






 本文讲述了在生产环境中如何构建高可用的k8s集群,包括使用etcd外接集群,并详细介绍了etcd的snapshot备份方法,备份频率,以及在数据丢失后如何通过snapshot恢复etcd和k8s服务的过程。
本文讲述了在生产环境中如何构建高可用的k8s集群,包括使用etcd外接集群,并详细介绍了etcd的snapshot备份方法,备份频率,以及在数据丢失后如何通过snapshot恢复etcd和k8s服务的过程。
环境
master节点
| 主机 | IP | 版本 |
| master01 | 192.168.66.50 | k8s-1.23.17 |
| master02 | 192.168.66.55 | k8s-1.23.17 |
| master03 | 192.168.66.56 | k8s-1.23.17 |
etcd集群节点
| 主机 | IP | 版本 |
| etcd01 | 192.168.66.58 | 3.5.6 |
| etcd02 | 192.168.66.59 | 3.5.6 |
| etcd03 | 192.168.66.57 | 3.5.6 |
生产环境中我们为了避免出现误操作或者是服务器硬件出见异常导致宕机,我们的虚拟机或者k8s集群崩溃,所以我们都会创建多节点的高可用集群,包括k8s集群使用外接etcd集群,但有时也可能出现数据丢失,所以经常要备份数据。
etcd备份
etcd集群的备份我们使用snapshot备份etcd集群数据
备份一般会使用脚本备份,三个etcd节点分别备份(虽然每份etcd节点的数据相同,但防止虚拟机宕机起不来,所以最好三个节点都备份,每小时备份一次,创建一个备份计划任务):
#!/bin/bash
#
###etcd cluster backup
time_back=`date +%Y%m%d-%H%M%S`
path='/etc/etcd/snapshot/'
/usr/bin/etcdctl --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt --endpoints=https://192.168.66.58:2379 snapshot save ${path}etcd-snapshot-`date +%Y%m%d-%H%M%S`.db
