







# 地理空间数据聚类
%matplotlib inline
import numpy as np,pandas as pd,matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from geopy.distance import great_circle
from shapely.geometry import MultiPoint,Polygon
from geopy.geocoders import Nominatim
from geopy.point import Point
import geopandas as gpd
from sklearn.preprocessing import StandardScaler,minmax_scalepath=r"GPS.csv"
df=pd.read_csv(path,index_col=0,usecols=[1,2,3,4],parse_dates=[3])
df=df[(df.latitude!=0) & (df.longitude >73.3)].drop_duplicates()
df_sort=df.groupby(by=df.index).count().sort_values(by="longitude",ascending=False)
dfIndex=df_sort[df_sort.longitude>30].index
dftest=df.loc[dfIndex]
dftest.head()| latitude | longitude | create_time | |
|---|---|---|---|
| custorm_id | |||
| 206301 | 39.842956 | 117.633808 | 2016-08-19 20:27:00 |
| 206301 | 39.842868 | 117.633726 | 2016-08-19 20:11:00 |
| 206301 | 39.842754 | 117.633703 | 2016-08-19 19:50:00 |
| 206301 | 39.842852 | 117.633790 | 2016-08-19 19:38:00 |
| 206301 | 39.842839 | 117.633791 | 2016-08-19 18:56:00 |
2.数据转换
- 经纬度解析出城市
def parse_city(latlng):
try:
locations=geolocator.reverse(Point(latlng),timeout=10)
loc=locations.raw[u'address']
if u'state_district' in loc:
city=loc[ u'state_district'].split('/')[0]
else :
city =loc[u'county'].split('/')[0] # 直辖市
except Exception as e:
print e
city=None
try:
state= loc[u'state']
except Exception as e:
print e
state=None
return city,state
def parse_state(latlng):
try:
locations=geolocator.reverse(Point(latlng),timeout=10)
loc=locations.raw
state= loc[u'address'][u'state']
except Exception as e:
print e
state=None
return state
geolocator = Nominatim()
latlngs=df.ix[:,['longitude','latitude']].values
df['city']=map(parse_city,latlngs)
df['state']=map(parse_state,latlngs)3.聚类分析
coords=dftest.as_matrix(columns=['longitude','latitude'])
kms_per_radian = 6371.0088
epsilon = 10/ kms_per_radian
db = DBSCAN(eps=epsilon, min_samples=80, algorithm='ball_tree', metric='haversine').fit(np.radians(coords))
cluster_labels = db.labels_
num_clusters = len(set(cluster_labels))
clusters = pd.Series([coords[cluster_labels == n] for n in range(num_clusters)])
print('Number of clusters: {}'.format(num_clusters))Number of clusters: 110
3.1类的中心点
def get_centermost_point(cluster):
centroid = (MultiPoint(cluster).centroid.x, MultiPoint(cluster).centroid.y)
