






当集群外部来请求或者集群内部pod间互相调用时,都需要知道请求地址,也就是ip、端口,但是pod的ip是在创建后才分配的,并且一旦重启、水平伸缩,ip都会变,所以无法确定请求的ip,于是有了服务的概念。
一、介绍服务
1、定义
k8s服务是一种为一组功能相同的pod提供单一不变的接入点的资源。
看一个前后端例子:
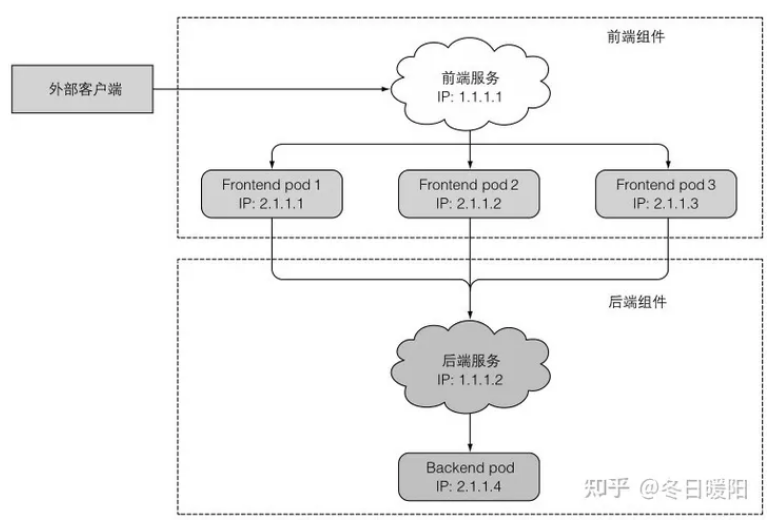
2、创建服务
和RC、RS一样,服务也是用标签来管理pod的,创建服务有两种方式:
(1)将RC或RS暴露为一个服务
kubectl expose replicationcontroller rc名 --type=LoadBalancer --name 服务名(2)yaml
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- port: 80 //服务对外的端口
targetPort: 8080 //服务将连接转发到的容器端口
selector: //标签选择器
app: kubia通过kubectl get service查询所有服务,可以看到服务的ip
找一个pod curl一下服务ip
kubectl exec pod名 -- curl -s http://ip // -- 用于分割后面在pod里执行的命令如果一个服务管理了多个pod的副本,那服务会将请求随机转发到一个pod上,如果想让每次来自于某个客户端的请求都转发到特定pod上,可以在yaml里加参数
spec.sessionAddinity: ClientIP
可以看到yaml里端口是一个列表,也就意味着可以暴露多个端口出去,但暴露多个端口时,一定要指定端口的名称,并且给targetPort也起个名字,这样一旦容器的端口号变了,至少名字不变,还是能转发到容器上的
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- name: http
port: 80
targetPort: http
- name: https
port: 443
targetPort: https
selector:
app: kubia3、服务发现
服务创建后,我们就可以通过一个稳定单一的ip去访问pod,在服务的整个生命周期,这个ip都不会变,无论pod重启、重建还是水平伸缩,ip地址变了也能访问到。
但pod之间是怎么知道这个ip的呢?