###删除7天之前的文件
/usr/bin/find /etc/etcd/snapshot -name "*.db" -mtime +7 | xargs rm -f
为了防止备份文件过多,占用磁盘空间,删除磁盘中7天之前的备份,一般最早的数据来说,意义不是很大
etcd集群使用snapshot恢复集群
1:使用snapshot恢复etcd集群,我们需要先停掉master节点上的docker和kubelet服务,停止etcd节点上的kubelet服务,确保没有服务调用etcd服务
[root@master01 ~]# systemctl stop kubelet
[root@master01 ~]# systemctl stop docker.socket && systemctl stop docker
[root@master01 ~]# docker ps

2:etcd的数据计划存储在/var/lib/etcd/目录下,所以删除etcd集群中每个节点/var/lib/etcd/目录下的数据,确保/var/lib/etcd/是空目录,或者/var/lib/etcd/是新创建的目录。如果存放其他目录下也可以,需要修改etcd配置文件,需要修改--data-dir参数。
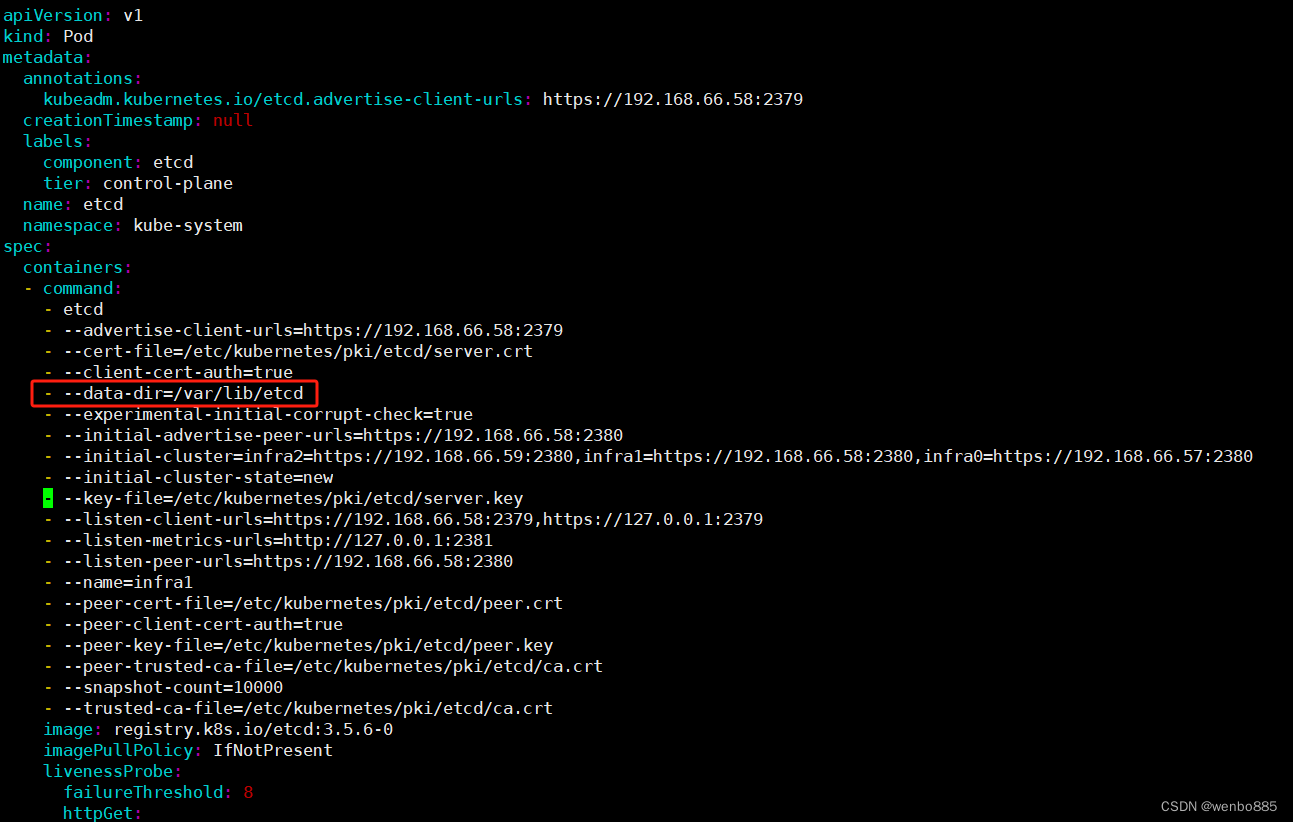
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/etcd.advertise-client-urls: https://192.168.66.58:2379
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.66.58:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --initial-advertise-peer-urls=https://192.168.66.58:2380
- --initial-cluster=infra2=https://192.168.66.59:2380,infra1=https://192.168.66.58:2380,infra0=https://192.168.66.57:2380
- --initial-cluster-state=new
