







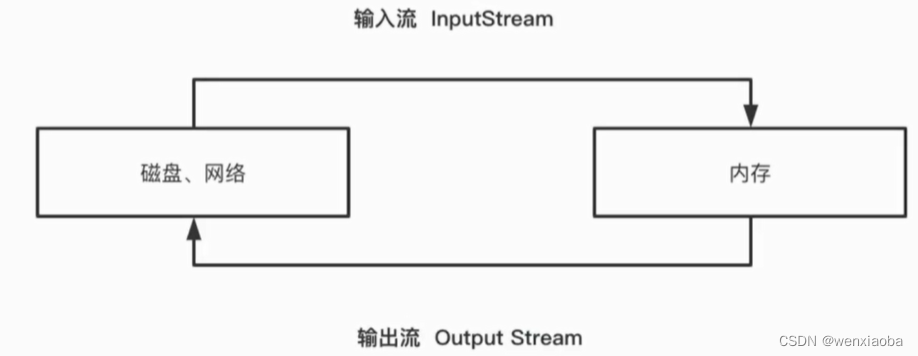
输入流: 把数据(键盘输入、鼠标、扫描仪等外设设备)读入到内存中,即读数据;
输出流: 把内存(程序)中的数据输出到外设或其他地方,即写数据。
以内存为参考点,进内存就是输入流,出内存就是输出流
文件处理步骤:
1、打开文件
2、操作文件(读/写内容)
3、关闭文件
打开和关闭文件
python提供了open函数用来打开文件,该函数返回文件对象
open方法:open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
常用的参数
- file:必传参数,文件路径(相对路径时会按照当前.py文件目录进行拼接,绝对路径时就打开绝对路径对应的文件)
- mode:可选,文件打开模式,默认只读
- encoding:一般使用utf8,使用时最好还是设置下,不同平台、系统可能默认编码不一样,导致程序在不同平台、系统执行结果不一样
- errors,在读写过程中,会遇到某些字符无法用指定的编码进行编码,可以指定errors为"ignore"去忽略编码报错的内容,默认为None,与"strict"的作用一样,即严格按照指定编码
注意:如果mode中包含b(即二进制),则只需要file和mode参数即可,其他的参数加上去会报错(二进制数据是没有编码解码等方法的)
基础示例如下:
data.txt文件内容如下:
hello,world!
打开文件练习
休息还是找工作,这是个问题
打开并读取data.txt文件内容:
# 打开文件
f = open("data.txt", "r", encoding="utf-8")
# 文件操作
print(f.read()) # 读取文件内容
# 关闭文件
f.close()
执行结果为:
hello,world!
打开文件练习
休息还是找工作,这是个问题
读文件
| 方法 | 描述 |
|---|---|
| read() | 一次读取文件所有内容,返回一个字符串 |
| read(size) | 每次最多读取指定长度(字符长度)的内容,返回一个字符串 |
| readlines() | 一次读取文件所有内容,按行返回一个列表 |
| readline() | 每次只读取一行内容 |
| data.txt文件内容如下: |
人生苦短,我用python
打开文件练习
休息还是找工作,这是个问题
read()使用
# 打开文件
f = open("data.txt", "r", encoding="utf-8")
# 文件操作
print(f.read())
# 关闭文件
f.close()
执行结果为:
人生苦短,我用python
打开文件练习
休息还是找工作,这是个问题
read(size)使用
# 打开文件
f = open("data.txt", "r", encoding="utf-8")
# 文件操作
print(f.read(16))
# 关闭文件
f.close()
执行结果如下:
人生苦短,我用python
打开
从结果看出,只有15个字,剩下的一个其实是第一行的换行符
readlines()
# 打开文件
f = open("data.txt", "r", encoding="utf-8")
# 文件操作
result = f.readlines()
print(type(result))
print(result)
# 关闭文件
f.close()
执行结果:
<class 'list'>
['人生苦短,我用python\n', '打开文件练习\n', '休息还是找工作,这是个问题']
readline()
# 打开文件
f = open("data.txt", "r", encoding="utf-8")
# 文件操作
line1 = f.readline()
line2 = f.readline()
line3 = f.readline()
print(type(line1), "line1 = ", line1)
print("line2 = ", line2)
print("line3 = ", line3)
# 关闭文件
f.close()
执行结果:
<class 'str'> line1 = 人生苦短,我用python
line2 = 打开文件练习
line3 = 休息还是找工作,这是个问题
with open方法:with open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True) as f: f.xxxx
使用open方法的话,需要自己
写文件
write()和writelines()
写入文件的方法有2个:write()和writelines()
| 方法 | 描述 |
|---|---|
| write(str) | 将字符串str写入到文件中 |
| writelines(list[str]) | 将列表(元素均为字符串)写入到文件中 |
# 打开文件
f = open("data.txt", "w", encoding="utf-8")
# 文件操作
f.write("人身安全,值得慎重\n这个是第二行\n现在是第三行了\n")
content = ["\n首行需要写什么?\n", "第二行跟python无关\n", "第三行是最后一行"]
f.writelines(content)
# 关闭文件
f.close()
执行成功后,data.txt文件内容如下:
人身安全,值得慎重
这个是第二行
现在是第三行了
首行需要写什么?
