







背景
机翼表面不相容的气动网格和结构网格之间的插值是时域法计算机翼气动弹性的难点之一,网上少有关于并行化动网格的UDF教程,本文展示了在Fluent中采用并行化UDF实现网格变形的代码编写思路以及对应源码,供大家交流学习。
正文
首先插入必要的头文件,包括 Fluent UDF 自带的2个头文件,1个用于矩阵运算的头文件以及4个C语言的头文件。
#include "udf.h"
#include "dynamesh_tools.h"
#include "Matrix.h"
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
#include<string.h>Fluent UDF的核心是DEFINE宏,本文利用DEFINE_GRID_MOTION宏独立移动网格节点,实现机翼的弹性变形。该宏有5个参数,分别为:
- ModeShape:UDF名称
- d: 指向Domian的指针
- dt: 存储动网格信息的结构体指针
- time: 当前时刻
- dtime: 时间步长
DEFINE_GRID_MOTION(AGARD, domain, dt, time, dtime)
{
Thread* t = DT_THREAD(dt);
Node* v;
face_t f;
// 以上为固定格式,建议不做修改,含义参考官方UDF手册
计算节点部分代码
为了提升计算效率,通常以并行模式运行Fluent,气动网格被分割为若干个部分,每个部分由一计算节点(Compute node)执行计算,因此UDF也需要就行并行化处理。
#if !RP_HOST // 仅计算节点编译该部分内容
int n_faces = 0; // 气动网格面数
int nodeindex = 0; // 气动网格节点数
int n = 0, i = 0;对于每个计算节点(包括0节点),循环所有的面(face),再循环面上的所有节点,存储在xftmp数组中,通过 NODE_VISITED flag 确保每个节点只存储一次。
real(*xftmp)[ND_ND]; // 气动网格节点坐标
n_faces = THREAD_N_ELEMENTS_INT(t);
xftmp = (real(*)[ND_ND])malloc(n_faces * ND_ND * sizeof(real));
if (xftmp == NULL)exit(-1);
Clear_Node_Flags(domain, NODE_VISITED_FLAG);
begin_f_loop(f, t)
{
f_node_loop(f, t, n)
{
v = F_NODE(f, t, n);
if (!NODE_IS_VISITED(v))
{
xftmp[nodeindex][0] = NODE_X(v);
xftmp[nodeindex][1] = NODE_Y(v);
xftmp[nodeindex][2] = NODE_Z(v);
nodeindex += 1;
SET_NODE_VISITED(v);
}
}
}
end_f_loop(f, t)接下来需要将各计算节点的网格节点坐标都汇总到一个计算节点(node 0)进行处理,利用Flunet UDF提供的信息传递宏实现。
if (!I_AM_NODE_ZERO_P)
{
PRF_CSEND_INT(node_zero, &nodeindex, 1, myid);
PRF_CSEND_INT(node_zero, &nodeindex, 1, myid);
PRF_CSEND_REAL(node_zero, xftmp[0], nodeindex* ND_ND, myid);
}在计算节点0创建一个用于储存每个计算节点中包含的网格节点数的数组,以及储存总网格节点数的变量。
if (I_AM_NODE_ZERO_P)
{
// 储存每个计算节点的网格节点数
int(*n_nodes_array);
n_nodes_array = (int*)malloc(sizeof(int) * compute_node_count);
// 计算总节点数目
int Total_aero_nodes;
int NodeCount = 0;
Total_aero_nodes = nodeindex;
n_nodes_array[0] = nodeindex;
compute_node_loop_not_zero(n)
{
PRF_CRECV_INT(n, &nodeindex, 1, n);
n_nodes_array[n] = nodeindex;
Total_aero_nodes += nodeindex;
}
首先将计算节点0的坐标信息存储到xf数组中,再接收其他计算节点的信息,并储存在xf中。
// 汇总网格点坐标
real(*xf)[ND_ND];
xf = (real(*)[ND_ND])malloc(ND_ND * Total_aero_nodes * sizeof(real));
if (xf == NULL)exit(-1);
for (i = 0; i < n_nodes_array[0]; i++)
{
xf[NodeCount][0] = xftmp[i][0];
xf[NodeCount][1] = xftmp[i][1];
