







我们经常在野外采集一些地震数据,通常可以保存为SEGY和SEG2两种格式。然后,一炮一个文件,甚至一道就是一个文件。接着,拿回去数据,需要做一些处理。所有的数据处理都事先要将原始数据导入到计算机内存中。它具有某种固定的数据结构,可以用结构体变量和其它各自编程语言给出的某种数据结构来实现。C语言、FORTRAN语言和MATLAB语言中的STRUCT结构用得最多。SEGY数据在C语言中的结构描述如下所示[1],来自于SEISMIC UNIX中的代码:
Note: The web version of this archive does not contain the SEG-Y Trace files. These files are very large and would require extremely long download times. To obtain the complete CD-ROM archive, contact USGS Information at (888) ASK-USGS.
The seismic data are stored in SEG-Y, integer, Motorola format. The SEG-Y files on this CD-ROM conform to the SEG-Y standard format (Barry and others, 1975) with the exception of the 3600-byte reel identification header which is provided in ASCII format. Standard SEG-Y uses a EBCDIC 3600-byte reel identification header. The Delph Seismic version of SEG-Y consists of the following:
- A 3600-byte reel identification header with the first 3200 bytes consisting of an ASCII header block and a 400-byte binary header block. Both headers include information specific to the line and reel number.
- The trace data block follows the reel identification header. The first 240 bytes of each trace block is the binary trace identification header. The seismic data samples follow the trace identification header.

/* TYPEDEFS */
typedef struct { /* segy - trace identification header */
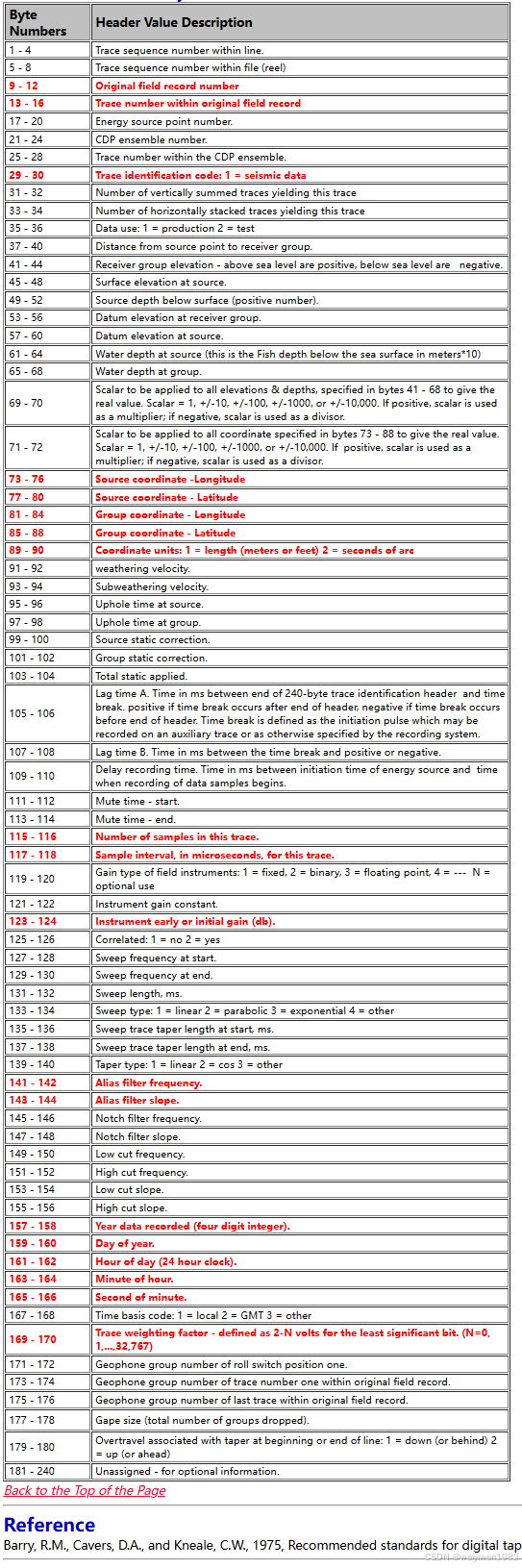
int tracl; /* Trace sequence number within line
--numbers continue to increase if the
same line continues across multiple
SEG Y files.
byte# 1-4
*/
int tracr; /* Trace sequence number within SEG Y file
---each file starts with trace sequence
one
byte# 5-8
*/
int fldr; /* Original field record number
byte# 9-12
*/
int tracf; /* Trace number within original field record
byte# 13-16
*/
int ep; /* energy source point number
---Used when more than one record occurs
at the same effective surface location.
byte# 17-20
*/
int cdp; /* Ensemble number (i.e. CDP, CMP, CRP,...)
byte# 21-24
*/
int cdpt; /* trace number within the ensemble
---each ensemble starts with trace number one.
byte# 25-28
*/
short trid; /* trace identification code:
-1 = Other
0 = Unknown
1 = Seismic data
2 = Dead
3 = Dummy
4 = Time break
5 = Uphole
6 = Sweep
7 = Timing
8 = Water break
9 = Near-field gun signature
10 = Far-field gun signature
11 = Seismic pressure sensor
12 = Multicomponent seismic sensor
- Vertical component
13 = Multicomponent seismic sensor
- Cross-line component
14 = Multicomponent seismic sensor
- in-line component
15 = Rotated multicomponent seismic sensor
- Vertical component
16 = Rotated multicomponent seismic sensor
- Transverse component
17 = Rotated multicomponent seismic sensor
- Radial component
18 = Vibrator reaction mass
19 = Vibrator baseplate
20 = Vibrator estimated ground force
21 = Vibrator reference
22 = Time-velocity pairs
23 ... N = optional use
(maximum N = 32,767)
Following are CWP id flags:
109 = autocorrelation
110 = Fourier transformed - no packing
xr[0],xi[0], ..., xr[N-1],xi[N-1]
111 = Fourier transformed - unpacked Nyquist
xr[0],xi[0],...,xr[N/2],xi[N/2]
112 = Fourier transformed - packed Nyquist
even N:
xr[0],xr[N/2],xr[1],xi[1], ...,
xr[N/2 -1],xi[N/2 -1]
(note the exceptional second entry)
odd N:
xr[0],xr[(N-1)/2],xr[1],xi[1], ...,
xr[(N-1)/2 -1],xi[(N-1)/2 -1],xi[(N-1)/2]
(note the exceptional second & last entries)
113 = Complex signal in the time domain
xr[0],xi[0], ..., xr[N-1],xi[N-1]
114 = Fourier transformed - amplitude/phase
a[0],p[0], ..., a[N-1],p[N-1]
115 = Complex time signal - amplitude/phase
a[0],p[0], ..., a[N-1],p[N-1]
116 = Real part of complex trace from 0 to Nyquist
117 = Imag part of complex trace from 0 to Nyquist
118 = Amplitude of complex trace from 0 to Nyquist
119 = Phase of complex trace from 0 to Nyquist
121 = Wavenumber time domain (k-t)
122 = Wavenumber frequency (k-omega)
123 = Envelope of the complex time trace
124 = Phase of the complex time trace
125 = Frequency of the complex time trace
126 = log amplitude
127 = real cepstral domain F(t_c)= invfft[log[fft(F(t)]]
130 = Depth-Range (z-x) traces
201 = Seismic data packed to bytes (by supack1)
202 = Seismic data packed to 2 bytes (by supack2)
byte# 29-30
*/
short nvs; /* Number of vertically summed traces yielding
this trace. (1 is one trace,
2 is two summed traces, etc.)
