







- 安装jdk
1.1下载jdk1.8版本,拷贝到/usr/local目录
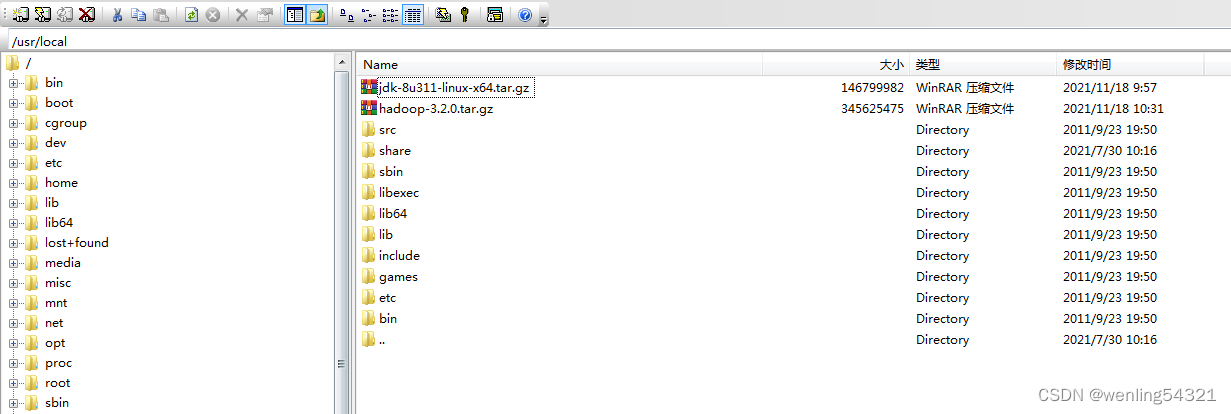
1.2解压安装包,tar -zvxf jdk-8u311-linux-x64.tar.gz
1.3 创建/usr/local/java目录,将解压后的jdk文件夹拷贝到java目下下
Cd /usr/local
Mkdir java
mv jdk1.8.0_311/ java/
1.4修改系统环境变量
Vi /etc/profile //打开文件,在profile末尾新增下面几行,之后运行source /etc/profile 立即生效
export JAVA_HOME=/usr/local/java/jdk1.8.0_311
export JRE_HOME=/usr/local/java/jdk1.8.0_311/jre
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/jre/lib/rt.jar:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
1.5测试java是否安装成功

- 实现ssh无密登陆
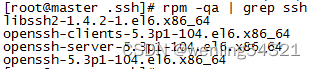
rpm -qa | grep ssh 验证是否安装ssh,下面表示已经安装
如果没有安装 ,执行下面命令
yum -y install openssh openssh-server openssh-clients
2.1在master机器上生成密码对
ssh-keygen -t rsa //后面回车
cd ~/.ssh
cat id_rsa.pub >>authorized_keys
chmod 600 authorized_keys
2.2设置ssh配置,修改文件etc/ssh/sshd_config
Vi etc/ssh/sshd_config
将下面注释的重新启用
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys // authorized_keys对应上面的文件名
配置完之后要重启ssh : service sshd restart
之后测试免密登录 ssh localhost
2.3复制文件到slaves机器
scp authorized_keys root@storeip62:/root/.ssh/
scp authorized_keys root@storeip63:/root/.ssh/
之后重复修改etc/ssh/sshd_config配置文件,以及重启shh操作,最后master免密登录到其它slaves节点配置完成
2.4接下来实现slaves机器无密访问master,重复下面步骤
ssh-keygen -t rsa //后面回车
cd ~/.ssh
cat id_rsa.pub >>authorized_keys 把Slave1的公钥追加到masert复制来的文件上
chmod 600 authorized_keys
scp authorized_keys root@storeip63:/root/.ssh/
scp authorized_keys root@master:/root/.ssh/
在每个节点都重复上述操作,这样就实现了集群的每台服务器之间的免密访问
- Zookeeper安装
tar -zvxf apache-zookeeper-3.6.3-bin.tar.gz
mv apache-zookeeper-3.6.3-bin/ zookeeper-3.6.3
cd zookeeper-3.6.3/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
dataDir=/usr/local/zookeeper-3.6.3/data
dataLogDir=/usr/local/zookeeper-3.6.3/logs
server.1=master:2888:3888
server.2=storeip62:2888:3888
server.3=storeip63:2888:3888
创建zookeeper-3.6.3下的data目录,在data目录下创建myid文件,向这个 myid 文件中写入 ID(ID 与前面 server.x 的 x 一致)
mkdir /usr/local/zookeeper/data
vi /usr/local/zookeeper/data/myid
vi /etc/profile
加入环境变量
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.6.3
export PATH=$PATH:$ZOOKEEPER_HOME/bin