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://192.168.66.58:2379,https://127.0.0.1:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.66.58:2380
- --name=infra1
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.k8s.io/etcd:3.5.6-0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /health
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: etcd
resources:
requests:
cpu: 100m
memory: 100Mi
startupProbe:
failureThreshold: 24
httpGet:
host: 128.0.0.1
path: /health
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priorityClassName: system-node-critical
securityContext:
seccompProfile:
type: RuntimeDefault
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-data
status: {}停止相关服务后,使用快照恢复数据,三个节点一次恢复,先恢复etcd01
etcd01恢复命令:
etcdctl snapshot restore etcd-snapshot-20231213-121501.db\
--data-dir=/var/lib/etcd/ --initial-cluster-token="etcd-cluster" \
--name=infra1 --initial-advertise-peer-urls=https://192.168.66.58:2380 \
--initial-cluster="infra0=https://192.168.66.57:2380,infra1=https://192.168.66.58:2380,infra2=https://192.168.66.59:2380"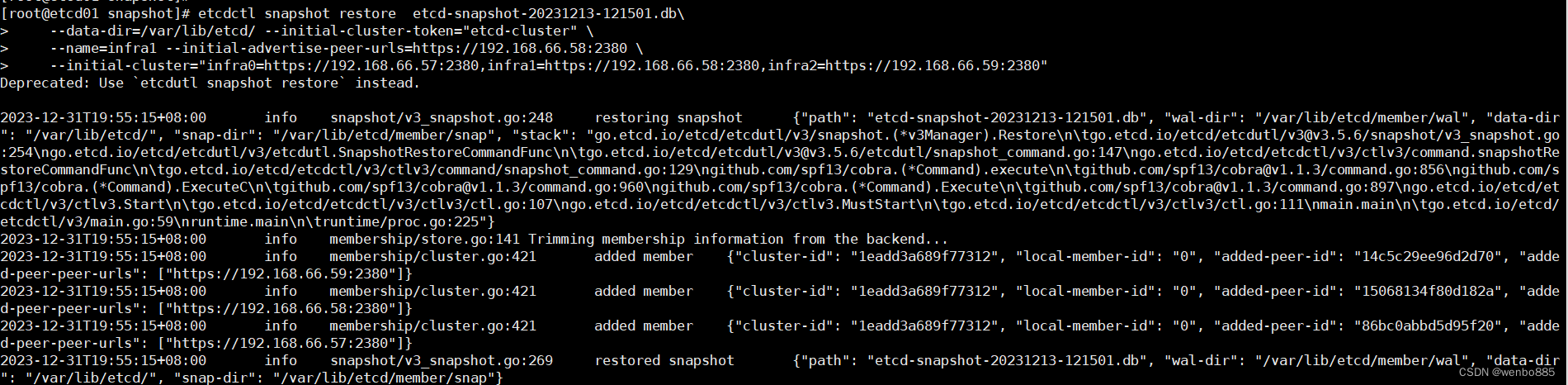
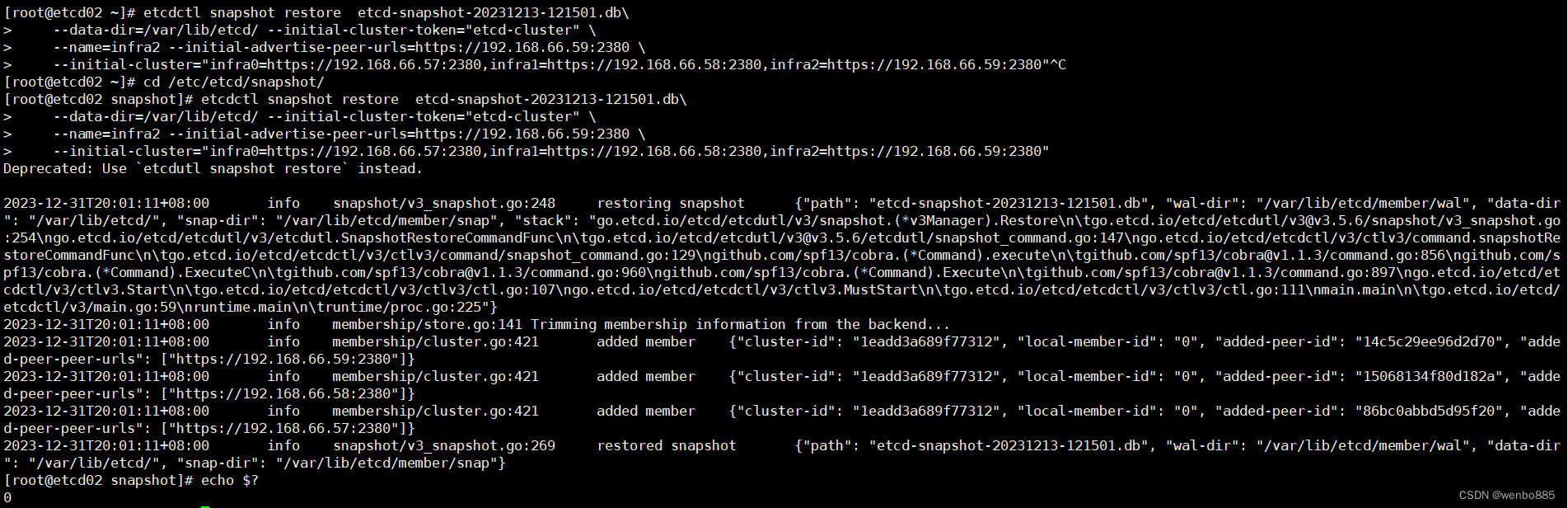
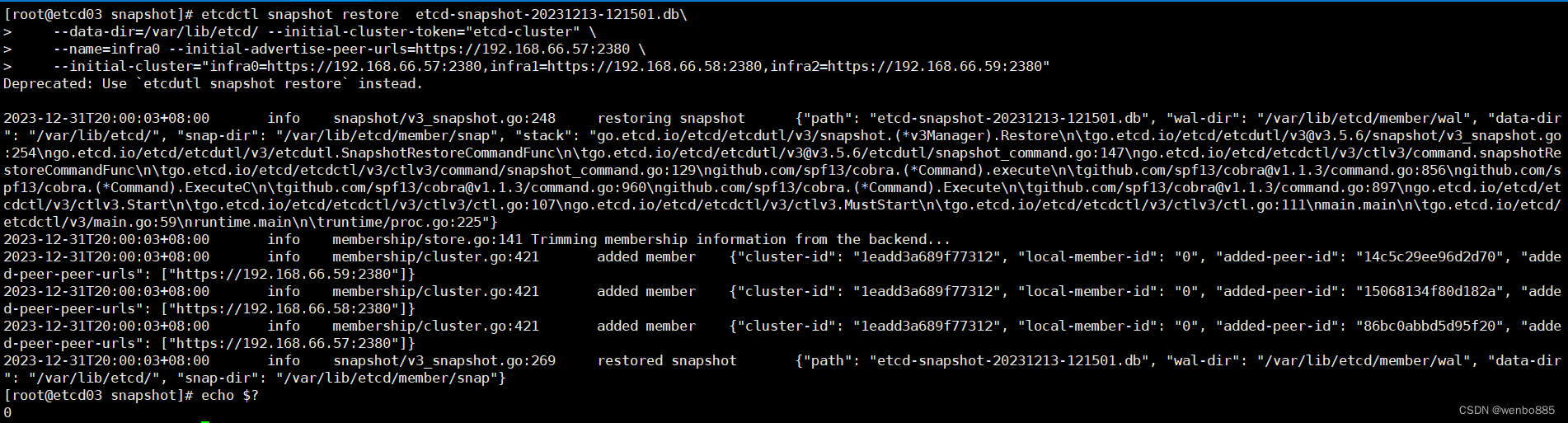
etcd02和etcd03节点恢复:
etcdctl snapshot restore etcd-snapshot-20231213-121501.db\
--data-dir=/var/lib/etcd/ --initial-cluster-token="etcd-cluster" \
--name=infra2 --initial-advertise-peer-urls=https://192.168.66.59:2380 \
--initial-cluster="infra0=https://192.168.66.57:2380,infra1=https://192.168.66.58:2380,infra2=https://192.168.66.59:2380"etcdctl snapshot restore etcd-snapshot-20231213-121501.db\
--data-dir=/var/lib/etcd/ --initial-cluster-token="etcd-cluster" \
--name=infra0 --initial-advertise-peer-urls=https://192.168.66.57:2380 \
--initial-cluster="infra0=https://192.168.66.57:2380,infra1=https://192.168.66.58:2380,infra2=https://192.168.66.59:2380"注意使用最新的快照文件,和快照文件路径。
3:数据恢复后,启动docker和kubelet服务 ,需要近最快时间启动。
[root@etcd01 snapshot]# systemctl start docker && systemctl start kubelet