xf[NodeCount][2] = xftmp[i][2];
NodeCount += 1;
}
compute_node_loop_not_zero(n)
{
PRF_CRECV_INT(n, &nodeindex, 1, n);
PRF_CRECV_REAL(n, xftmp[0], nodeindex * ND_ND, n);
for (i = 0; i < nodeindex; i++)
{
xf[NodeCount][0] = xftmp[i][0];
xf[NodeCount][1] = xftmp[i][1];
xf[NodeCount][2] = xftmp[i][2];
NodeCount += 1;
}
}将xf数组发送到主机(node host)处理。
PRF_CSEND_INT(node_host, &Total_aero_nodes, 1, myid);
PRF_CSEND_REAL(node_host, xf[0], Total_aero_nodes * ND_ND, myid);
free(xf);接下来需要主机计算网格变形(见后文),操作完成后将网格变形量发送回计算0节点。
real* dxf;
real(*FNodeDisp)[ND_ND];
dxf = (real*)malloc(sizeof(real) * Total_aero_nodes * ND_ND);
PRF_CRECV_REAL(node_host, dxf, Total_aero_nodes * ND_ND, node_host);
FNodeDisp = (real(*)[3])malloc(sizeof(real*) * Total_aero_nodes * ND_ND);
for (i = 0; i < Total_aero_nodes; i++)
{
FNodeDisp[i][0] = dxf[i * 3 + 0];
FNodeDisp[i][1] = dxf[i * 3 + 1];
FNodeDisp[i][2] = dxf[i * 3 + 2];
}计算节点0对该节点所包含的网格进行移动。
Clear_Node_Flags(domain, NODE_VISITED_FLAG);
i = 0;
begin_f_loop(f, t)
{
f_node_loop(f, t, n)
{
v = F_NODE(f, t, n);
if (!NODE_IS_VISITED(v))
{
NV_V(NODE_COORD(v),+=,FNodeDisp[i]);
SET_NODE_VISITED(v);
i += 1;
}
}
}
end_f_loop(f, t)计算节点0将其他计算节点的网格位移信息分发给对应节点。
int start, length;
start = n_nodes_array[0];
compute_node_loop_not_zero(n)
{
length = n_nodes_array[n];
PRF_CSEND_REAL(n, FNodeDisp[start], ND_ND*length, node_zero);
start += length;
}务必释放手动分配的内存。
free(dxf);
free(FNodeDisp);
}除0节点外的计算节点接收网格节点位移信息并移动网格节点。
if (!I_AM_NODE_ZERO_P)
{
real(*FNodeDisp)[ND_ND];
FNodeDisp = (real(*)[3])malloc(sizeof(real) * nodeindex * ND_ND);
PRF_CRECV_REAL(node_zero, FNodeDisp[0], nodeindex*ND_ND, node_zero);
i = 0;
Clear_Node_Flags(domain, NODE_VISITED_FLAG); // TODO
begin_f_loop(f, t)
{
f_node_loop(f, t, n)
{
v = F_NODE(f, t, n);
if (!NODE_IS_VISITED(v))
{
NV_V(NODE_COORD(v), +=, FNodeDisp[i]);
SET_NODE_VISITED(v);
i += 1;
}
}
}
end_f_loop(f, t)
free(FNodeDisp);
}
free(xftmp);
#endif主节点部分代码
主节点并不存储网格信息,不执行流场计算,主要用于读取文件以及传递cortex的信息,因此本文将RBF操作放到主节点中。首先定义结构信息需要的矩阵,本文读取了机翼的前5阶模态,选取了53个机翼表面的插值节点。
double(*Gmass); // Generalized mass
double(*Gstif); // Generalized stiffness
double** PhiMat; // Generalized Coordinate (N_i * 3) * N_modes
int N_modes = 5; // Number of selected structural modes
int N_i = 53; // Number of selected interpolation points (from structural grids)
char* linetext;
int i = 0, j = 0;
