







K近邻(K-Nearest Neighbors,简称KNN)算法是一种常用的分类和回归算法
- knn算法原理
当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
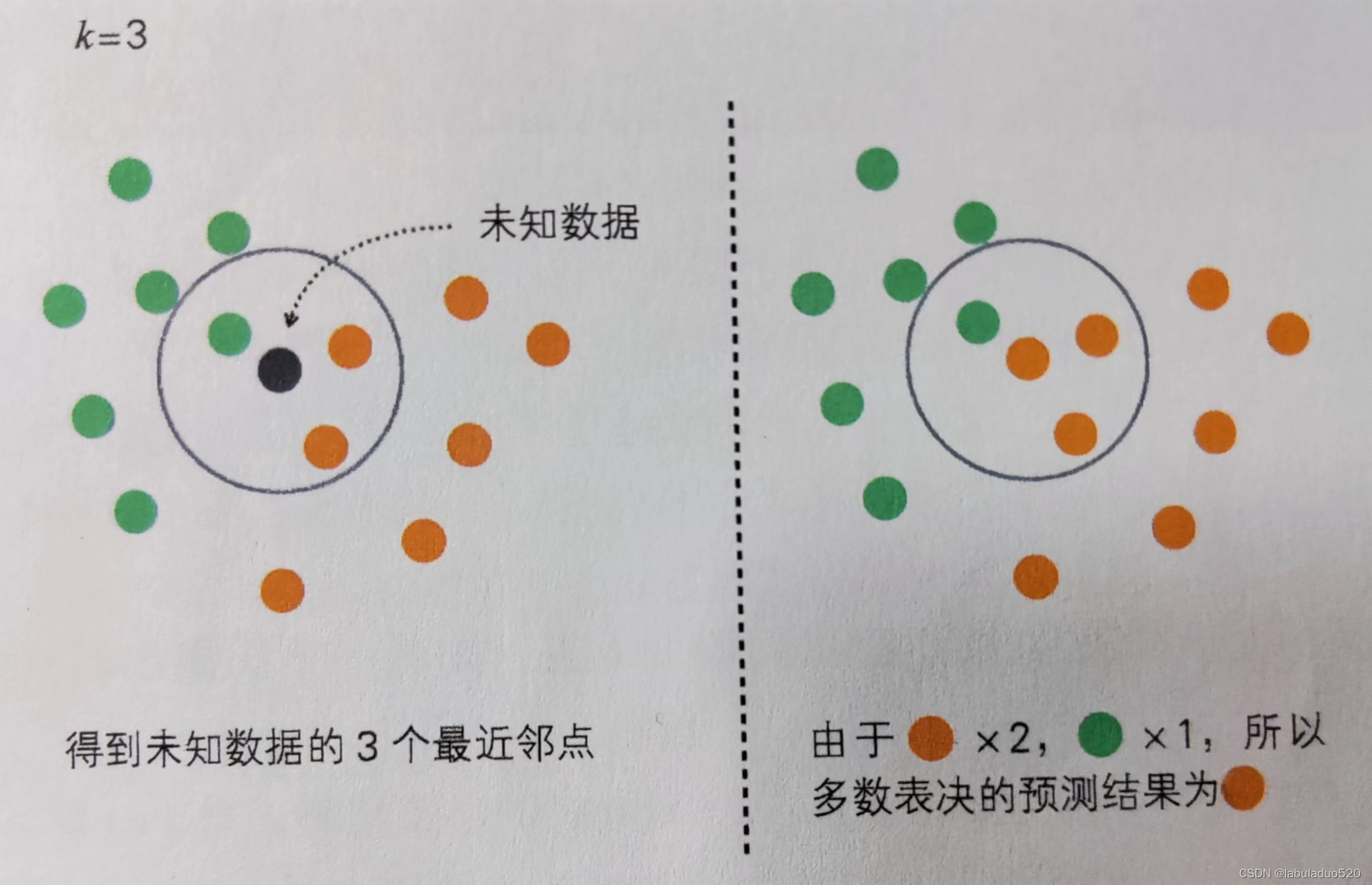
注:通过多数表决进行分类
- 距离计算
要度量空间中点与点之间的距离,有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离计算等。不过通常KNN算法中使用的是欧式距离。
以二维平面为例:
1、曼哈顿距离:
2、欧氏距离:
欧氏距离其实就是我们高中时所学的两点之间距离的计算公式
- 代码实现
1、基于sklearn中的鸢尾花数据集手写knn算法
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 定义KNN算法类
class KNN:
# KNN算法初始化
def __init__(self, n_neighbors=5):
self.n_neighbors = n_neighbors
def fit(self, X, y):
self.X = X
self.y = y
def euclidean_distance(self, x1, x2):
return np.sqrt(np.sum((x1 - x2) ** 2)) # 两个向量
def predict(self, X_test):
y_pred = []
for test_sample in X_test:
distances = [self.euclidean_distance(test_sample, x) for x in self.X]
nearest_indices:numpy.ndarray = np.argsort(distances)[:self.n_neighbors] # 排序
nearest_labels = self.y[nearest_indices]
unique_labels, counts = np.unique(nearest_labels, return_counts=True)# 返回值是一个包含两个数组的元组,第一个数组是唯一的标签值,第二个数组是对应每个唯一标签值的计数
predicted_label = unique_labels[np.argmax(counts)] # np.argmax(counts)返回数组中最大元素的索引
y_pred.append(predicted_label)
return np.array(y_pred) # 将预测结果转换为数组并返回
# 加载鸢尾花数据集
iris = load_iris()
x = iris.data
y = iris.target
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=100)
# 实例化KNN算法类
knn = KNN(n_neighbors=5)
# 将训练集送入knn算法
knn.fit(x_train, y_train)
# 预测测试集
y_pred = knn.predict(x_test)
# 预测结果展示
labels = ["山鸢尾","虹膜锦葵","变色鸢尾"]
for i in range(len(y_pred)):
print("第%d次测试:\t预测值:%s\t\t真实值:%s"%((i+1),labels[y_pred[i]],labels[y_test[i]]))
# 计算准确率
# accuracy_score()函数位于sklearn.metrics模块中,属于Scikit-learn库的一部分
accuracy = accuracy_score(y_test, y_pred) # accuracy_score()函数会比较真实标签值和预测标签值,并计算出准确分类的样本数占总样本数的比例,即准确率。
print("准确率:", accuracy)运行结果:
第1次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第2次测试: 预测值:山鸢尾 真实值:山鸢尾
第3次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第4次测试: 预测值:山鸢尾 真实值:山鸢尾
