







系列文章目录
Mysql集群及高可用-Mysql高可用MHA
mysql集群及高可用
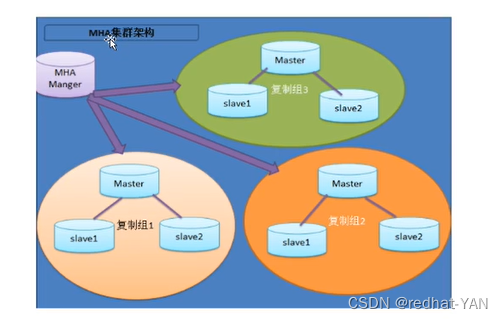
一、Mysql集群-高可用MHA
主复制是内部高可用是官方的,节点最多9个
实际情况节点更多,也需要主从架构
MHA利用了主从复制原理
Mysql高可用的架构一般都利用了主从复制,所以Mysql的重点是弄懂它的二进制日志
数据的一致性、备份、恢复都是依靠二进制日志
去中心化的架构往往比较重量级,相对操作比较复杂
一个节点需要装MHA Manger 在数据库(一主两从)需要安装MHA node
即server4 安装MHA所有包
server1、2、3 安装MHA node(都是操作二进制日志的工具包)
二、实验环境准备
1.在server4上停掉刚才做的Mysql路由服务system stop mysqlrouter.service
2.拆掉多主server1、2、3,即停掉mysql数据库
/etc/init.d/mysqld stop
3.清理掉server1、2、3数据目录里的数据(之前的数据是针对主复制的)
cd /usr/loacl/mysql/data
rm -fr *
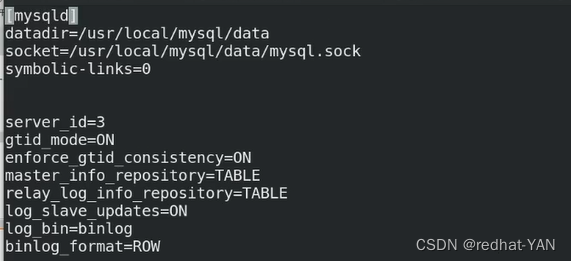
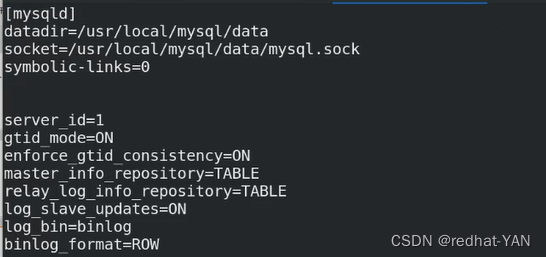
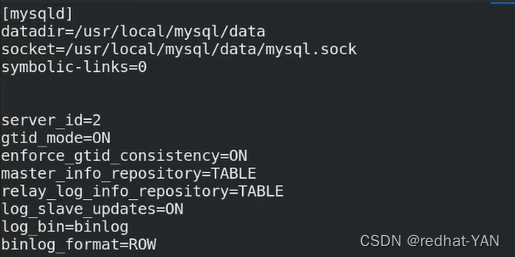
4.server1、2、3修改配置/etc/my.cnf文件,恢复成主从架构,一主两从的架构
所有节点配置一样,因为组从高可用切换,原先是slave可能会变成master
server3:
server1:
server2:
5.server1、2、3修改/etc/my.cnf后初始化mysql
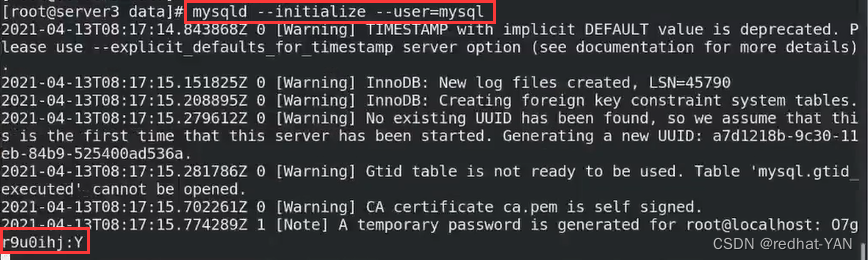
6.server1、2、3启动mysql/etc/init.d/mysqld start
三、Gtid模式一主两从
server1(master):
使用初始化后的临时密码后进入数据库
生产环境,在初始化后推荐使用安全初始化家脚本后进入数据库,
因为这样可以控制权限更安全
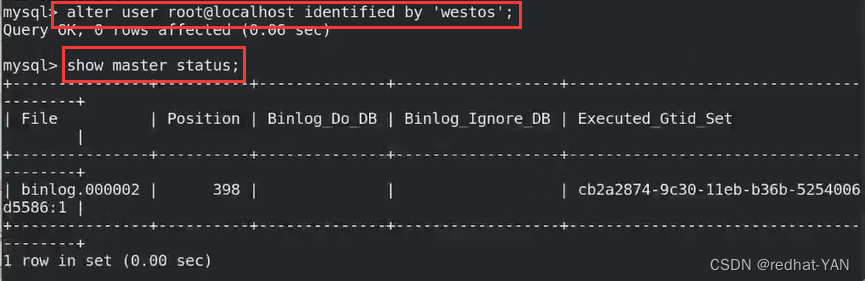
授权

server2(slave):
使用初始化后的临时密码后进入数据库


同理server3


四、MHA配置
下载MHA(还要下载它的依赖性,我是把MHA和它所需的依赖性都放在MHA包里面了)
我提前下载好直接取,我下载的是0.58版本(支持gtid),之前版本只支持pos号
server4:
有大量的复制,所以需要做免密
ssh-keygen
后面提示全是回车就行
这个操作给server1、2、3
ssh-copy-id server1
ssh-copy-id server2
ssh-copy-id server3
将node安装包给server1、2、3
server1:
安装Node包,同理server2、3(不截图了)