FILE* fp;
Gmass = (double*)malloc(sizeof(double) * N_modes);
Gstif = (double*)malloc(sizeof(double) * N_modes);
PhiMat = (double**)malloc(sizeof(double*) * N_i * 3);
for (i = 0; i < N_i * 3; i++)
PhiMat[i] = (double*)malloc(sizeof(double) * N_modes);读取文本中存储的结构信息。
// Read Generalized Mass Matrix
linetext = (char*)malloc(sizeof(char) * 100); // Read line width up to 100
fp = fopen("GMassMat.txt", "r");
if (fp == NULL)
{
fprintf(stderr, "Open file failed\n");
exit(EXIT_FAILURE);
}
else
{
j = 0;
while (fgets(linetext, 100, fp) != NULL)
{
sscanf(linetext, "%lf", &Gmass[j]);
j++;
}
}
free(linetext);
linetext = NULL;
// Read Generalized Stiffness Matrix
linetext = (char*)malloc(sizeof(char) * 100);
fp = fopen("GStifMat.txt", "r");
if (fp == NULL)
{
fprintf(stderr, "Open file failed\n");
exit(EXIT_FAILURE);
}
else
{
j = 0;
while (fgets(linetext, 20, fp) != NULL)
{
sscanf(linetext, "%lf", &Gstif[j]);
j++;
}
}
free(linetext);
linetext = NULL;
// Read Generalized Coordinate Matrix
linetext = (char*)malloc(sizeof(char) * 100);
fp = fopen("PhiMat.txt", "r");
if (fp == NULL)
{
fprintf(stderr, "Open file failed\n");
exit(EXIT_FAILURE);
}
else
{
j = 0;
while (fgets(linetext, 100, fp) != NULL)
{
sscanf(linetext, "%lf %lf %lf %lf %lf", &PhiMat[j][0], &PhiMat[j][1], &PhiMat[j][2], &PhiMat[j][3], &PhiMat[j][4]); // TODO!
j++;
}
}
free(linetext);
linetext = NULL;
real(*xi)[ND_ND];
xi = (real(*)[ND_ND])malloc(sizeof(real) * ND_ND * N_i);
linetext = (char*)malloc(sizeof(char) * 100);
fp = fopen("InterPoints.txt", "r");
if (fp == NULL)
{
fprintf(stderr, "Open file failed\n");
exit(EXIT_FAILURE);
}
else
{
j = 0;
while (fgets(linetext, 100, fp) != NULL)
{
sscanf(linetext, "%lf %lf %lf", &xi[j][0], &xi[j][1], &xi[j][2]); // TODO!
j++;
}
}
free(linetext);
linetext = NULL;
Message("Structure info read success!\n");接收Node0发送的网格节点坐标信息
int Total_aero_nodes;
real(*xf)[ND_ND];
PRF_CRECV_INT(node_zero, &Total_aero_nodes, 1, node_zero);
xf = (real(*)[ND_ND])malloc(ND_ND * Total_aero_nodes * sizeof(real));
PRF_CRECV_REAL(node_zero, xf[0], Total_aero_nodes* ND_ND, node_zero);计算插值矩阵,此处需要用到 MatrixOper.h 头文件
real** Afs;
real** Css;
real Radius = 3.0;
real** CssI;
real** H;
Afs = AfsMatrix(xf, xi, Radius);
Css = CssMatrix(xi, Radius);
CssI = Inver(Css);
H = MatMatMultiply(Afs, CssI); // Todo!