第5次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第6次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第7次测试: 预测值:山鸢尾 真实值:山鸢尾
第8次测试: 预测值:山鸢尾 真实值:山鸢尾
第9次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第10次测试: 预测值:山鸢尾 真实值:山鸢尾
第11次测试: 预测值:山鸢尾 真实值:山鸢尾
第12次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第13次测试: 预测值:山鸢尾 真实值:山鸢尾
第14次测试: 预测值:山鸢尾 真实值:山鸢尾
第15次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第16次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第17次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第18次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第19次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第20次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第21次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第22次测试: 预测值:山鸢尾 真实值:山鸢尾
第23次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第24次测试: 预测值:山鸢尾 真实值:山鸢尾
第25次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第26次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第27次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第28次测试: 预测值:山鸢尾 真实值:山鸢尾
第29次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第30次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第31次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第32次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第33次测试: 预测值:虹膜锦葵 真实值:变色鸢尾
第34次测试: 预测值:山鸢尾 真实值:山鸢尾
第35次测试: 预测值:山鸢尾 真实值:山鸢尾
第36次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第37次测试: 预测值:山鸢尾 真实值:山鸢尾
第38次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第39次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第40次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第41次测试: 预测值:山鸢尾 真实值:山鸢尾
第42次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第43次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第44次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第45次测试: 预测值:山鸢尾 真实值:山鸢尾
准确率: 0.97777777777777772、基于sklearn中的鸢尾花数据集掉包实现knn算法
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
