







上一节的kNN算法中,训练样本是直接输入进去的。这一节中,主要介绍如何把txt文本中的训练样本解析为numpy的array数组:
文本数据解析伪代码的流程:
1、打开txt训练文本:
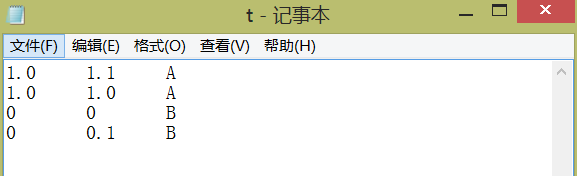
2、利用列表的strip函数和split函数来处理txt文件,函数的使用如下:

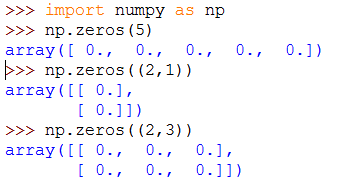
3、通过numpy的zeros函数来创建一个array数组,来存储训练样本数据,zeros的使用如下:
 本文介绍了如何将txt文本中的kNN训练样本解析为numpy array数组。内容包括:打开txt文件,使用strip和split处理数据,用zeros创建数组存储样本,定义列表存储标签,并展示数据解析的代码及测试结果。
本文介绍了如何将txt文本中的kNN训练样本解析为numpy array数组。内容包括:打开txt文件,使用strip和split处理数据,用zeros创建数组存储样本,定义列表存储标签,并展示数据解析的代码及测试结果。
上一节的kNN算法中,训练样本是直接输入进去的。这一节中,主要介绍如何把txt文本中的训练样本解析为numpy的array数组:
文本数据解析伪代码的流程:
1、打开txt训练文本:
2、利用列表的strip函数和split函数来处理txt文件,函数的使用如下:
3、通过numpy的zeros函数来创建一个array数组,来存储训练样本数据,zeros的使用如下:
 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