[root@etcd02 snapshot]# systemctl start docker && systemctl start kubelet
[root@etcd03 snapshot]# systemctl start docker && systemctl start kubelet
4:查看服务状态,以及etcd服务是否启动,集群是否正常
[root@etcd01 snapshot]# systemctl status docker && systemctl status kubelet
[root@etcd02 snapshot]# systemctl status docker && systemctl status kubelet
[root@etcd03 snapshot]# systemctl status docker && systemctl status kubelet
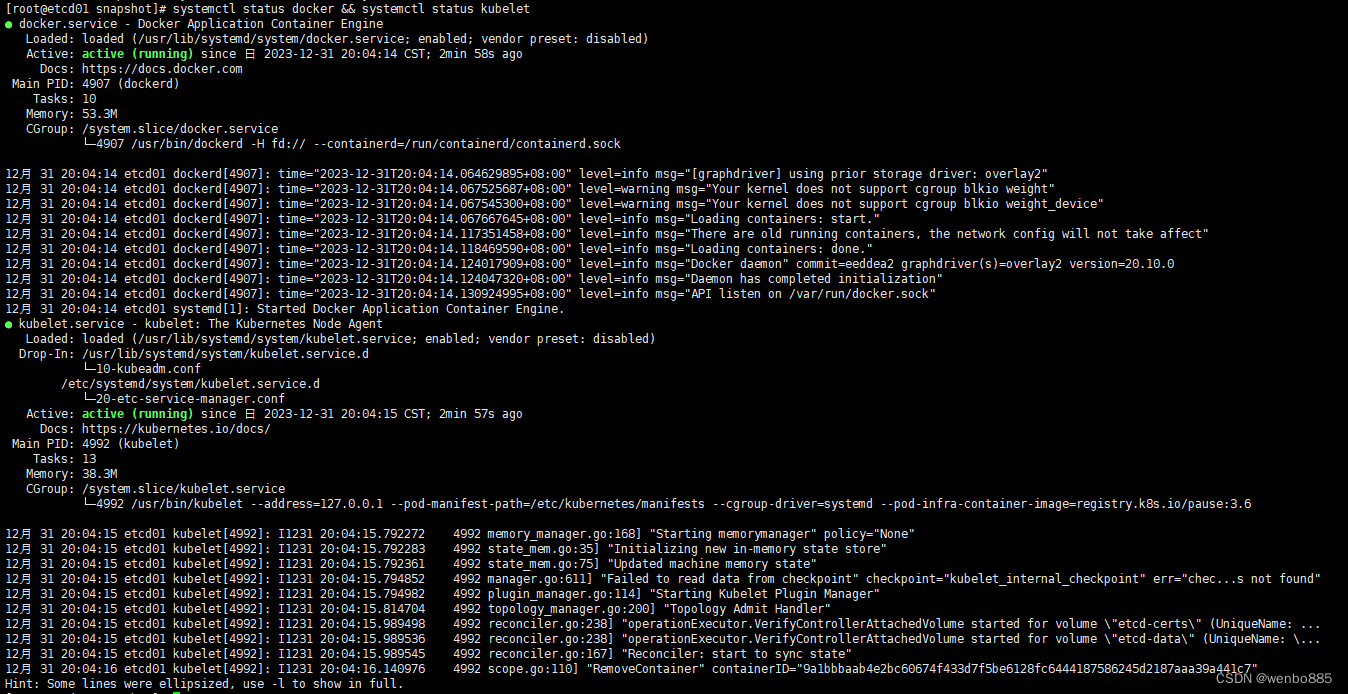
需要在三个节点上分别查看,docker ps,etcd容器是否起来
[root@etcd01 snapshot]# docker ps

[root@etcd02 snapshot]# docker ps
 [root@etcd03 snapshot]# docker ps
[root@etcd03 snapshot]# docker ps

使用member list查看集群节点状态,或使用脚本查看集群状态:
#!/bin/bash
#
###etcd cluster status check
####检查集群节点的健康状态
echo "etcd集群节点的健康状态检查"
/usr/bin/etcdctl --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt --endpoints=https://192.168.66.58:2379,https://192.168.66.59:2379,https://192.168.66.57:2379 endpoint health -w table
####检查集群的状态
echo "etcd=`hostname`:集群的节点详细状态包括leader or flower"
