






A.5.1 实验目的
加深对指令级并行性及其开发的理解。
加深对Tomasulo算法的理解。
掌握Tomasulo算法在指令流出、执行、写结果各阶段对浮点操作指令以及load和store指令进行什么处理。
掌握采用了Tomasulo算法的浮点处理部件的结构。
掌握保留站的结构。
给定被执行代码片段,对于具体某个时钟周期,能够写出保留站、指令状态表以及浮点寄存器状态表内容的变化情况。
A.5.2 实验平台
实验平台采用Tomasulo算法模拟器。
环境的建立:见A.0。
A.5.3 实验内容及步骤
首先要掌握Tomasulo模拟器的使用方法。(见使用说明:点击模拟器中标题右侧的小圈)
1. 假设浮点功能部件的延迟时间为加减法2个时钟周期,乘法10个时钟周期,除法40个时钟周期,Load部件2个时钟周期。
(1)对于下面的代码段,给出当指令MUL.D即将确认时,保留站、load缓冲器以及寄存器状态表中的内容。
L.D F6, 24(R2)
L.D F2, 12(R3)
MUL.D F0, F2, F4
SUB.D F8, F6, F2
DIV.D F10, F0, F6
ADD.D F6, F8, F2
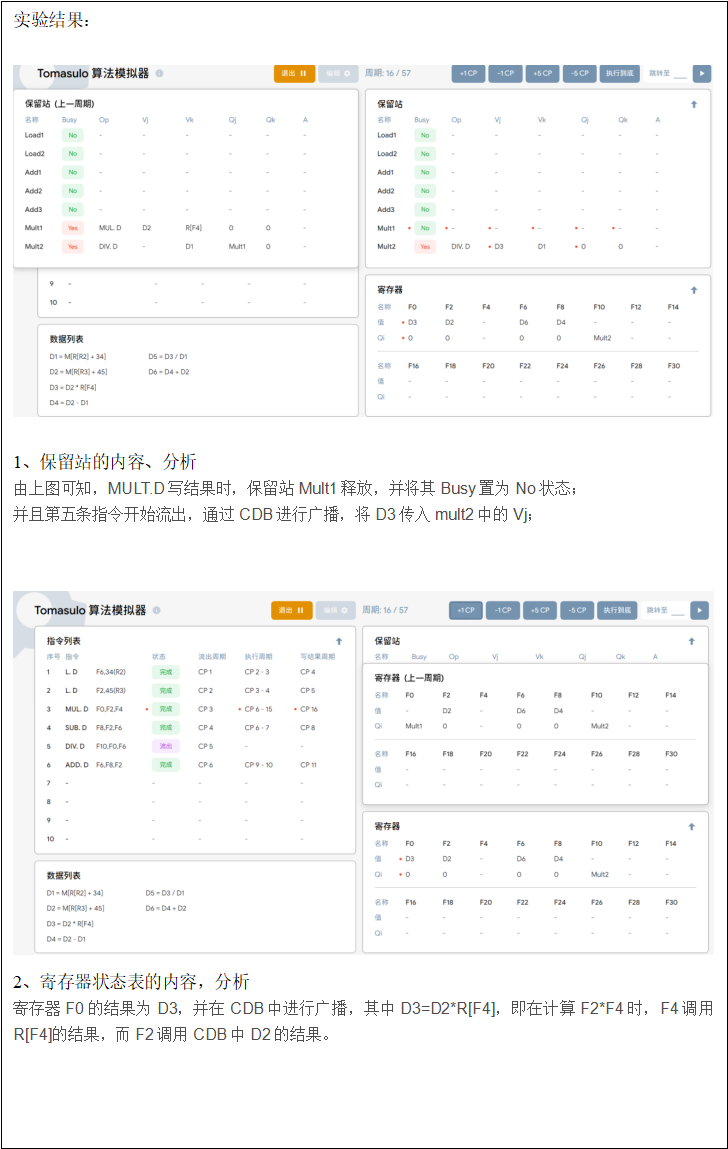
按步进方式执行上述代码,利用模拟器的“向上箭头”(鼠标摸上去)的对比显示功能,观察每一个时钟周期前后各信息表中内容的变化情况。
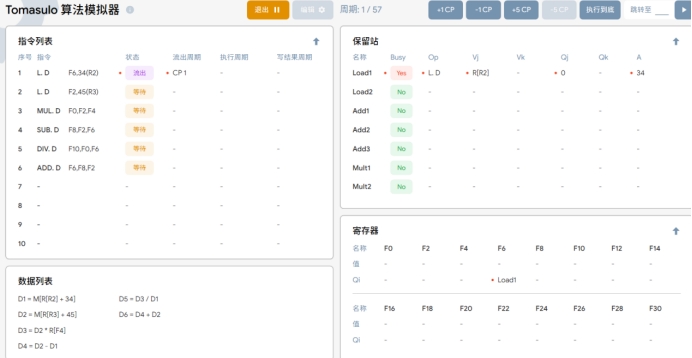