byte# 31-32
*/
short nhs; /* Number of horizontally summed traces yielding
this trace. (1 is one trace
2 is two summed traces, etc.)
byte# 33-34
*/
short duse; /* Data use:
1 = Production
2 = Test
byte# 35-36
*/
int offset; /* Distance from the center of the source point
to the center of the receiver group
(negative if opposite to direction in which
the line was shot).
byte# 37-40
*/
int gelev; /* Receiver group elevation from sea level
(all elevations above the Vertical datum are
positive and below are negative).
byte# 41-44
*/
int selev; /* Surface elevation at source.
byte# 45-48
*/
int sdepth; /* Source depth below surface (a positive number).
byte# 49-52
*/
int gdel; /* Datum elevation at receiver group.
byte# 53-56
*/
int sdel; /* Datum elevation at source.
byte# 57-60
*/
int swdep; /* Water depth at source.
byte# 61-64
*/
int gwdep; /* Water depth at receiver group.
byte# 65-68
*/
short scalel; /* Scalar to be applied to the previous 7 entries
to give the real value.
Scalar = 1, +10, +100, +1000, +10000.
If positive, scalar is used as a multiplier,
if negative, scalar is used as a divisor.
byte# 69-70
*/
short scalco; /* Scalar to be applied to the next 4 entries
to give the real value.
Scalar = 1, +10, +100, +1000, +10000.
If positive, scalar is used as a multiplier,
if negative, scalar is used as a divisor.
byte# 71-72
*/
int sx; /* Source coordinate - X
byte# 73-76
*/
int sy; /* Source coordinate - Y
byte# 77-80
*/
int gx; /* Group coordinate - X
byte# 81-84
*/
int gy; /* Group coordinate - Y
byte# 85-88
*/
short counit; /* Coordinate units: (for previous 4 entries and
for the 7 entries before scalel)
1 = Length (meters or feet)
2 = Seconds of arc
3 = Decimal degrees
4 = Degrees, minutes, seconds (DMS)
In case 2, the X values are longitude and
the Y values are latitude, a positive value designates
the number of seconds east of Greenwich
or north of the equator
In case 4, to encode +-DDDMMSS
counit = +-DDD*10^4 + MM*10^2 + SS,
with scalco = 1. To encode +-DDDMMSS.ss
counit = +-DDD*10^6 + MM*10^4 + SS*10^2
with scalco = -100.
byte# 89-90
*/
short wevel; /* Weathering velocity.
byte# 91-92
*/
short swevel; /* Subweathering velocity.
byte# 93-94
*/
short sut; /* Uphole time at source in milliseconds.
byte# 95-96
*/
short gut; /* Uphole time at receiver group in milliseconds.
byte# 97-98
*/
short sstat; /* Source static correction in milliseconds.
byte# 99-100
*/
short gstat; /* Group static correction in milliseconds.
byte# 101-102
*/
short tstat; /* Total static applied in milliseconds.
(Zero if no static has been applied.)
byte# 103-104
*/
short laga; /* Lag time A, time in ms between end of 240-
byte trace identification header and time
break, positive if time break occurs after
end of header, time break is defined as
the initiation pulse which maybe recorded
on an auxiliary trace or as otherwise
specified by the recording system
byte# 105-106
*/
short lagb; /* lag time B, time in ms between the time break
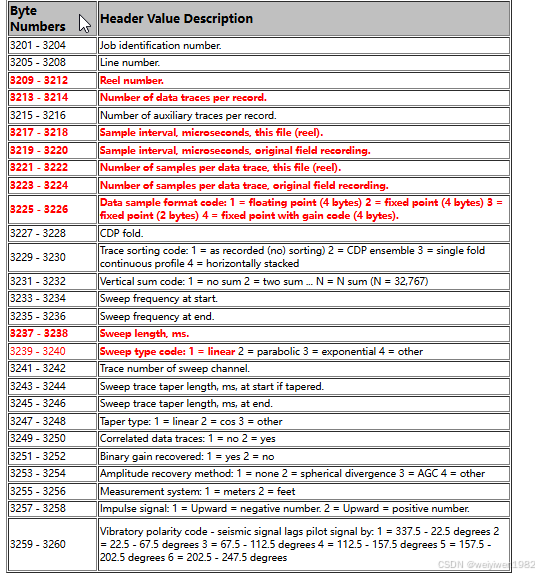
and the initiation time of the energy source,
may be positive or negative
byte# 107-108
*/
short delrt; /* delay recording time, time in ms between
initiation time of energy source and time
when recording of data samples begins
(for deep water work if recording does not
start at zero time)
byte# 109-110
*/
short muts; /* mute time--start
byte# 111-112
*/
short mute; /* mute time--end
byte# 113-114
*/
unsigned short ns; /* number of samples in this trace
byte# 115-116
*/
unsigned short dt; /* sample interval; in micro-seconds
byte# 117-118
*/
short gain; /* gain type of field instruments code:
1 = fixed
2 = binary
3 = floating point
4 ---- N = optional use
byte# 119-120
*/
short igc; /* instrument gain constant
byte# 121-122
*/
short igi; /* instrument early or initial gain
byte# 123-124
*/
short corr; /* correlated:
1 = no
2 = yes
byte# 125-126
*/
short sfs; /* sweep frequency at start
byte# 127-128
*/
short sfe; /* sweep frequency at end
byte# 129-130
*/
short slen; /* sweep length in ms
byte# 131-132
*/
short styp; /* sweep type code:
1 = linear
2 = cos-squared
3 = other
byte# 133-134
*/
short stas; /* sweep trace length at start in ms
byte# 135-136
*/
short stae; /* sweep trace length at end in ms
byte# 137-138
*/
short tatyp; /* taper type: 1=linear, 2=cos^2, 3=other
byte# 139-140
*/
short afilf; /* alias filter frequency if used
byte# 141-142
*/
short afils; /* alias filter slope
byte# 143-144
*/
short nofilf; /* notch filter frequency if used
byte# 145-146
*/
short nofils; /* notch filter slope
byte# 147-148
*/
short lcf; /* low cut frequency if used
byte# 149-150
*/
short hcf; /* high cut frequncy if used
byte# 151-152
*/
short lcs; /* low cut slope
byte# 153-154
*/
short hcs; /* high cut slope
byte# 155-156
*/
short year; /* year data recorded
byte# 157-158
*/
short day; /* day of year
byte# 159-160
*/
short hour; /* hour of day (24 hour clock)
byte# 161-162
*/
short minute; /* minute of hour
byte# 163-164
*/
short sec; /* second of minute
byte# 165-166
*/
short timbas; /* time basis code:
1 = local
2 = GMT
3 = other
byte# 167-168
*/
short trwf; /* trace weighting factor, defined as 1/2^N
volts for the least sigificant bit
byte# 169-170
*/
short grnors; /* geophone group number of roll switch
position one
byte# 171-172
*/
short grnofr; /* geophone group number of trace one within
original field record
byte# 173-174
*/
short grnlof; /* geophone group number of last trace within
original field record
byte# 175-176
*/
short gaps; /* gap size (total number of groups dropped)
byte# 177-178
*/
short otrav; /* overtravel taper code:
1 = down (or behind)
2 = up (or ahead)
byte# 179-180
*/
1.使用MATLAB读取外部SEISMIC BINARY DATA
由于SEISMIC BINARY DATA在工作中经常碰到。例如SEGY, SEG2格式的地震数据在石油勘探、天然地震以及工程物探中经常被存储在磁盘文件中。科技工作者们需要将这些磁盘中的SEISMIC BINARY DATA导入到计算机内存中。因此,这个工作可以利用FILE OPEN 和 READ, WRITE语句以及CLOSE语句实现。编程过程比较死板,需要一步一步来,遇到有重复步骤的可以稍微调用循环语句实现。为了对编程过程数据格式进行保密或者不触犯相关保密条例。以下SEISMIC BINARY DATA一律采用某数据格式来表达。
