






如何提高kettle在大数据量下的读写速度
1、kettle执行测速
背景:最近公司项目重构,准备数据迁移,之前的表结构都会有变动,然后就准备用kettle做数据迁移,发现表的数据量大的时候,kettle对表的读写操作的速度很慢,并且是达到一定数据量以后速度会特别慢,数据量小的时候读的速度是很快的
1.1 在5000条数据量和16000条数据量下读取数据的速度
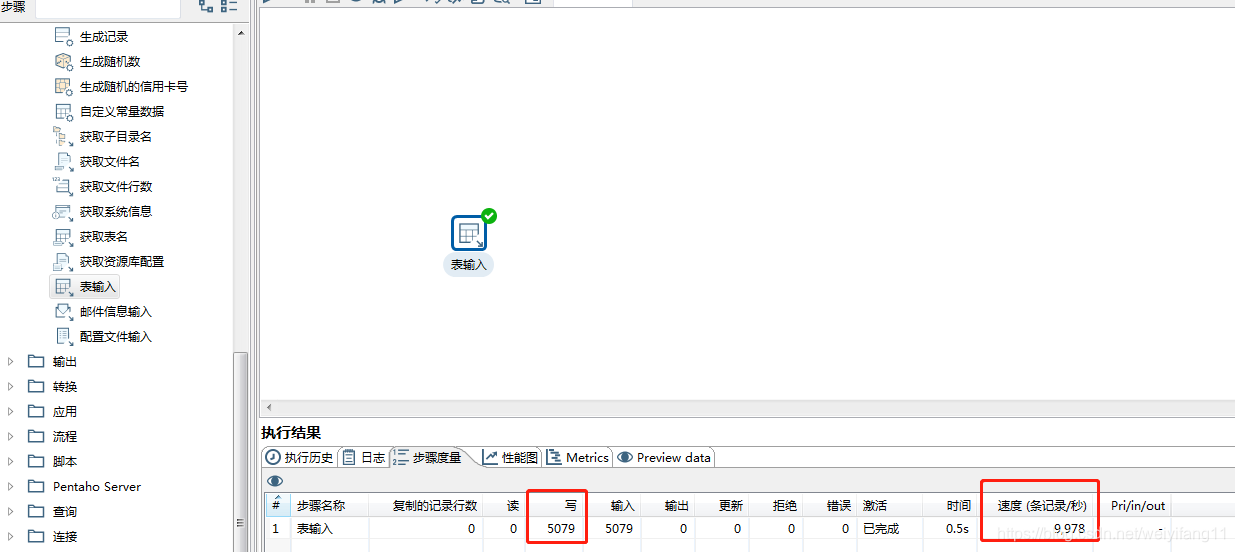

可以看出数据量增加三倍以后,我读取数据的速度直接下降了五六十倍
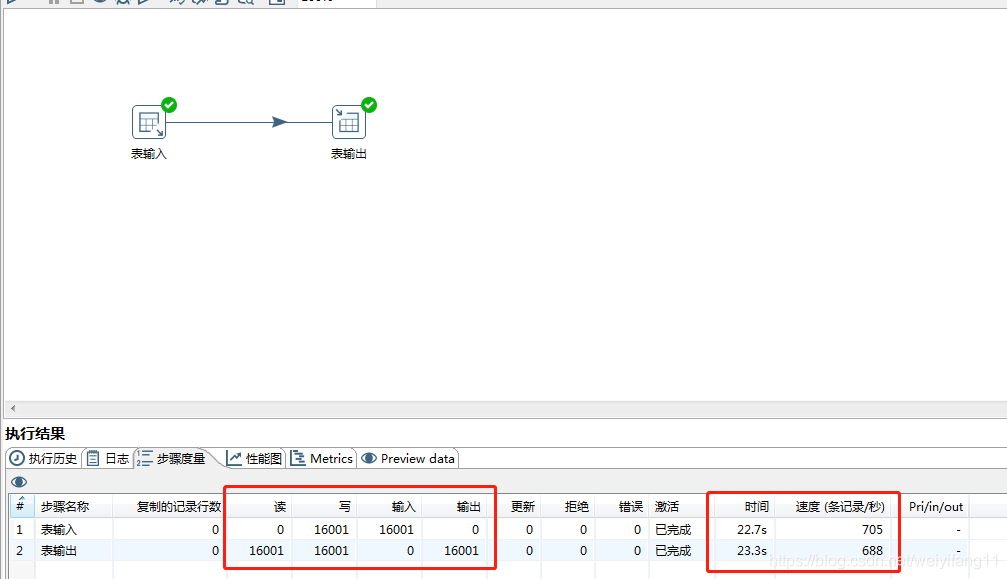
1.2 在5000条数据量和16000条数据量下读写操作的速度
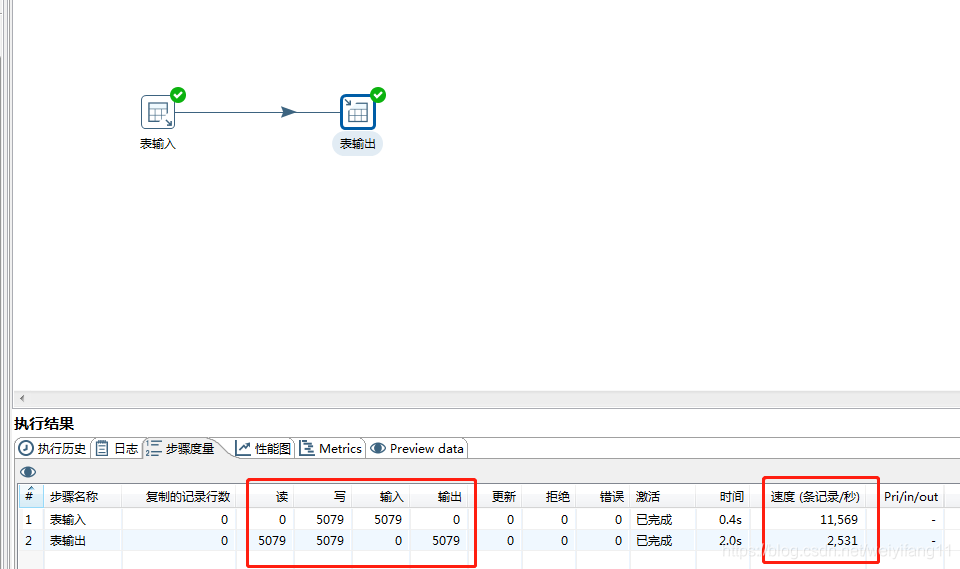
这里读写操作的数据量差异之所以会这么大,是因为我没有修改输出表的提交记录数据,导致每次输出只能1000条的处理,这里修改成10000的时候,读写速度差不多可以同步,可以自己测试