Message("Interpolation matrix calculate success!\n");计算插值节点位移
real q0[5] = { 0, 0.01, 0 , 0 , 0 }; // 此处控制使用的模态
real qd0[5] = { 1, 0, 0 , 0 , 0 };
real* dxi;
dxi = (real*)malloc(sizeof(real) * N_i * ND_ND);
for (i = 0; i < N_i * 3; i++)
{
dxi[i] = 0;
for (j = 0; j < N_modes; j++)
{
dxi[i] += PhiMat[i][j] * q0[j];
}
}计算气动节点位移
real* dxf;
dxf = (real*)malloc(sizeof(real) * Total_aero_nodes * ND_ND);
Message("Calculating the fluid nodes displacement, please wait... \n");
for (i = 0; i < Total_aero_nodes; i++)
{
dxf[i * 3 + 0] = 0;
dxf[i * 3 + 1] = 0;
dxf[i * 3 + 2] = 0;
for (j = 0; j < N_i; j++)
{
dxf[i * 3 + 0] += H[i][j + 4] * dxi[j * 3 + 0];
dxf[i * 3 + 1] += H[i][j + 4] * dxi[j * 3 + 1];
dxf[i * 3 + 2] += H[i][j + 4] * dxi[j * 3 + 2];
}
}
Message("Fluid nodes displacement calculation success!\n");将气动节点位移发送至计算节点0并释放使用完毕的内存
PRF_CSEND_REAL(node_zero, dxf, Total_aero_nodes * ND_ND, node_host);
free(xf);
free(dxi);
free(dxf);
#endif
}头文件MatrixOper.h内容
头文件主要包括矩阵乘法、矩阵求逆(来源于网上资源)、RBF插值内容。
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
#include<string.h>
double** Inver(double** src)
{
//step 1
//判断指针是否为空
if (src == NULL)exit(-1);
int i, j, k;
int n;
int col;
int row;
int principal;
double** res, ** res2, tmp;//res为增广矩阵,res为输出的逆矩阵
double Max;
//判断矩阵维数
row = (double)_msize(src) / (double)sizeof(double*);
col = (double)_msize(*src) / (double)sizeof(double);
if (row != col)exit(-1);
//step 2
res = (double**)malloc(sizeof(double*) * row);
res2 = (double**)malloc(sizeof(double*) * row);
n = 2 * row;
for (i = 0; i < row; i++)
{
res[i] = (double*)malloc(sizeof(double) * n);
res2[i] = (double*)malloc(sizeof(double) * col);
memset(res[i], 0, sizeof(res[0][0]) * n);//初始化
memset(res2[i], 0, sizeof(res2[0][0]) * col);
}
//step 3
//进行数据拷贝
for (i = 0; i < row; i++)
{
//此处源代码中的n已改为col,当然方阵的row和col相等,这里用col为了整体逻辑更加清晰
memcpy(res[i], src[i], sizeof(res[0][0]) * col);
}
//将增广矩阵右侧变为单位阵
for (i = 0; i < row; i++)
{
for (j = col; j < n; j++)
{
if (i == (j - row))
res[i][j] = 1.0;
}
}
for (j = 0; j < col; j++)
{
//step 4
//整理增广矩阵,选主元
principal = j;
Max = fabs(res[principal][j]); // 用绝对值比较
// 默认第一行的数最大
// 主元只选主对角线下方
for (i = j; i < row; i++)
{
if (fabs(res[i][j]) > Max)
{
principal = i;
Max = fabs(res[i][j]);
}
}
if (j != principal)
{
for (k = 0; k < n; k++)
{
tmp = res[principal][k];
res[principal][k] = res[j][k];
res[j][k] = tmp;
}
}
//step 5
//将每列其他元素化0
for (i = 0; i < row; i++)
{
if (i == j || res[i][j] == 0)continue;
double b = res[i][j] / res[j][j];
for (k = 0; k < n; k++)
{
res[i][k] += b * res[j][k] * (-1);
}
}
//阶梯处化成1
double a = 1.0 / res[j][j];
for (i = 0; i < n; i++)
{
res[j][i] *= a;
}
}
//step 6
//将逆矩阵部分拷贝到res2中
for (i = 0; i < row; i++)
{
memcpy(res2[i], res[i] + row, sizeof(res[0][0]) * row);
}
//必须释放res内存!