某二进制SEISMIC DATA的读取
path(path,'D:');
id=fopen('c4','r','ieee-le');%ieee-le为little endian;ieee-be为big endian
fseek(id,0,'bof');
fseek(id,4,'bof');
ntr=fread(id,1,'int16');
fseek(id,0,'bof');
fseek(id,10,'bof');
nt=fread(id,1,'int16');
data=zeros(nt,ntr);
data1=zeros(nt,ntr);
fseek(id,0,'bof');
fseek(id,14,'bof');
dt=fread(id,1,'int32');
for i=1:ntr
fseek(id,0,'bof');
fseek(id,512+nt*4*(i-1),'bof');
for j=1:nt
data(j,i)=fread(id,1,'int32');
end
for j=1:nt
data(j,i)=bitshift(int32(data(j,i)),0);%32位不做任何偏移,0偏移
end
end
%d=quantizer([32 16]);
%data1=bin2num(d,data);
data1=data.*1e10;
%data1=hex2dec(data);
image(data1(:,1:ntr));
fclose(id);
SEG2格式:
/* Copyright (c) Colorado School of Mines, 2002.*/
/* All rights reserved. */
/*
FROM THE PUBLISHED VERSION IN GEOPHYSICS, SEPT '90
Original Header:
NAME: SEG2SEGY.C
VERSION: V1.0
CREATION DATE: 6/15/90
AUTHOR: Brett Bennett
PURPOSE: Conversion of the SEG2-PC standard data set
to SEG-Y 32-BIT format.
LIMITATIONS: In this implementation of the conversion only
the data generated in the IBM byte ordering method can be
converted. i.e. byte ordering must be LSB-MSB Data generated
by a 68000 pro- cessor, for instance, will not convert. A flag
is however in the code for future addition of this capability.
The SEG-Y file also differs slightly from Barry et al standard.
Word 88 is defined as "last-trace-flag" rather than "Geophone
group number of last trace within original file." This
simplification greatly reduces the amount of code needed for
conversion. Header word 92 is defined here as the
Shot-Sequence-Number. This is used to assign each trace group a
unique number.
EXTENSIVE REWRITE/HACK AND PORT: 11/95
AUTHOR: Ian Kay.
-Added code to handle running on big-endian machines.
-Replaced all non-unix portable code and library calls.
-Typed all the ints so they are the right types
(on DOS int=short, on Unix int=long)
-removed calls to "ieeeibm" since workstations are ieee floating point
format as well.
-partial addition of structures to handle the keywords and headers.
but I eventually gave up.
$Id: seg2segy.c,v 1.2 2003/02/06 19:05:45 pm Exp $
Changes:
Feb 96. Trace header was not being written out with swap on bytes above
89 although info is stored in 92,93,94. Error in original, fixed.
Oct 97. Changed the input to command line, inspired by the seg2segy
version in CWP/SU package.
Jan 98.
fixed malloc problem; not enough space was malloced to hold the
string defpath.
freed the malloced space when finished.
closed the segykeyword file when finished.
changed curf and lastf to int from short; this should allow digits
in the file name prefix (but what will happen in DOS?).
Sep 98.
Ok. So no one can figure out the segykeyword file mechanism,
so I've changed it. Now, if the environment variable SEGKEYPATH
is set , then that file is used for the segykeywords. If that
isn't set then a system default is used /usr/local/lib/segykeyword
or "segykeyw.ord" in the local directory in DOS. Finally, neither
of those exist, then the default values are built in.
NOTE that this means that you can do away with the segykeyword
file altogether!
$Log: seg2segy.c,v $
Revision 1.2 2003/02/06 19:05:45 pm
fixed sawtooth on 20bit packed data conversion case 3
Revision 1.1 2003/02/06 18:44:59 pm
working on 3rdparty seismic unix
Revision 1.2 2002/11/12 16:01:43 john
type changed on i,j,k to in
t
Revision 1.1 2001/04/12 17:55:11 john
Initial revision
Revision 1.7 1998/10/08 20:17:15 kay
A little more cleanup...^[
Revision 1.6 1998/10/07 18:54:40 kay
Built in the defaults for the segykeyword file. This file is no longer
needed.
Revision 1.5 1998/01/07 13:36:15 kay
added new changes and a Log for the future
*/
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <string.h>
#ifndef __MSDOS__
#include <unistd.h>
#define MAXSAMP 16384
#define MAXTRACES 16384
#else
#include <io.h>
#define MAXSAMP 4096
#define MAXTRACES 512
#endif
#ifndef NULL
#define NULL ((void *)0)
#endif
#define STRINGWIDTH 100
#define MAXKEYWORDS 100
#define MAXPARMS 10
/* global data... */
short int segyreelheader[1800];
int totalkeys;
char string1[200];
short int outhead[120];
typedef struct _SegyKeyTable
{
char segykeyword[STRINGWIDTH];
int segyfunction;
int segyheader;
double segyparms[MAXPARMS];
} SegyKeyTable;
void
swapshort (short *si)
{
/* void swab(char *from, char *to, size_t nbytes); */
short tempc;
tempc = *si;
swab ((char *) &tempc, (char *) si, sizeof (short));
}
void
swaplong (long *li)
{
short sl, sh;
long temp, temp1;
temp = *li;
sl = temp & 0x0000ffff;
sh = (temp >> (8 * sizeof (short))) & 0x0000ffff;
swapshort (&sl);
swapshort (&sh);
temp = (sl << (8 * sizeof (short)));
temp1 = (sh & 0x0000ffff);
temp = temp | temp1;
*li = temp;
}
void
float_to_ibm(long from[], long to[], long n)
{
register long fconv, fmant, ii, t;
for (ii=0;ii<n;++ii) {
fconv = from[ii];
if (fconv) {
fmant = (0x007fffff & fconv) | 0x00800000;
t = (long) ((0x7f800000 & fconv) >> 23) - 126;
while (t & 0x3) { ++t; fmant >>= 1; }
fconv = (0x80000000 & fconv) | (((t>>2) + 64) << 24) | fmant;
}
to[ii] = fconv;
}
return;
}
char *
strrev (char *s)
{
char *tmpstr;
int i, len;
tmpstr = (char *) malloc (sizeof (char) * strlen (s));
len = 0;
while (s[len] != '\0')
len++;
for (i = 0; i < len; i++) {
tmpstr[i] = s[len - 1 - i];
tmpstr[i + 1] = '\0';
}
tmpstr[++i] = '\0';
strcpy (s, tmpstr);
free (tmpstr);
tmpstr = (char *) NULL;
return s;
}
void
parseSegyKeys(FILE *keyfptr, SegyKeyTable *keywords)
{
int i, j;
char input[STRINGWIDTH], inputbuf[STRINGWIDTH];
char *token;
i = 0;
while (fgets (input, STRINGWIDTH, keyfptr)) {
j = 0;
if ( strlen(input) > (size_t)STRINGWIDTH) {
fprintf (stderr, "String too long!\n (line:%d)\n", __LINE__);
exit (-12);
}
/*
* if left most character = "*" then
* this line is a comment and should be ignored.
