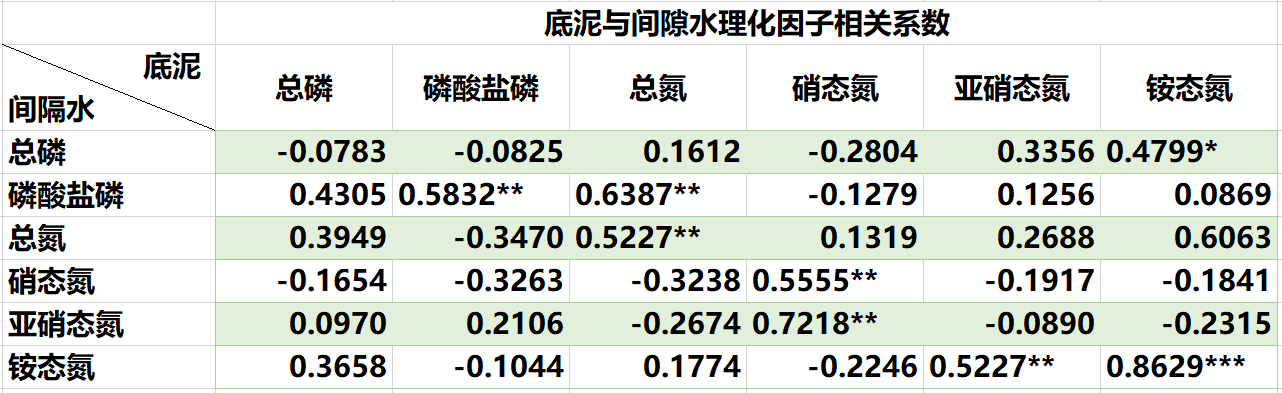
注:***为在 0.01 水平上显著(双尾),**为在 0.05 水平上显著(双尾),*为在 0.1 水平上显著(双尾)。
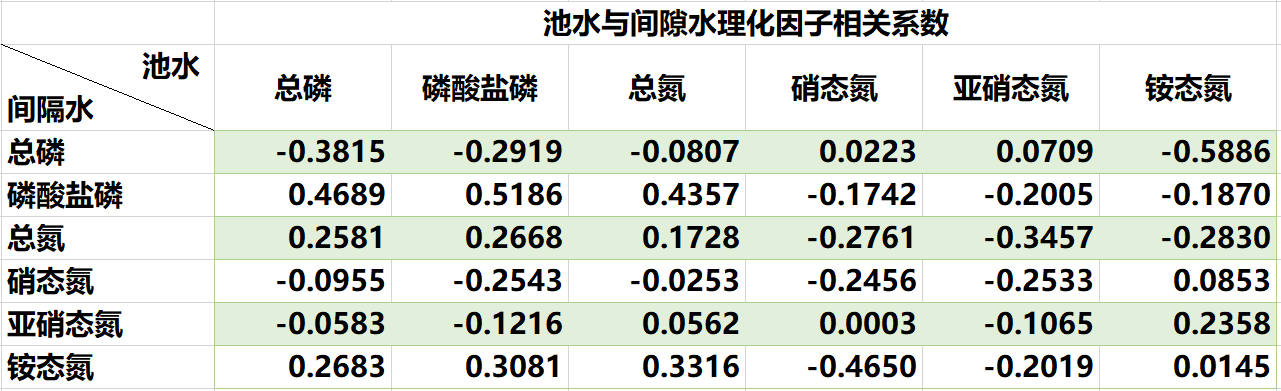
从以上两表中可以看出
池水与间隙水两者之间的理化因子相关性不高
底泥与间隙水的磷酸盐磷,总氮,硝态氮,亚硝态氮,铵态氮之间都具有显著的相关性
铵态氮还达到了高度相关,因此可以知道底泥与间隙水之间的理化因子相关性较大
池水与间隙水之间的理化因子几乎没有关系
总结:给定的样本数据可能是不相关的,求得的Pearson相关系数就可能是虚假相关,要进行显著性检验才能确定最终相关关系,进行相关性的分析时一定要配合散点图,否则是无效的
典型相关分析
没学呢哈哈哈
第二问分析求解
第二问问题:通过附件2中数据对四个池塘水体质量进行评价及分类,分析虾池与鱼池对水体的影响。
1.题型分析:评价类问题
2.模型选择:基于熵权法的Topsis模型
a.分析对象以及指标的选取:
问题二要求我们分别对四个池塘水体质量进行评价,分析虾池与鱼池对水体质量的影响。
水质的指标分为物理指标、化学指标和生物指标三大类。
根据题目所给出的数据我们可将指标进行分类,其中
物理指标有:温度和透明度:
化学指标有:H 值、COD、溶氧值、盐度、总碱度、总氮、总磷、钙离子、镁离子和氯离子:
生物指标有:轮虫、叶绿体和生物量。

我们首先粗略地根据《地表水环境质量标准 GB3838-2002》2对这四个池塘的指标进行分析,进行大致评价。
附件1中数据: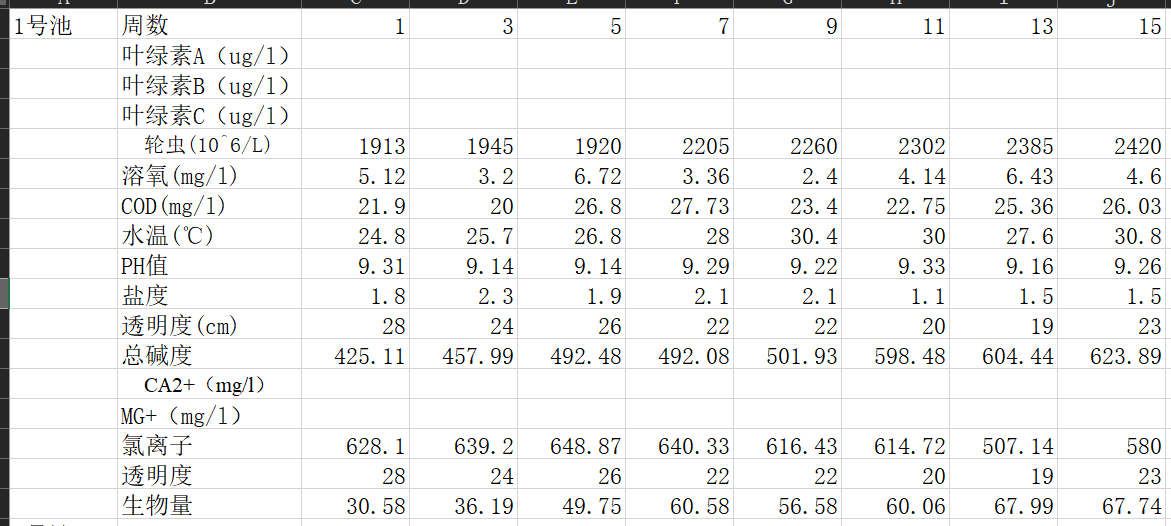
发现缺少双周的数据(考虑使用三次埃尔米特插值)
将表中数据插入matlab中
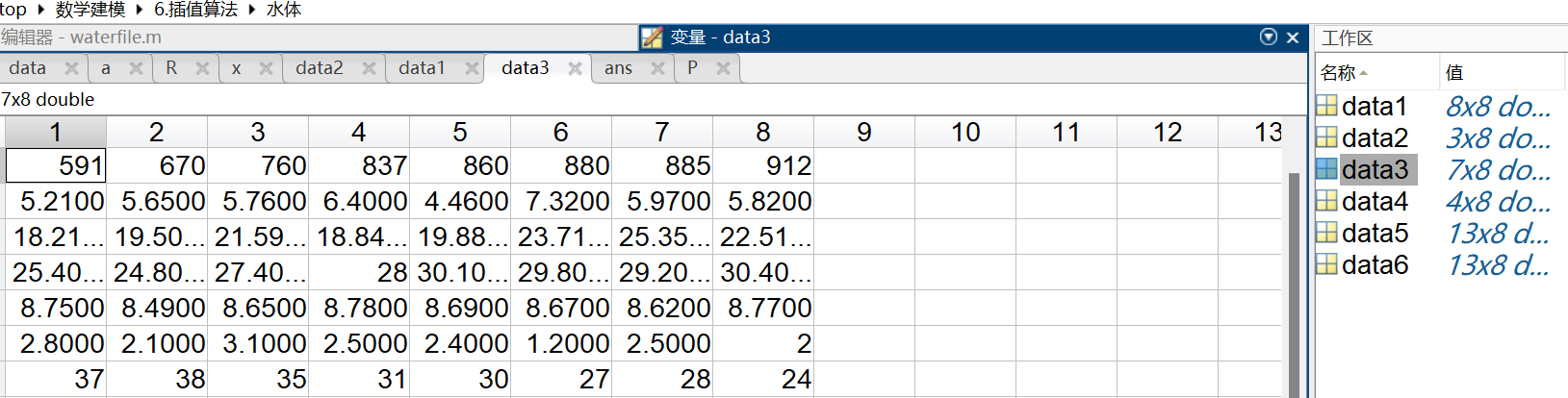
matlab代码
x = 1:2:15;
y1 = data1;
y2 = data2;
y3 = data3;
y4 = data4;
y5 = data5;
y6 = data6;
new_x = 1:1:15;
p1 = spline(x,y1,new_x)
p2 = spline(x,y2,new_x)
p3 = spline(x,y3,new_x)
p4 = spline(x,y4,new_x)
p5 = spline(x,y5,new_x)
p6 = spline(x,y6,new_x) 插值结果:
插值结果:
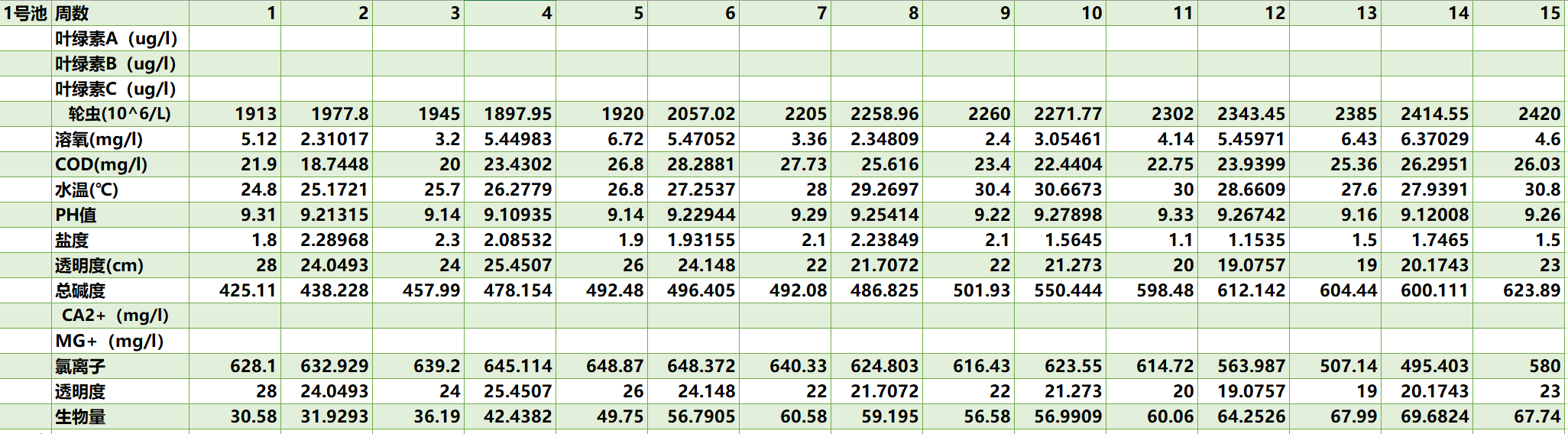
基于熵权法的Topsis模型
TOPSIS 法别名优劣解距离法,其主要利用数据的信息,精确的反应评价方案之间的优劣差距。TOPSIS 法多用于解决多指标的决策性问题,其实现原理为通过计算各备选方案与正负理想解之间的相对距离来进行排序并做出选择
一.步骤
1.将原始矩阵正向化
%正向化
[n,m] = size(data)
disp(['There are ' num2str(n) ' evaluation objects and ' num2str(m) '' ...
' evaluation indicators']);
a = input("the"+num2str(m)+"number of the evaluation index " + ...
"needs to be forward-treated:0 or1:")
if a==1
Position = input("Please enter the column of the metric that" + ...
" needs forward processing," + ...
" for example, columns 1,2,3 need to be processed, " + ...
"then enter [1,2,3]:")
disp("Enter the type of metric you want to process these columns " + ...
