







一、背景
鉴于sqlserver的row_number函数的便捷性,寻思sql如何实现,遍向大佬学习了一番,自我感觉还不错,于是来加强巩固一下。
二、步骤
1. 原始数据表
select
st.Sname Sname
,st.Ssex Ssex
,sc.Degree Degree
,te.Tname Tname
,te.Prof Prof
,te.Depart Depart
,cs.Cname Cname
from Student as st
-- 关联成绩表
LEFT JOIN Score as sc
on st.Sno = sc.Sno
-- 关联科目
left join Course as cs
on cs.Cno = sc.Cno
-- 关联教师表
left join Teacher as te
on te.Tno = cs.Tno
order by st.Sname, sc.Degree desc查询结果如下:
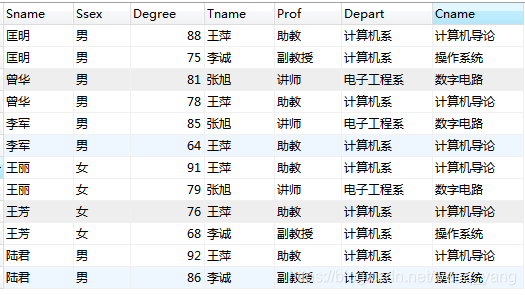
2. 需求:想实现获取每个学生成绩最好的科目信息
3. 思路:
增加临时变量去记录需要分组的值,同时增加一个等级变量,去记录分组排名的结果,后面可以根据结果去查询响应等级的值。 @group_clum : 此处用这个变量记录分组的值 @rank: 此处用这个变量记录分组后的等级
三、经典SQL实现:
- 查询所有学生的成绩 按照 学生姓名 性别 课程名称 成绩 展示该学生成绩最高的科目信息
select * from
(select
*
,@rank := case when @group_clum != T1.Sname then 1 else @rank +1 end as rank
,@group_clum:=T1.Sname as group_clum_tmp
from (
select
st.Sname Sname
,st.Ssex Ssex
,sc.Degree Degree
,te.Tname Tname
,te.Prof Prof
,te.Depart Depart
,cs.Cname Cname
from Student as st
LEFT JOIN Score as sc
on st.Sno = sc.Sno
left join Course as cs
on cs.Cno = sc.Cno
left join Teacher as te
on te.Tno = cs.Tno
order by st.Sname, sc.Degree desc
) as T1) as T2
where T2.rank =1
order by T2.Degree desc查询结果如下,大功告成!
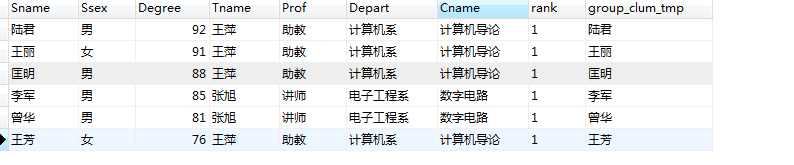
四、优化思考
使用pandas直接读取数据库,使用dataframe的merge查询获取数据信息。
import pandas as pd
from pymysql import Connect
MYSQL_DB = {
"host": "192.168.xx.xx",
"user": "xxx",
"password": "xxx",
"database": "ZuoYe",
"charset": "utf-8"
}
conn = Connect(host=MYSQL_DB["host"], port=3306, user=MYSQL_DB["user"], password=MYSQL_DB["password"], database=MYSQL_DB["database"])
sql_student = "select * from Student;"
sql_score = "select * from Score;"
sql_teacher = "select * from Teacher;"
sql_course = "select * from Course;"
df_student = pd.read_sql_query(sql_student, conn)
df_score = pd.read_sql_query(sql_score, conn)
df_teacher = pd.read_sql_query(sql_teacher, conn)
df_course = pd.read_sql_query(sql_course, conn)
df1 = pd.merge(df_student, df_score, left_on=["Sno"], right_on=["Sno"], how="left")
df2 = pd.merge(df1, df_course, left_on=["Cno"], right_on=["Cno"], how="left")
df3 = pd.merge(df2, df_teacher, left_on=["Tno"], right_on=["Tno"], how="left")
df4 = df3[["Sname", "Ssex", "Degree", "Tname", "Prof", "Depart", "Cname"]]
df5 = df4.copy()
df5.sort_values(axis=0, by=["Sname", "Degree"], ascending=[True, False], inplace=True)
df6 = df5.drop_duplicates(["Sname"])
print(df6.sort_values(["Degree"], ascending=False))同样输出了结果:
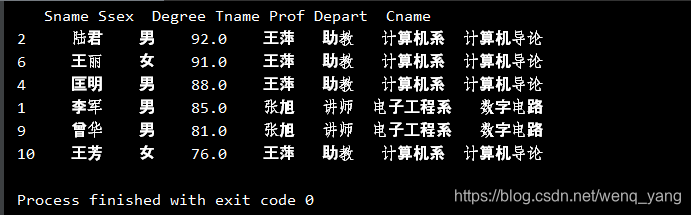














 1418
1418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