Node包都是一些操作二进制日志工具的包
第一个diff是差异的工具(针对relay_log)
第二个filter过滤的工具(binlog)
第三个purge回收的工具(relay_log)
第四个save保存的工具(binlog)
server4:
Manager包
都是二进制指令,没有配置文件
check_ssh检测各个节点的连通性
check_repl检测主从复制是否完整
manager MHA后台管理节点
check_status检测MHA状态
master_monitor监控
master_switch手工的故障切换
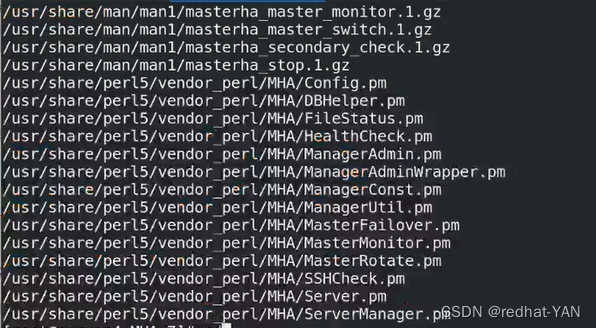
工具包总结:

五、配置主配置文件
server4:

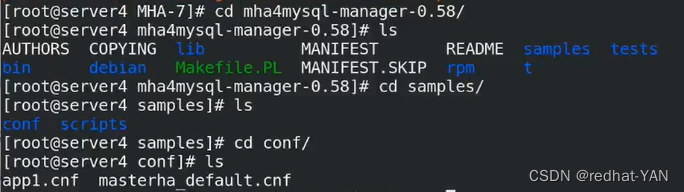
conf理解每个server(每个数据库实例的配置,写入每个数据库的主,从)
global(除了主从其它信息写入这)
app1.cnf针对数据库实例的配置,每个实例是一个管理进程,app1单独创建由manager来启动
manager进程可以读取不同的app1来启动
我的习惯是只写一个,因为目前只有一个实例
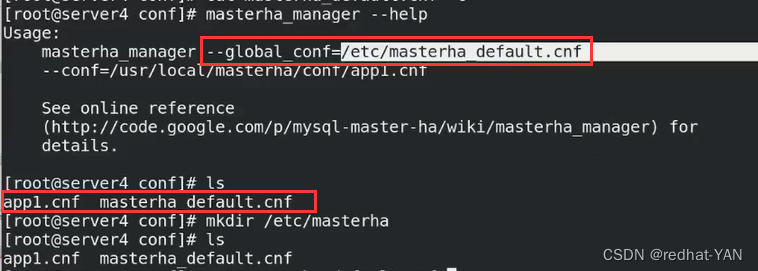
将两个配置写成一个


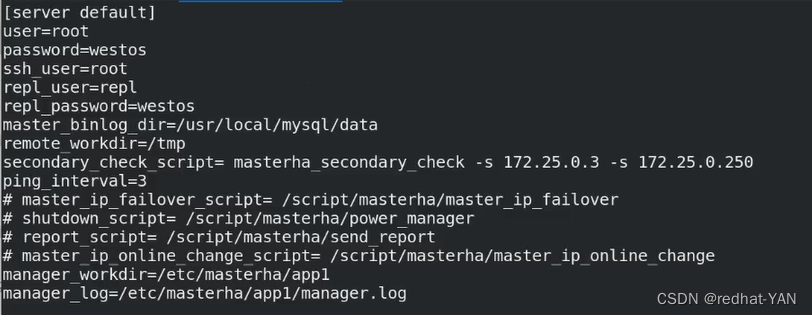
server default就是global
user是数据库用户管理员的名(管理员必须能远程登录)
需要通过管理员用户登录到远程数据库执行相应的指令,比如change master to
password数据库管理员的密码
ssh user 是操作系统的root(需要免密)主机节点server4装了很多工具包的指令,需要通过操作系统的root免密去调相应的二进制程序来做相应的操作(对你的二进制日志)
repl_user和repl_password主从里面的复制用户和密码
remote_workdir远程工作目录(随意指)
secondary脚本(二层网络检测)
如果manager和后端的网络出现故障,第一个ip是网内其它节点(判断是不是manager网络是否有问题),第二个再写远程数据库(判断是其它数据库出现问题)
manager出现故障,其实Mysql集群是好的,不可能在集群内做故障切换
我写的第二个是3,因为3一般是slave我不会切换它,第一个指向250(宿主机的地址)
ping是每隔3s
工作目录和日志设置到那块就去那块看
实例
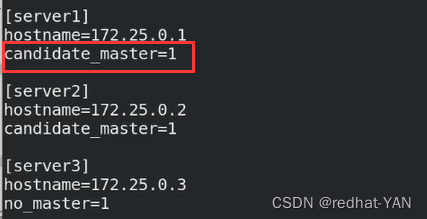
server1是master
server2是备用master(1挂了会接管)
server3默认情况下不会接管
1挂了2接管,1恢复后,2挂了,1接管
所以现在一主两从架构,主要1和2接管,3始终处于备用状态
校验各个节点的免密连接