*/
if (input[0] == '*' || input[0] == '\n')
continue;
strcpy (inputbuf, input); /* make a working copy of input */
token = strtok (inputbuf, " "); /* search out space. */
/* copy keyword into array */
strncpy (keywords[i].segykeyword, token, 1 + strlen (token));
/* get function value. */
token = strtok (NULL, " ");
keywords[i].segyfunction = atoi (token); /* convert to value. */
token = strtok (NULL, " ");
/* get segy header pointer */
keywords[i].segyheader = atoi (token);
/* now start getting any parameters on the line. */
token = strtok (NULL, " ");
j = 0;
while (token != NULL) {
/* get next token and start putting them in their array location */
keywords[i].segyparms[j] = atof (token);
token = strtok (NULL, " ");
j++;
if (j > MAXPARMS) {
printf ("Too many parameters in %s keyword\n", keywords[i].segykeyword);
printf ("No more than %d allowed per function\n", j - 1);
exit (-13);
}
} /* end parameter extraction while loop */
i++; /* inc counter to keyword number */
} /* end keyword string while loop */
totalkeys = i;
} /* end parseSegyKeys() */
void
loadSegyKeyTableDefaults(SegyKeyTable * keywords)
{
char *defaults[] = {
"ACQUISITION_DATE 3 6 ",
"ACQUISITION_TIME 3 7 ",
"ALIAS_FILTER 5 0 1 71 72 ",
"CDP_NUMBER 5 1 1 12 ",
"CDP_TRACE 5 1 1 14 ",
"CHANNEL_NUMBER 5 1 1 8 ",
"CLIENT 3 1 ",
"COMPANY 3 2 ",
"DATUM 5 1 1 28 ",
"DELAY 1 55 1000 ",
"END_OF_GROUP 1 88 1 ",
"FIXED_GAIN 1 61 1 ",
"FIXED_GAIN 1 62 1 ",
"HIGH_CUT_FILTER 5 0 1 76 78 ",
"INSTRUMENT 3 4 ",
"JOB_ID 3 9 ",
"LINE_ID 3 3 ",
"LOW_CUT_FILTER 5 0 1 75 77 ",
"NOTCH_FREQUENCY 5 0 1 73 ",
"OBSERVER 3 5 ",
"RAW_RECORD 5 1 1 6 ",
"RECEIVER_LOCATION 5 1 1 42 44 22 ",
"RECEIVER_STATION_NUMBER 1 93 1 ",
"SAMPLE_INTERVAL 1 59 1000000 ",
"SOURCE_LOCATION 5 1 1 38 40 26 ",
"SHOT_SEQUENCE_NUMBER 1 92 1 ",
"SOURCE_STATION_NUMBER 1 94 1 ",
"STACK 1 16 1 ",
"STATIC_CORRECTIONS 5 0 1 50 51 52 ",
"TRACE_SORT 2 1615 ",
"TRACE_TYPE 4 15 ",
"UNITS 3 8 ",
"AMPLITUDE_RECOVERY 0 0 ",
"BAND_REJECT_FILTER 0 0 ",
"DESCALING_FACTOR 0 0 ",
"DIGITAL_BAND_REJECT_FILTER 0 0 ",
"DIGITAL_HIGH_CUT_FILTER 0 0 ",
"DIGITAL_LOW_CUT_FILTER 0 0 ",
"GENERAL_CONSTANT 0 0 ",
"NOTE 0 0 ",
"POLARITY 0 0 ",
"PROCESSING_DATE 0 0 ",
"PROCESSING_TIME 0 0 ",
"RECEIVER 0 0 ",
"RECEIVER_GEOMETRY 0 0 ",
"RECEIVER_SPECS 0 0 ",
"SKEW 0 0 ",
"SOURCE 0 0 ",
"SOURCE_GEOMETRY 0 0 ",
NULL};
char **defaultsptr=defaults;
char tmpfilename[L_tmpnam];
FILE *tmpfileptr;
tmpnam(tmpfilename);
tmpfileptr=fopen(tmpfilename, "w");
/*fwrite(defaults, sizeof(char), strlen(defaults), tmpfileptr); */
while(*defaultsptr) fprintf(tmpfileptr,"%s\n", *defaultsptr++);
tmpfileptr=freopen(tmpfilename,"r",tmpfileptr);
parseSegyKeys(tmpfileptr, keywords);
fclose(tmpfileptr);
remove(tmpfilename);
} /* end loadSegyKeyTableDefaults() */
/*-----------------------------------------------------------------------
READSEGYKEYS
This routine reads in the valid keywords in file SEGKEYW.ORD
and stores the results in global arrays
----------------------------------------------------------------------*/
void
readSegyKeys (SegyKeyTable *keywords)
{
char *envkeypath;
char *syskeypath;
#ifdef __MSDOS__
char *defpath = "segykeyw.ord";
#else
char *defpath = "/usr/local/lib/segykeyword";
#endif
FILE *keyfile;
syskeypath = (char *) malloc ((strlen(defpath)+1) * sizeof(char));
sprintf (syskeypath, "%s", defpath);
envkeypath = getenv ("SEGKEYPATH");
if (envkeypath != (char *) NULL)
{
if((keyfile=fopen(envkeypath,"rb")) != (FILE *)NULL)
fprintf (stderr, "%s used for header word mapping.\n", envkeypath);
parseSegyKeys(keyfile, keywords);
fclose (keyfile);
}
else if ((keyfile = fopen (syskeypath, "rb")) != (FILE *)NULL)
{
fprintf (stderr, "Using header word mappings in %s\n",defpath);
parseSegyKeys(keyfile, keywords);
fclose (keyfile);
}
else
{
fprintf (stderr, "Using default header word mappings. \n");
loadSegyKeyTableDefaults(keywords);
}
free(syskeypath);
return;
} /* end readsegyKeys() */
/*------------------------------------------------------------
* KEYCHECK
* This routine compares list of keywords with the global string 1 and inserts
* values found in the input string into specified header locations (see
* segykeyw.ord). KEYCHECK checks EVERY keyword for a match. Repeated
* keywords are valid.
