







GTX 1080/1070虽然性能很强悍,但它们在全新的帕斯卡家族中只能算是中档水准,真正的大杀器是顶级大核心GP100,拥有3840个FP32单精度、1920个FP64双精度CUDA核心,主要面向高性能计算领域。
担任首发的Tesla P100(似乎也叫Tesla P1),只开启了3584个单精度、1792个双精度核心,即便如此单、双精度浮点性能也高达10.6TFlops、5.3TFlops,同时还搭配了4096-bit 16GB HBM2高带宽显存,并支持全新的NVLink互连总线,取代传统PCI-E。

NVIDIA Tesla P100
那么它到底性能如何呢?圣地亚哥超级计算中心的Scott Le GrandRoss Walker、亚马逊网络服务的Scott Le Grand联合编写了一个通用计算测试工具AMBER,可模拟生物分子周围的力场,并与NVIDIA合作对Tesla P100进行了一番测试,包括单路、双路、四路。
由于测试所用硬件还是工程样品,操作系统是Linux,而且测试工具和测试方法是专门为了考察纯粹计算性能而设计的,所以结果反映的只是纯计算能力,和游戏表现无关。
事实上,GP100核心应该永远不会出现在消费级领域,GTX 1080 Ti、GTX Titan X 2之类的顶级卡会使用GP102。
参与对比的产品中,Tesla M40基于麦克斯韦架构大核心GM200,3072个流处理器,单精度性能突破7TFlops,双精度只有0.21TFlops,搭配384-bit 12GB GDDR5显存。
Tesla K80使用的是两个开普勒架构大核心GK210,4992个流处理器,单双精度浮点性能8.74、2.91TFlops,搭配两组384-bit 12GB GDDR5。
Tesla K40的核心是GK110,2880个流处理器,单双精度浮点性能4.29、1.43TFlops,搭配384-bit 12GB GDDR5。
GTX 1080、Titan X、980 Ti、980也都加入了对比,另外还有几颗纯CPU,包括双路的E5-2697 v4/2698 v3/2650 v3,分别有32/32/20个核心。
具体测试原理、流程啥的就不多说了,专业性太强,只简单看看结果:
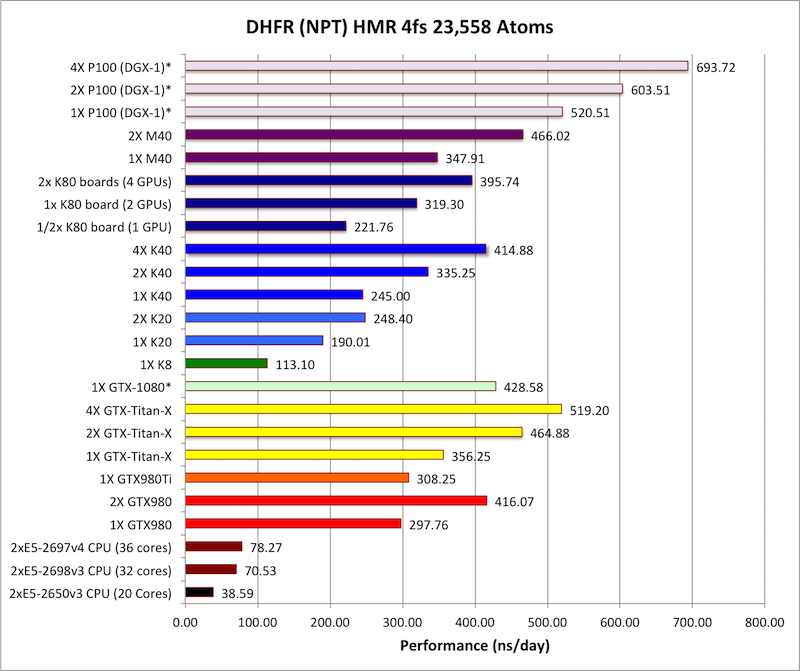