第二行跟python无关
第三行是最后一行
写文件模式
| 模式 | 描述 |
|---|---|
| r | 以只读模式打开文件,并将文件指针指向文件头,如果文件不存在会报错 |
| w | 以只写模式打开文件,并将文件指针指向文件头;如果文件存在则将其内容清空,如果文件不存在则创建 |
| a | 以只追加可写模式打开文件,并将文件指针指向文件尾部;如果文件不存在则创建 |
| r+ | 读写的模式打开文件,写文件时,从光标所在位置一个字一个字的覆盖写,即文件原有的内容会被覆盖,覆盖长度为写入的内容长度 |
| w+ | 读写的模式打开文件(文件不存在时会新建文件),且会先清空文件内容再写入 |
| a+ | 读写的模式打开文件(文件不存在时会新建文件),写文件时,在文件末尾追加需要写入的内容 |
| b | 读写二进制文件,需要与上面的几种模式搭配使用,如ab,wb,ab+ |
打开文件模式为r
若打开文件模式为r时,写入内容会报错
f = open("data.txt", "r", encoding="utf-8")
f.write("人身安全,值得慎重\n这个是第二行\n现在是第三行了\n")
f.close()
执行结果:
Traceback (most recent call last):
File "E:\hogwart\work\wen.py", line 4, in <module>
f.write("人身安全,值得慎重\n这个是第二行\n现在是第三行了\n")
io.UnsupportedOperation: not writable
打开文件模式为w
w模式会将文件中原有的内容给清空
执行前data.txt文件内容如下
人身安全,值得慎重
这个是第二行
执行代码如下:
f = open("data.txt", "w", encoding="utf-8")
f.write("今天周六了\n深圳没有封控\n区域风控")
f.close()
执行成功后,data.txt内容如下:
今天周六了
深圳没有封控
区域风控
打开文件模式为a
写入内容时,在文件末尾开始写
执行前,data.txt文件内容为:
今天周六了
深圳没有封控
执行代码为:
f = open("data.txt", "a", encoding="utf-8")
f.write("追加的第一行\n我不是药神\n天天做核酸")
f.close()
执行后,data.txt文件内容为:
今天周六了
深圳没有封控追加的第一行
我不是药神
天天做核酸
打开文件模式为r+
执行前,data.txt文件内容为:
人生苦短,我用python
hello
今天吃云吞
执行代码为:
# r+ 模式打开文件,此时文件指针指向文件头,即光标所在位置为0
f = open("data.txt", "r+", encoding="utf-8")
# 写文件,从文件头开始一个个覆盖(原文件内容被写入内容覆盖),直至写入的内容写入完成
f.write("python是世界上最好的语言") # 不知道为什么,3个字符才替换成1个中文。。后面知道了再补充
f.close()
执行后,data.txt文件内容为:
python是世界上最好的语言
今天吃云吞
我在执行的时候遇到了一个我无法理解的现象,就是如果我在文件对象生效的时候使用的read(),write()都会将内容从文件尾开始写,这里记录下这个问题,后面我在看看有没有了解这个的。
打开文件模式为w+
读写的模式打开文件(文件不存在时会新建文件),且会先清空文件内容再写入
f = open("data.txt", "w+", encoding="utf-8")
# 写文件
print(f.read())
f.write("python是世界上最好的语言\n山河令的阿湘和曹蔚宁好意难平\n你看,这不就喜丧")
print("-----------------------")
f.seek(0) # 将光标位置移动到文件首位
print(f.read())
f.close()
执行结果为:
-----------------------
python是世界上最好的语言
山河令的阿湘和曹蔚宁好意难平
你看,这不就喜丧
打开文件模式为a+
追加可读写,写入内容时,默认从文件末尾的位置开始追加要写入的内容
执行前,data.txt文件内容
人生苦短,我用Python
赚钱不易,积极赚钱
python测试开发,进发!