(1)环境变量
使用命令
kubectl exec pod名 env查看pod的环境变量,如果pod创建时,服务已存在,则环境变量里就会有服务的ip和端口,如果服务在pod后创建,则没有
(2)DNS
在kube-system命名空间下有个pod名字叫kube-dns,这个pod运行DNS服务,集群里的其他pod都被配置了使用它作为dns,运行在pod上的进程DNS查询都会被k8s自身的DNS服务器响应,也就是这个服务,这个服务知道系统中运行的所有服务。pod是否使用内部的DNS服务器是根据pod的spec.dnsPolicy属性决定的。
(3)FQDN
每个服务都会有自己的FQDN(全限定域名)
backend-database.default.svc.cluster.local第一个是服务名,第二个是命名空间,后面的是在所有集群本地服务名称中使用的可配置集群域后缀,,同一个命名空间下,可以省略后缀和命名空间
二、连接集群外部的服务
1、介绍服务Endpoint
服务通过标签选择器管理一些pod,但当有请求来到服务时,服务是怎么转发请求到特定pod呢?至少得知道pod的ip、端口吧,也就是说服务和pod之间还有一层资源----Endpoint,用来暴露一个服务下所有pod的ip和端口
用kubectl describe service 时,会有一个字段Endpoint

实际上,k8s中有个endpoint controller组件,它是负责生成和维护所有endpoint对象的控制器
负责监听service和对应pod的变化
监听到service被删除,则删除和该service同名的endpoint对象
监听到新的service被创建,则根据新建service信息获取相关pod列表,然后创建对应endpoint对象
监听到service被更新,则根据更新后的service信息获取相关pod列表,然后更新对应endpoint对象
监听到pod事件,则更新对应的service的endpoint对象,将podIp记录到endpoint中
2、手动配置服务的Endpoint
当创建服务时,没有指定标签选择器,endpoint controller则不会创建相应的Endpoint资源,这时候,我们需要手动去创建一个Endpoint,指定pod的ip端口,并且将名称和服务名称保持一致,就可以让服务和pod对应起来
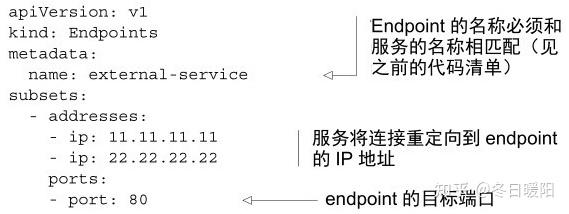
当外部服务不归pod管理时,手动配置服务和Endpoint绝对是一个好的方式,因为无法给外部服务打标签,直接创建一个服务,创建对应的Endpoint并配置外部的ip、端口,内部pod访问该服务时,就可以自动转发到外部的ip、端口上了。
三、将服务暴露给外部客户端
有三种方式对外暴露一个服务--------服务类型设置为NodePort、服务类型设置为LoadBalance、创建一个Ingress资源
常规服务的类型是ClusterIP
尤其是web应用需要对外暴露,客户端即是浏览器
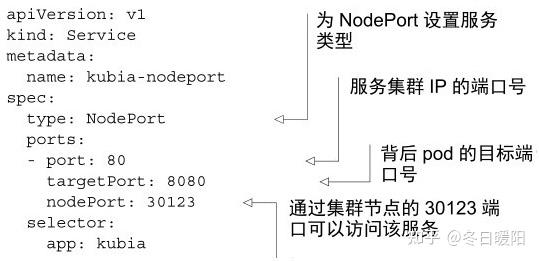
1、使用NodePort类型的服务
通过创建NodePort服务,可以让k8s在其所有节点上保留一个端口(所有节点上都用相同的端口号),并将传入的连接转发给作为服务部分的pod
对于常规服务来说,只可以通过服务的内部集群ip访问,但是NodePort还可以通过任何节点的ip和预留节点端口访问服务。
(1)创建一个NodePort类型的服务
