







为了简化感知器公式的表示法,我们将把偏差aaWp=b与其他权重合并到一个向量中[wo,1,。…,wd]“,其中T表示向量的转置,所以w是acolumn向量,我们也将x作为列向量,并将其修改为x=[o,1,…,ad]T,其中所添加的坐标ao固定在co=1。

With this convention,w Tx = >d_o WwiOi, and so Equation (1.1) can be rewrit-ten in vector form as 有了这个约定,w tx=>d_o wwioi,所以方程(1.1)可以作为向量形式的rewt-10,如

我们现在介绍感知器学习算法(PLA),该算法将根据数据确定w是什么。让我们假设数据集是线性可分的,这意味着有一个向量w使(1.2)在所有的训练考试中达到正确的判决h(Xn)=yn,如图1.3所示。
我们的学习算法将使用一个简单的迭代方法找到这个w,下面是它的工作原理。在迭代t中,t=0,1,2,.,有权向量的当前值,称为w(T)。该算法从(x1,y1)…中选择一个示例(n,YN)目前被错误分类,称之为(x(T),g9(T)),并使用它更新w(T)。由于该示例被错误分类,我们使用了gy(T)≠符号(WT(T)x(T))。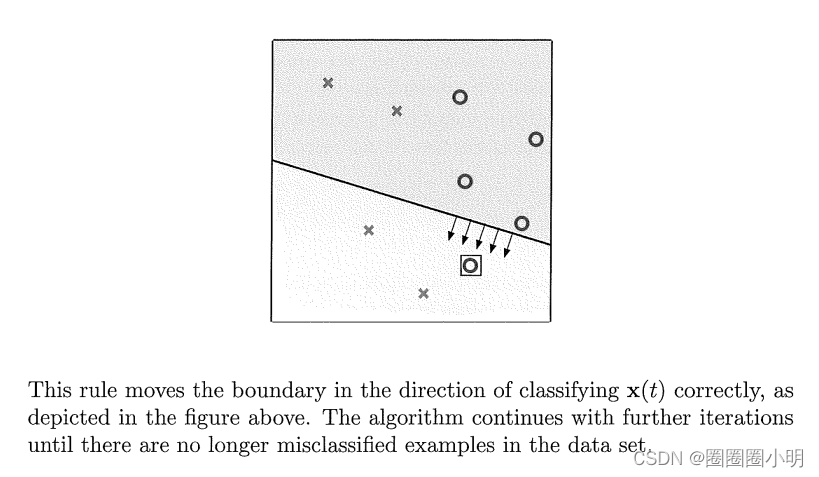 这个规则正确地将边界移向分类x(T)的方向,如上图所示。该算法继续进行进一步的迭代,直到数据集中不再有错误分类的示例。
这个规则正确地将边界移向分类x(T)的方向,如上图所示。该算法继续进行进一步的迭代,直到数据集中不再有错误分类的示例。















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