centermost_point = min(cluster, key=lambda point: great_circle(point, centroid).m)
return tuple(centermost_point)
centermost_points = clusters[:-1].map(get_centermost_point)
3.2 类中心原始数据
lons, lats = zip(*centermost_points)
rep_points = pd.DataFrame({'lon':lons, 'lat':lats})
rs = rep_points.apply(lambda row: dftest[(dftest['latitude']==row['lat']) &(dftest['longitude']==row['lon'])].iloc[0], axis=1)4.数据可视化
4.1 二维坐标
fig, ax = plt.subplots(figsize=[10,6])
rs_scatter = ax.scatter(rs['longitude'], rs['latitude'], c='#99cc99', edgecolor='None', alpha=0.7, s=120)
df_scatter = ax.scatter(df['longitude'], df['latitude'], c='k', alpha=0.9, s=3)
ax.set_title('Full data set vs DBSCAN reduced set')
ax.set_xlabel('Longitude')
ax.set_ylabel('Latitude')
ax.legend([df_scatter, rs_scatter], ['Full set', 'Reduced set'], loc='upper right')
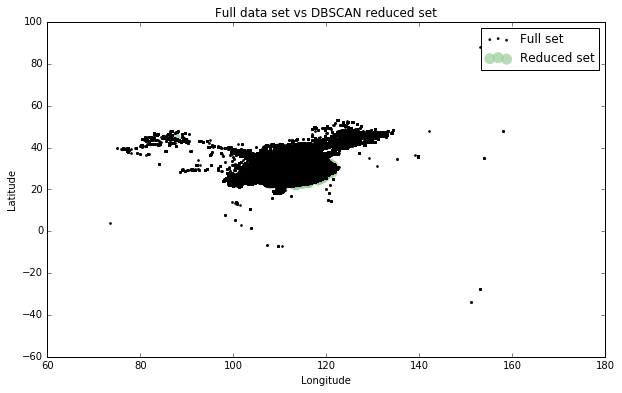
4.2 确定坐标的范围
margin_width = 0
lon_range = [rs['longitude'].min() - margin_width, rs['longitude'].max() + margin_width]
lat_range = [rs['latitude'].min() - margin_width, rs['latitude'].max() + margin_width]
spatial_extent = Polygon([(lon_range[0], lat_range[0]),
(lon_range[0], lat_range[1]),
(lon_range[1], lat_range[1]),
(lon_range[1], lat_range[0])])
4.3中国省级行政区地图
file_path=r'E:\workpalce\Python\regular_python\IP_location_wordpress-master\date\Lambert\省级行政区.shp'.decode('utf-8')
world=gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
china_map=gpd.read_file(file_path)
china_map=china_map.to_crs(world.crs)
china_map.plot(color='white',figsize=(20,20))
4.4 地理坐标中的聚类分析
import bokeh
from bokeh import mpl
from bokeh.plotting import output_file, show
import matplotlib.pylab as pylab
pylab.rcParams['figure.figsize'] = 20, 20
china_map=china_map[china_map['geometry'].intersects(spatial_extent)]
fig=plt.figure()
#set the figure dimensions to the extent of the coordinates in our data
ydimension = int((lat_range[1] - lat_range[0]) / 4)
xdimension = int((lon_range[1] - lon_range[0]) / 4)
fig.set_size_inches(xdimension, ydimension)
# plot the country boundaries and then our point data
china_map.plot(colormap='binary', alpha=0)
scal=minmax_scale([len(line) for line in clusters[:-1]])
rs_scatter = plt.scatter(x=rs['longitude'], y=rs['latitude'], c=scal+10, edgecolor='white', alpha=.9, s=scal*6000) # 自己的行为轨迹
# rs_scatter = p.circle(np.array(rs['longitude']), np.array(rs['latitude']), fill_color=scal, alpha=.9, radius=scal*100) # 自己的行为轨迹
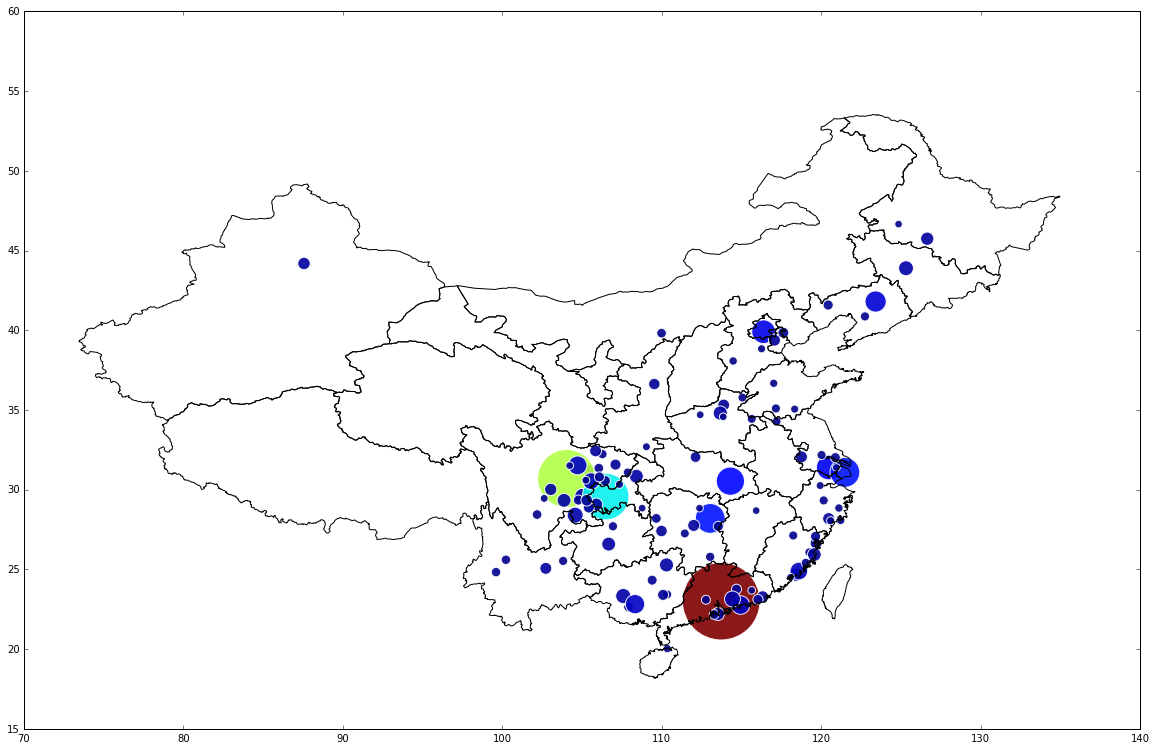