我是两个文件写到一个文件了,所以会有Warning,但是没有关系,跳过了
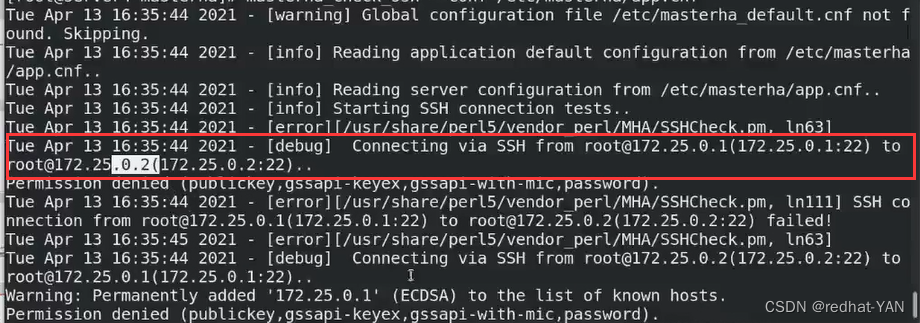
1免密2,连接错误了Permission denied
2也连接1,可以发现是需要彼此间都需要免密
要求的manage可以对集群所有服务器都能免密,服务器间能互相免密
即server4对server1、2、3都能免密,server1、2、3间互相免密
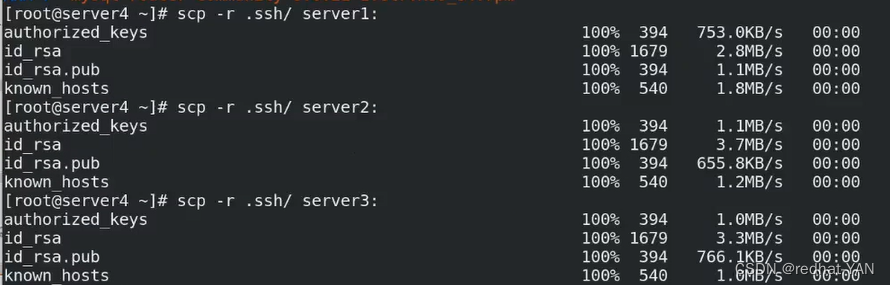
做免密,在server1、2、3 上面做ssh-keygen ssh-copy-id server1、2、3、 太麻烦
server4直接把这个目录(之前server4对1、2、3做过免密)给server1、2、3就行了(大家使用同一个公钥,密钥对一样)
彼此免密server4要对自己也免密
server4:

检测成功后检测主从
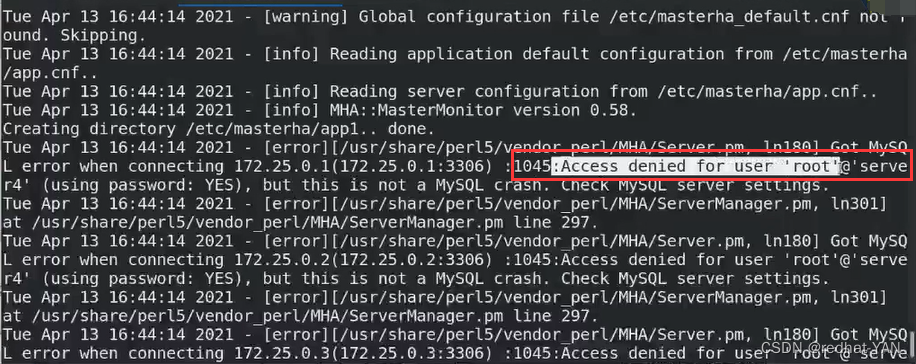
免密和主从的检测都必须通过后才能做后续的

root远程免密失败,默认情况下管理员没有远程登录的权限
server1:
进入数据库后授权
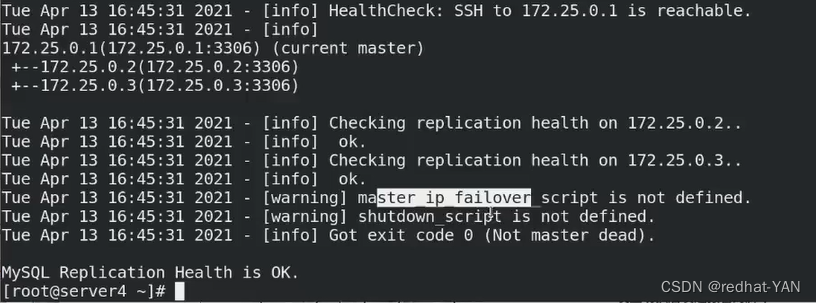
server4:
再次检测脚本,但是告知shutdown脚本master_ip脚本没有

六、高可用手动切换
6.1状态一(master在线状态)
手动切换分为2种masterha_master_switch
第一种是维护状态(比如server1,要更换下硬件或者维护一下需要切换到server2)master端是活着的,第二种是挂掉了
数据库默认端口是3306但是有时候为了安全可能会变,根据实际情况自己写
orig_master_is_new_slave(数据库是活的,通过数据库的root SA,密码登上去把原来的master切换成新的slave)
running_updates_limit超时时间

server4:

刷新,这个时候不要写二进制日志了(别切换的过程中丢数据了)YES

询问你是不是要把master从1变成2,YES
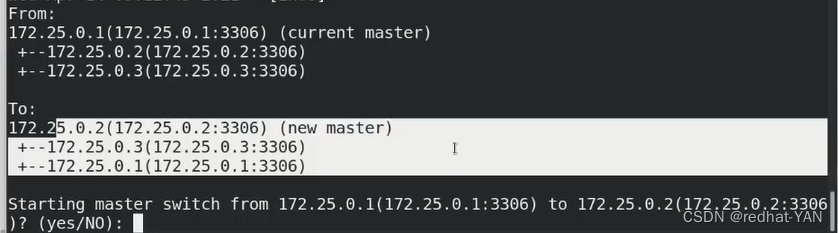
在线手动切花需要调动脚本,脚本的意义在于创建和回收vip(漂移vip),高可用必须要有vip支撑,要不然外部的客户端,原本访问1的,现在切到2,客户端不知道,让客户端重新连接不合适,所以切换的时候保持主从vip不变,YES
现在没有这个脚本,也没有VIP,就正常切换(不用考虑那么多)

切换的过程会做锁表动作,保证切换过程中,不能频繁写入,造成数据不一致的情况
直接用chek_repl可以查看到当前的状态

server2是master
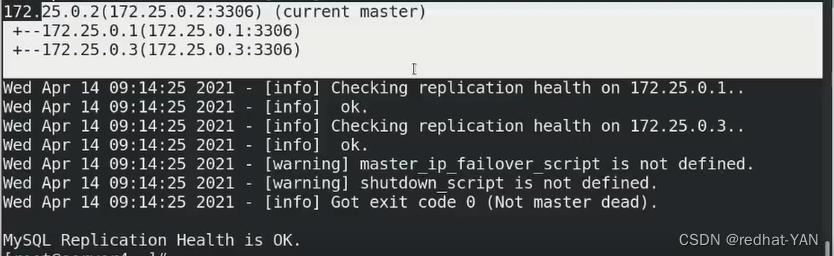
server2:
进入数据库后
可以发现slave是空的,所以再次验证它是master
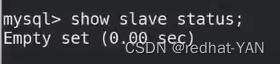
server1、3
6.2状态二(master挂掉状态)
server2:

停掉后,外部没有监控不可能自动切换的,想用Mysql本身的高可用不用外部监控,只能用MGR
server1、3:



server4:
–ignore_last_failvor

询问你是不是原先的master挂掉了YES

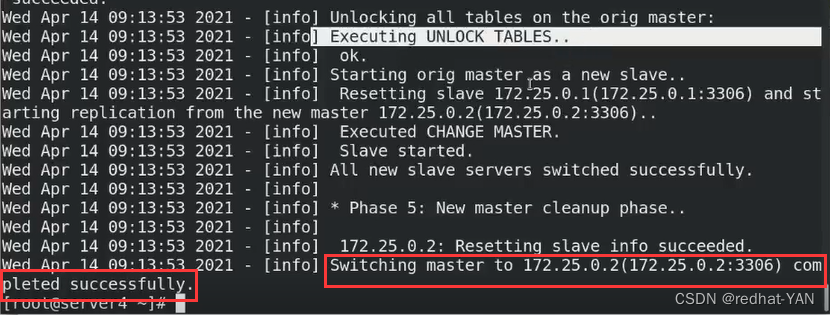
询问是是不是要把master从2变成1YES
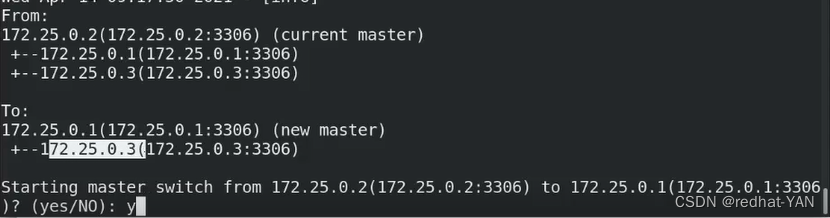
故障切换完成
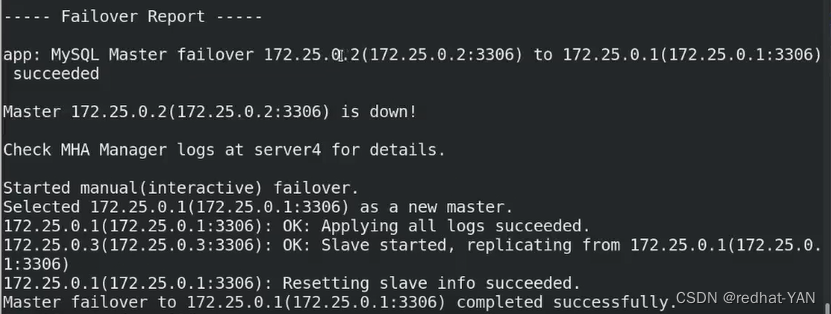
执行完后,app1多出文件
空文件就是个锁定文件(避免服务的抖动)
(下次执行的时候,–ignore参数就是忽略这个文件)
–ignore_last_failvor
因为一旦发生故障切换后(现在就是故障切换2到1)活着的状态不会生成
切换是没问题的,但是不希望频繁切换,比如网络抖动出现1切2,2切别的机器
每次做完故障切换就会生成这个文件,它会在8h内再做切换,因为你频繁切换任务你服务不稳定,是抖动状态
如果你有这个频繁切换的需求就可以加上这个选项--ignore_last_failvor (忽略这个文件)或者进入目录后直接删掉

server3:

测试成功
手动切换没有日志
在cat /etc/masterha/app.cnf主配置文件中定义了
里面只有manager_log,因为手动切换的过程中就加载了日志,很详细

手动切换过程中的,记录的很详细
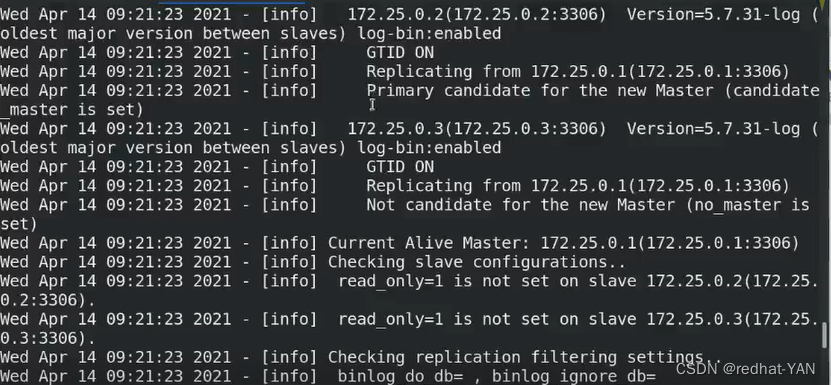
server2:
还原实验环境状态
恢复数据库服务

进入数据库
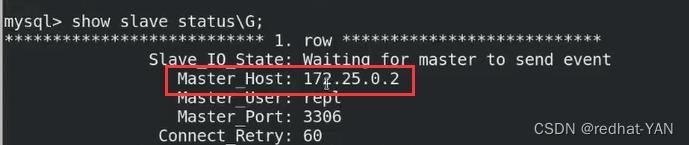
show slave status\G;


