







1、从文本中解析数据(特征数据和标签数据分离):file2matrix()
文本中的部分样本数据如下:

file2matrix()代码如下:

利用file2matrix()将特征值和标签值分离:
>>> import demo
>>> data,label=demo.file2matrix('D:\\datingTestSet.txt')
2、将特征数据归一化:autoNorm()
autoNorm()代码如下:

利用autoNorm()进行特征值归一化处理:
>>> import demo1
>>> normdata=demo1.autoNorm(data)
>>> normdata
array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]])3、将归一化的特征数据永久存储:pickle模块
利用Python的pickle模块存储归一化后的特征值data到本地硬盘空间中:
>>> import pickle as p
>>> data='D:\\data'
>>> f=open(data,'wb')
>>> p.dump(normdata,f)
>>> f.close()
4、基于kNN算法的分类器:classify0()

5、分类器算法的正确率测试:datingTest()
利用样本数据的10%作为测试数据,90%作为训练数据进入分类器,测试其正确率:

测试结果如下:
>>> import demo3
>>> demo3.datingTest()
The total error rate is: 0.0400006、用户层输入交互:person()
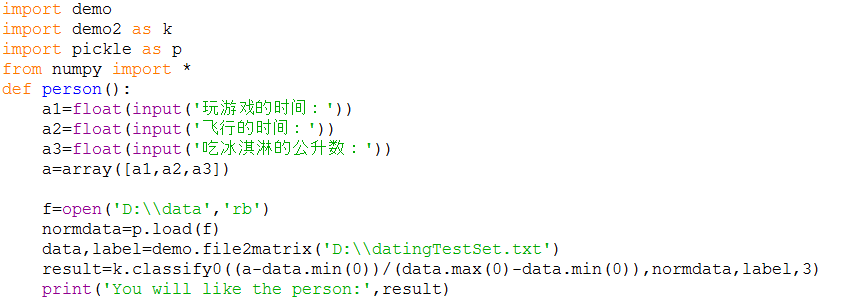
测试结果:
>>> import demo4
>>> demo4.person()
玩游戏的时间:10000
飞行的时间:10
吃冰淇淋的公升数:0.5
You will like the person: smallDoses















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