TI:当执行指令LDF6,34(R2)时,将地址偏移量为34的数据从内存加载到LOAD 部件的LOAD1中,并将LOAD1的值存储到寄存器字段F6中。
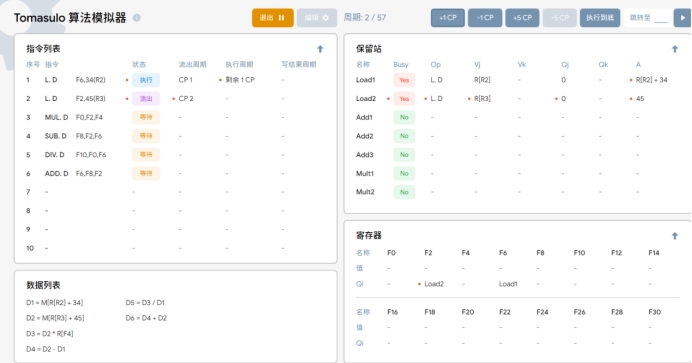
T2:执行指令 L.DF2,45(R3),将地址偏移量为45的数据加载到LOAD部件的LOAD2
中,并将LOAD2的值存储到寄存器字段F2中。与此同时,第一条指令LDF6,34(R2)开始执行,在其执行过程中,将LOAD1上的绝对地址写入。
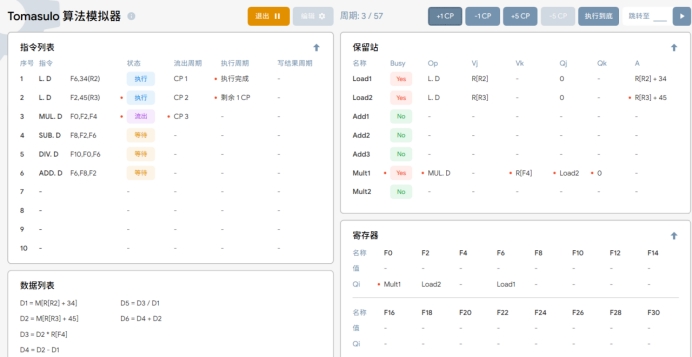
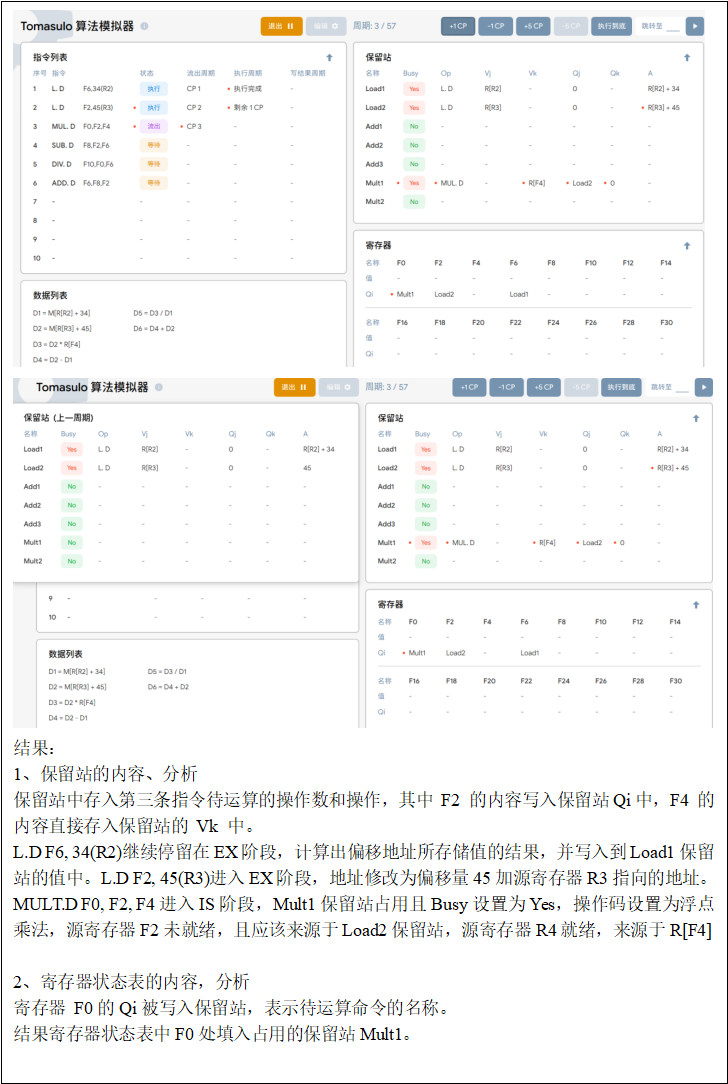
T3:执行第三条指令 MUL.D F0,F2,F4 ,同时进行以下操作:
1.该指令被取出并进入流出阶段。
2 第一条指令 LDF6,34(R2)已完成取值,并在下一个时钟周期准备写入寄存器F6
3. 第二条指令LD F2,45(R3)开始执行,LOAD2 上写入绝对地址。
4. 保留站中存入第三条指令待运算的操作数和操作,其中 F2 的内容写入保留站的
Qi中,F4 的内容直接存入保留站的 Vk 中。
寄存器 F0的Qi被写入保留站,表示待运算命令的名称。
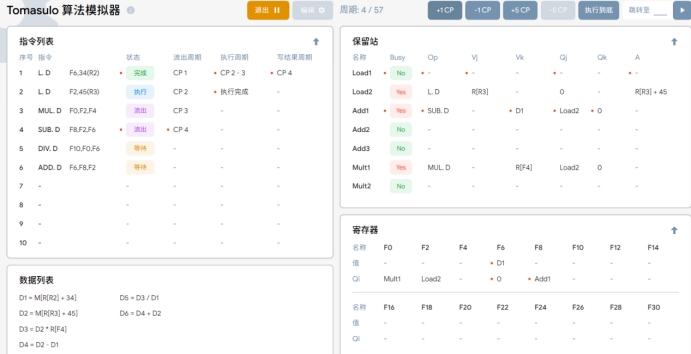
T4:在执行第四条指令 SUB.D F8,F6,F2 的同时,执行以下操作:
1. 第二条指令 LDF2,45(R3)执行完成,同时第一条指令 L.D F6,24(R2)完成写入结果D1到寄存器表F6中的值,并在指令状态表中的第一条指令填入写结果周期CP4.