import random
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"]=["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"]=False
"""
利用KNN算法对鸢尾花进行分类
"""
# 获取鸢尾花数据 三个类别(山鸢尾/0,虹膜锦葵/1,变色鸢尾/2),每个类别50个样本,每个样本四个特征值(萼片长度,萼片宽度,花瓣长度,花瓣宽度)
def get_iris_data():
iris = load_iris()
iris_data = iris.data # 特征值
iris_target = iris.target # 目标值(类别)
return iris_data, iris_target
def run():
# 1.获取鸢尾花的特征值,目标值
iris_data, iris_target = get_iris_data()
# 2.将数据分割成训练集和测试集 test_size=0.25表示将25%的数据用作测试集,random_state不同的随机种子会在数据集中抽取不同的20%作为测试集
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.3,random_state=100)
# x_train:训练集特征值,x_test:测试集特征值,y_train:训练集目标值,y_test:测试集目标值
# 4.knn算法
knn = KNeighborsClassifier(n_neighbors=5) # 创建一个KNN分类器,n_neighbors默认为5,后续通过网格搜索获取最优参数
knn.fit(x_train, y_train) # 将测试集送入算法
y_predict = knn.predict(x_test) # 获取预测结果
print(f"预测结果:{y_predict}")
# 预测结果展示
labels = ["山鸢尾","虹膜锦葵","变色鸢尾"]
for i in range(len(y_predict)):
print("第%d次测试:\t预测值:%s\t\t真实值:%s"%((i+1),labels[y_predict[i]],labels[y_test[i]]))
print("准确率:",knn.score(x_test, y_test))
get_iris_data()
run()
'''
运行结果:
预测结果:[2 0 2 0 2 2 0 0 2 0 0 2 0 0 2 1 1 1 2 2 2 0 2 0 1 2 1 0 1 2 1 1 1 0 0 1 0
1 2 2 0 1 2 2 0]
第1次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第2次测试: 预测值:山鸢尾 真实值:山鸢尾
第3次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第4次测试: 预测值:山鸢尾 真实值:山鸢尾
第5次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第6次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第7次测试: 预测值:山鸢尾 真实值:山鸢尾
第8次测试: 预测值:山鸢尾 真实值:山鸢尾
第9次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第10次测试: 预测值:山鸢尾 真实值:山鸢尾
第11次测试: 预测值:山鸢尾 真实值:山鸢尾
第12次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第13次测试: 预测值:山鸢尾 真实值:山鸢尾
第14次测试: 预测值:山鸢尾 真实值:山鸢尾
