







Redis简介
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.
Redis是一个开源的内存数据结构存储引擎,可用作数据库,缓存和消息队列。
Redis的主要特点
Redis具有速度快、数据结构丰富、过期设置和淘汰策略、支持事务、支持持久化、支持复制和分布式集群等主要特点。
- 速度快。基于内存、C语言实现、单线程(非阻塞IO多路复用和流水线)、设计精妙
- 基于键值对的数据结构服务器。字符串、 哈希、 列表、 集合、 有序集合,还有位图和HyperLogLog,geospatial index和stream
- 丰富的功能:
- 键过期功能,实现缓存
- 发布订阅,实现消息系统
- Lua脚本,创建新的命令
- 事务功能
- 流水线功能
- 简单稳定。源码精简、单线程、不依赖操作系统库
- 客户端语言多
- 持久化:RDB和AOF
- 主从复制
- 高可用和分布式:Redis Sentinel、Redis Cluster
Redis的使用场景
- 缓存。键过期时间设置和灵活的淘汰策略,字符串和hash
- 排行榜。合理运用列表和有序集合
- 计数器。redis天然支持计数功能且性能很好
- 社交网络。点赞、收藏、好友、推送等等
- 消息系统。阻塞队列(lpush+brpop);发布订阅(publish+subscribe+unsubscribe)
- 分布式ID生成器,分布式锁等
- 内存很贵,Redis不能做:大数据、冷数据
Redis数据结构典型应用
字符串:实际可以是整型、字符型、二进制数据。可用于:
- 缓存,如页面缓存
- 计数,如视频播放次数、分布式id
- 共享session、分布式锁
- 限速限流,按次数或按时间间隔
哈希:hash基于field-value的形式保存数据,适用于对象或表记录缓存,如缓存用户信息。
列表:灵活运用列表可以实现队列、栈等等,具体为:
- 消息队列,lpush+brpop
- 分页列表,如分页获取文章列表,lrange user:1:articles 0 9
- 栈,后进先出,lpush+lpop
- 队列,先进先出,lpush+rpop
- 有限集合,lpush+ltrim
集合:元素唯一的特点,特别适用于标签系统。
有序集合:元素唯一,且支持排序,带分数score的集合,特别适用于排行榜系统。
位图:本质是字符串,提供位操作,主要优势是节约内存,运用于状态保存。例如对所有用户,记录每个用户是否访问过某个页面。
Redis命令处理过程

