







 本文介绍了字节对齐在编程中的重要性,特别是在处理不同硬件平台的内存访问效率。它详细解释了字节对齐的必要性、对CPU存取效率的影响以及如何使用alignas关键字进行内存对齐。通过示例代码展示了不同类型结构体的对齐情况。
本文介绍了字节对齐在编程中的重要性,特别是在处理不同硬件平台的内存访问效率。它详细解释了字节对齐的必要性、对CPU存取效率的影响以及如何使用alignas关键字进行内存对齐。通过示例代码展示了不同类型结构体的对齐情况。
为什么要用字节对齐:
每个硬件平台对存储空间的处理不尽相同,比如一些CPU访问
特定的变量必须从特定的地址进行读取,所以在这种架构下,就必须进行字节对齐,
要不然读取的数据就可能并不是想要的数据。
字节对齐的缺点:
会对CPU的存取效率产生影响:比如有些平台CPU从内存中偶数地址开始读取数据,
如果数据其实地址刚好为偶数,则1个读取周期就可以读出一个读出一个int类型的值,
而如果数据的起始地址为奇数,那我们就需要2个读取周期读取数据,并对高地址和低
地址进行拼凑,这在读取效率上显然已经落后了很多。
对齐标准数据类型,它的地址只要是它的长度的整数倍就行,而非标准数据类型按下面
的原则对齐:
数组: 按照基本数据类型对齐,第一个对齐了,后面的自然就对齐了。
联合: 按其包含的长度最大的数据类型对齐。
结构体:结构体中每个数据类型都要对齐。
alignof用于获取内存对齐的大小
alignas用于设置内存对齐的大小
alignas使用方法: 一般在类型定义时,放在名称前,效果和__attribute__(aligned(n)) 效果一样,向上对齐
alignas的参数必须是2的幂次方。
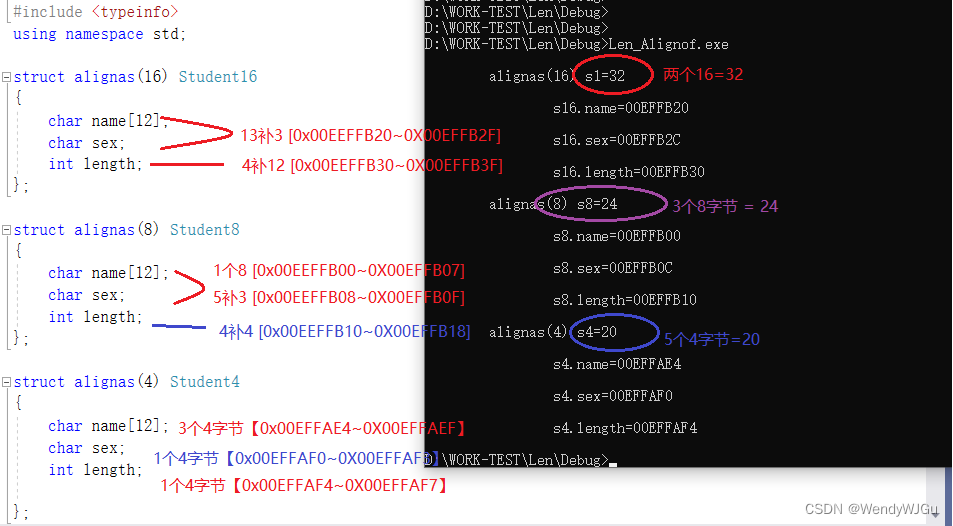
示例源码:
// Len_Alignof.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include <typeinfo>
using namespace std;
struct alignas(16) Student16
{
char name[12];
char sex;
int length;
};
struct alignas(8) Student8
{
char name[12];
char sex;
int length;
};
struct alignas(4) Student4
{
char name[12];
char sex;
int length;
};
int main()
{
Student16 s16 = { "张小菜" ,1, 165};
cout << "\n\talignas(16) s1=" << sizeof(s16) << endl;
cout << "\n\t\ts16.name=" << &s16.name << endl;
cout << "\n\t\ts16.sex=" << (void*)&s16.sex << endl;
cout << "\n\t\ts16.length=" << &s16.length << endl;
Student8 s8 = { "张小菜" ,1, 165};
cout << "\n\talignas(8) s8=" << sizeof(s8) << endl;
cout << "\n\t\ts8.name=" << &s8.name << endl;
cout << "\n\t\ts8.sex=" << (void*)&s8.sex<<endl;
cout << "\n\t\ts8.length=" << &s8.length << endl;
Student4 s4 = { "张小菜" ,1, 165};
cout << "\n\talignas(4) s4=" << sizeof(s4) << endl;
cout << "\n\t\ts4.name=" << &s4.name << endl;
cout << "\n\t\ts4.sex=" << (void*)&s4.sex << endl;
cout << "\n\t\ts4.length=" << &s4.length << endl;
}
执行结果:


















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