2. 保留站中存入第四条指令的待运算操作数和操作。其中,F6的值为D 1,因此存入Vk;F2 是等待Load 的值,所以存入 Qj中表示等待中;同时,寄存器表中F8的Qi存入将要给它赋值的指令名称Add1。
Load 部件中的LOAD1行被清空。
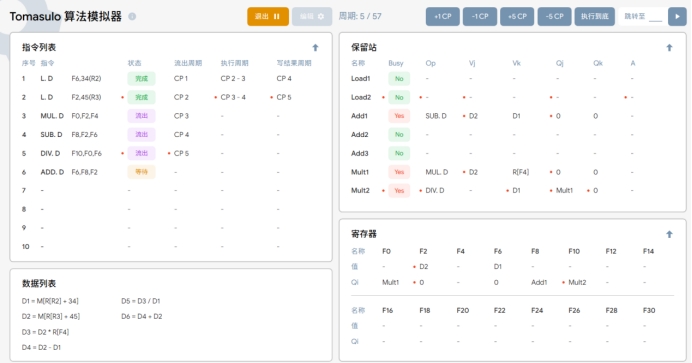
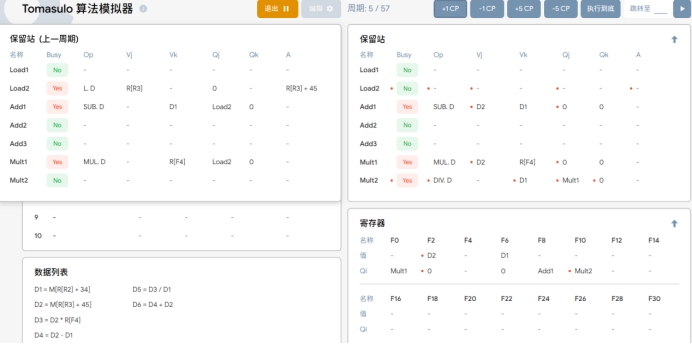
T5:在执行周期5时:
1.第五条指令 DIV.D F10,F0,F6 被取出进入流出阶段。
2 第二条指令 L.D F2,45(R3)写入结果 D2 到寄存器 F2的值中,Load 部件表中LOAD2 行被清空。
3.由于 F2 的值 D2 已经准备好,因此在保留站中,第三行的Qj 转为 Vj 为D2,同理第六行。
4.保留站中存入第五条指令的待运算操作数和操作。因为F0需要Mult1 的值,所以保留站最后一行 Qi先填入对应寄存器指令名称。
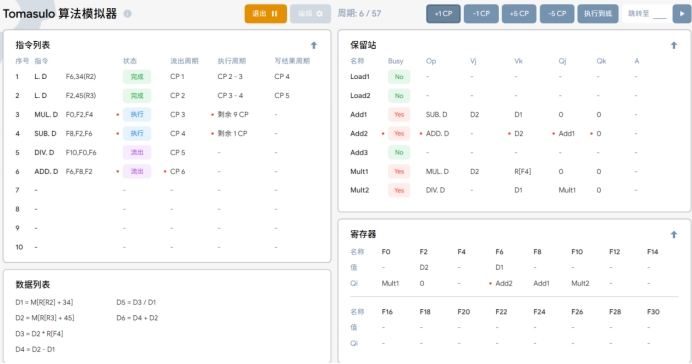
T6:在执行周期6时,执行以下操作:
1、取出第六条指令 ADD.D F6,F8,F2进到流出阶段;
2. 由于所需数据已经在之前的周期中写回结果。第三条和第四条指今在第六个周期开始执行,并在指令状态中更新。
3、 相关的操作数和操作特被存入保留站。由于F8的结果正在由SUB.D 执行,所以 Qi 先写为 SUB所在的保留站Add1,同时在寄存器表中F6(第六条指令将要写入的寄存器)的 Qi 被更改为指令执行的保留站号Add2.
4. 由于 SUB.D和 MUL.D 都已经取到值了,可以开始执行了。
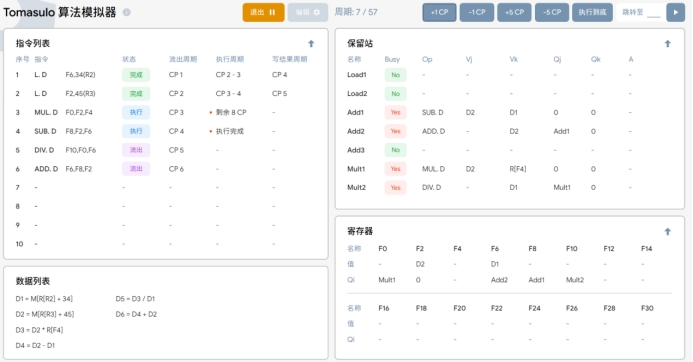
T7:在执行周期7时,执行以下操作:
1. SUB.D 只需2个周期就可以执行完,第四条 SUB.D 指令执行完成,更新指令状态,并且准备写入寄存器表中
Qi为Add1 的寄存器中,即 F8。
2. 保留站中的 MUL.D 指令继续执行。
3.DIVD指令继续等待MUL.D的完成。
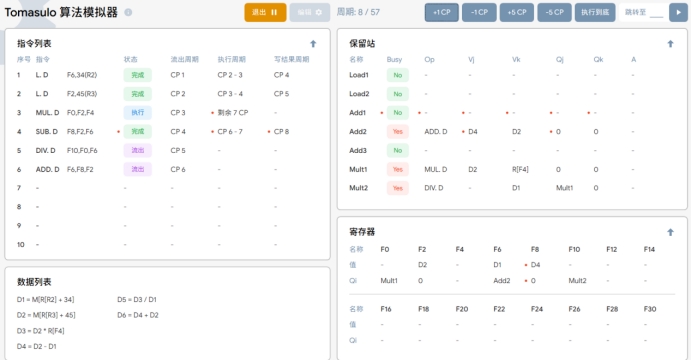
T8:在执行周期8时,执行以下操作:
1. SUB.D 指令在上个周期执行完成后,在下个周期将结果D4 写入寄存器 F8。
2. 由于 SUB.D 指令执行完成,保留站Addl 中存放的指令位置被清空。
3. MUL.D指令继续执行。
4. 由于F8也有了ADD所需要的数据,更新保留站 Add2 中的Vj为D4。
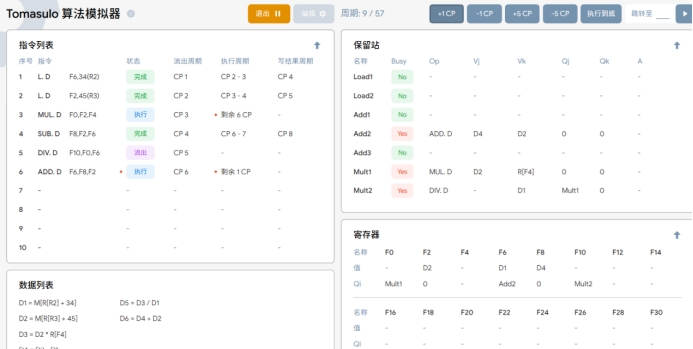
T9:开始执行ADD.D指令,同时MUL.D指令继续执行。
T10:ADD.D指令成功执行完成并准备将运算结果写入F6,同时MUL.D指令仍然保持执行状态。
T11:ADD.D指令将结果D1写入到F6中,清空保留站中ADD指令的位置。MUL.D指令仍然保持执行状态。
T12~T15:MUL.D指令继续执行,直到完成。
T16:MULT指令将结果D3写到F0,保留站中的内容被重置。
T17~T56:DIV指令开始执行至执行完毕。
2. 对于与上面相同的延迟时间和代码段。
给出在第3个时钟周期时,保留站的内容.