scp -r /usr/local/zookeeper-3.6.3/ root@storeip62:/usr/local/
若启动失败,查看/usr/local/zookeeper-3.6.3/data下会新增一个version-2文件夹,修改文件夹下面所有文件的权限
cd version-2/
chmod 777 acceptedEpoch
chmod 777 currentEpoch
chmod 777 snapshot.0
./bin/zkServer.sh start
./bin/zkServer.sh stop
- hadoop3.2.0安装+zookeeper3.6.3
安装前先关闭防火墙 service iptables stop service iptables status
4.1服务器三台
| 192.168.7.61(master) | 192.168.7.62(storeip62) | 192.168.7.61(storeip63) | ||||
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain | ||||
| NameNode | NameNode | |||||
| DFSZKFailoverController | DFSZKFailoverController | |||||
| JournalNode | JournalNode | |||||
| DataNode | DataNode | |||||
| ResourceManager | ResourceManager | |||||
|
|
4.2解压安装包
tar –zvxf hadoop-3.2.0.tar.gz
安装目录如下
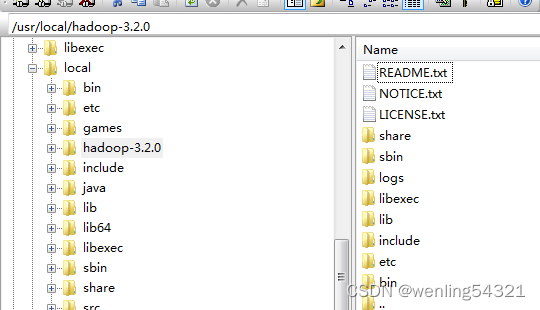
4.3修改环境变量
export HADOOP_HOME=/usr/local/hadoop-3.2.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
4.4修改core-site.xml,新增以下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/chudu/tmp</value>
</property>
<!-- zk 链接信息-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,storeip62:2181,storeip63:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>3000</value>
</property>
4.5修改hdfs-site.xml,新增以下内容:
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/chudu/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/chudu/hdfs/data</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>master,storeip62</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.master</name>
<value>master:9820</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.storeip62</name>
<value>storeip62:9820</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.master</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.storeip62</name>
<value>storeip62:9870</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;storeip62:8485/cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/chudu/hdfs/journal</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
4.6修改mapred-site.xml,新增以下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop-3.2.0/etc/hadoop,
/usr/local/hadoop-3.2.0/share/hadoop/common/*,
/usr/local/hadoop-3.2.0/share/hadoop/common/lib/*,