* GLOBALS USED:
* totalkeys int
*------------------------------------------------------------*/
void
keycheck (SegyKeyTable *keywords)
{
int i;
int matchfound;
char string2[STRINGWIDTH];
char *token;
/* start a loop for total keys and compare the input with the list */
/* make a copy of string1. strtok destroys it's input during token search*/
/* therefore need to keep a copy for each keyword checked */
strcpy (string2, string1);
/* clear the match found flag */
matchfound = 0;
for (i = 0; i < totalkeys; i++)
{
/*
* restore string1. It will have been destroyed if an
* earlier match has occured.
*/
strcpy (string1, string2);
if (0 == strncmp (string1, keywords[i].segykeyword,
strlen (keywords[i].segykeyword) ) )
{
/* have found a match! Set the matchfound flag */
matchfound = 1;
/* look up the function and implement it. */
switch (keywords[i].segyfunction)
{
case 0:
break; /* null case nothing to do */
case 1:
{
/* function 1 keywords have a single parameter
* in the input; assumed to be a number. */
/* find the parameter. */
/* find first token which will be a keyword */
token = strtok (string1, " ");
/* should be a number. */
token = strtok (NULL, " ");
/* parameter found. pointed to by token. */
/* function 1 calls for the value on the input line to be mulitplied */
/* by segykeyword parm 1. and then inserted into header. */
outhead[keywords[i].segyheader - 1] =
atof (token) * keywords[i].segyparms[0];
break;
}
case 2:
{
/* function 2 is a special function. It has to deal with the special
* case of trace sorting. In this case the parameter on the input
* line is not a number but a char string.
* Notice that spaces in the keywords (i.e. AS ACQUIRED) cause
* the parsing to fail. Words must be 'spaceless' */
token = strtok (string1, " "); /* pointing to keyword. */
token = strtok (NULL, " "); /* token points to input char. */
if (0 == strcmp ("AS_ACQUIRED", token))
segyreelheader[keywords[i].segyheader - 1] = 1;
else if (0 == strcmp ("CDP_GATHER", token))
segyreelheader[keywords[i].segyheader - 1] = 2;
else if (0 == strcmp ("CDP_STACK", token))
segyreelheader[keywords[i].segyheader - 1] = 4;
else if (0 == strcmp ("COMMON_OFFSET", token))
segyreelheader[keywords[i].segyheader - 1] = 3;
else if (0 == strcmp ("COMMON_RECEIVER", token))
segyreelheader[keywords[i].segyheader - 1] = 1;
else if (0 == strcmp ("COMMON_SOURCE", token))
segyreelheader[keywords[i].segyheader - 1] = 1;
else if (0 == strcmp ("METERS",token))
segyreelheader[keywords[i].segyheader -1] = 1;
else if (0 == strcmp ("FEET",token))
segyreelheader[keywords[i].segyheader -1] = 2;
break;
} /* end case 2 */
case 3:
{
/*
* this case requires the text string found on the input
* line to be copied to the SEGY-REEL header at the line
* indicated in the segyheader index. to compute this
* location it is (line#-1)*80
*/
strncpy ((char *) &segyreelheader[80 * (keywords[i].segyheader - 1)],
string1, 80);
break;
} /* end case 3 */
case 4:
{
/* this case, like 2, calls for special string parsing. */
/* for TRACE_TYPE, see code for allowable inputs. */
/* pointing to keyword. */
token = strtok (string1, " ");
/* assume its seismic */
outhead[keywords[i].segyheader - 1] = 1;
/* token points to input char. */
token = strtok (NULL, " ");
if (0 == strcmp ("SEISMIC_DATA", token))
outhead[keywords[i].segyheader - 1] = 1;
else if (0 == strcmp ("DEAD", token))
outhead[keywords[i].segyheader - 1] = 2;
else if (0 == strcmp ("TEST_DATA", token))
outhead[keywords[i].segyheader - 1] = 3;
else if (0 == strcmp ("UPHOLE", token))
outhead[keywords[i].segyheader - 1] = 5;
/* RADAR_DATA not defined in SEG-Y assume it to be normal seismic */
else if (0 == strcmp ("RADAR_DATA", token))
outhead[keywords[i].segyheader - 1] = 1;
break;
} /* end case 4 */
case 5:
{
/* this case calls for the input data to be inserted into the
* sepcified header location of parms 2-10. The normal
* 'header' location indicates the type of data, 0=int,
* 1=long int, 2=floating point. Parm 1 is the multiplier. */
token = strtok (string1, " ");
/* do the integer case first */
if (keywords[i].segyheader == 0) {
int paramcount = 1;
int headindex;
token = strtok (NULL, " "); /* token points to input char. */
while (token != NULL && paramcount < 10) {
headindex = keywords[i].segyparms[paramcount] - 1;
outhead[headindex] = atof (token) * keywords[i].segyparms[0];
paramcount++;
token = strtok (NULL, " "); /* token points next input char. */
}
}
/* do the long integer case next */
else if (keywords[i].segyheader == 1) {
int paramcount = 1;
int headindex;
long *outpoint;
token = strtok (NULL, " "); /* token points to input char. */
while (token != NULL && paramcount < 10) {
/* set outpoint to beginning of WORD of interest */
/* need to subtract 2 from the location value. */
headindex = keywords[i].segyparms[paramcount] - 2;
outpoint = (long *) &outhead[headindex];
/* outpoint now points to the area of interest and is
* typed correctly. Compute the value, cast it and send it in. */
outpoint[0] = (long) (atof (token) * keywords[i].segyparms[0]);
paramcount++;
token = strtok (NULL, " "); /* token points next input char. */
}
}
/* finally do floating point case */
else if (keywords[i].segyheader == 2) {
int paramcount = 1;
int headindex;
float *outpoint;
token = strtok (NULL, " "); /* token points to input char. */
while ((token != NULL) && (paramcount < 10))
{
/* set outpoint to point to beginning of WORD of interest */
/* need to subtract 2 from the location value. */
headindex = keywords[i].segyparms[paramcount] - 2;
outpoint = (float *) &outhead[headindex];
/* outpoint now points to the area of interest and is typed
* correctly. Compute the value, cast it and put it in
* outhead (using outpoint). */
outpoint[0] = (float) (atof (token) * keywords[i].segyparms[0]);
paramcount++;
/* ieee2ibm(outpoint,0); *//* convert to ibm format if necessary */
token = strtok (NULL, " "); /* token points next input char. */
}
}
break;
} /* end case 5 */
case 6:
{
short day, year;
token=strtok(string1," ");