2、步进5个时钟周期,给出这时保留站、load缓冲器以及寄存器状态表中的内容。
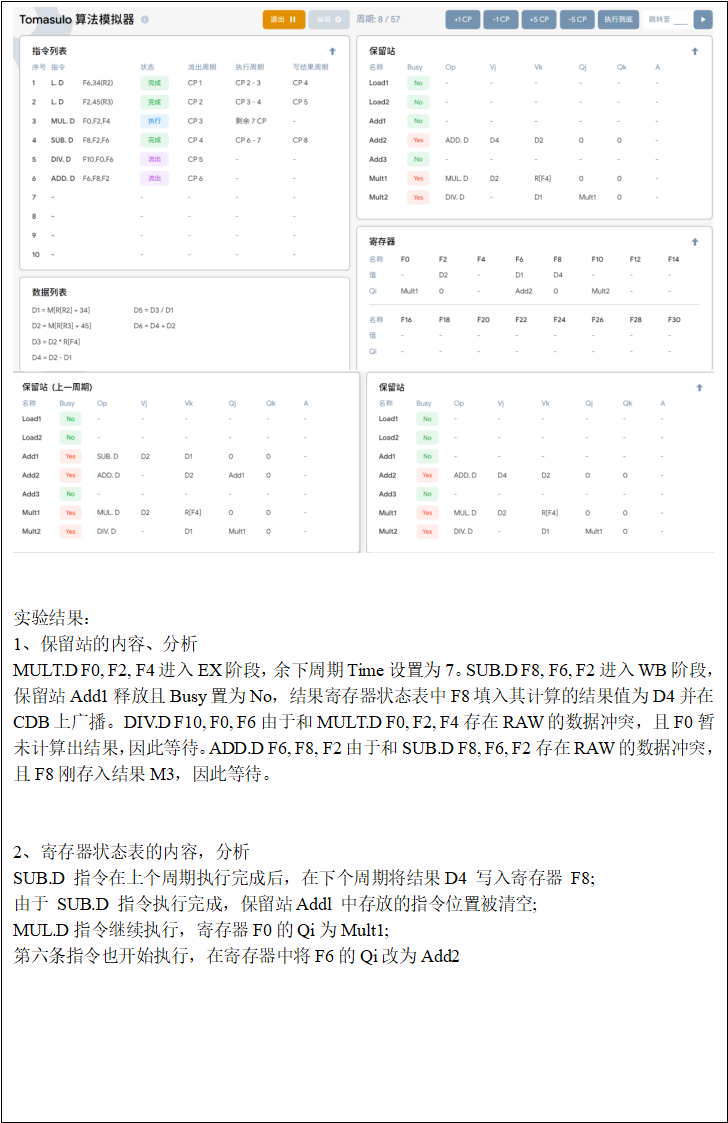
再步进10个时钟周期,给出这时保留站、load缓冲器以及寄存器状态表中的内容。
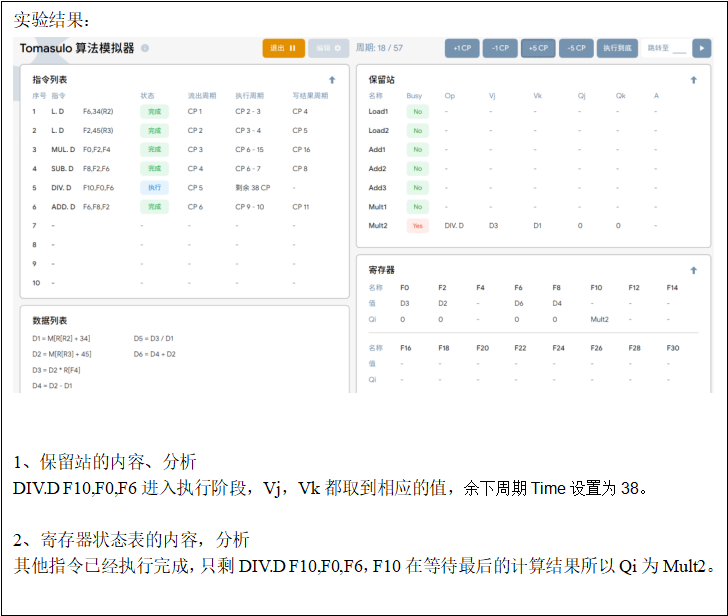
问题 1、执行完6条指令最终用多少个周期?(给出计算步骤)
计算步骤:
L.D F6, 34(R2) 和 L.D F2, 45(R3) 这两条指令都是加载指令,它们的延迟是2个时钟周期。由于它们可以同时开始执行(没有数据依赖),流出周期+执行周期+写入结果周期=4个周期,它们在周期1开始,周期5完成。
MUL.D F0, F2, F4 这条乘法指令的延迟是10个时钟周期。F2在周期5可用,F4在乘法指令开始时应该是可用的。因此,乘法指令在周期3开始流入,流入周期为3,执行10周期,写入结果1周期,所以在16周期完成。
SUB.D F8, F6, F2 这条减法指令的延迟是2个时钟周期。F6和F2都在周期5可用,所以减法指令在周期4开始流入,因为周期5的时候F2、F6都取到相应的值,到周期8的时候完成。
DIV.D F10, F0, F6 这条除法指令的延迟是40个时钟周期。因为在第五条指令,所以DIV.D在周期5的时候流入,开始等待所需要的值,F0在周期17可用,F6在周期4可用。因此,除法指令在周期17开始,执行40个周期,所以在周期57的时候完成。
ADD.D F6, F8, F2 这条加法指令的延迟是2个时钟周期。F8在周期8可用,F2在周期5可用。在周期6是流出周期,需要的F8, F2在周期8的时候取得相应的值,开始执行直到周期11完成。
根据上面的分析可以得到
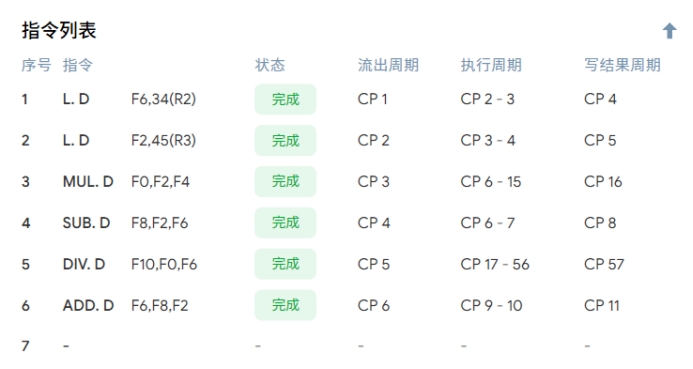
总时间 = 57周期
实验得到的结果也是57周期:
2、6条指令流出的顺序是什么?