执行文件:
f = open("data.txt", "a+", encoding="utf-8")
# 写文件
f.write("python是世界上最好的语言\n山河令的阿湘和曹蔚宁好意难平\n你看,这不就喜丧")
f.close()
执行后,data.txt文件内容为:
人生苦短,我用Python
赚钱不易,积极赚钱
python测试开发,进发!python是世界上最好的语言
山河令的阿湘和曹蔚宁好意难平
你看,这不就喜丧
打开文件模式为b
b表示是二进制的形式,搭配rb就是二进制读文件,wb为二进制写文件,即读出或写入的内容,是二进制形式的内容
data.txt文件内容如下:
人生苦短,我用Python
赚钱不易,积极赚钱
python测试开发,进发!
执行代码如下:
f = open("data.txt", "rb")
content = f.read()
print(type(content))
print(content)
print(content.decode("utf-8"))
f.close()
执行结果为:
<class 'bytes'>
b'\xe4\xba\xba\xe7\x94\x9f\xe8\x8b\xa6\xe7\x9f\xad\xef\xbc\x8c\xe6\x88\x91\xe7\x94\xa8Python\r\n\xe8\xb5\x9a\xe9\x92\xb1\xe4\xb8\x8d\xe6\x98\x93\xef\xbc\x8c\xe7\xa7\xaf\xe6\x9e\x81\xe8\xb5\x9a\xe9\x92\xb1\r\npython\xe6\xb5\x8b\xe8\xaf\x95\xe5\xbc\x80\xe5\x8f\x91\xef\xbc\x8c\xe8\xbf\x9b\xe5\x8f\x91\xef\xbc\x81'
人生苦短,我用Python
赚钱不易,积极赚钱
python测试开发,进发!
写入的话,写入的内容要转换成二进制才能写入成功,否则会报错
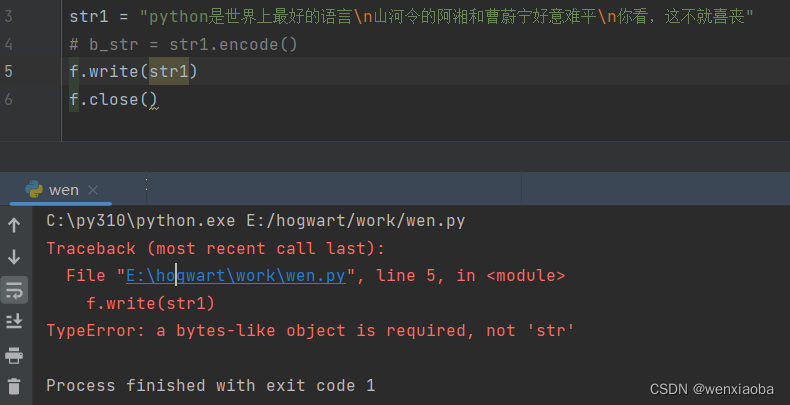
正确写入方式:
执行代码:
f = open("data.txt", "wb")
# 写文件
str1 = "python是世界上最好的语言\n山河令的阿湘和曹蔚宁好意难平\n你看,这不就喜丧"
# 使用encode()转成二进制数据后,再写入文件
b_str = str1.encode()
f.write(b_str)
f.close()
执行后,data.txt文件内容为:
python是世界上最好的语言
山河令的阿湘和曹蔚宁好意难平
你看,这不就喜丧
with open()
打开文件后,我们必须执行关闭文件的操作,忘记关闭文件,危害较大
1、应用系统本身对文件的打开数量有做限制,如果一个文件被打开多个,达到限制的数量后,后续的打开都会失败,影响程序运行,危害严重
2、文件对象未关闭的话,也会占用内存空间,非常浪费资源,影响服务器性能
3、内存空间不足够时,会导致系统频繁自动回收资源,打开文件并修改的数据未被保存就被系统自动回收,极易造成数据的丢失
使用传统的open()和close()时,一定要跟try/except/finally进行一场处理,以防打开文件或操作文件过程中因为异常导致文件一直打开而占用资源,影响程序运行(finally语句去执行关闭文件的操作)
Python也提供了with的方法来控制文件的打开关闭
格式:
with open("data.txt", "w+", encoding="utf-8") as fxx:
fxx.write("xxx")
fxx.read()
示例如下:
with open("data.txt", "w+", encoding="utf-8") as f:
f.write("人生苦短,我用python\npython是一门脚本语言\n任何一门语言都不容易学会")