token=strtok(NULL,"/");
day=atoi(token);
token=strtok(NULL,"/");
if (0==strcmp("FEB",token) || 0==strcmp("02",token)) day+=31;
else if(0 == strcmp("MAR",token) || 0== strcmp("03",token)) day+=59;
else if(0 == strcmp("APR",token) || 0== strcmp("04",token)) day+=90;
else if(0 == strcmp("MAY",token) || 0== strcmp("05",token)) day+=120;
else if(0 == strcmp("JUN",token) || 0== strcmp("06",token)) day+=151;
else if(0 == strcmp("JUL",token) || 0== strcmp("07",token)) day+=181;
else if(0 == strcmp("AUG",token) || 0== strcmp("08",token)) day+=212;
else if(0 == strcmp("SEP",token) || 0== strcmp("09",token)) day+=243;
else if(0 == strcmp("OCT",token) || 0== strcmp("10",token)) day+=273;
else if(0 == strcmp("NOV",token) || 0== strcmp("11",token)) day+=304;
else if(0 == strcmp("DEC",token) || 0== strcmp("12",token)) day+=334;
token=strtok(NULL," ");/* token points to input char. */
year=atoi(token);
if(!year%4 && day>59) day+=1; /* Yikes. This may break! */
outhead[keywords[i].segyheader - 2] = year;
outhead[keywords[i].segyheader - 1] = day;
break;
}
default: /* case where function not found.. should never happen */
{
printf ("Function %d not defined.\n", keywords[i].segyfunction);
break;
}
} /* end switch */
break; /* don't go through rest of for() loop, go to next string */
} /* end if */
/* loop through and see if it can be found again */
} /* end of i loop */
if (!matchfound) /* did a match occur */
printf ("No match found for %s\n", string1);
} /* end of keysegy */
int
main (int argc, char *argv[])
{
#define NFILECHAR 32
char prefix[NFILECHAR], seg2file[NFILECHAR],
segyfile[NFILECHAR], suffix[NFILECHAR], str[NFILECHAR];
char *digits = "1234567890";
char stringtermcount, stringterm1, stringterm2;
char linetermcount, lineterm1, lineterm2;
char reserved[19];
unsigned char datatype;
int i, j, k;
short int ssn;
short int reversed = 0;
int curf, lastf;
short int blockid, revnum, pointerbytecount, numtrace, stringlength;
short int first = 1;
size_t l,ln;
unsigned short int blockleng;
long tracepointers[MAXTRACES];
long outbuf[MAXSAMP];
long *outheadl=NULL;
unsigned long numsamples, datalength;
FILE *f1=NULL, *f2=NULL;
SegyKeyTable keywords[MAXKEYWORDS];
double dinbuf[MAXSAMP];
float *finbuf = (float *)dinbuf;
long *linbuf = (long *)dinbuf;
short int *iinbuf = (short int *)dinbuf;
unsigned char *cinbuf = (unsigned char *)dinbuf;
float scale=1;
outheadl = (long *) &outhead[0];
for (i = 0; i < 1800; i++) segyreelheader[i] = 0;
if (argc < 3 || argc > 4) {
printf("Usage: seg2segy first-seg2file number-of-files [shot-number]\n");
exit(-1);
}
sprintf(seg2file,"%s", argv[1]);
if (strchr(seg2file,'.')==NULL)
strcat(seg2file, ".dat");
l = strcspn(seg2file,".");
strncpy(segyfile, seg2file, l);
segyfile[l]='\0';
strcpy(suffix,seg2file+l);
l=strcspn(segyfile,digits);
if (l==strlen(segyfile)
|| strspn(segyfile+l,digits)!=strlen(segyfile+l)){
printf("file name seg2 %s invalid\n", seg2file);
exit(-2);
}
strncpy(prefix, segyfile, l); prefix[l]='\0';
curf=atoi(segyfile+l);
ln=strlen(segyfile+l);
strcat(segyfile, ".sgy");
lastf=curf+atoi(argv[2])-1;
if (argc==4) ssn=atoi(argv[3]); else ssn=1;
f2 = fopen(segyfile, "wb");
if (f2 == (FILE *) NULL) {
fprintf (stderr, "**OUTPUT FILE OPEN FAILURE**\n **ABORTING**\n");
exit (-3);
}
readSegyKeys (keywords);
/* start the big loop ... */
for(; curf<=lastf; curf++) {
strcpy(seg2file,prefix);
sprintf(str,"%d",curf);
l=strlen(str);
while(l<ln) { strcat(seg2file,"0"); l++; }
strcat(seg2file,str);
strcat(seg2file,suffix);
if ((f1=fopen(seg2file,"rb")) == (FILE *)NULL) {
fprintf (stderr, "\n***ERROR OPENING FILE %s***\n", seg2file);
fprintf (stderr, "Skipping to next file number.\n");
continue; /* go to end of loop, try next file */
}
fread (&blockid, 2, 1, f1);
if (blockid == 0x553a)
reversed = 1;
if (blockid != 0x3a55) {
if (!reversed) {
fprintf (stderr, "Not SEG-2 data can not continue\n");
exit (-4);
}
}
fread (&revnum, 2, 1, f1);
fread (&pointerbytecount, 2, 1, f1);
fread (&numtrace, 2, 1, f1);
if (reversed) {
swapshort (&revnum);
swapshort (&pointerbytecount);
swapshort (&numtrace);
}
printf ("File %s, Data Format Revision: %d, Number of traces: %d\n", seg2file, revnum, numtrace);
fread (&stringtermcount, 1, 1, f1);
fread (&stringterm1, 1, 1, f1);
fread (&stringterm2, 1, 1, f1);
fread (&linetermcount, 1, 1, f1);
fread (&lineterm1, 1, 1, f1);
fread (&lineterm2, 1, 1, f1);
fread (reserved, 1, 18, f1); /* reserved block, not used */
if (numtrace > (pointerbytecount / 4)) {
fprintf (stderr, "Number of traces greater than number of trace pointers\n");
fprintf (stderr, "Number of pointers = %d\n", pointerbytecount / 4);
fprintf (stderr, "Due to this inconsistency processing must stop\n");
exit (-5);
}
fread (tracepointers, 4, numtrace, f1);
if (reversed) {
for (i = 0; i < numtrace; i++)
swaplong (&tracepointers[i]);
}
/* now read file descriptor block. */
fread (&stringlength, 2, 1, f1);
if (reversed)
swapshort (&stringlength);
while (0 != stringlength) {
fread (string1, 1, stringlength - 2, f1);
keycheck (keywords);
fread (&stringlength, 2, 1, f1);
if (reversed) swapshort (&stringlength);
}
for (j = 0; j < numtrace; j++) {
for (i = 0; i < 120; i++)
outhead[i] = 0;
printf ("trace-%d-\r", j + 1); fflush(stdout);
fseek (f1, tracepointers[j], SEEK_SET);
fread (&blockid, 2, 1, f1);
if (reversed)
swapshort (&blockid);
if (blockid == 0x2244) {
/* reversed=1; should already know this */
fprintf (stderr, "Opps, I've blown it here.... (line:%d)\n", __LINE__);
exit (-6);
}
if (blockid != 0x4422) {
fprintf (stderr, "Not a SEG-2 trace header. Can not process %x (line %d)\n", blockid, __LINE__);
exit (-7);
}
fread (&blockleng, 2, 1, f1);
if (reversed)
swapshort ((short *) &blockleng);
fread (&datalength, 4, 1, f1);
if (reversed)
swaplong ((long *) &datalength);
fread (&numsamples, 4, 1, f1);
if (reversed)
swaplong ((long *) &numsamples);
if (numsamples >= MAXSAMP){
fprintf(stderr, "Your data contains more samples than I can handle\n");
exit(-8);
}
fread (&datatype, 1, 1, f1);