第15次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第16次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第17次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第18次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第19次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第20次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第21次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第22次测试: 预测值:山鸢尾 真实值:山鸢尾
第23次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第24次测试: 预测值:山鸢尾 真实值:山鸢尾
第25次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第26次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第27次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第28次测试: 预测值:山鸢尾 真实值:山鸢尾
第29次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第30次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第31次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第32次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第33次测试: 预测值:虹膜锦葵 真实值:变色鸢尾
第34次测试: 预测值:山鸢尾 真实值:山鸢尾
第35次测试: 预测值:山鸢尾 真实值:山鸢尾
第36次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第37次测试: 预测值:山鸢尾 真实值:山鸢尾
第38次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第39次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第40次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第41次测试: 预测值:山鸢尾 真实值:山鸢尾
第42次测试: 预测值:虹膜锦葵 真实值:虹膜锦葵
第43次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第44次测试: 预测值:变色鸢尾 真实值:变色鸢尾
第45次测试: 预测值:山鸢尾 真实值:山鸢尾
准确率: 0.9777777777777777
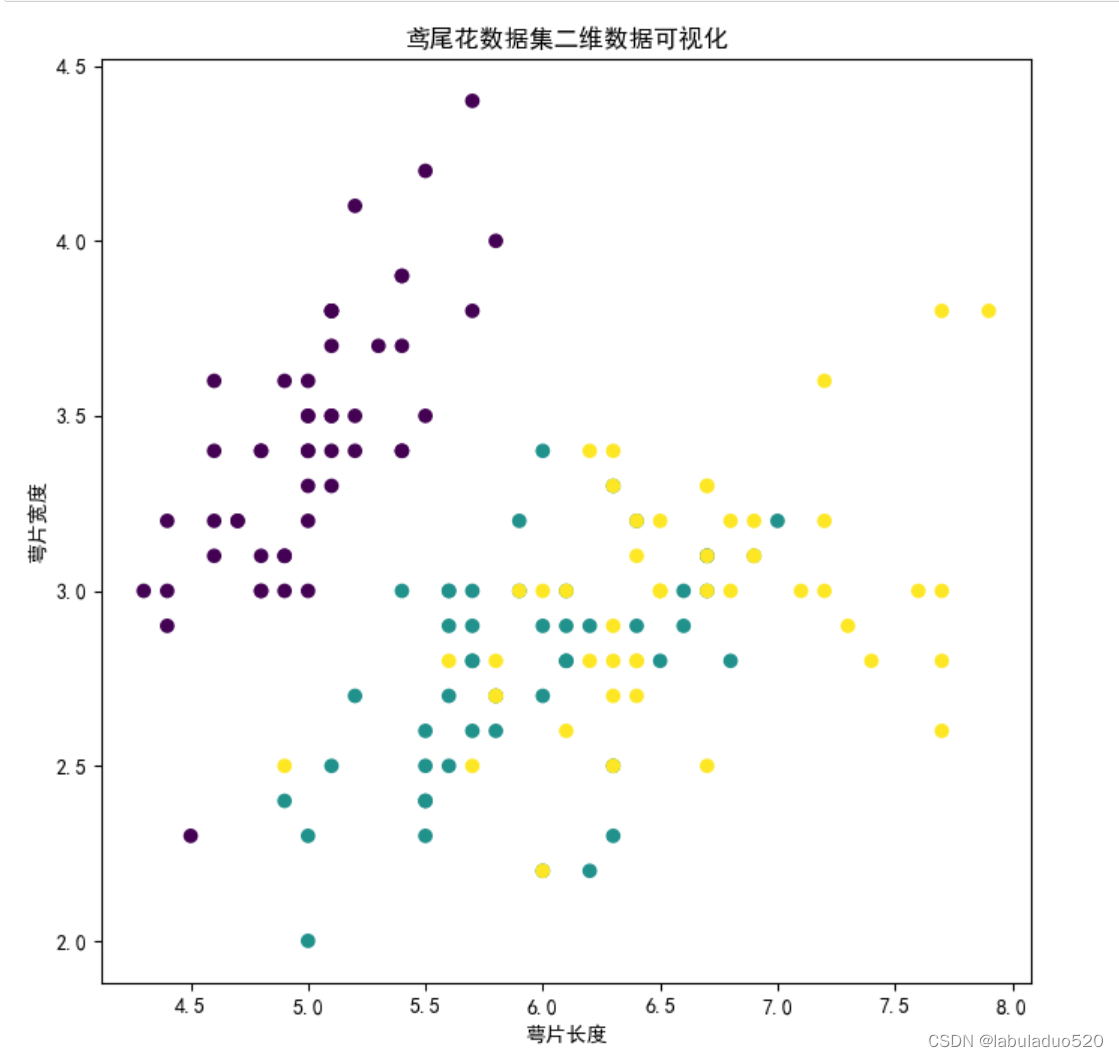
'''3、基于sklearn中的鸢尾花数据集掉包实现二维数据可视化
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
import random
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"]=["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"]=False
# 获取鸢尾花数据集
iris = load_iris()
x = iris.data[:, :2] # 只使用前两个特征
y = iris.target
# 定义KNN分类器
knn = KNeighborsClassifier(n_neighbors=5)
# 将数据集送入算法
knn.fit(x, y)
# 可视化数据集
plt.figure(figsize=(8,8),dpi=100) # 创建画布
'''
x[:, 0]表示取特征矩阵x的所有行的第一个特征(萼片长度),
x[:, 1]表示取特征矩阵x的所有行的第二个特征(萼片宽度)。
'''
plt.scatter(x[:, 0], x[:, 1], c=y) # 绘制图像 , cmap='coolwarm'
plt.xlabel('萼片长度') # 修改x轴显示
plt.ylabel('萼片宽度') # 修改y轴显示
plt.title('鸢尾花数据集二维数据可视化') # 添加标题