"(1: Very Small, 2: Intermediate, 3: Interval")
Type = input("Enter the type according to the list")
for i = 1:size(Position,2)
data(:,Position(i)) = Positivization(data(:,Position(i)),Type(i))
end
disp("Forward matrix:")
disp(data)
end%正向化函数
function[data] =Positivization(data,type)
if type ==1
disp("Extremely small")
data = abs(data-max(data))
elseif type ==2
disp("Intermediate")
data_best = input("enter the best value:")
Max = max(abs(data-data_best))
data = 1-abs(data-data_best)./Max
else
disp("Interval type")
lowest = input("lowest:")
highest = input("highest:")
Max_Interval = max([lowest-min(data),max(data)-highest])
for i = 1:size(data)
if data(i)<lowest
data(i) = 1-(lowest-data(i))/Max_Interval
elseif lowest<=data(i)&&data(i)<=highest
data(i) = 1
else
data(i) = 1-(data(i)-highest)/Max_Interval
end
end
end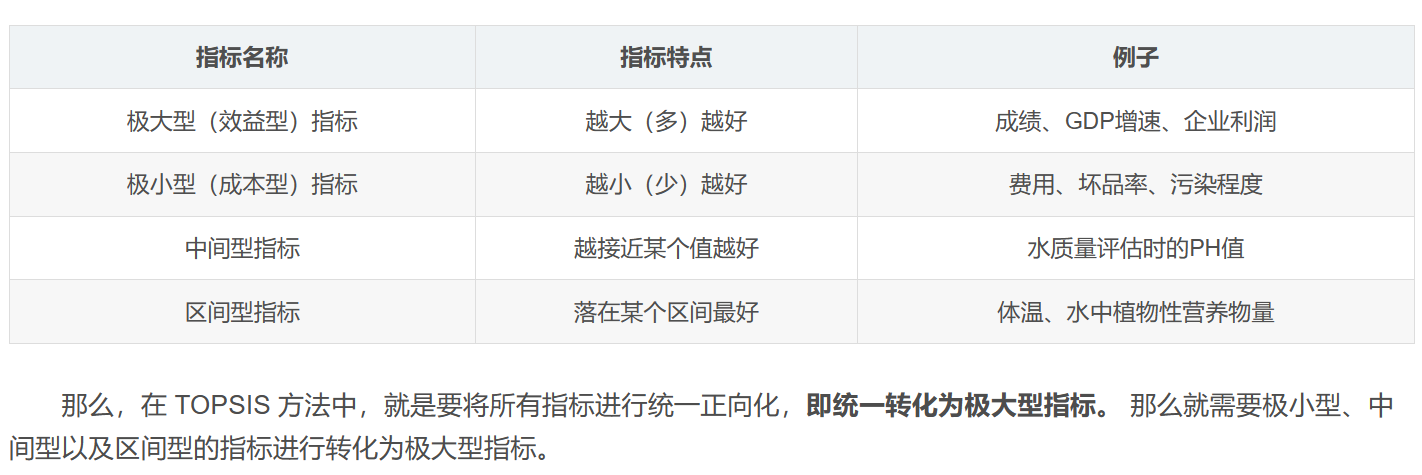
2.正向化矩阵标准化
消除量纲的影响
%%正向化--->标准化
[n,m] = size(data);
% 标准化矩阵
standardization_matrix = data./repmat(sum(data.*data).^0.5,n,1);
disp("standardization_matrix:")
disp(standardization_matrix)3.计算权重
a.计算概率
b.计算信息熵
c.计算信息效用值
d.归一化得到熵权
%熵权法
weight_number = Weight(standardization_matrix)% 熵权法
function[final_result] = Weight(standardization_matrix)
[n,m] = size(standardization_matrix);
%计算概率
probability = standardization_matrix./(repmat(sum(standardization_matrix,1),n,1))
%计算信息熵
%消除ln0
for i = 1:m
for j = 1:n
if probability(j,i) == 0
probability(:,i) = probability(:,i)+0.001;
end
end
end
result = probability.*log(probability)
Information_entropy = (sum(result,1)./(repmat(log(n),1,m)))*(-1)
%信息效用值
Information_utility_value = 1-Information_entropy;
%归一化得到熵权
number = repmat(sum(Information_utility_value,2),1,m);
final_result = Information_utility_value./number
%topsis默认权重都相同,所以可以使用熵权法计算权重加入计算中4.计算得分归一化
%%评分--->套用评分公式
%计算最大最小距离
max_distance = sum(weight_number.*((repmat(max(standardization_matrix,[],1),n,1) ...
