






 本文详细介绍了MySQL8.0中InnoDB与MyISAM的不同,包括执行流程、支持的引擎、事务特性、隔离级别、索引使用、SQL优化以及与PostgreSQL(pg)的比较,强调了各自的优缺点和适用场景。
本文详细介绍了MySQL8.0中InnoDB与MyISAM的不同,包括执行流程、支持的引擎、事务特性、隔离级别、索引使用、SQL优化以及与PostgreSQL(pg)的比较,强调了各自的优缺点和适用场景。
一、mysql语句执行过程
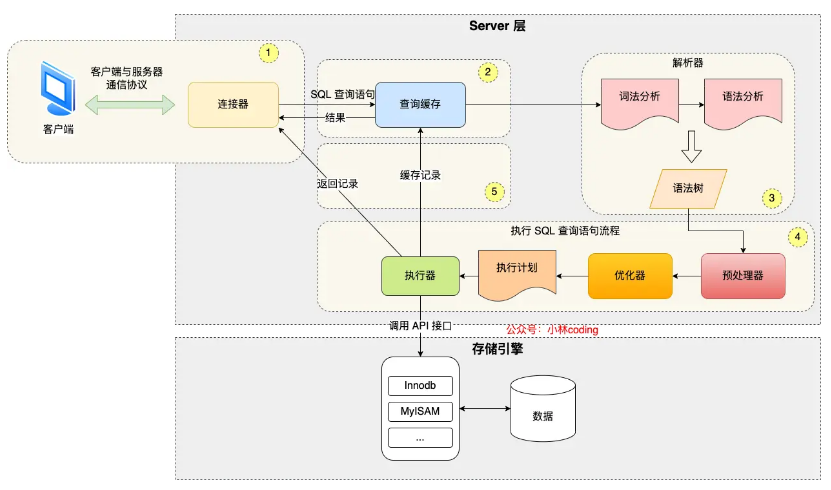
缓存在mysql8.0之后就被删除了,因为一旦表有更新,查询缓存就失效了。
预处理阶段会检查语句中的表名、列名的正确性等。
二、支持的引擎,Innodb和MyISAM的区别
mysql支持的引擎还是很多的,默认当然用的是innodb
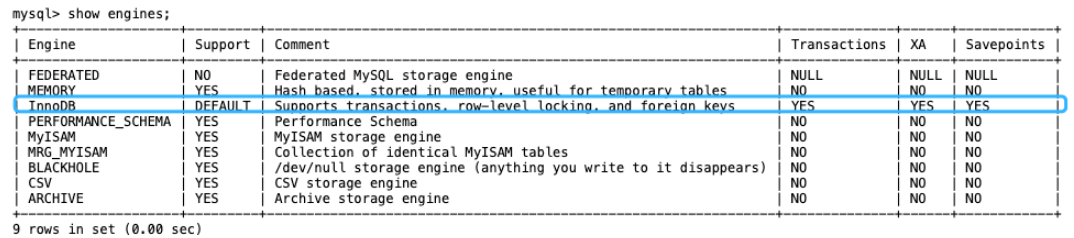
Innodb和MyISAM的区别:
1、行级锁:
MyISAM 只有表级锁,写操作为了不出现并发问题,会锁住整张表
Innodb有行级锁
2、事务:
MyISAM不支持事务
Innodb支持事务
3、外键:
MyISAM不支持外键
Innodb支持外键
4、数据库异常崩溃后的安全恢复:
MyISAM不支持
Innodb支持
5、MVCC
MyISAM不支持
Innodb支持
其实不支持行级锁肯定也不支持MVCC
三、事务
1、事务四大特性ACID:
原子性:要么都成功,要么都失败
一致性:执行事务前后,数据保持一致,例如转账操作,出和入得保持一致
隔离性:事务之间不互相干扰
持久性:事务被提交后,数据就永久保存了
2、事务带来的问题
脏读:读到的是另一个事务未提交的数据
幻读:count后有另一个事务新增记录,再count会不一致,重点在于新增
不可重复度:事务A读取数据后,事务B对这个数据做了修改,事务A再读一遍,结果不一致,类似于幻读。重点在于数据修改了
3、四个事务隔离级别
READ-UNCOMMITTED(读取未提交) :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
READ-COMMITTED(读取已提交) :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
REPEATABLE-READ(可重复读) :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
SERIALIZABLE(可串行化) :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,效率低
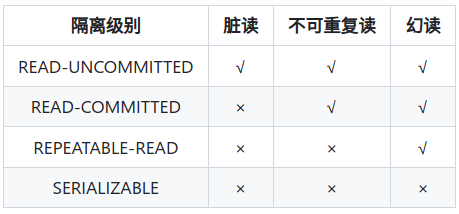