为什么redis使用单线程模型?
先考虑为什么要用多线程?多线程收益最明显的场景有:
- 可并行化的大数据计算:redis主要作缓存,复杂计算少,排除这一点
- IO:redis基于内存,IO操作少,只有持久化和网络处理时有IO情况。而且redis使用非阻塞IO多路复用机制进行优化,还使用了客户端缓冲,AOF缓冲等优化手段。
所以,redis从多线程模型获取的收益很小,而且多线程也有缺点,如线程创建和上下文切换的开销,线程同步的复杂性等等。
持久化:RDB
RDB是Redis的一种持久化机制,RDB会生成当前进程数据的快照并保存到磁盘。
可以配置rdb文件路径和文件名称:
config set dir{newDir}
config set dbfilename{newFileName}
RDB可以通过命令手动触发:
- save: 阻塞会当前Redis服务器, 直到RDB过程完成为止。
- bgsave: Redis进程fork创建子进程, RDB持久化过程由子进程负责, 完成后自动结束。
RDB还支持自动触发:
- 使用 save m n 命令,m秒内存在n次修改,则自动触发bgsave
- 如果从节点执行全量复制,则主节点自动执行bgsave生成rdb文件并发给从节点
- 使用 debug reload 命令,会触发save命令,不建议使用
- 如果没有开启AOF,shutdown命令会触发bgsave
RDB优缺点:
- RDB是快照,代表redis某个时间点完整的数据状态,所以非常适用于备份和全量复制等场景。
- Redis加载RDB恢复数据远远快于AOF的方式。
- RDB文件时二进制文件,兼容性差。
持久化:AOF
AOF即 append only file,只可追加不可修改,这种特性应用广泛,如kafka的log。
Redis开启AOF持久化时,会记录每次写命令到AOF中,重启时再重新执行AOF文件中的命令。aof文件是文本格式的,使用Redis序列化协议(RESP)。
AOF解决了RDB实时性不高的问题,因此在实时性高的场景应用非常广泛。
配置AOF:
config set appendonly yes
config set dir{newDir}
config set appendfilename{newFileName}
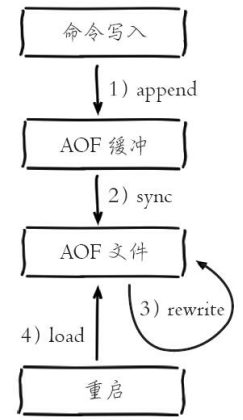
AOF工作机制
- 所有的写入命令会追加到aof_buf中。
- aof_buf 根据对应的策略向硬盘做同步操作。
- 随着AOF文件越来越大, 需要定期对AOF文件进行重写, 达到压缩的目的。
- 当Redis服务器重启时, 可以加载AOF文件进行数据恢复。
AOF同步策略
Redis支持不同的AOF同步策略,由appendfsync参数控制:
- always,命令写入aof_buf后调用fsync同步到aof文件,完成后线程返回
- everysec,命令写入aof_buf后调用write,完成后线程返回。同步过程由另一个线程每秒调用一次fsync执行
- no,命令写入aof_buf后调用write,完成后线程返回。redis不做fsync操作,由操作系统负责同步,通常不超过30秒
建议配置为everysec,也是默认配置, 做到兼顾性能和数据安全性。
AOF文件重写
AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。AOF文件重写能压缩aof文件体积,这样占用空间小了,也加速了redis加载过程。
为什么重写可以压缩文件体积?
- 很多过期了的命令,在重写时不会写入新aof
- 旧的AOF文件中有很多无效的命令,例如删除命令del,这些命令不会写入新aof
- 多条命令可以合并为一条命令
AOF重写如何使用?
- 手动触发: 直接调用bgrewriteaof命令。
- 自动触发: 根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机。
所以自动触发AOF文件重写的时机是:
自动触发时机 =
(aof_current_size > auto-aof-rewrite-minsize)&&
((aof_current_size - aof_base_size)/aof_base_size >= auto-aof-rewritepercentage)
//aof_current_size = 当前AOF文件大小
//aof_base_size = 上一次重写后的AOF文件大小
//可通过 info Persistence查看
AOF重写过程?

1)执行AOF重写请求
2)父进程调用fork创建子进程 。
3)父进程继续响应请求,处理命令:
- 所有修改命令依然写入AOF缓冲区并根据appendfsync策略同步到硬盘,保证原有AOF机制正确性。
- 由于fork操作运用写时复制技术,子进程只能共享fork操作时的内存数据。由于父进程依然响应命令,Redis使用“AOF重写缓冲区”保存这部分新数据,防止新AOF文件生成期间丢失这部分数据。
4)子进程根据内存快照,按照命令合并规则写入到新的AOF文件。每次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘阻塞。
5)子进程写入AOF文件完成:
- 新AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息,具体见info persistence下的aof_*相关统计。
- 父进程把AOF重写缓冲区的数据写入到新的AOF文件。
- 使用新AOF文件替换老文件, 完成AOF重写。
Redis内存消耗
使用 info memory 命令可以查看内存相关指标,其中三个指标非常重要。
- used_memory_rss:操作系统为redis分配的实际物理内存
- used_memory:redis内存分配器分配的内存,即redis的虚拟内存
- mem_fragmentation_ratio:两者比值。
- 小于1时,表示实际物理内存小于虚拟内存。很可能是操作系统把一部分redis内存SWAP出去了,redis性能会下降。
- 小于1时,表示实际物理内存大于大于虚拟内存,这是由内存碎片引起的。
Redis进程内消耗主要包括: 自身内存+对象内存+缓冲内存+内存碎片。
自身内存很小,基本可以忽略不记。