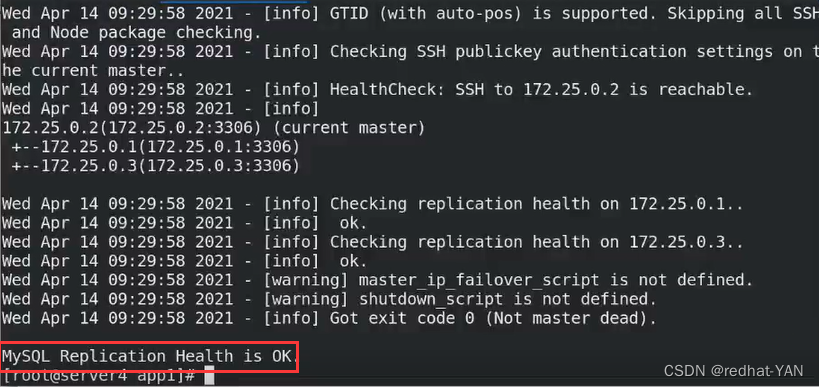
server4:
再次检测

状态是好的
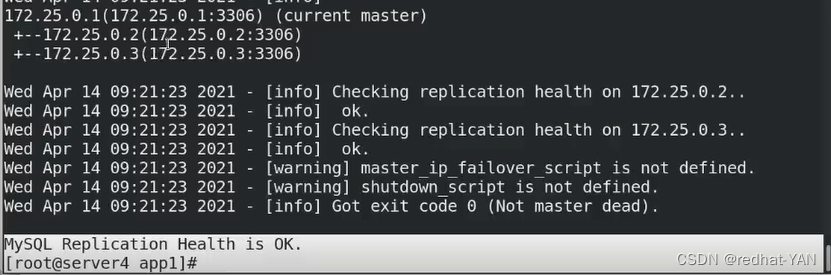
七、自动切换
server4:
由于上面有锁定文件,所以需要删掉


perl程序,perl运行的

这个进程做完一次故障切换后就自动退出了,避免来回的切
希望在后端保持监听(写个脚本或者demotools后台维护)持续在后端运行着
这个进程专门管控/etc/masterha/app.cnf这个文件写的的数据库实例的,一旦做完高可用就退出了,所以可以创建多个数据库实例的文件,然后启动多个进程,每个进程监控一个实例,推荐每个文件(进程)监控一个数据库实例,做完切换后自动退出
测试
1现在是Master

每3s检测一次节点的连通性,当发现server1出现故障的时候,开始自动切换Master
perl进程开始启动开了
检测,然后ssh
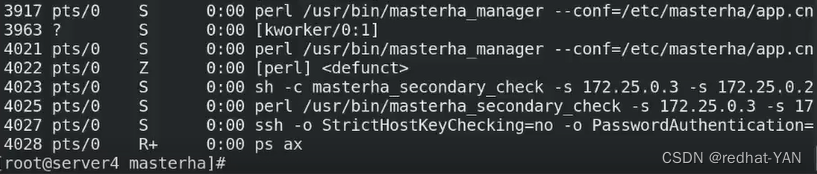
进程没停止,然后server2show slave status\G;仍然有信息
出错了
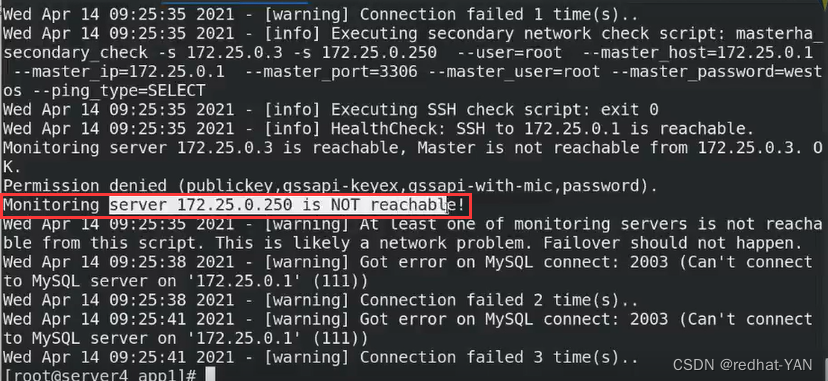
查看日志
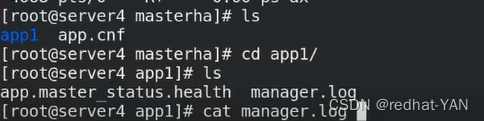
免密有问题,监控主机0.250不可到达


换成2和3,这样方便做实验(生产环境尽量是网内其它节点,判断是不是manager网络是否有问题)
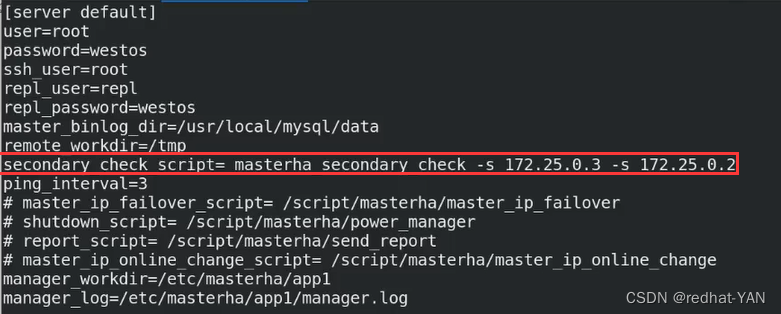
重新测试



进程响应,一旦做完切换,进程就自动退出了
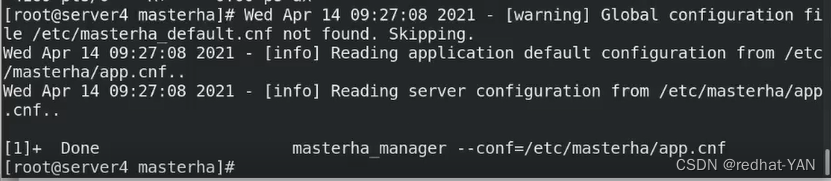
server3:
切换过去了

server4:

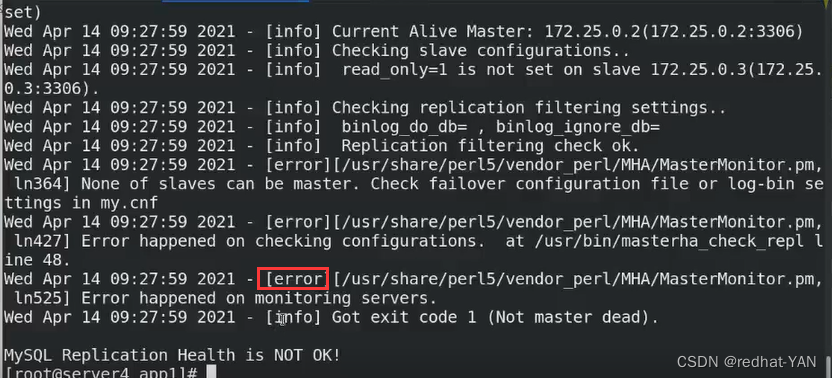
not ok
因为现在1挂了,不满足一主两从的结构
server1:
进入数据库


show slave status\G;

server4:

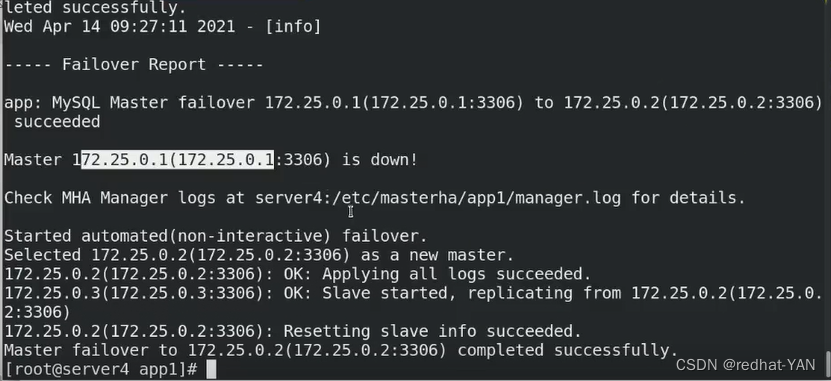
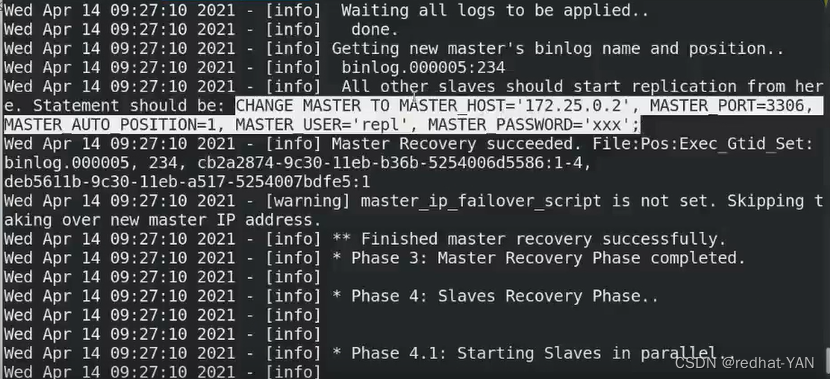
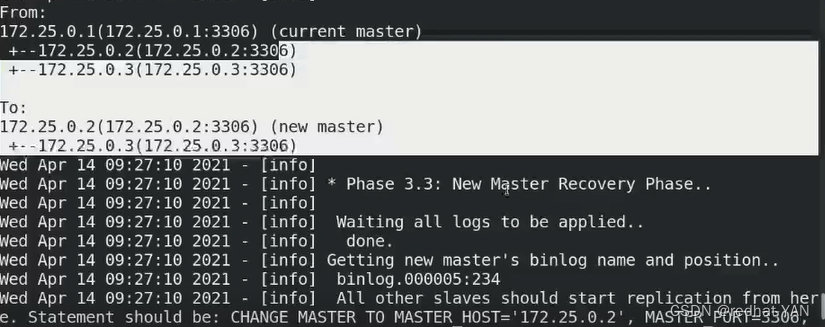
自动切换,不显示日志,需要到主配置文件中指定的日志目录查看
和手动切换记录的日志其实是差不多的

可以发现获取新master的二进制日志目录和pos号
通过远程方式连接数据库实例,执行相应的change master to 等
实际情况更推荐手动切换,数据库维护的过程中需要小心一些,数据库太核心了
万一数据一致性有问题,会造成损失
不是特别重要的实例可以自动切换,如果数据库实例特别重要,尽量用手动切换,确保数据一致性后再切换会更加的稳妥
八、书写脚本让perl程序一直监控数据库实例
server4:
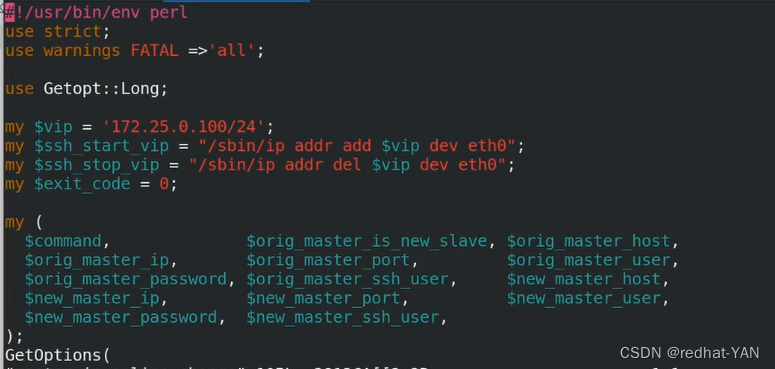
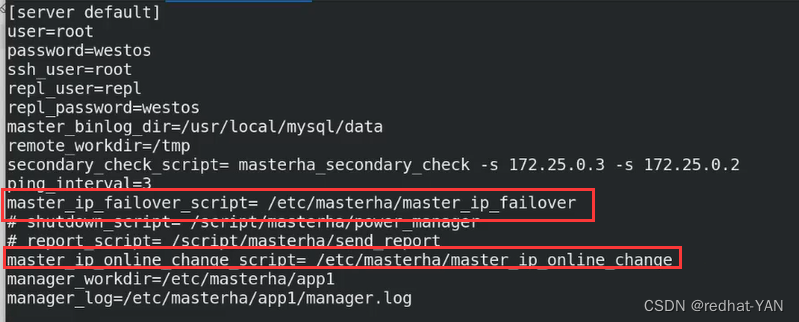
用到上面没有用到的vip,脚本放在我的服务器中pub/docs/mysql/master_ip_failover

