







【问题描述】
有些网站的反爬机制是很强的,不仅网络请求中的参数经过 JS 加密,甚至还针对一些常用的爬虫工具,如 Selenium 作了屏蔽。
比如前段时间我爬取的卫健委官网,反爬机制就相当变态(传送门:Python网络爬虫实战:卫健委官网数据的爬取)。
本文教你如何设置 Pyppeteer 来完美地避开这些反爬机制的检测。
【解决方法】
方法一:在导入 launch 之前 把 --enable-automation 禁用 防止监测webdriver
from pyppeteer import launcher
# 在导入 launch 之前 把 --enable-automation 禁用 防止监测webdriver
launcher.AUTOMATION_ARGS.remove("--enable-automation")这种方法在网上很多博客中都有写,不过我在使用这种方法的时候, 运行报错。
module 'pyppeteer.launcher' has no attribute 'AUTOMATION_ARGS'不知道大家运行是不是也是这样,如果有成功的,可以在评论区分享一下这种方法使用的正确姿势。
2021.02.25 更新
经过读者 @一只面包虫 的提醒,发现这个错误是由于源代码中 "AUTOMATION_ARGS" 改成了 "DEFAULT_ARGS" 而出现的。
修改的话,将
launcher.AUTOMATION_ARGS.remove("--enable-automation")
改为
launcher.DEFAULT_ARGS.remove("--enable-automation")
即可正常使用
方法二:直接在 launcher 脚本中注释掉 --enable-automation 参数
launcher.py 脚本位置
(你自己的Python安装路径)\Python37_64\Lib\site-packages\pyppeteer\launcher.py然后打开脚本,注释掉 --enable-automation ,保存即可。
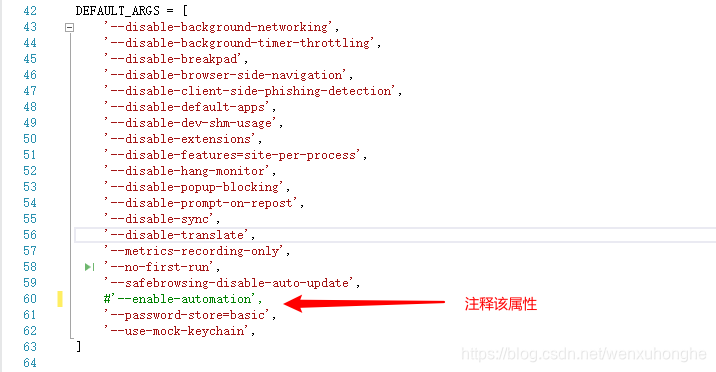
这种方法是我在方法一的基础上想到的,既然无法在代码中移除该参数,那么就在它的源码中注释掉,哈哈。
方法三:通过执行 js 脚本,把 webdriver 的值设置为 false,也可以避免被反爬检测。
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,'
'{ webdriver:{ get: () => false } }) }')下面放一段测试代码,亲测确实可行:
import asyncio
from pyppeteer import launch
url = 'http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml'
async def fetchUrl(url):
browser = await launch({'headless': False,'dumpio':True, 'autoClose':False})
page = await browser.newPage()
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,'
'{ webdriver:{ get: () => false } }) }')
await page.goto(url)
asyncio.get_event_loop().run_until_complete(fetchUrl(url))
大家还有没有知道其他绕过反爬机制检测的方法,欢迎在评论区一起交流分享!
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