# plt.grid(linestyle='--',alpha=0.5) # 添加网格
plt.show()运行结果:
4、基于sklearn中的鸢尾花数据集掉包实现k折交叉验证
k折交叉验证(k-fold cross-validation)是一种常用的模型评估方法,用于评估机器学习模型的性能和泛化能力。它的步骤如下:
①将原始数据集分成k个大小相等的子集(折),其中k-1个子集作为训练集,剩下的1个子集作为验证集。
② 对于每个子集,使用其余的k-1个子集作为训练集来训练模型,然后使用该子集作为验证集来评估模型的性能。
③ 重复步骤2,直到每个子集都充当过一次验证集。
④ 计算k次验证结果的平均值作为模型的性能评估指标。
k折交叉验证的优点:
① 更准确的模型评估:通过对数据集进行多次划分和验证,可以更准确地评估模型的性能和泛化能力。
②充分利用数据:k折交叉验证允许每个样本都充当过训练集和验证集,充分利用了数据集的信息。
k折交叉验证的缺点:
① 计算开销较大:进行k次模型训练和验证比单次训练和验证更加耗时。
② 可能引入一定的方差:由于每次划分的训练集和验证集不同,模型的性能评估结果可能存在一定的方差。
k折交叉验证是一种常用的模型评估方法,可以帮助选择合适的模型和调优模型的参数,提高模型的泛化能力。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV,cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
import random
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"]=["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"]=False
# 获取鸢尾花数据集
iris = load_iris()
x = iris.data
y = iris.target
# 创建KNN分类器
knn = KNeighborsClassifier(n_neighbors=5)
# 使用交叉验证评估模型性能
'''
cross_val_score函数用于评估模型在不同训练集上的性能,它会将数据集分成多个子集(称为折),然后在每个子集上进行训练和测试。
cross_val_score函数会返回一个数组,其中包含每个子集的评估结果
'''
scores = cross_val_score(knn, x, y, cv=5) # 5折交叉验证
# 输出每次交叉验证的准确率
print("每次交叉验证的准确率:", scores)
# 输出平均准确率和标准差
print("平均准确率:", np.mean(scores))
print("准确率标准差:", np.std(scores))
'''
运行结果:
每次交叉验证的准确率: [0.96666667 1. 0.93333333 0.96666667 1. ]
平均准确率: 0.9733333333333334
准确率标准差: 0.02494438257849294
'''- 优缺点分析
优点:
1. 简单直观:KNN算法的思想简单明了,易于理解和实现。
2. 无需训练过程:KNN是一种基于实例的学习方法,不需要显式地进行训练,而是根据训练数据集直接进行预测。
3. 对数据分布没有假设:KNN算法对数据分布没有假设,适用于各种类型的数据。
4. 可以进行多分类:KNN算法可以处理多分类问题,并且在类别不平衡的情况下也能有效工作。
缺点:
1. 计算复杂度高:KNN算法需要计算测试样本和所有训练样本之间的距离,当样本规模较大时,计算复杂度较高。
2. 存储开销大:KNN算法需要保存所有的训练样本,对内存要求较高。
3. 预测速度慢:由于需要计算距离并比较所有训练样本,KNN算法的预测速度相对较慢。
4. 对异常值敏感:KNN算法对异常值敏感,如果训练集中有噪声或异常值,可能会对预测结果产生较大影响。
5. 需要确定K值:KNN算法中的K值需要人为设定,选择不当可能导致预测结果不准确。
总的来说,KNN算法是一种简单易懂、灵活、适用于多分类问题的算法,但在计算和存储开销、预测速度等方面存在一些缺点。















 3207
3207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