默认是可重复读
4、如何实现事务隔离
MVCC和读写锁
5、行锁类别
记录锁(Record Lock):也被称为记录锁,属于单个行记录上的锁。
间隙锁(Gap Lock):锁定一个范围,不包括记录本身。
临键锁(Next-Key Lock):Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
6、手动开启事务
START TRANSACTION;
// 操作
SAVEPOINT sp;
// 操作
ROLLBACK TO sp;
COMMIT;四、索引
Innodb使用B+树做索引
常见的如hash索引不能使用范围索引,因为只是key-value的键值对,查询单个数据的效率快
不同于B树,B+树的非叶子结点只会存储key,叶子节点的data域才会存储数据
但按照底层存储方式划分索引类型,可以分为聚簇索引和非聚簇索引。
在聚簇索引中,索引结构和数据一起存放,例如innodb的主键索引,B+树的叶子结点的data域存放的是数据本身
在非聚簇索引中,索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MyISAM不管主键还是非主键,使用的都是非聚簇索引。B+树的叶子结点的data域存放的是数据的地址
聚簇索引查询速度更快,能快速定位到数据本身,不用回表查询(先通过索引找到主键,再用主键回表里查一遍),但需要保证数据有序,并且维护成本相对较高,更新代价大
非聚簇索引更新代价较小,而且也需要保证数据有序,但还又可能需要回表查询,除非一些简单的按id查询的语句,即覆盖索引:要查询的字段就是索引字段。
五、sql优化
秉承三点原则:
(1)尽量不要使用select *
(2)尽量建立索引,但肯定不是索引越多越好,因为维护索引还是需要开销的
(3)查询索引需要上下限来做范围查询,所以尽量不要在条件语句中出现in 、not in、is null、<>、!=这种字眼,否则会全表扫描
六、日志
undo log回滚日志,redo log重做日志,binlog归档日志
undo log(回滚日志):是 Innodb 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC。
redo log(重做日志):是 Innodb 存储引擎层生成的日志,实现了事务中的持久性,主要用于掉电等故障恢复;
binlog (归档日志):是 Server 层生成的日志,主要用于数据备份和主从复制;
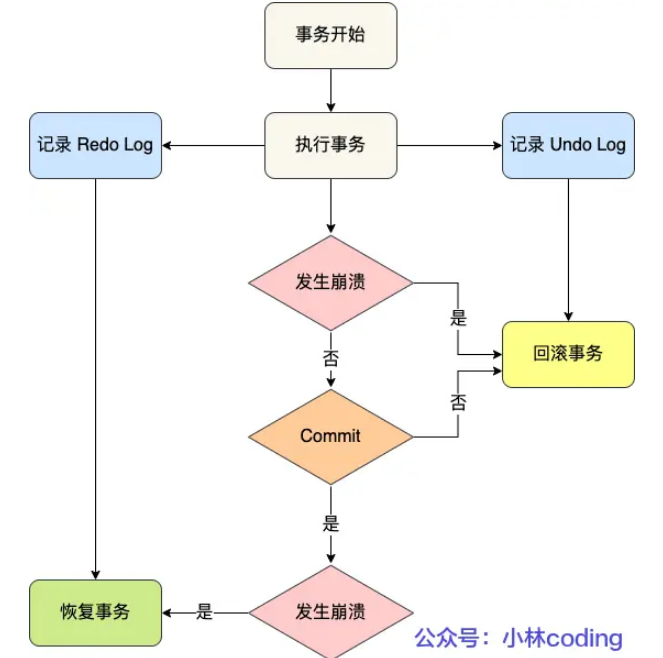
1、undo log:事务在执行中,但还未提交,mysql发生了崩溃,就需要undo log来回退事务,需要的是记录执行事务之前的状态。虽然还未commit,但事务已经写入了