/usr/bin/etcdctl --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt --endpoints=https://192.168.66.58:2379,https://192.168.66.59:2379,https://192.168.66.57:2379 endpoint status --write-out=table
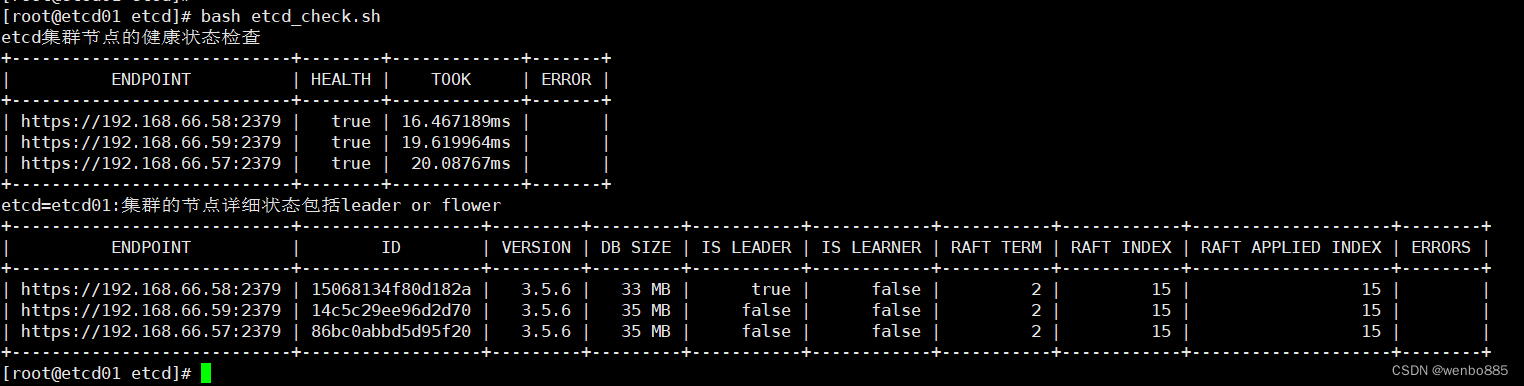
在第二章表格中的IS LEADER字段中,可以看到etcd01是true,etcd02和etcd03是false,所以集群没有出现脑裂,集群状态正常
恢复master节点服务,查看k8s集群状态
[root@master01 ~]# systemctl start docker && systemctl start kubelet
[root@master02 ~]# systemctl start docker && systemctl start kubelet
[root@master03 ~]# systemctl start docker && systemctl start kubelet
查看服务状态
[root@master01 ~]# systemctl status docker && systemctl status kubelet
[root@master02 ~]# systemctl status docker && systemctl status kubelet
[root@master03 ~]# systemctl status docker && systemctl status kubelet
查看k8s集群是否恢复
[root@master01 ~]# kubectl get nodes
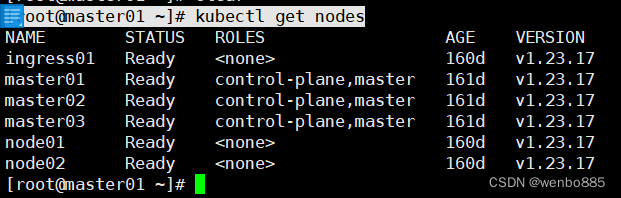
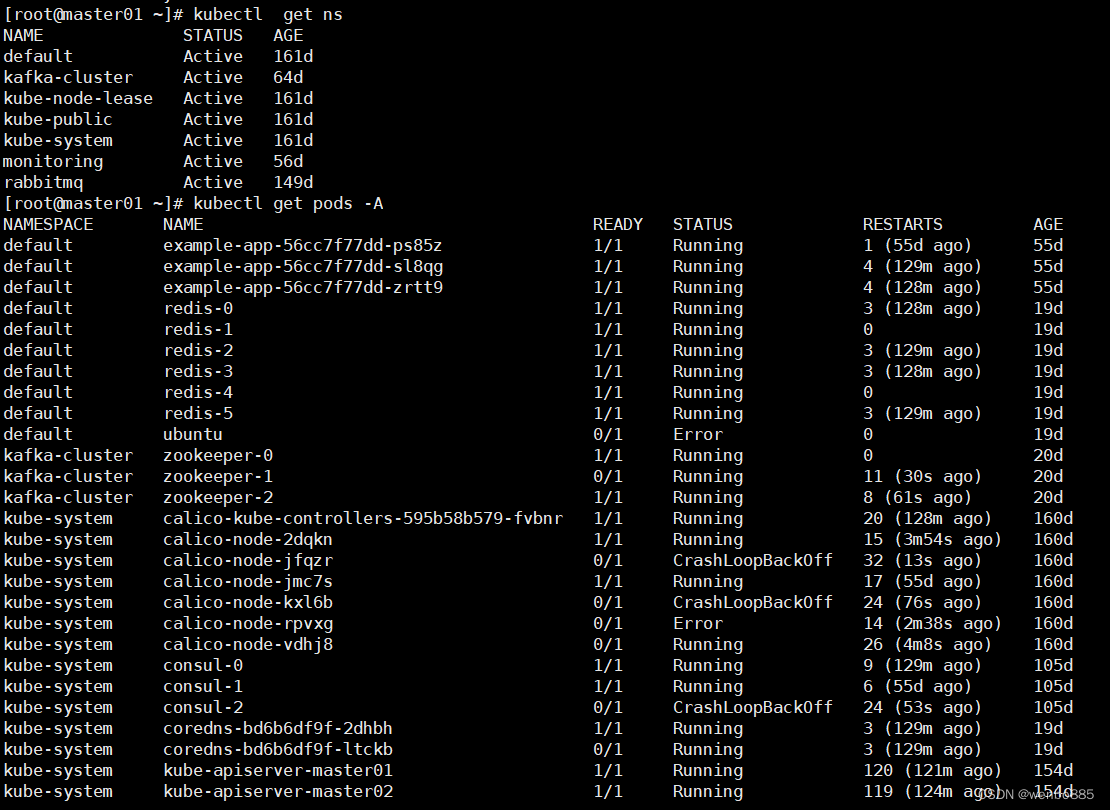
可以看到我们的k8s集群已经恢复,之前创建的pods也都存在,其中谢谢pods状态不正常,再继续排查。















 3366
3366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