fprintf(stderr,"Data type = %d \n", (int) datatype);
if (datatype > 5 || datatype < 1) {
fprintf (stderr,"Data type %d not available/valid\n", (int) datatype);
break;
}
outhead[57] = numsamples;
fread (reserved, 1, 19, f1);
fread (&stringlength, 2, 1, f1);
if (reversed)
swapshort (&stringlength);
while (0 != stringlength) {
fread (string1, 1, stringlength - 2, f1);
keycheck (keywords);
fread (&stringlength, 2, 1, f1);
if (reversed)
swapshort (&stringlength);
}
fseek (f1, blockleng + tracepointers[j], SEEK_SET);
switch ((int) datatype)
{
case 1:
fread (iinbuf, 2, (int) numsamples, f1);
if (reversed) {
for (i = 0; i < (int) numsamples; i++)
swapshort (&iinbuf[i]);
}
for (k = 0; k < numsamples; k++)
outbuf[k] = iinbuf[k];
break;
case 2:
fread (linbuf, 4, (int) numsamples, f1);
if (reversed) {
for (i = 0; i < (int) numsamples; i++)
swaplong (&linbuf[i]);
}
for (k = 0; k < numsamples; k++)
outbuf[k] = linbuf[k];
break;
case 3:
{
unsigned long totalbytes, subpointer;
unsigned int expo;
long longdat;
short int sdata; /*modified version by PM */
totalbytes = (numsamples * 5) / 2;
fread (cinbuf, 1, (size_t) totalbytes, f1);
/* Original Code SU-36 3rd Party
for (k = 0; k < (numsamples);) {
subpointer = (k / 4) * 5;
expo = (unsigned) iinbuf[subpointer++];
for (i = 0; i < 4; i++) {
if (0x8000 & iinbuf[subpointer])
longdat = 0xffff8000;
else
longdat = 0;
longdat = longdat | ((long) iinbuf[subpointer++] << (0x000f & expo));
expo >>= 4;
outbuf[k++] = longdat;
}
}
*/
/*modified version by P.Michaels <pm@cgiss.boisestate.edu> */
/*fixes sawtooth conversion error on large negative values */
for (k = 0; k < (numsamples);) {
subpointer = (k / 4) * 5;
expo = (unsigned) iinbuf[subpointer++];
for (i = 0; i < 4; i++) {
sdata=iinbuf[subpointer++];
if (sdata>0)
{
longdat=(long) sdata;
longdat=longdat << (0x000f & expo);
}
else
{
longdat=(long) -sdata;
longdat=longdat << (0x000f & expo);
longdat = -longdat;
} /* endif */
expo >>= 4;
outbuf[k++] = longdat;
} /* next i */
} /* next k */
/* end of modifications */
if (reversed) {
for (i = 0; i < numsamples; i++)
swaplong (&outbuf[i]);
}
}
break;
case 4:
fprintf(stderr,"Reading type 4/n");
fread (finbuf, 4, (int) numsamples, f1);
if (reversed) {
long *buf = (long *) dinbuf;
for (i = 0; i < numsamples; i++)
swaplong (&buf[i]);
}
/* scale values */
for (k = 0; k < numsamples; k++)
outbuf[k] = finbuf[k]/scale;
for (k = 0; k < numsamples; k++)
fprintf(stderr,"dataval = %ld \n", outbuf[k]);
fprintf(stderr," if dataval = 0 then increase the value of scale, recompile\n");
break;
case 5:
fread (dinbuf, 8, (int) numsamples, f1);
if (reversed) {
long *buf = (long *) dinbuf;
for (i = 0; i < numsamples * 2; i++)
swaplong (&buf[i]);
}
for (k = 0; k < numsamples; k++)
outbuf[k] = dinbuf[k];
break;
} /* end switch */
/* set vertical stack traces=1 */
/*
if(outhead[15]==0) outhead[15]=1;
if(outheadf[59]==0.0) gain=1.; else gain=outheadf[59];
for(i=0;i<numsamples;i++)
outbuf[i]*=gain/outhead[15];
*/
/* assign the original field record number as the current file number */
if (outheadl[2] == 0) outheadl[2] = (long) curf;
/* set trace type as sesmic data */
if (outhead[14] == 0) outhead[14] = 1;
/* set last trace flag (modified segy) */
if (j == numtrace - 1 && outhead[87] == 0) {
outhead[87] = 1;
ssn = ssn + 1;
}
/* from rec-station-number and source-station-number (93 and 94) */
/* distance from source to receiver */
/* outheadl[9]=(long)(abs(outhead[93]-outhead[92])); */
/* set group for trace one and roll switch position */
outhead[85] = outhead[86] =
(int) (1 + labs ((long) outhead[92] - outheadl[3]));
/* special case, execute on first pass only... */
if (first == 1) {
first = 0;
segyreelheader[1606] = numtrace;
segyreelheader[1608] = outhead[58];
segyreelheader[1609] = outhead[58];
segyreelheader[1610] = numsamples;
segyreelheader[1611] = numsamples;
segyreelheader[1612] = 2;
if (!reversed) /* swap only if we are on a little endian machine */
{
for (k = 1600; k < 1606; k += 2)
swaplong ((long *)&segyreelheader[k]);
for (k = 1606; k < 1630; k++)
swapshort((short *)&segyreelheader[k]);
}
fwrite (segyreelheader, 1, 3600, f2); /* create the segy headers */
}
if (!reversed) { /* swap only if we are on a little endian machine */
/* first swap longs */
for (k = 0; k < 7; k++)
swaplong((long *)&outheadl[k]);
for (k = 9; k < 17; k++)
swaplong((long *)&outheadl[k]);
for (k = 18; k < 22; k++)
swaplong((long *)&outheadl[k]);
/* now swap the shorts */
for (k = 14; k < 18; k++)
swapshort((short *)&outhead[k]);
for (k = 34; k < 36; k++)
swapshort((short *)&outhead[k]);
/* for(k=44;k<90;k++) *//* error: should have gone beyond 95 word */
for (k = 44; k < 95; k++)
swapshort((short *)&outhead[k]);
}
if (120 != (k = fwrite (outhead, 2, 120, f2))) { /* write header */
fprintf (stderr,"\nWrite failure during header write\n");
exit (-9);
}
if (!reversed) {
for (k = 0; k < numsamples; k++)
swaplong ((long *)&outbuf[k]);
}
if ((int) numsamples != (k = fwrite (outbuf, 4, (int) numsamples, f2))) {
fprintf (stderr,"Write failure during trace write\n");
exit (-10);
}
} /* end trace loop */
fclose (f1);
outhead[87] = 0; /* reset last trace flag. */
} /* end kk loop */
fclose(f2);
return 0;
} /* end main */
以上代码可以顺利将外部磁盘中的SEISMIC BINARY DATA读取到内存中。特别是MATLAB的MAT二进制格式是处理所有数据的基础。
在matlab version 5中,MAT文件由一个128字节的文件头和若干个数据单元组成。每个数据单元有一个8个字节的tag,用于说明数据单元的占用的字节数(不包括tag的8个字节)和数据类型。
文件头header里有124字节的文本描述区域和4个字节的flag。flag中的前2个字节说明version,后两个字节是endian indicator。文本描述区域主要说明MAT文件的版本,创建于哪个平台,创建时间。flag中的version说明的是创建这个MAT文件的matlab的版本。edian indicator包括两个字符M和I。
char mat_data_fhead1[51] =
{"MATLAB 5.0 MAT-file, Platform: PCWIN, Created on: "};
char mat_data_fhead2[51] = {" "};
char mat_data_fhead3[4] = {0, 0x01, 0x49, 0x4d};
char* datetime = NULL;
time_t ltime;
tm* today;
time(ltime);
today = localtime(ltime);
datetime = asctime(today);
fwrite(mat_data_fhead1, 1, 50, fp);
fwrite(datetime, 1, 24, fp);
fwrite(mat_data_fhead2, 1, 50, fp);
fwrite(mat_data_fhead3, 1, 4, fp);
关于edian:endian: The ordering of bytes in a multi-byte number.