f.seek(0)
print(f.read())
# 可以通过属性closed判断文件是否关闭,True表示文件关闭了,False表示文件打开状态中
print(f.closed)
执行结果为:
控制台
人生苦短,我用python
python是一门脚本语言
任何一门语言都不容易学会
True
data.txt
人生苦短,我用python
python是一门脚本语言
任何一门语言都不容易学会
seek()和tell()
seek(offset: int, whence: int = 0):移动文件读取指针到指定位置
offset为偏移量,即需要移动偏移的字节数;
whence表示是从哪个位置开始偏移,0:文件头,1:当前位置,2:文件末尾
返回:成功时返回新的文件位置,失败时返回-1
示例:
data.txt文件内容如下:
hello,world!
打开文件练习
休息还是找工作
执行代码:
with open("data.txt", "r", encoding="utf-8", errors="ignore") as f1:
# 中文占了多个字节,在光标移动到指定位置后,读取可能会失败,所以open参数加上了errors="ignore"表示忽略报错
f1.seek(15)
print(f1.read())
print("-------------------------")
with open("data.txt", "rb+") as f2:
# 读取文件前12个字符
print(f2.read(12))
# 将光标向前移动6位
f2.seek(-6, 1)
f2.write("\nhello,早上好".encode())
print("-------------------------")
with open("data.txt", "r+", encoding="utf-8", errors="ignore") as f3:
# 读取文件前12个字符
print(f3.read(12))
# 将光标移动到
f3.seek(-6, 1)
f3.write("\nhello, 早上好")
执行后,控制台内容如下:
开文件练习
休息还是找工作
-------------------------
b'hello,world!'
-------------------------
hello,
hello
Traceback (most recent call last):
File "E:\hogwart\work\wen.py", line 19, in <module>
f3.seek(-6, 1)
io.UnsupportedOperation: can't do nonzero cur-relative seeks
data.txt文件内容如下:
hello,
hello,早上好件练习
休息还是找工作
从最后的结果报错可以看出,当open使用r+方式打开时,seek()会报错,这就奇怪了,前2个with open都正常执行了,为什么到了第3个with open就报错了呢?原来是在python3中,非二进制打开文件时,只有在文件开头进行偏移是被允许的,在当前所在位置和文件末尾进行偏移就会报错。所以想要seek不报错,就需要使用二进制模式b打开文件。具体说明可以参考这位博主的文章:file.seek()方法引出的文本文件和二进制文件问题
tell():返回文件的当前位置(即光标所在位置)
data.txt内容如下:
hello,
hello,早上好件练习
休息还是找工作
with open("data.txt", "r+") as f:
print(f.read(5))
print(f.tell())
执行结果为:
hello
5















 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