/usr/local/hadoop-3.2.0/share/hadoop/hdfs/*,
/usr/local/hadoop-3.2.0/share/hadoop/hdfs/lib/*,
/usr/local/hadoop-3.2.0/share/hadoop/mapreduce/*,
/usr/local/hadoop-3.2.0/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop-3.2.0/share/hadoop/yarn/*,
/usr/local/hadoop-3.2.0/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/home/chudu/hdfs/staging</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>15000</value>
</property>
4.7修改yarn-site.xml,新增以下内容:
<!--开启 resourcemanager HA, 默认不开起 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的 cluster id-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<!--所有参与集群的 RM-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>yn111,yn112</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.yn111</name>
<value>storeip62</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.yn112</name>
<value>storeip63</value>
</property>
<!-- 每台主机配置的 yarn id 都不一样,所以最后拷贝到其他机器时需要修改,storeip63上改为yn112-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>yn111</value>
</property>
<!-- 配置 zk 地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,storeip62:2181,storeip63:2181</value>
</property>
<!--开启自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--====================================== 故障处理 =====================-->
<!--rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<!--================================== 分别配置 这 3 台 RM 地址 =================-->
<!-- scheduler -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!--schelduler失联等待连接时间-->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<property>
<name>yarn.resourcemanager.address.yn111</name>
<value>storeip62:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.yn111</name>
<value>storeip62:8088</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.yn111</name>
<value>storeip62:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.yn111</name>
<value>storeip62:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.yn111</name>
<value>storeip62:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.yn111</name>
<value>storeip62:23142</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.yn112</name>