L.D F6, 34(R2) 和 L.D F2, 45(R3) 没有什么数据依赖,可以按照顺序流出。
MUL.D F0, F2, F4 依赖于F2,而F2由L.D F2, 12(R3)提供,所以MUL.D在L.D F2之后流出。
SUB.D F8, F6, F2 依赖于F6和F2,它们都在L.D指令之后可用,所以SUB.D可以在L.D指令之后流出,由于MUL.D执行的周期比SUB.D 长,导致SUB.D会先得到结果流出。
DIV.D F10, F0, F6 依赖于F0,而F0由MUL.D提供,所以DIV.D在MUL.D之后流出。
ADD.D F6, F8, F2 不依赖于DIV.D的结果(尽管它使用F6,但F6的值在ADD.D执行前已经确定),所以ADD.D在SUB.D之后流出。
流出顺序:
L.D F6, 34(R2)
L.D F2, 45(R3)
SUB.D F8, F6, F2
MUL.D F0, F2, F4
ADD.D F6, F8, F2
DIV.D F10, F0, F6
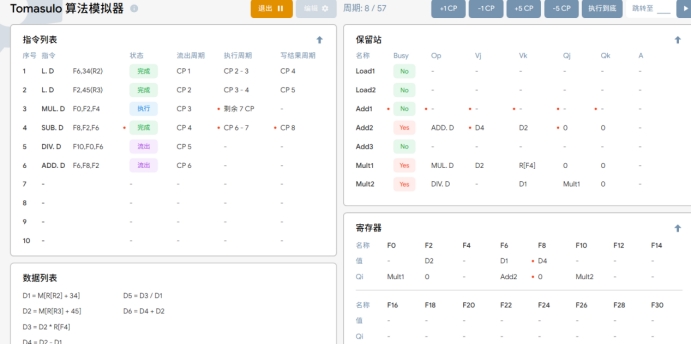
上述指令中DIV.D F10,F0,F6和ADD.D F6,F8,F2 的WAR冲突是如何消除的?
WAR冲突(写后读)发生在一条指令读取另一条指令刚刚写入的寄存器时。在这个例子中,DIV.D F10,F0,F6可能会读取ADD.D F6,F8,F2之后写入的F6。但在这个程序里面我们通过智能地调度指令的执行顺序,可以避免或最小化WAR冲突。例如,可以确保读取操作在其依赖的写入操作完成之后才执行。
由下面这张运行图,我们可知在这个运行的时候ADD.D F6,F8,F2将结果写回F6之前,我们指令中DIV.D F10,F0,F6已经流出周期,取得F6的值在等待F0,此时ADD.D的指令还没有执行结束,很好的规避了WAR冲突
假设浮点功能部件的延迟时间为加减法3个时钟周期,乘法8个时钟周期,除法40个时钟周期。自己编写一段程序(要在实验报告中给出),重复上述步骤2的工作。