for (i = 0; i < row; i++)
{
free(res[i]);
}
free(res);
return res2;
}
double** AfsMatrix(double xf[][3], double xs[][3], double R0)
{
double** Afs;
int N_f, N_s;
int i, j, k;
// Calculate number of nodes
N_f = (double)_msize(xf) / sizeof(double* [3]);
N_s = (double)_msize(xs) / sizeof(double* [3]);
// Define the Afs Matrix
Afs = (double**)malloc(sizeof(double*) * N_f);
if (Afs == NULL)exit(-1);
for (i = 0; i < N_f; i++)
{
Afs[i] = (double*)malloc(sizeof(double) * (N_s + 4));
if (Afs[i] == NULL)exit(-1);
}
for (i = 0; i < N_f; i++)
{
Afs[i][0] = 1;
Afs[i][1] = xf[i][0];
Afs[i][2] = xf[i][1];
Afs[i][3] = xf[i][2];
for (j = 0; j < N_s; j++)
{
double R = 0;
for (k = 0; k < 3; k++)
R += pow((xf[i][k] - xs[j][k]), 2);
R = sqrt(R);
if (R > R0)
Afs[i][j + 4] = 0;
else
Afs[i][j + 4] = pow((1 - R / R0), 4) * (4 * R / R0 + 1);
}
}
return Afs;
}
double** CssMatrix(double xs[][3], double R0)
{
double** Css;
int N_s;
int i, j, k;
// Calculate number of nodes
N_s = (double)_msize(xs) / sizeof(double* [3]);
// Allocate memory for Css & CssI (Inverse Css Matrix) Matrix
Css = (double**)malloc(sizeof(double*) * (N_s+4));
if (Css == NULL)exit(-1);
else
{
for (i = 0; i < N_s + 4; i++)
{
Css[i] = (double*)malloc(sizeof(double) * (N_s + 4));
if (Css[i] == NULL)exit(-1);
}
}
// Calculate Lower Triangle Css Matrix
// Css[i<=4][j<=4] = 0
for (i = 0; i < 4; i++)
{
for (j = 0; j < i + 1; j++)
Css[i][j] = 0.0;
}
for (i = 4; i < N_s + 4; i++)
{
Css[i][0] = 1;
Css[i][1] = xs[i - 4][0];
Css[i][2] = xs[i - 4][1];
Css[i][3] = xs[i - 4][2];
for (j = 4; j < i + 1; j++)
{
double R = 0;
for (k = 0; k < 3; k++)
R += pow((xs[i-4][k] - xs[j-4][k]), 2);
R = sqrt(R);
if (R > R0)
Css[i][j] = 0;
else
Css[i][j] = pow((1 - R / R0), 4) * (4 * R / R0 + 1);
}
}
// Copy elements from lower half Css to Upper half Css
for (i = 1; i < N_s+4; i++)