-standardization_matrix).^2),2).^0.5;
min_distance = sum(weight_number.*((repmat(min(standardization_matrix,[],1),n,1) ...
-standardization_matrix).^2),2).^0.5;
Score = min_distance./(min_distance+max_distance);
%归一化
Normalization = Score/sum(Score)
[SA,index] = sort(Normalization,"descend")5.根据得分进行排序
我们用 Topsis 算法进行评价前必须先确定各指标的权重。淡水养殖池塘水质的影 响因素很多,对于一个评价系统而言,不能面面俱到地对每一个因素进行评价。所以我 们通过专家评分的方法来确定对池塘水质进行总体评价的指标体系。在专家的指导下选 择 14 个因素,并通过专家对这 14 个因素的重要程度进行排序来获得主要因素
以下表格在淡水养殖池塘水质评价指标体系研究 - 中国知网中获取
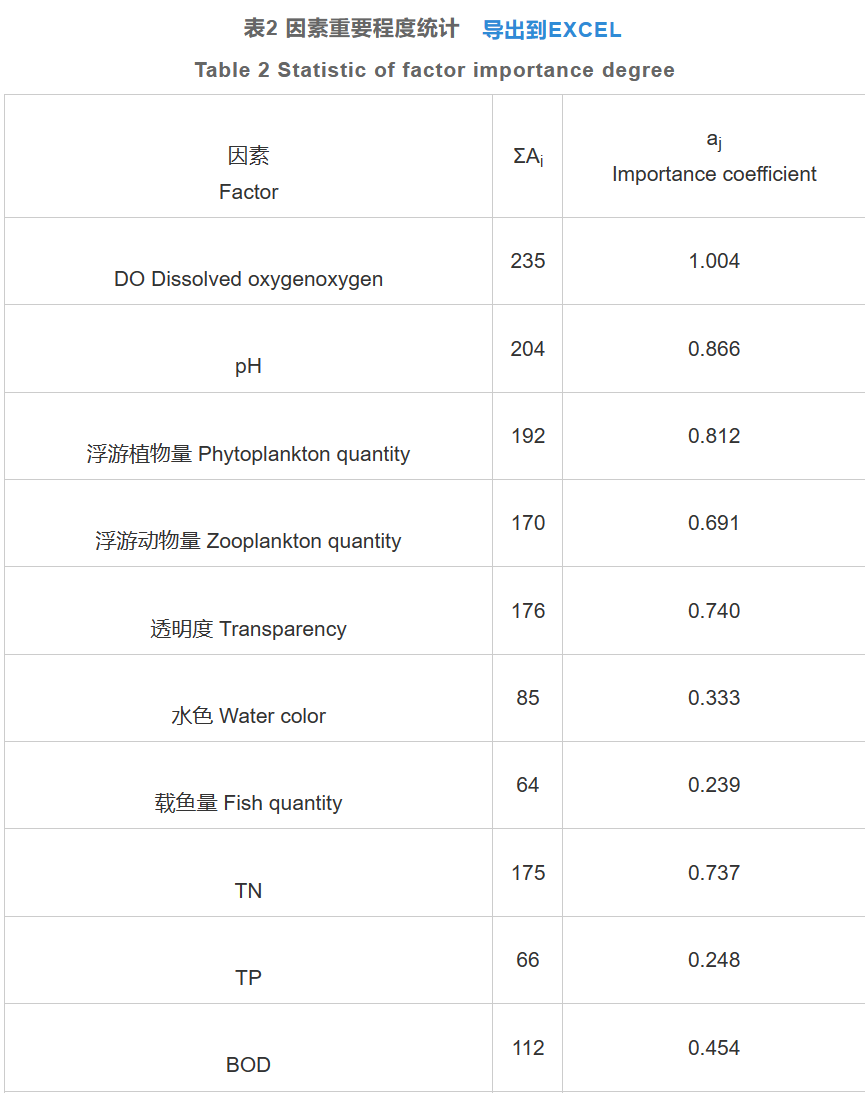
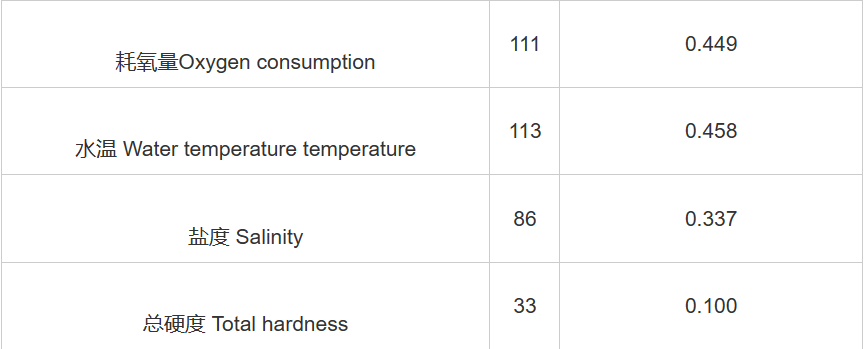 因素重要程度模糊子集:A=(1.004,0.866,0.812,0.691,0.740,0.333,0.239,0.737,0.248,0.454,0.449,0.458,0.337,0.100)
因素重要程度模糊子集:A=(1.004,0.866,0.812,0.691,0.740,0.333,0.239,0.737,0.248,0.454,0.449,0.458,0.337,0.100)
我们采用重要程度大的 5 个因素作为评价指标,即溶解氧、pH、浮游 植物量、透明度和氮。
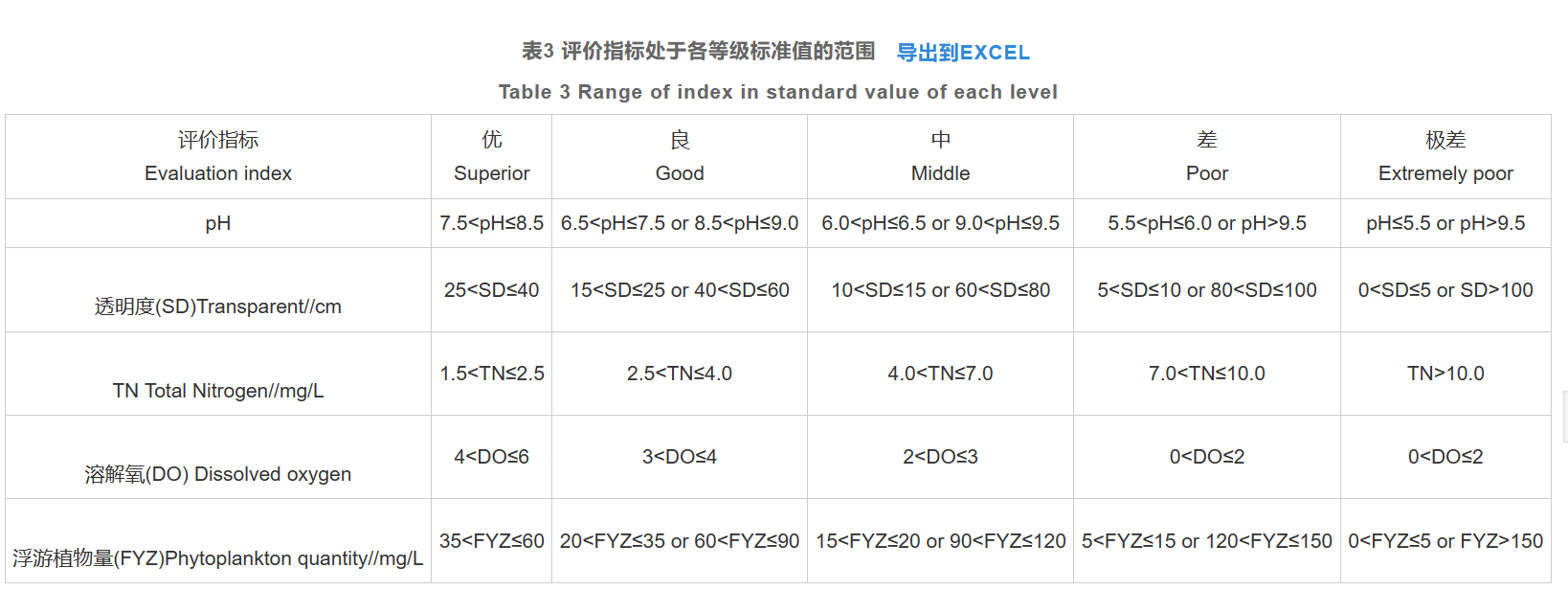
五个指标均是区间型指标



















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