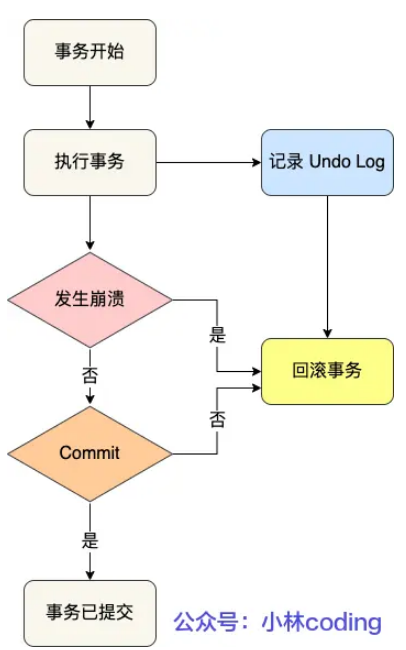
2、redo log
在事务中,所有修改其实都是先写到缓存+日志的,最后提交的时候再写到磁盘(由后台线程完成),所以一旦提交失败,还可以重新提交,重新提交就是根据日志来redo
redo log 和 undo log区别在于:
redo log 记录了此次事务「完成后」的数据状态,记录的是更新之后的值;
undo log 记录了此次事务「开始前」的数据状态,记录的是更新之前的值;
pg和mysql
pg默认用的堆存储引擎,mysql用的innodb
pg索引是标准的B树,mysql B+树
PG相对于MySQL的优势:
1、在SQL的标准实现上要比MySQL完善,而且功能实现比较严谨;
2、存储过程的功能支持要比MySQL好,具备本地缓存执行计划的能力;
3、对表连接支持较完整,优化器的功能较完整,支持的索引类型很多,复杂查询能力较强;
4、PG主表采用堆表存放,MySQL采用索引组织表,能够支持比MySQL更大的数据量。
5、PG的主备复制属于物理复制,相对于MySQL基于binlog的逻辑复制,数据的一致性更加可靠,复制性能更高,对主机性能的影响也更小。
6、MySQL的存储引擎插件化机制,存在锁机制复杂影响并发的问题,而PG不存在。
MySQL相对于PG的优势:
1、innodb的基于回滚段实现的MVCC机制,相对PG新老数据一起存放的基于XID的MVCC机制,是占优的。新老数据一起存放,需要定时触 发VACUUM,会带来多余的IO和数据库对象加锁开销,引起数据库整体的并发能力下降。而且VACUUM清理不及时,还可能会引发数据膨胀;
2、MySQL采用索引组织表,这种存储方式非常适合基于主键匹配的查询、删改操作,但是对表结构设计存在约束;
3、MySQL的优化器较简单,系统表、运算符、数据类型的实现都很精简,非常适合简单的查询操作;
4、MySQL分区表的实现要优于PG的基于继承表的分区实现,主要体现在分区个数达到上千上万后的处理性能差异较大。
5、MySQL的存储引擎插件化机制,使得它的应用场景更加广泛,比如除了innodb适合事务处理场景外,myisam适合静态数据的查询场景。
开源数据库都不是很完善,商业数据库oracle在架构和功能方面都还是完善很多的。从应用场景来说,PG更加适合严格的企业应用场景(比如金融、电信、ERP、CRM),而MySQL更加适合业务逻辑相对简单、数据可靠性要求较低的互联网场景(比如google、facebook、alibaba)。
mysql是开源的数据库,有安全漏洞,一旦因为安全漏洞受到攻击,公司还是要承担风险的,但PG是通过版权渠道来的,可以规避安全风险















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