<value>storeip63:8088</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.yn112</name>
<value>storeip63:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.yn112</name>
<value>storeip63:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.yn112</name>
<value>storeip63:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.yn112</name>
<value>storeip63:23142</value>
</property>
<!--================================================ NodeManager 配置 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/chudu/hdfs/nodemanager/local</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/home/chudu/hdfs/nodemanager/remote-app-logs</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/chudu/hdfs/nodemanager/logs</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 日志配置 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>864000</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>86400</value>
</property>
4.8修改hadoop-env.sh,新增以下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_311
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HADOOP_SHELL_EXECNAME=root
4.9修改mapred-env.sh,新增以下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_311
4.10修改yarn-env.sh,新增以下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_311
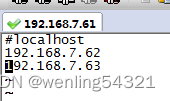
4.11修改workers,新增datanode服务器IP
4.12启动zookeeper
Cd /usr/local/zookeeper3.6.3
./bin/zkServer.sh start
4.13格式化zk
hdfs zkfc -formatZk
4.14格式化namenode
sbin/hadoop-daemon.sh start journalnode 格式化前要启动journalnode
hadoop namenode –format
4.15格式化后将hadoop3.2.0拷贝到其他服务器上,并修改环境变量
scp -r /usr/local/hadoop3.2.0/ root@storeip62:/usr/local/
scp -r /usr/local/hadoop3.2.0/ root@storeip63:/usr/local/
4.16启动hadoop
Cd /usr/local/hadoop3.2.0
./sbin/start-all.sh //能启动所有相关联的程序
./sbin/stop-all.sh
sbin/hadoop-daemon.sh start journalnode 单独启动journalnode
yarn-daemon.sh start resourcemanager单独启动resourcemanager
https://blog.csdn.net/weixin_45025143/article/details/121757627
Transformations算子
Actions算子
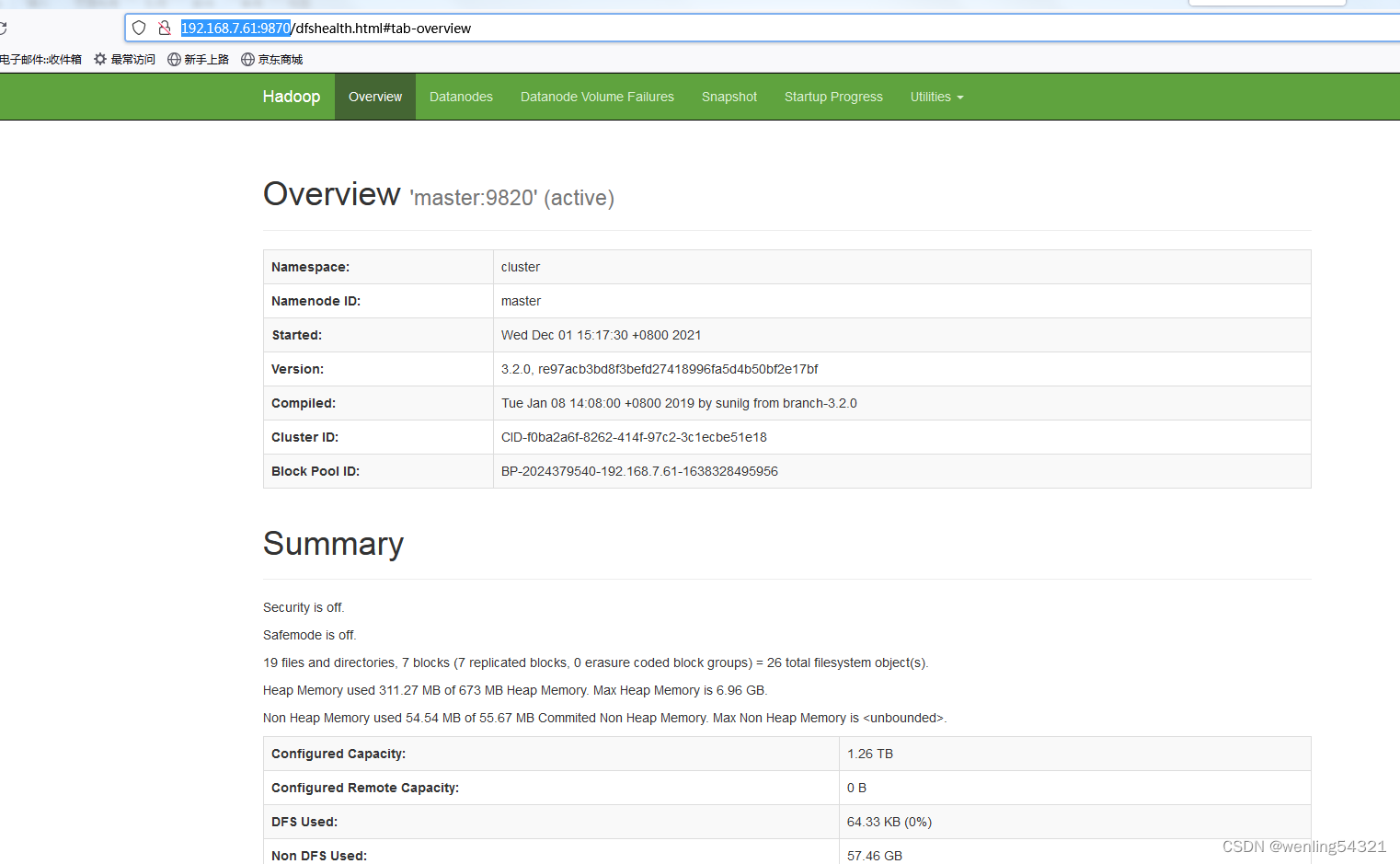
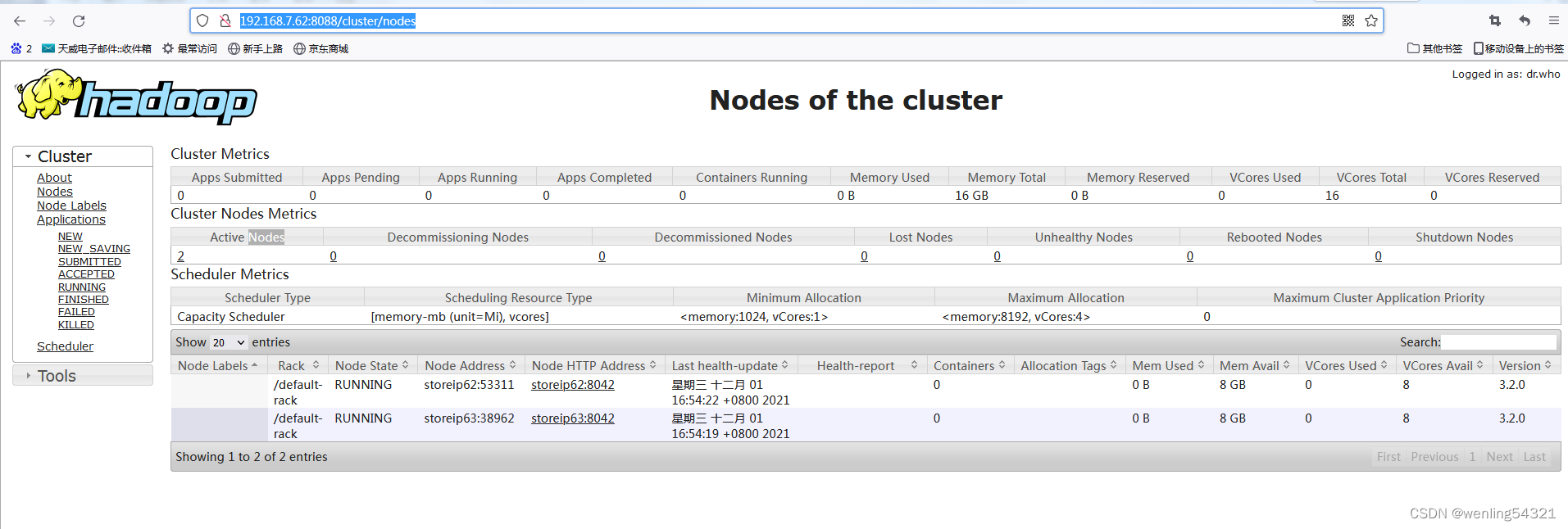