1.对象内存
对象内存是Redis内存占用最大的一块, 存储着用户所有的数据。 Redis所有的数据都采用key-value数据类型,每次创建键值对时,至少创建两个类型对象:key对象和value对象。对象内存消耗可以简单理解为sizeof(keys)+sizeof(values)。
2.缓冲内存
缓冲内存主要包括: 客户端缓冲、 复制积压缓冲区、 AOF缓冲区
客户端缓冲区
所有接入到Redis服务器TCP连接的输入输出缓冲。
输入缓冲无法控制,最大空间为1G,如果超过将断开连接,可配置maxclients。
输出缓冲通过参数client-output-buffer-limit控制,按客户端类型分为:
- 普通客户端:client-output-buffer-limit norma1000 ,一般可忽略不计。
- 从客户端:主节点会为每个从节点单独建立一条连接用于命令复制,client-output-buffer-limit slave256mb64mb60。
- 订阅客户端:当使用发布订阅功能时,连接客户端使用单独的输出缓冲区,client-output-buffer-limit pubsub32mb8mb60
复制积压缓冲区
一个用于实现部分复制功能的可重用的固定大小缓冲区,根据 repl-backlog-size 参数控制,默认1MB,可根据实际情况调大,如100MB。
AOF缓冲区
这部分空间用于在Redis重写期间保存最近的写入命令,AOF缓冲区空间消耗用户无法控制,消耗的内存取决于AOF重写时间和写入命令量,这部分空间占用通常很小。
Redis内存管理
Redis主要通过控制内存上限和回收策略实现内存管理。
Redis使用 maxmemory 参数限制最大可用内存。 限制内存的目的主要有:
- 用于缓存场景, 当超出内存上限maxmemory时使用LRU等删除策略释放空间。
- 防止所用内存超过服务器物理内存。
Redis的内存回收机制主要体现在以下两个方面:
- 删除到达过期时间的键对象。
- 内存使用达到maxmemory上限时触发内存溢出控制策略。
删除过期键对象机制
Redis所有的键都可以设置过期属性, 内部保存在过期字典中。
Redis采用惰性删除和定时任务删除机制实现过期键的内存回收。
惰性删除是指,当客户端读取超时的键时,会执行删除操作并返回空。这种策略是出于节省CPU成本考虑,不需要单独维护TTL链表来处理过期键的删除。
定时任务删除是指,Redis内部维护一个定时任务来删除过期键,默认每秒运行10次(通过配置hz控制)。
定时任务删除过期键逻辑采用了自适应算法,根据键的过期比例、使用快慢两种速率模式回收键。

1)定时任务在每个数据库空间随机检查20个键, 当发现过期时删除对应的键。
2)如果超过检查数25%的键过期,循环执行回收逻辑,直到不足25%或运行超时为止。慢模式下超时时间为25毫秒。
3)如果之前回收键逻辑超时,则在Redis触发内部事件之前再次以快模式运行回收过期键任务,快模式下超时时间为1毫秒且2秒内只能运行1次。
4)快慢两种模式内部删除逻辑相同,只是执行的超时时间不同。
内存溢出控制策略
当Redis所用内存达到maxmemory上限时会触发相应的溢出控制策略。具体策略受maxmemory-policy参数控制,如下所示:
- noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息(OOM command not allowed when used memory),此时Redis只响应读操作。
- volatile-lru:根据LRU算法删除设置了超时属性的键,直到腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略。
- allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
- allkeys-random:随机删除所有键,直到腾出足够空间为止。
- volatile-random:随机删除过期键,直到腾出足够空间为止。
- volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有, 回退到noeviction策略。















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