定义:在计算机系统体系结构中用来描述在多字节数中各个字节的存储顺序。相关概念还有MSB(Most Significant Bit/Byte)和LSB(Least Significant Bit/Byte)。在所有的介绍字节序的文章中都会提到字节序分为两类:Big-Endian和Little-Endian。引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
c) 网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
PS:有些文章中称低位字节为最低有效位,高位字节为最高有效位。
如果edian indicator中的值为MI,则读取MAT数据时应该用IM的顺序。若对于16bit的数据,则要进行两个字节数据的交换。
数据单元的格式
每个数据单元开头都有8个字节的tag用于说明数据单元存储的数据类型和字节数(不包括tag的8个字节)。version5支持多种数据类型。data type中的值为1到14。除了用数值表示某种类型外,还用标识单词联系一种类型。例如data type中存储的是数值1时,代表8bit singed,它的标识单词就为miINT8,方便了用户记忆。值14的标志单词是miMATRIX,代表一种矩阵数据。
数据单元tag中的字节数是每个数据单元不包括8个字节tag的数据字节个数。
接下来的就是存储的数据。数据需要64bit对齐,不够时要补齐到64bit。数据类型是miMATRIX时,数据单元tag中字节数包括矩阵中每个padding的数据个数。其他数据类型时,字节数不包括padding的个数。
当存储的数据不超过4个字节时,还可以采用压缩的数据单元格式。用4个字节存储tag,另外4个字节存储数据。在编程时,tag的前两个字节不为零时,则说明采用的是压缩的数据单元格式。在把数据写入MAT文件中时,压缩的数据单元格式是优先选择的。
datatype值为14的数据类型是:array data,包括了各种类型的array,如数值矩阵,字符矩阵,稀疏矩阵。是一种复合类型结构。字节数包括所有subelement字节数之和。每个subelement都有自己的tag。主要有array flags, dimensions array subelement, array name subelement, real part(pr)subelement, image part subelement。
下图为MAT文件格式的FORTRAN,C等语言的读写程序:
2.python中的obspy及sgyio库的调用
下面以obspy库的调用为例,打开一个sgy文件的命令:
import obspy
t=obspy.read('Model+GathEP-Z.sgy')
tr=t[0]
print(tr.stats)
network:
station:
location:
channel:
starttime: 1970-01-01T00:00:00.000000Z
endtime: 1970-01-01T00:00:00.485200Z
sampling_rate: 2500.0
delta: 0.0004
npts: 1214
calib: 1.0
_format: SEGY
segy: AttribDict({'trace_header': LazyTraceHeaderAttribDict({'unpacked_header': b'\x00\x00\x00\x01\x00\x00\x00\x01\x00\x00\x00\x01\x00\x00\x00\x01\x00\x00\x00\x01\x00\x00\x00\x01\x00\x00\x00\x01\x00\x01\x00\x00\x00\x00\x00\x01\xff\xff\xfe\x0c\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xff\x9c\xff\x9c\x00\x00\xc3P\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x04\xbe\x01\x90\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00', 'endian': '>', 'sample_interval_in_ms_for_this_trace': 400, 'year_data_recorded': 0})})
>>> tr.plot()

单道地震数据显示
对于地震多道剖面数据显示,需要计算偏移距
>>> i=0
>>> for tr in t:
... i=i+1
... tr.stats.distance=i*10
...
>>> t.plot(type='section')
>>pip install ipykernel
>>python -m ipykernel install --user --name python33 --display-name python33
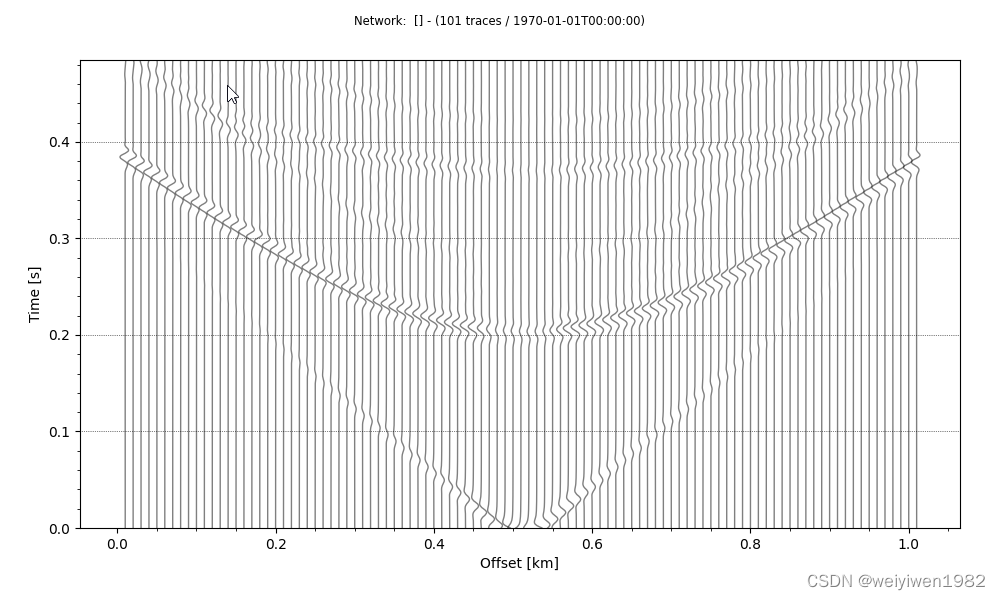
地震剖面数据显示
读取地震事件的函数为obspy.readevents('*.ndx')


[2]https://pubs.usgs.gov/of/2003/ofr-03-141/ofr_03_141_508.pdf
[3]Seismic Conversion Shareware
[4]Barry, K. M., Cavers, D. A. and Kneale, C. W., 1975, Report on recommended standards for digital tape formats: Geophysics, Soc. of Expl. Geophys., 40, 344-352. Dobrin, M. B., 1960, [5]Geophysical prospecting: McGraw-Hill, pp 71-73. Pullan, S. E., 1990, Recommended standard for seismic (/radar) files in the personal computer environment: Geophysics, Soc. of Expl. Geophys., 55, 1260-1271.
[5]http://www.interpex.com/ftp/ixseg2segy/ixseg2segysetup.exe
[6]https://www.interpex.com/ftp/ixseg2segy/ixseg2segymanual.pdf


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