for (j = 0; j < i; j++)
Css[j][i] = Css[i][j];
return Css;
}
double** MatMatMultiply(double** A, double** B)
{
double** res;
int rowA, rowB, colA, colB, i, j, k;
double tmp1, tmp2, tmp3;
rowA = (double)_msize(A) / (double)sizeof(double*);
colA = (double)_msize(*A) / (double)sizeof(double);
rowB = (double)_msize(B) / (double)sizeof(double*);
colB = (double)_msize(*B) / (double)sizeof(double);
if (colA != rowB)
{
printf("Fatal error: colA!=rowB");
exit(-1);
}
res = (double**)malloc(sizeof(double*) * rowA);
if (res == NULL)exit(-1);
for (i = 0; i < rowA; i++)
{
res[i] = (double*)malloc(sizeof(double) * colB);
if (res[i] == NULL)exit(-1);
}
for (i = 0; i < rowA; i++)
{
for (j = 0; j < colB; j++)
{
res[i][j] = 0;
for (k = 0; k < colA; k++)
{
tmp1 = A[i][k];
tmp2 = B[k][j];
tmp3 = A[i][k] * B[k][j];
res[i][j] += tmp3;
}
}
}
return res;
}
double* MatVecMultiply(double** A, double* B)
{
double* res;
int rowA, rowB, colA, i, j;
rowA = (double)_msize(A) / (double)sizeof(double*);
colA = (double)_msize(*A) / (double)sizeof(double);
rowB = (double)_msize(B) / (double)sizeof(double);
if (colA != rowB)
{
printf("Fatal error: colA!=rowB");
exit(-1);
}
res = (double*)malloc(sizeof(double) * rowA);
if (res == NULL)exit(-1);
for (i = 0; i < rowA; i++)
{
res[i] = 0;
for (j = 0; j < rowB; j++)
res[i] += A[i][j]*B[j];
}
return res;
}操作说明
1. 在并行模式打开Fluent,读取机翼网格文件,编译UDF(需要配置环境,具体参考网上教程)
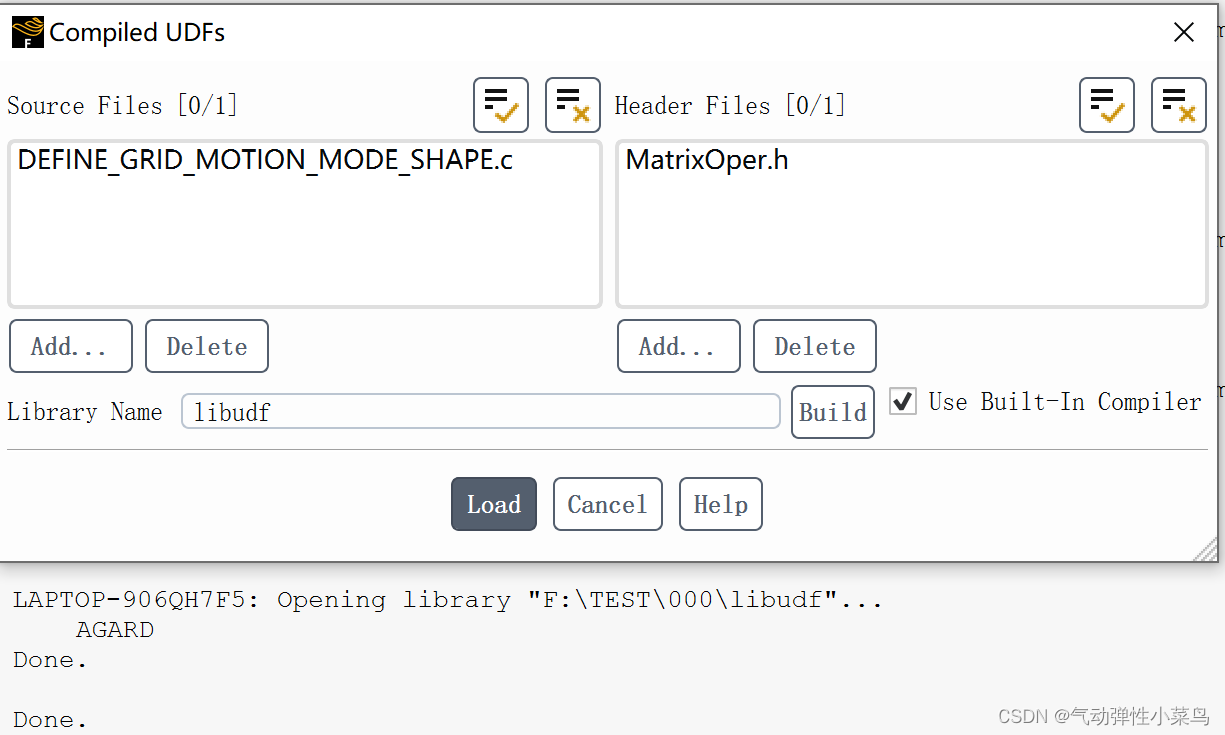
2. 在Dynamic Mesh中创建wall的动网格

3. 点击Display Zone Motion 设置1步

4. 点击 Preview 观察网格变形


可见能够实现网格的光滑连续的变形,成功将结构模态形状插值到气动网格节点,为后续气动弹性计算打下基础。
后记
笔者水平有限,没有C语言基础,编写代码的过程多有不规范的地方,还有很多可以优化的地方,望大家不吝赐教。从3个月前开始接触时域法计算气动弹性响应,才开始探索Fluent UDF,遇到了很多困难,网上能搜索到的学习资料也非常有限,非常感谢大波师兄提供的理论指导以及ccy提供的代码指导。希望研究方向相近的同志多多交流,互相学习!















 4182
4182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