根据题意编写这段程序
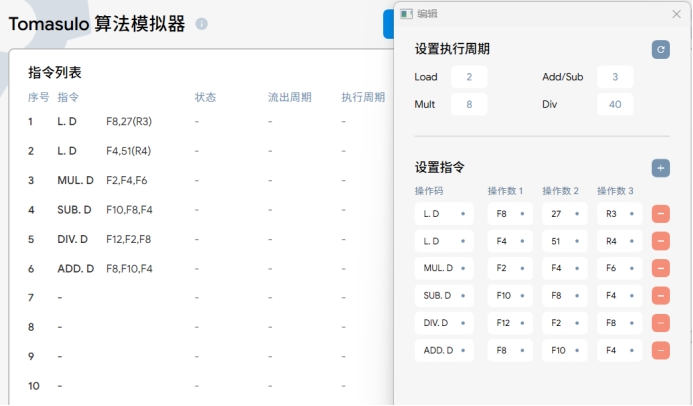
重复上述步骤2的工作
周期1
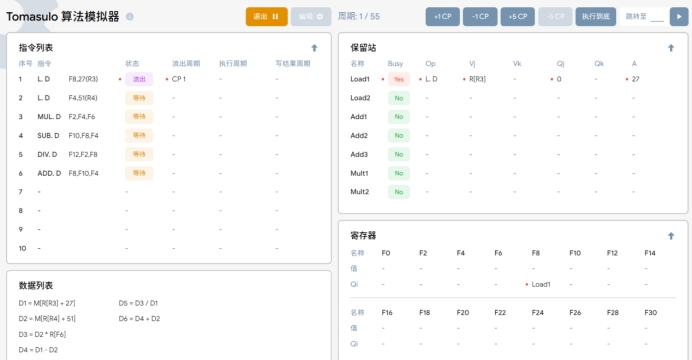
TI:当执行指令LDF8,27(R3)时,将地址偏移量为27的数据从内存加载到LOAD 部件的LOAD1中,并将LOAD1的值存储到寄存器字段F8中。
周期2
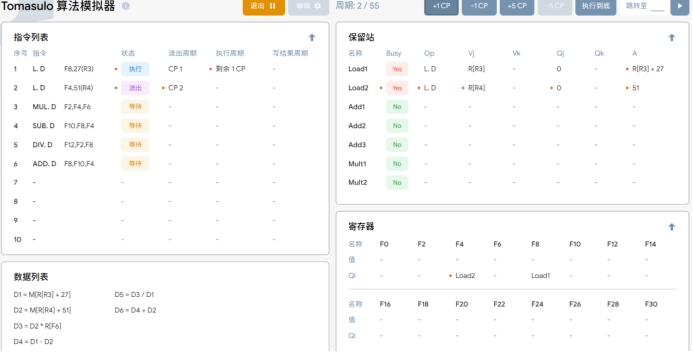
T2:执行指令 L.DF4,51(R4),将地址偏移量为51的数据加载到LOAD部件的LOAD2
中,并将LOAD2的值存储到寄存器字段F2中。与此同时,第一条指令LDF8,27(R3)开始执行,在其执行过程中,将LOAD1上的绝对地址写入。
周期3
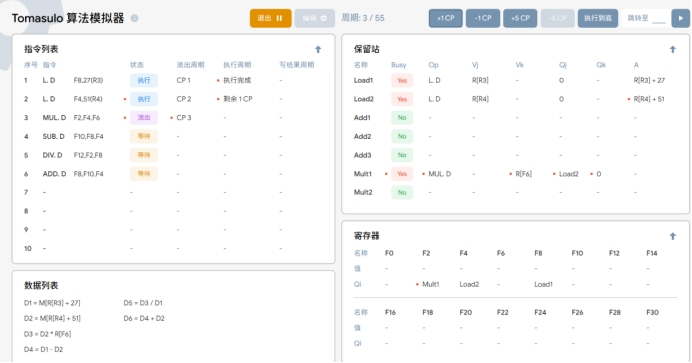
T3:执行第三条指令 MUL.D F2,F4,F6 ,同时进行以下操作:
1.该指令被取出并进入流出阶段。
2 第一条指令 L.DF8,27(R3)已完成取值,并在下一个时钟周期准备写入寄存器F8
3. 第二条指令L.D F4,51(R4)开始执行,LOAD2 上写入绝对地址。
周期4
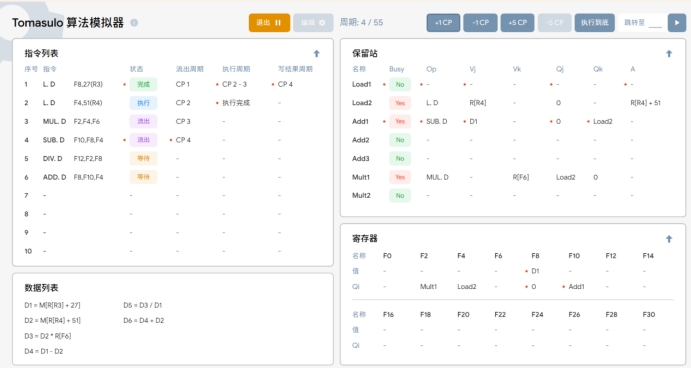
T4:在执行第四条指令 SUB.D F10,F8,F4 的同时,执行以下操作:
1. 第二条指令 LDF4,51(R4)执行完成,同时第一条指令 L.D F6,24(R2)完成写入结果D1到寄存器表F6中的值,并在指令状态表中的第一条指令填入写结果周期CP4.
2. 保留站中存入第四条指令的待运算操作数和操作。其中,F8的值为D 1,因此存入Vk;F2 是等待Load 的值,所以存入 Qj中表示等待中;同时,寄存器表中F10的Qi存入将要给它赋值的指令名称Add1。
Load 部件中的LOAD1行被清空。
周期5