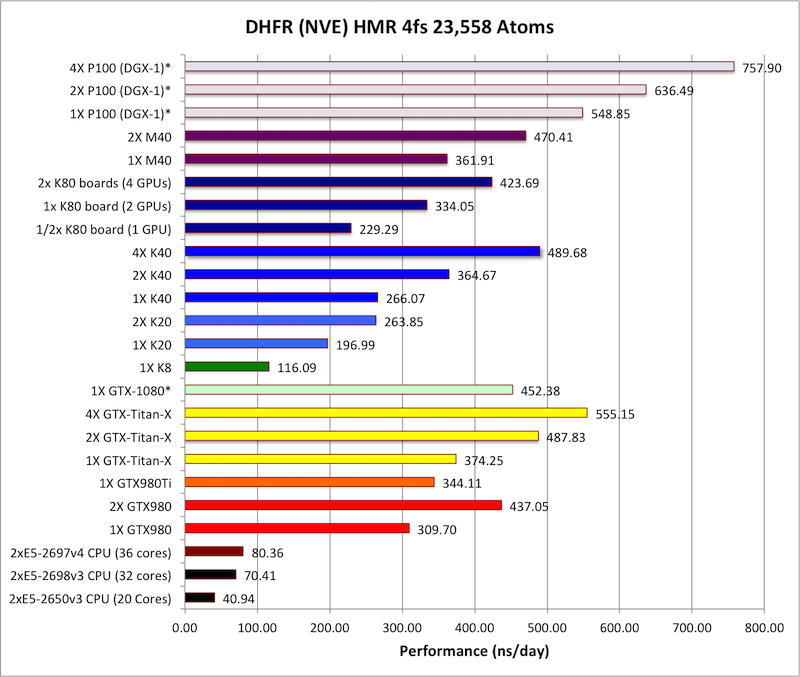

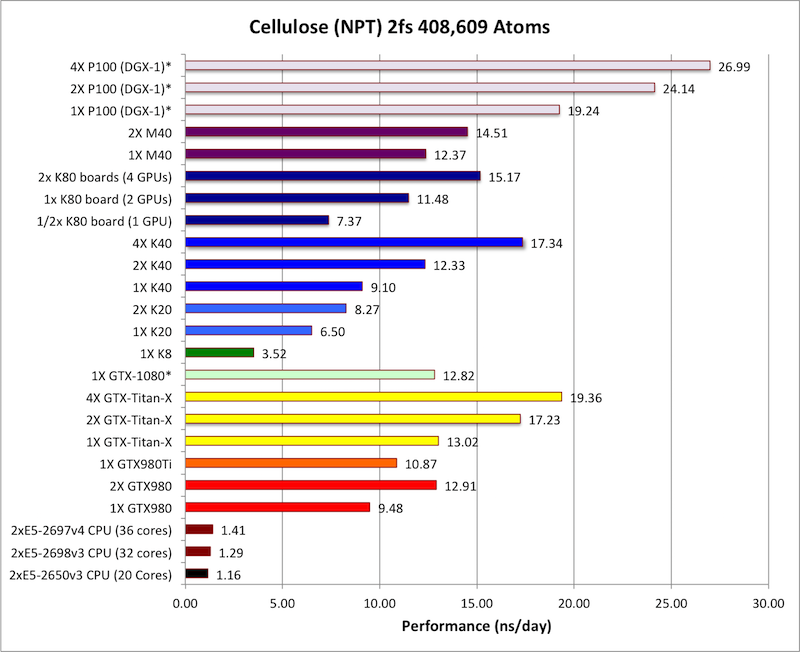



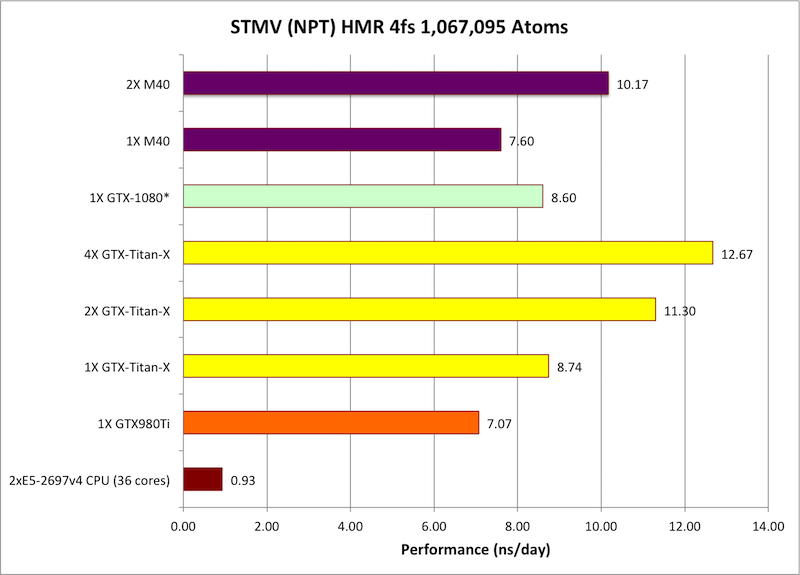


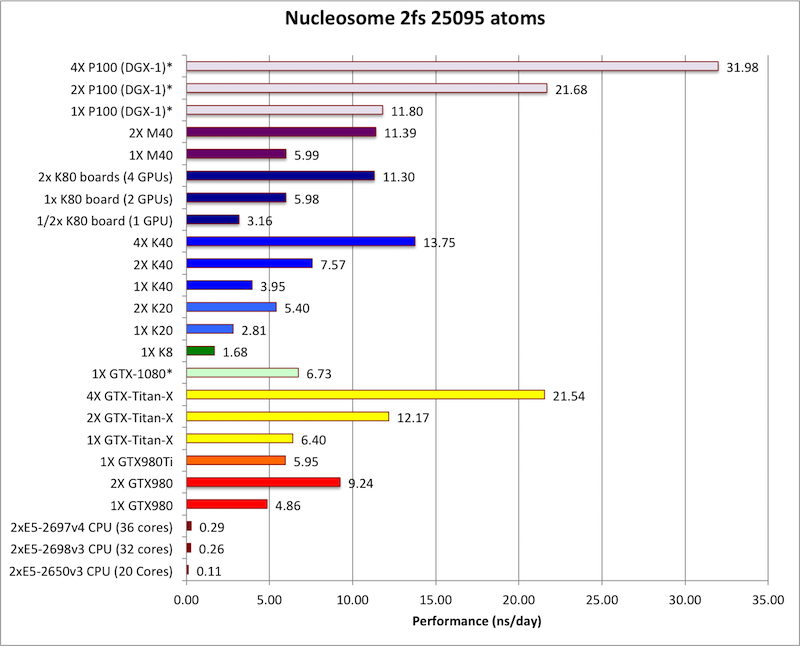
相比于前辈M40,P100的计算性能提升相当猛,绝大部分项目都在50%左右,少数甚至超过80%,有的甚至接近100%!
事实上在大部分时候,单路P100都能干掉双路M40,领先幅度10-20%不等。
对比消费级游戏卡,P100单路已经相当于GTX Titan X四路的水准,也可以看到GTX 1080同样十分凶猛,多数情况下都达到或者接近M40的水平,但不够稳定,有时候相当于单块Titan X,有时候超过人家两块。
最遗憾的是,NV-Link总线的威力还没有发挥出来,双路、四路P100的提升幅度普遍还不如PCI-E。

原文链接
更多推荐
利用人工智能回答员工的重复性问题,Spoke获得2800万美元融资
本文为ATYUN(www.atyun.com)编译作品,ATYUN专注人工智能。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