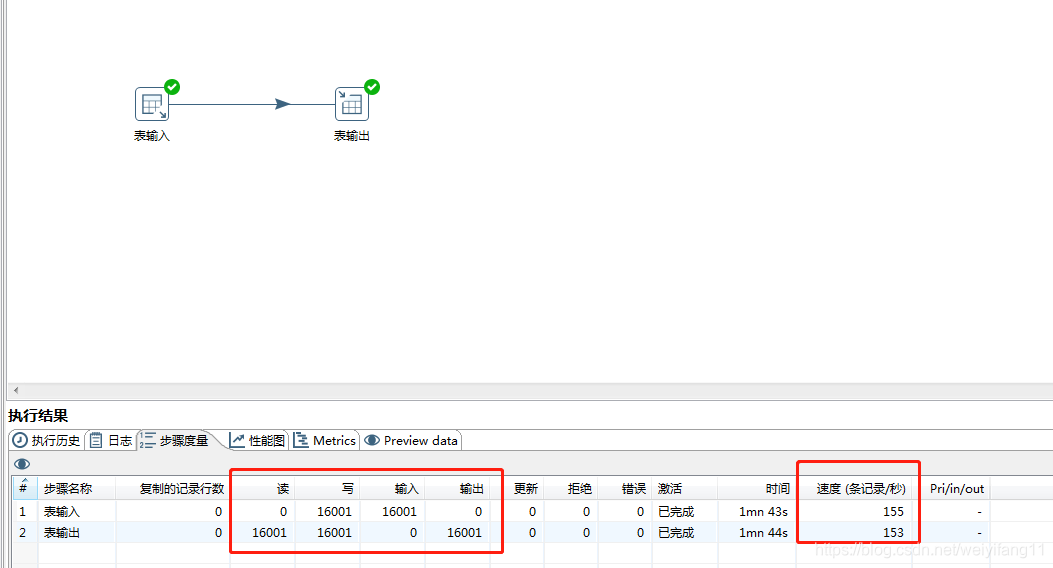
在数据量不同的情况下,读和写的操作的速度也是很明显的,上面速度也差了几十倍
2、提高kettle在大数据量下的读写速度
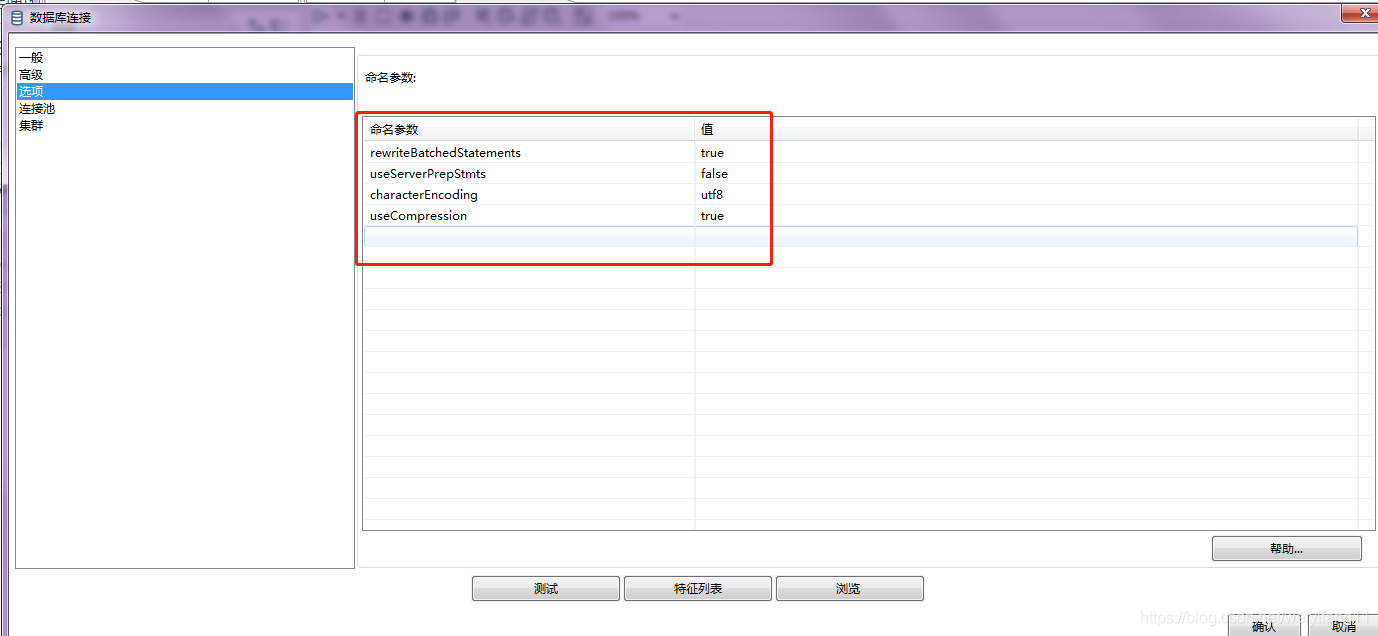
2.1 修改数据库连接参数
characterEncoding = utf8 //配置数据库字符编码
输入、输出数据库的配置都添加如下参数:
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
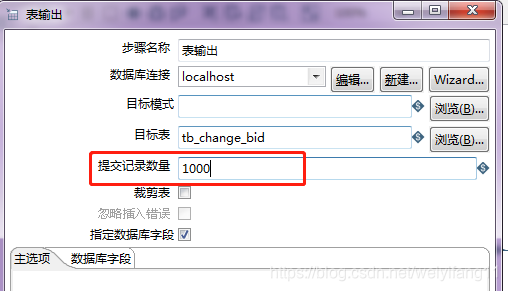
并且在输出表空间中可以修改提交记录数据的值,默认值是1000条,根据时间情况可以改大
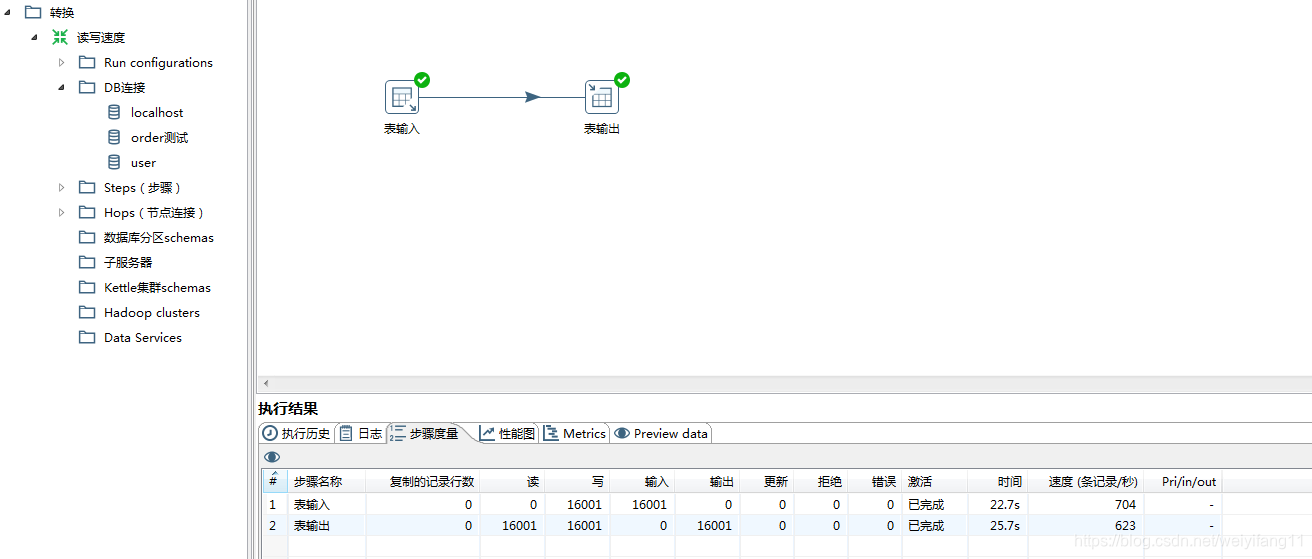
16000千条数据,再次操作,可以提高5倍速度
2.2 根据输入、输出库修改配置参数
1、在输入表的数据库中添加如下参数配置:
// 增加读的操作
useServerPrepStmts:true