(2)查看该服务
使用kubectl get srv 查看
kubectl get svc kubia-nodeport
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
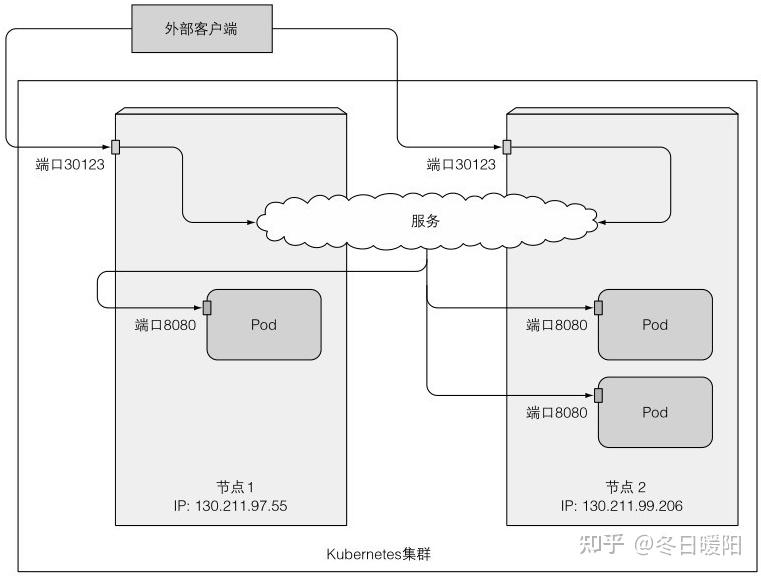
kubia-nodeport 10.111.254.233 <nodes> 80:30123/TCP 2mEXTERNAL-IP列显示的是nodes,说明可以通过任意一个节点访问这个服务,加上端口信息,可以通过以下任一地址访问该服务:
10.111.254.233:80
<1st node's IP>:30123
<2nd node's IP>:30123等
最终的请求会调度到哪个pod上是不确定的:
(3)更改防火墙规则,让外部客户端访问我们的NodePort服务
有时,外部客户端不一定能通过节点访问服务,记得关防火墙
2、通过负载均衡器将服务暴露出来
在云提供商上运行的k8s集群通常支持从云基础架构自动提供负载均衡器,只需要将服务类型设置为Load Balancer即可。负载均衡器拥有一个可公开访问的IP地址,并将所有连接重定向到服务,可以通过负载均衡器的IP访问服务,不用知道节点的IP
但是如果k8s运行在不支持load balancer服务的环境中运行,就不会调用 负载均衡器,服务将表现为一个NodePort类型的服务,因为Load Balancer是NodePort的扩展。
创建:

没有指定特定的节点端口,k8s会随机选择一个端口
查看:
kubectl get svc kubia-nodeport
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubia-nodeport 10.111.241.153 130.211.53.173 80:32143/TCP 2mEXTERNAL-IP就是负载均衡器的IP地址,访问只需 curl http://130.211.53.173, NodePort的访问方式依然可用
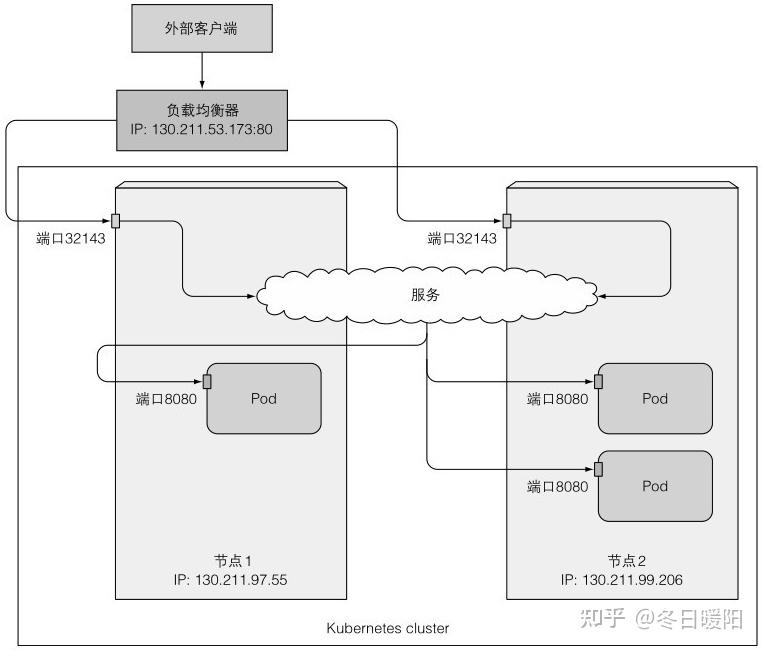
这中方式也会经过节点端口,所以loadbalancer是nodeport的扩展
3、了解外部连接的特性
(1)了解并防止不必要的网络跳转
当客户端通过节点端口连接服务时(或负载均衡器),随机选择的pod不一定在指定节点上,可能需要额外的网络跳转才能到达pod,可以在创建服务时设置参数指定选择本地运行的pod
spec:
externalTrafficPolicy: Local这样会有两个缺点:
a.通过节点端口连接服务:服务代理会选择本地运行的pod,但当本地没有运行pod(所有pod都在其他节点上运行,或本地pod挂了)则连接将挂起,所以,要确保负载均衡器将连接转发给至少有一个pod运行的节点
b.通过负载均衡器ip连接服务:不设置这个策略时,连接均匀的分布在所有pod上,设置了之后,连接均匀的分布在节点上。假设三个pod,节点A运行一个,节点B运行两个,原先每个pod接收请求的概率均为1/3,现在是第一个pod 50%,第二和三个pod每个25%
(2)客户端IP是不记录的
集群内客户端访问服务时,pod可以获取客户端的ip,但是当客户端是外部来的时,通过节点端口接收到连接时,数据包执行了源网络地址转换,源IP变了,pod无法查看实际的IP
四、通过Ingress暴露服务
为什么需要Ingress?