TOPN
每个人的地理位置信息进行DBSCAN聚类分析,得出用户活动范围最为频繁的TopN个地点,本文人为一个人在5公里活动区域内为一个“共现区域”,在一个地点活动至少2次才能被认为是“共现区域”,下面是样例代码,在实际操作中由于数据量比较大,可以才用多线程或者分布式的方式实现速度的提升。
def getPersonlMost(dft):
coords=dft.as_matrix(columns=['longitude','latitude'])
kms_per_radian = 6371.0088
epsilon = 5/ kms_per_radian
db = DBSCAN(eps=epsilon, min_samples=2, algorithm='ball_tree', metric='haversine').fit(np.radians(coords))
cluster_labels = db.labels_
num_clusters = len(set(cluster_labels))
clusters = pd.Series([coords[cluster_labels == n] for n in range(num_clusters)])
clusters=pd.Series([line for line in clusters if len(line)>0])
sorted_cluster=sorted([(get_centermost_point(line),len(line)) for line in clusters],key = lambda x:x[1],reverse=True)[:3]
return sorted_cluster
path="GPSA.csv"
df=pd.read_csv(path,index_col=0,usecols=[1,2,3,4],names=['custorm_id','longitude','latitude','createtime'])
df=df[(df.latitude!=0) & (df.longitude >73.3)].drop_duplicates()
df_sort=df.groupby(by=df.index).count().sort_values(by="longitude",ascending=False)
dfIndex=df_sort[df_sort.longitude>5].index
dftest=df.loc[dfIndex].dropna()
dftest.to_csv("deftest.csv")TopN=[]
import csv
# path=r"D:\学习资料\数据\GPSA.csv".decode('utf-8')
# df=pd.read_csv(path,index_col=0,header=[u'custorm_id',u'latitude', u'longitude', u'create_time'])
# df=df[(df.latitude!=0) & (df.longitude >73.3)].drop_duplicates()
# df_sort=df.groupby(by=df.index).count().sort_values(by="longitude",ascending=False)
# dfIndex=df_sort[df_sort.longitude>30].index
# dftest=df.loc[dfIndex]
dftest=pd.read_csv("deftest.csv",index_col=0).drop_duplicates().dropna()
cnt=0
for line in dftest.index.unique():
cnt+=1
if cnt%1000==0:
print cnt
dfs=dftest.loc[line]
cc=getPersonlMost(dfs)
TopN.append(cc)
peronalMost=pd.DataFrame(TopN,index=dftest.index.unique(),columns=["mostly",'secondly','merely'])
peronalMost.to_csv("personal_most.csv")总结
本文主要是对位置信息进行简单的分析聚类,可以看出人群主要分布情况,以及每个人主要活动的几个区域。其实地理位置信息可以获取很多的个人信息,比如根据其活动的区域的经济状况可以大体推算出其经济水平,通过其活动的范围大小,离散程度等等情况分析其一些行为和心理上的特征。本文只取地理位置数据进行分析,而因为各种原因,没有在时间维度上进行探索,这也是一个前进的方向,基于时空数据的分析,是当下数据挖掘领域较为火热的领域。无论是个人征信系统的建立、还是用户行为的分析,随着物联网的兴起,物联网上数量庞大的传感器的数据也是基于时间和空间的数据,你也许根据数据去预测地震、海啸、森林火灾、水资源的污染,甚或者你可以深入到智能家居,智能电网、智能交通等等智慧城市的各个领域。时间虽然过去了,但它留下了财富,空间虽然不断变换,我们亦可以追本溯源。















 3003
3003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