一个是自动切换,一个是手动切换
online是手动切换的时候,vip的飘逸调动的脚本
自动切换调用failover

由于是脚本所以需要加上x权限
这两个脚本是根据作者的源码例子改的
power_manager是不完整的,打开后,需要根据实际的情况来修改,因为不知道你是什么设备

send_report 需要接入到公司实际的邮件服务器上面

需要把vip改成自己的,启动vip的时候是通过ssh执行了ip的指令来添加/摘除到eh0接口上vip(根据自己的接口情况写),接口不是eth0需要更改
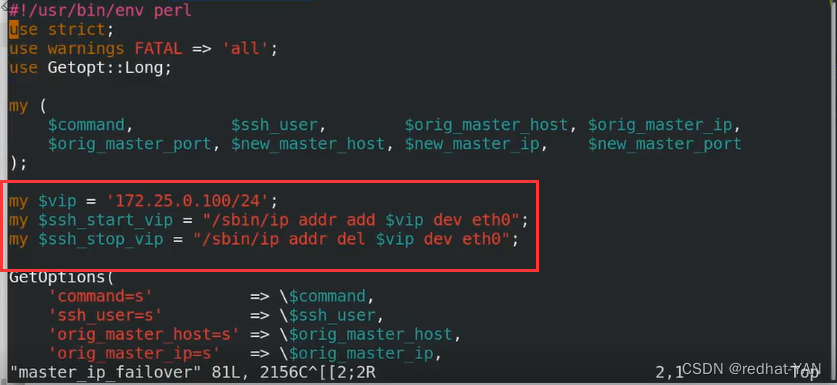
一样的

模拟
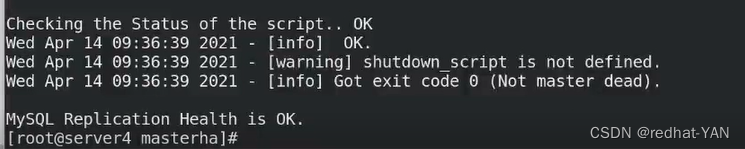
检测成功

修改主配置文件将这两个参数打开

再次测试

2是master

宿主机:
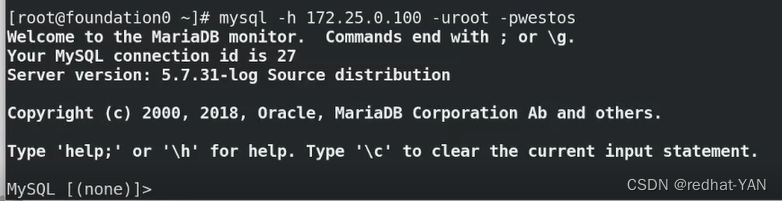
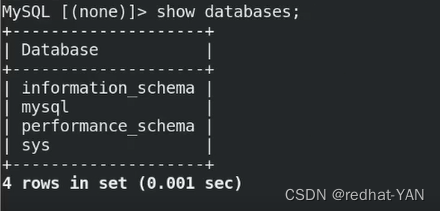
server4:
将master切换到1(手动切换)两个YES

server1:
server1加入VIP了,调用脚本成功
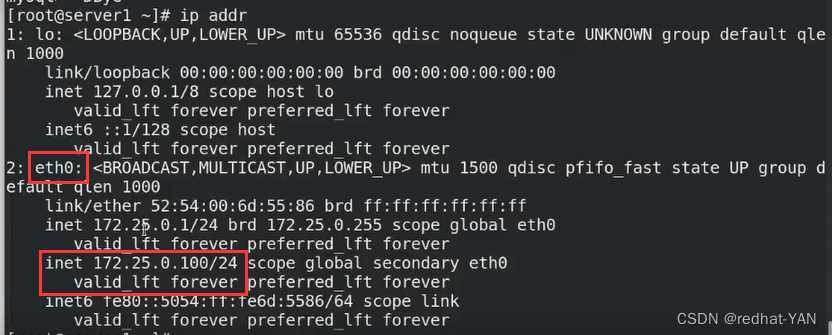
server2:
vip被摘取了
宿主机:
因为变更了数据库实例,因为VIP有2漂移到1上面了,会卡一下,但是没有关系,客户端数据库会重连的
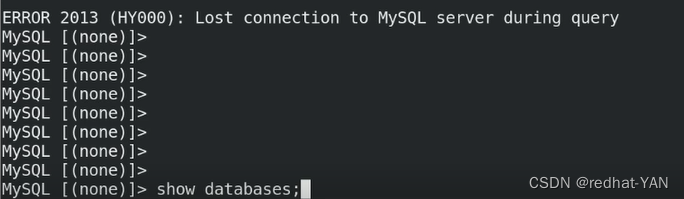
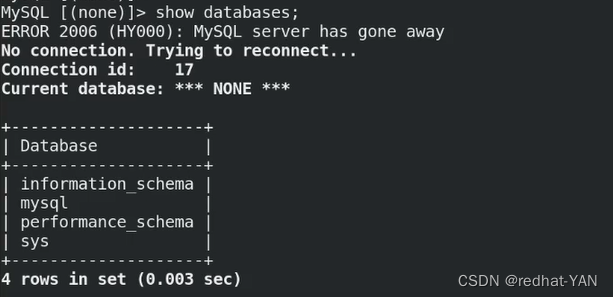
测试成功
再次做一次检测