总结上述两种方式:NodePort类型的服务可以通过节点端口连接;Load Balancer类型的服务是NodePort的扩展,除了节点端口连接外,还可以通过负载均衡器的IP连接服务。
但load balancer这种方式下,每个服务都会有一个负载均衡器,以及其独立的公网IP,这种方式就显得不好,那么就需要用到Ingress了
当客户端向Ingress发送HTTP服务时,Ingress会根据请求的主机名和路径决定请求转发到哪个服务
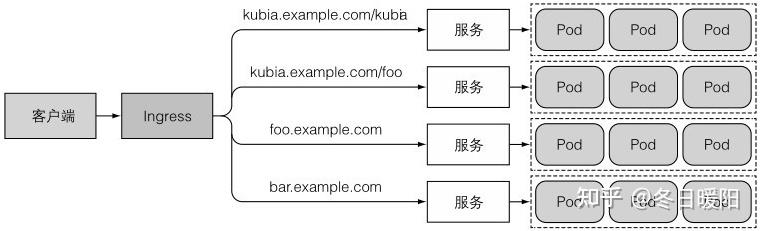
必须强调的是:集群中必须运行了Ingress控制器,Ingress资源才能正常工作
1、创建Ingress资源
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
rules:
- host: kubia.example.com //Ingress将域名kubia.example.com映射到你的服务
http:
paths:
- path: / //将所有请求发送到kubia-nodeport服务的80端口
backend:
serviceName: kubia-nodeport
servicePort: 802、通过Ingress访问服务
(1)列出Ingress的IP
kubectl get ingresses
NAME HOSTS ADDRESS PORTS AGE
kubia kubia.example.com 192.168.99.100 80 2m(2)配置/etc/hosts
192.168.99.100 kubia.example.com
(3)通过Ingress访问pod
(4)了解Ingress的工作原理
Ingress控制器不会将请求转发给该服务,只用它来选择一个pod
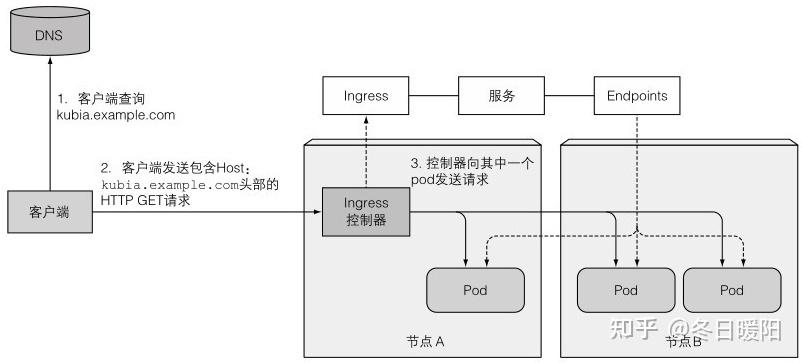
3、通过一个Ingress暴露多个服务
仔细看看创建Ingress的yaml,可以看到rules和paths都是数组,也就是说可以配置多个

或

4、配置Ingress处理TLS传输
上述的请求都是http的,如何配置Ingress以支持TLS呢?