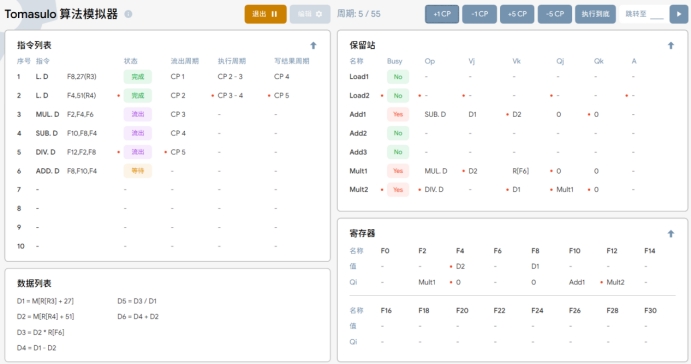
T5:在执行周期5时:
1.第五条指令 DIV.D F12,F2,F8 被取出进入流出阶段。
2 第二条指令 L.D F4,51(R4)写入结果 D2到寄存器 F4的值中,Load 部件表中LOAD2 行被清空。
3.由于 F4 的值 D2 已经准备好,因此在保留站中,第三行的Qj 转为 Vj 为D2,同理第六行。
4.保留站中存入第五条指令的待运算操作数和操作。因为F2需要Mult1 的值,所以保留站最后一行 Qi先填入对应寄存器指令名称。
周期6
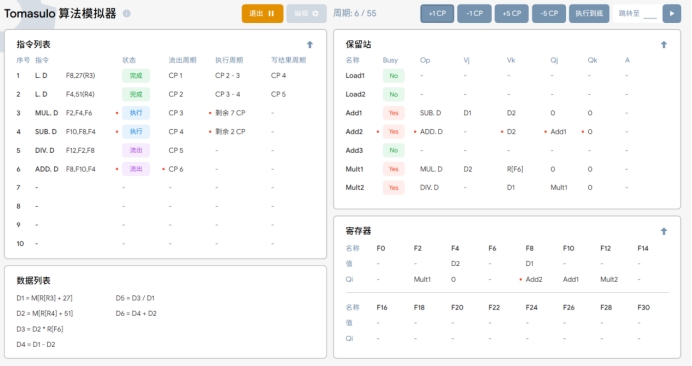
T6:在执行周期6时,执行以下操作:
1、取出第六条指令 ADD.D F8,F10,F4进到流出阶段;
2. 由于所需数据已经在之前的周期中写回结果。第三条和第四条指今在第六个周期开始执行,并在指令状态中更新。
3. 由于 SUB.D和 MUL.D 都已经取到值了,可以开始执行了。
周期7
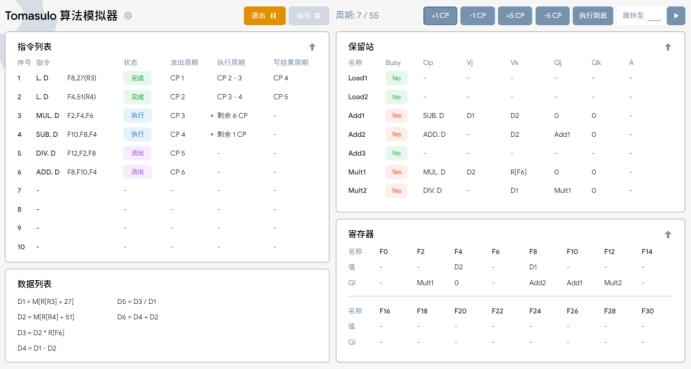
T7:在执行周期7时,执行以下操作:
1. SUB.D 只需1个周期就可以执行完,第四条 SUB.D 指令执行完成,更新指令状态,并且准备写入寄存器表中
Qi为Add1 的寄存器中,即 F8。
2. 保留站中的 MUL.D 指令继续执行。
3.DIVD指令继续等待MUL.D的完成。
周期8
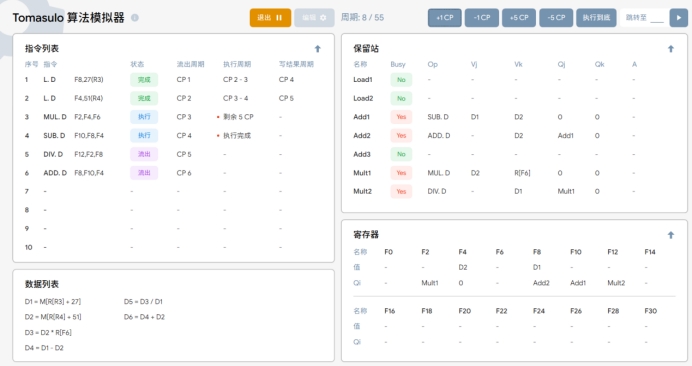
T8:在执行周期8时,执行以下操作:
1. SUB.D 指令在上个周期执行完成后,在下个周期将结果D4 写入寄存器 F8。
2. 由于 SUB.D 指令执行完成,保留站Addl 中存放的指令位置被清空。
3. MUL.D指令继续执行。
4. 由于F10也有了ADD所需要的数据,更新保留站 Add2 中的Vj为D4。
周期9
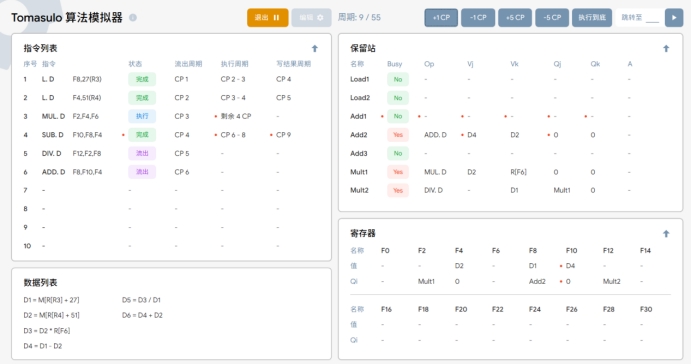