cachePrepStmts:true
// 读取缓存,设置过高消耗内存也会高
defaultFetchSize:10000
useCursorFetch:true
useCompression:true //压缩数据传入,与mysql服务端进行通信时采用zlib压缩
2、在输出表的数据库连接中添加如下参数配置:
defaultFetchSize:5000
// 提高写的操作
rewriteBatchedStatements:true
useServerPrepStmts:false
useCursorFetch:true
// 设置与mysql服务器通讯时压缩数据传入
useCompression:true
上面两种修改参数的方式都可以,而且修改完对kettle进行读写的速度影响也差不多,上面这两哥都是修改的数据库的一些配置参数,进而提高速度
2.3 kettle开启多个线程操作
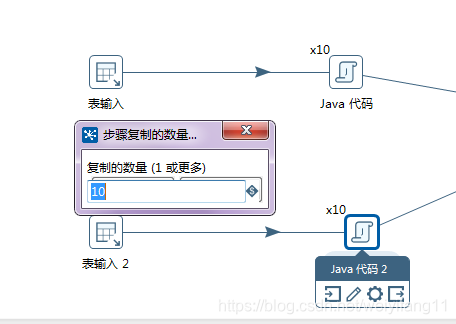 kettle支持多线程,对于操作慢的流程可以直接开启多线程并行执行,上面就是开启多线程的设置,我将两个java脚本都设置成10个线程执行一下就提高了运行速度
kettle支持多线程,对于操作慢的流程可以直接开启多线程并行执行,上面就是开启多线程的设置,我将两个java脚本都设置成10个线程执行一下就提高了运行速度
开启多个线程,要注意自己电脑的内存合理设置,否则电脑瞬间卡死,而且对于插入操作不能开启多线程插入,否则会插入重复数据
2.4 kettle修改spoon.bat的运行内存大小
上面说到了开启多线程,kettle其实也是在jvm内运行的,所以当设置的运行的jvm内存过小,但是开启多个线程占用内存过大,会直接导致卡死,执行不了,或是内存超出,此时可以修改spoon.bat的配置,修改完重启一下,修改的配置如下:
 将之前的配置修改为:
将之前的配置修改为:
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xmx4096m" "-XX:MaxPermSize=4096m"

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