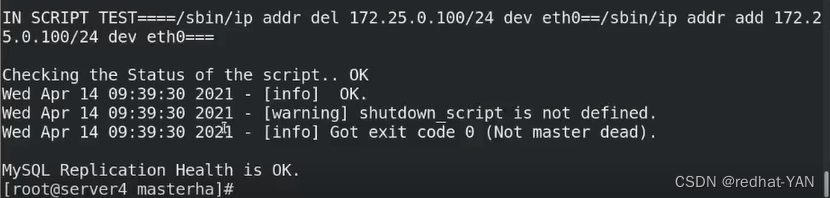
现在1是master,2、3是slave
测试自动切换
server4:
将锁定文件删掉
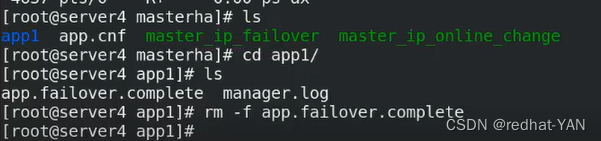


server1:

server2:
之前切换到server1的时候vip被摘取了
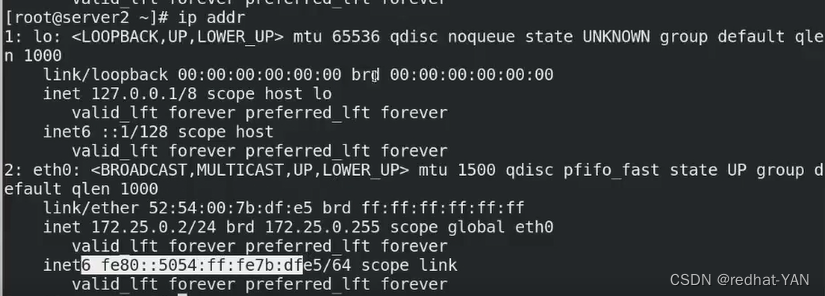
server1:
如果不想看见这些信息,当时的2个文件就不要写成一个文件,global文件也存在就没有这个信息

server4:
进程已经退出了

app1又生成锁定文件,manager.log记录了切换的过程

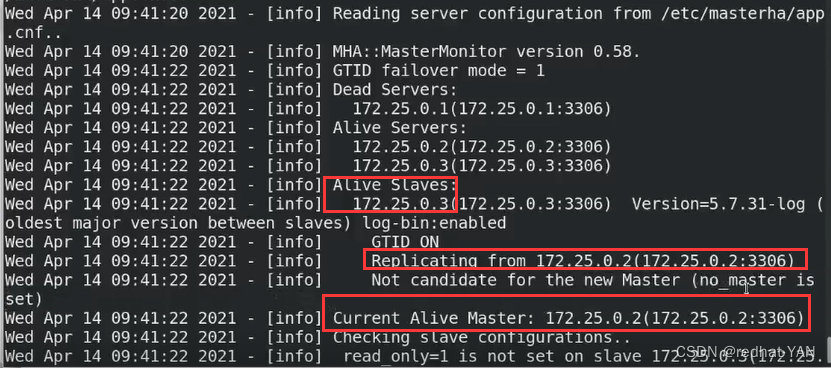
因为0.1已经挂了

也可以看这个

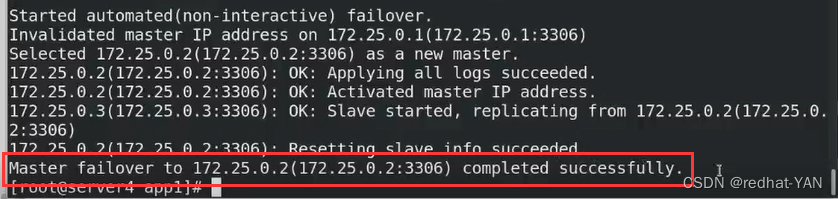
server3:
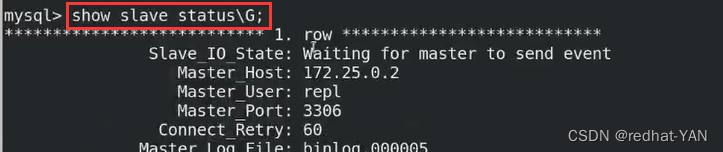
server2:
VIP已经漂移到server2了
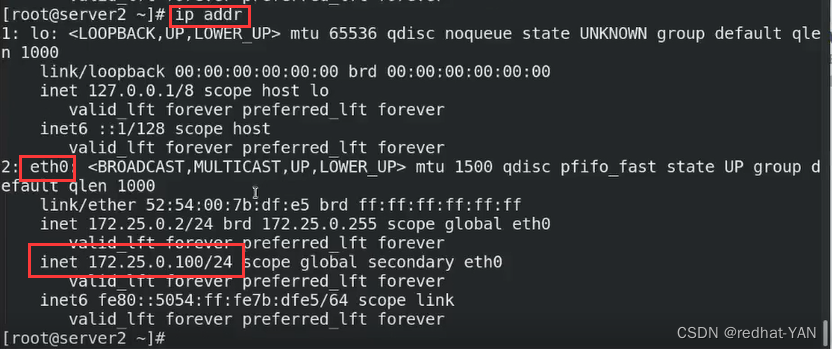
server1:
上面的VIP没有了
宿主机:
客户端是没有反应,是透明的

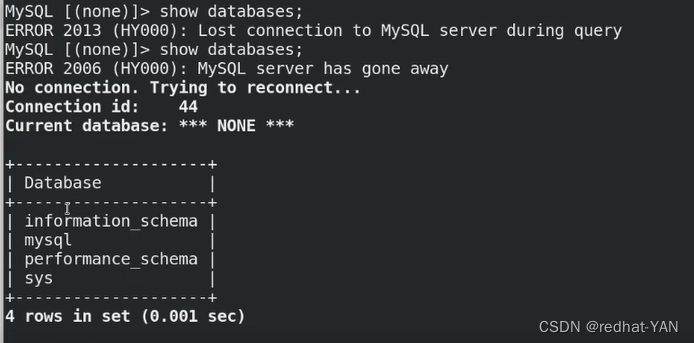
server1:
需要手工恢复加入集群


END















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