T9:开始执行ADD.D指令,同时MUL.D指令继续执行。
T10:ADD.D指令成功执行完成并准备将运算结果写入F8,同时MUL.D指令仍然保持执行状态。
T11:ADD.D指令将结果D1写入到F8中,清空保留站中ADD指令的位置。MUL.D指令仍然保持执行状态。
周期10
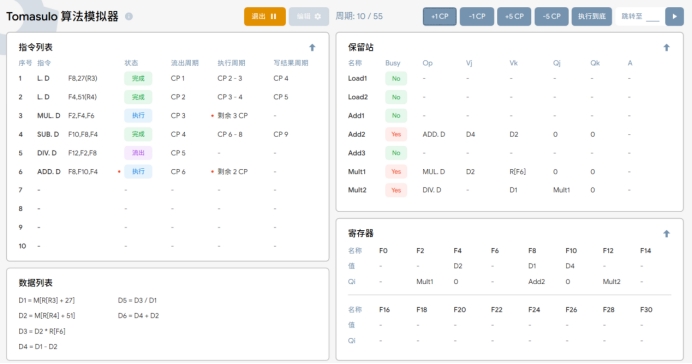
T10:ADD.D指令成功执行完成并准备将运算结果写入F8,同时MUL.D指令仍然保持执行状态。
周期11
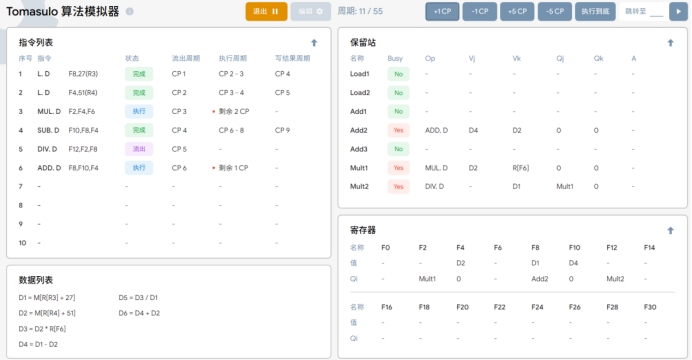
T11:ADD.D指令将结果D1写入到F8中,清空保留站中ADD指令的位置。MUL.D指令仍然保持执行状态。
周期12
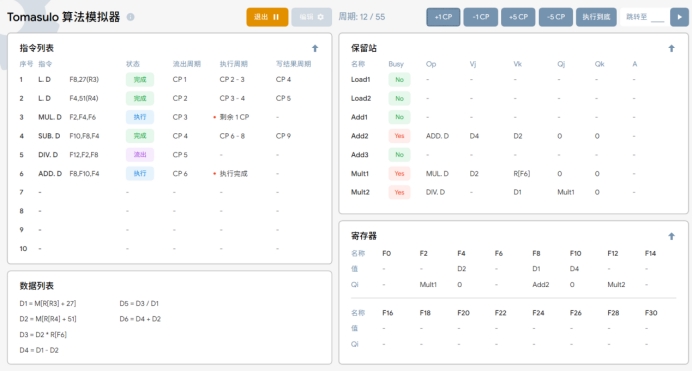
T12~T14:MUL.D指令继续执行,直到完成。
周期13
T15~T56:DIV指令开始执行至执行完毕。
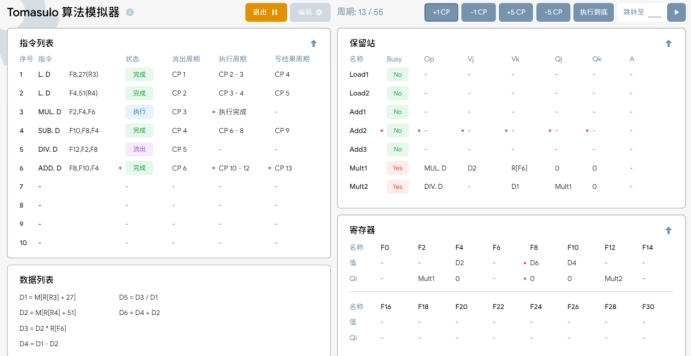
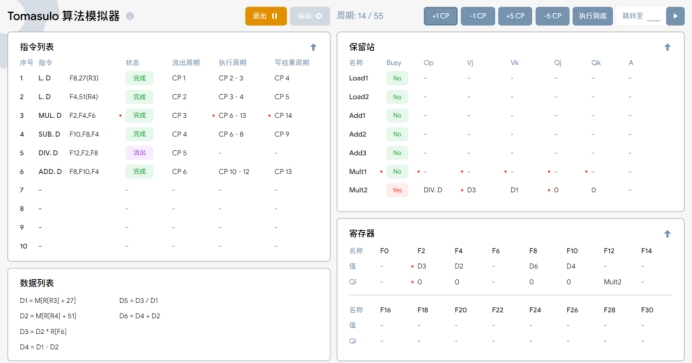
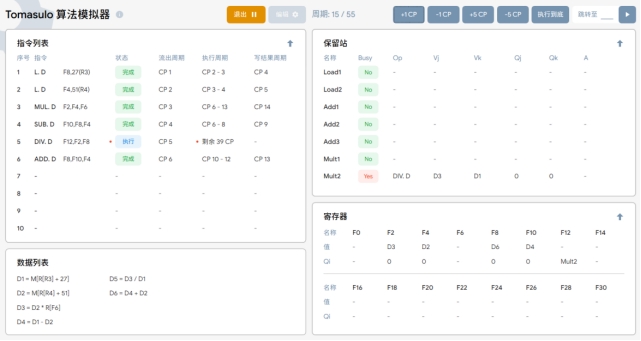
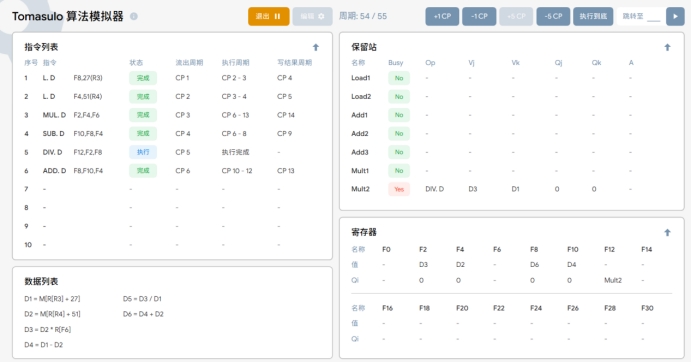
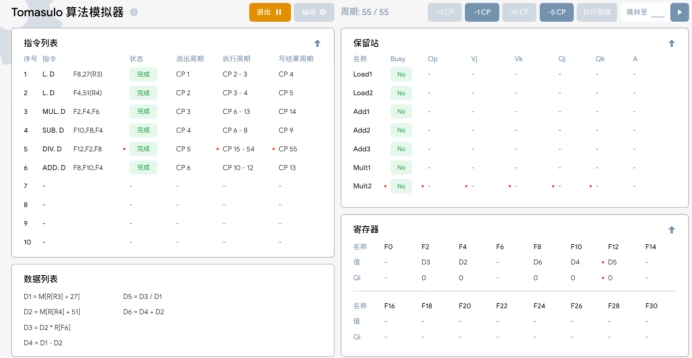
性能影响。修改延迟时间会影响处理器执行指令的速度。延长延迟会减慢指令执行,而缩短延迟可能加快执行,但这也取决于其他因素,如指令依赖性和资源利用率。
资源冲突和调度。在Tomasulo算法中,资源共享和动态调度是关键。改变延迟时间可能会影响功能单元的利用率和指令的调度顺序,进而影响整体性能。

















 8595
8595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