scp -r /usr/local/hadoop-3.2.0/etc/hadoop/hdfs-site.xml root@storeip62:/usr/local/hadoop-3.2.0/etc/hadoop/
ntpdate pool.ntp.org
lsof -i 查看是否有端口9820
cd /usr/local/
./zookeeper-3.6.3/bin/zkServer.sh start
scp -r /usr/local/spark/conf/spark-env.sh root@storeip63:/usr/local/spark/conf/
scp -r /usr/local/spark/conf/spark-env.sh root@storeip63:/usr/local/spark/conf/
hadoop jar /usr/local/hadoop-3.2.0/share/hadoop/mapreduce/demo.jar Vodplay.Poms 20211105 20211111 大连 按周
cat /etc/centos-release
五、spark安装
5.1解压spark-3.2.0-bin-without-hadoop.tgz
Tar –zvxf spark-3.2.0-bin-without-hadoop.tgz
Mv spark-3.2.0-bin-without-hadoop spark
Cd /usr/local/spark/conf
mv spark-env.sh.template spark-env.sh
mv workers.template workers
在 workers中加入spark节点服务器
storeip62
storeip63

在spark-evn.sh加入下面几行:
export JAVA_HOME=/usr/local/java/jdk1.8.0_311
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-3.2.0/bin/hadoop classpath)
加入环境变量,在/etc/profile中加入下面三行
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
启动spark
./sbin/start-all.sh
主节点多了Master进程
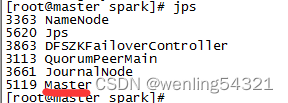
节点出现worker进程
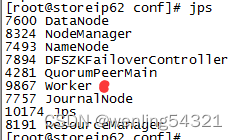
测试
bin/run-example SparkPi 2>&1 | grep "Pi is"
![]()
打开vi /etc/rc.local 设置开机自动启动项
Export JAVA_HOME=/usr/local/java/jdk1.8.0_311
/usr/local/zookeeper-3.6.3/bin/zkServer.sh start
/usr/local/hadoop-3.2.0/sbin/start-all.sh
/usr/local/spark/sbin/start-all.sh
Linux idea安装
系统必须是桌面模式,不能是服务器模式
修改/etc/ inittab文件,将id:3:initdefault:改为id:5:initdefault://将文字界面改为图形界面
下载版本![]() ,2021最新版无法安装,与现有操作系统版本不兼容
,2021最新版无法安装,与现有操作系统版本不兼容
tar -zvxf ideaIC-2018.3.6.tar.gz
cd idea-IC-183.6156.11
./idea.sh //安装,输入后会弹出框

![]()
./bin/spark-submit --class SecondScala --master spark://master:7077 /root/IdeaProjects/SecondSpark/out/artifacts/SecondSpark_jar/SecondSpark.jar
./bin/spark-submit --class SecondScala --master yarn /root/IdeaProjects/SecondSpark/out/artifacts/SecondSpark_jar/SecondSpark.jar
/usr/local/zookeeper-3.6.3/bin/zkServer.sh start
/usr/local/hadoop-3.2.0/sbin/start-all.sh
/usr/local/spark/sbin/start-all.sh
Hadoop fsck / -delete //执行健康检查,删除损坏掉的block。

















 1139
1139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