pod之间的通信不需要支持TLS,运行在pod上的应用也不用支持TLS,让Ingress控制器去处理与TLS相关的内容即可。
TLS最重要的组成部分:证书、私钥
使用openssl生成一个证书和私钥,创建一个Secret资源:
kubectl create secret tls tls-secret --cert=tls.cert --key=tls.key
现在证书和私钥存储在名为tls-secret的Secret资源中了,现在可以更新Ingress了
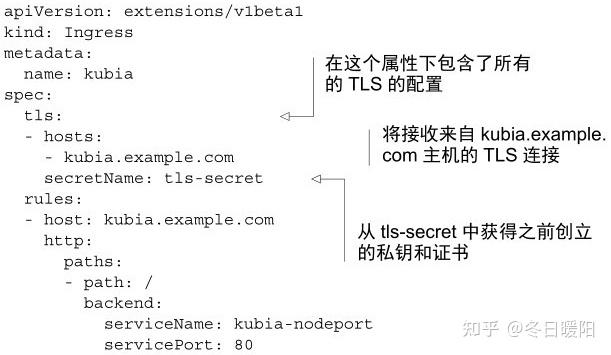
使用命令 kubectl apply -f xxx.yaml来更新Ingress,而不是删除并重建
这样就可以使用https访问服务了
五、pod就绪后发出信号
Ingress、服务、pod一键启动后,pod内的进程启动需要时间,这时客户端的访问肯定是得不到任何响应的(参考MANAGER里启动时的服务间依赖)
1、介绍就绪探针
之前讲过存活探针,用于确保异常容器自动重启
就绪探针也一样,就绪探测器定期调用,并确定特定的pod是否接收客户端请求。当容器的准备就绪探测返回成功,表示容器已准备好接收请求
(1)就绪探针的类型
类似于存活探针,就绪探针也有三种类型:
a、Exec探针:执行进程的地方,容器的状态由进程的退出状态码确定
b、HTTP GET探针:向容器发送GET请求,通过响应的HTTP状态码判断容器是否准备好
c、TCP Socket探针:打开一个TCP连接到容器指定端口,如果连接建立,则容器准备就绪
(2)了解就绪探针的操作
启动容器时,设置一个等待时间,等待多久后开始就绪探测,之后就会周期性的探测,当探测到容器未就绪时,则会从Endpoint中删除该pod,确保请求不会转发到该pod,如果pod再次准备就绪,则重新添加pod
就绪探针与存活探针最大的不同是:就绪探针探测失败了不会重启容器。
(3)就绪探针的重要性
endpoint中只维护就绪的pod,这样访问服务时总是与正常的pod交互
2、向pod添加就绪探针
可以通过修改Replication Controller的pod模板来为现有pod添加就绪探针
kubectl edit rc rc名

这个就绪探针是执行ls /var/ready命令,查看这个文件存不存在,存在则说明就绪
修改后删除原有pod即可
六、使用headless服务来发现多个pod
当连接一个服务时,这个连接会被转发到随机一个pod上,但如果我想连接这个服务下所有的pod呢?我需要知道他们的ip并直接连接pod,如何知道他们的ip呢?就要通过 DNS了
有一个tutum/dnsutils的镜像,可以运行容器后使用命令 nslookup 来查询DNS,例如启动了一个名为dnsutils的pod
kubectl exec dnsutils nslookup kubia
则会查询出kubia这个服务的IP
但上述命令显示的是服务的集群IP(集群IP默认都是有的),离我们想要的服务下所有pod的ip还不是一码事
考虑让一个服务没有集群IP,该命令就可以显示服务下所有的pod的ip了
那就让服务的clusterIP选项置为None吧
apiVersion: v1
kind: Service
metadata:
name: kubia-headless
spec:
clusterIP: None
ports:
- port: 80
targetPort: 8080
selector:
app: kubia这样就创建了一个headless服务,纳管了所有标签为app=kubia的pod,并且没有ClusterIP,再用上述查询DNS的命令查询该服务对应的ip,就可以看到服务下所有pod的ip了















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









