







文章目录
一、Huffman编码
首先,编码无非是说给一个数据一个代号。很多编码方式,包括Ascll码都是定长编码(也就是所有不同的数据都具有相同长度的编码),这样方便而且易于存贮管理(???我想应该是这样)。下面只是机械化的介绍一下Haffman编码。
编码动机
当一种类型编码的所有不同数据使用频率都相同时,定长的编码会是最好的选择(这个是可以证明的定理,不是我的猜测)。但是,但是,请注意,人类的世界-----所有种的数据使用频率相同-------的场景应该不多。如果能根据不同数据的频率而给不同的数据不同长度的编码,是不是会节省一些存贮数据的空间?
haffman编码就是基于这样的思想。
编码树
我想解释haffman编码的最好方法应该是直接上手编码。
首先为编码做铺垫的是-----构建编码树,haffman编码树是一棵满二叉树(每个分支节点都有2个子节点)。
上面已经提过,haffman编码动机是不同种数据和它的权重(这里就是指频率),假设我们有一组数据及每种数据对应的频率。所有----数据及其权值----构成一个集合。
构造编码树的过程是:每次从集合中取出权值最小的两个元素组成一个新的元素,它们两个的权值和作为新元素的权值,它们两作为新元素的两个子节点。将新元素放回集合。重复上述过程直至集合大小为1,构建完毕。 这个过程是一个典型的贪心过程。
以ascll码字符为例,假设我们有一组字符,它们频率分别对应如下:
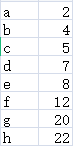
用它们组成下面的集合(画图板绘图,凑活看^&^),其实把里面的每个元素理解为一个只有一个节点的树可能更好,一棵树就是集合的一个元素。
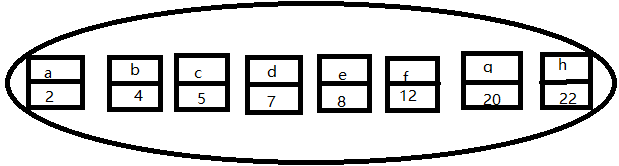
将最小权值的两个节点构成一个新的节点:
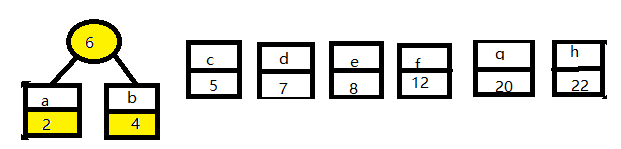
重复上面的过程:

继续重复:

…(此处略过几张图)
直到集合变成这个样子:

此时,集合中只有一棵树(一个元素),编码树构造完成。你会发现我们原始的数据都存在与树的叶子结点。而且,权值越大的数据越靠近根节点。
编码
有了编码树,编码很容易。
把树从根节点开始,到每个叶节点的路径,朝左编号为0,朝右为1,也就是:

然后,我们所有根节点到叶节点的路径就是该叶节点对应的数据的编码:
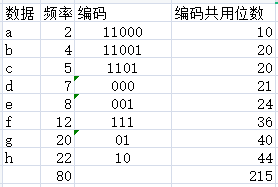
如果原本的编码方式是8位ascll码的话,一共80个字母需要80x8=640位的信息存贮这些字符。而用上面的编码方式,只需要215位就可以存贮原本的80个字符。假如这80个字符中有一个子串为acdghebc,那么由上面每个字符的编码,这个子串最后的编码就是:1100011010000110001110011101,过程如下:
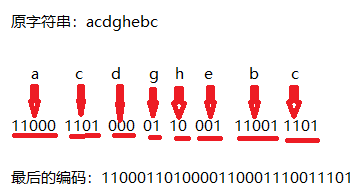
h和g出现的最多,而他们的编码也最短,最后的结果成为了最优的结果(最短的路径和,这个大多数算法书书上有证明),这就是haffman编码或者说贪心思想的妙处。
拿上面的例子来说,由本来需要存贮的640位(80个字节)变成了215位(27字节),以此节省空间,达到压缩的目的(这个说法可能并不完整,后面再补充)。
反编码
容我先讲一个我有时脑子短路的小插曲:
压缩不就是将数据原本的编码变短吗?这有何难,我们把所有的数据按频率排序,然后频率最多的编码为0,次高的编码为1,接着00,01,。。。。这样不好吗?我可以不加证明的说这绝对是任何序列的最短编码方式!如果我只是想过一次就算了,事实上,我傻到了再一次拿起haffman的时候我又想到了这个,我还傻乎乎的嘲笑haffman有什么好的。。。。。
为了提醒我以后不再傻傻的这么想,我还是写明白为好:
数据压缩的目的是为了节省存储空间,但既然是压缩,那么压缩后的数据一般来说会与源序列不同,也就是我们的内容都变了,但我们需要的是原来的内容。
比如我有序列abbccc,按照我脑子短路的想法,a编码00,b为1,c为0,那么这个序列可以编码为00 1 1 0 0 0。压缩的确是压缩了,我有了压缩的序列和编码,可是我怎么得到我原来的据???没了!
所以,想要得到我们原来的内容,要求压缩是说要能通过压缩后的内容还原出原来的内容!!!
呼之欲出的是,通过压缩后的内容和编码还原出原来的内容,haffman编码当然可以做到!
以编码时的例子来说,我最后得到的序列是:1100011010000110001110011101,每个字符的编码是: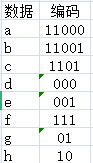
再看上面编码时的这张图片:
从编码生成序列的左边开始,1没有对应的编码字符,11,110,1100都没有,而到11000,他是字符a的编码,还原出了a。继续这个过程,就可以还原出所有原来字符。也就是,解码的过程中完全能将上面的箭头转向。(这时再回去看我上面的那个想法,就明白了为什么说那种方式还原不出原来的内容)
这个序列会不会只是个巧合?不是的。
上面的反编译过程之所以能成功,是因为在任意一次的序列探查中探查出这部分编码对应的正确的原字符之前,绝不会探查出其他的字符。标准的说法是:任意一个编码都不是另一个编码的前缀。也称这个编码组合符合前缀特性(我不懂为什么明明不是前缀,却叫了个前缀特性)。
而haffman编码就符合前缀特性:因为只有叶节点存储数据,很明显任何一个叶节点不会是根节点到其他叶节点路径上的节点(这句话本身就证明了它本身)。所以,haffman编码后的序列一定能通过编码表还原出原来的序列。 同时也指出对于haffman压缩来说,码表也是压缩后内容的一部分。
存在的问题
拿我上面编码的例子来说,原本80个字节,变成了27个字节,哪怕再加上码表,也还能称得上是“压缩”。但实际中一般并不采用haffman压缩。因为它的压缩率受原序列内容的影响特别大。
举一个我能说清楚的直观的例子:8位ascll码对应了256种不同的数据,那么我现在有一个序列包含256种数据各n个,通过haffman压缩的结果是什么呢?构建编码树的过程中很快就会发现最终得出的编码,每种数据编码仍然有8位。这样来说,即使不付码表,能压缩成的内容已经和原来的内容长度一模一样了,何况还需付码表。与压缩节省空间的初衷南辕北辙。
实际上,无需所有字符频率相等,只要频率最多的不超过频率最少的2倍,haffman压缩后的序列就与原序列长度几乎无异。(这个是算法导论上的证明题,这里还有一个更有趣的证明题:如果原序列中不同种数据的出现是完全随机的,那么没有任何一种压缩方法可以将这个序列压缩哪怕是一位)
这里我还有一个问题就是它压缩后的内容(编码序列部分,不包括码表)可以和原序列长度相同,那会不会长度比原序列更长呢?
到这里,Haffman压缩的所有内容我就大概说完了。
&&&我实现时遇到的一个问题,感觉很有趣,写在这里&&&
如果我需要一个n层的haffman树,我至少需要的数据规模是多少?(其实我的问题原本是,现在我的文件一共有x个字节,我最多需要多少位来保存haffman编码?)
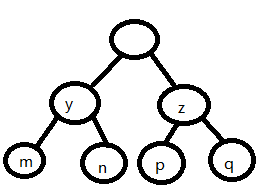
要搭建起有这样部分的haffman树,就要求y>=max(p,q);z>=max(m,n)。也就是满足这个条件才能搭起这个框架。现在为构建最高的haffman树,把z的孩子都拿掉,也就是只需要满足z>=max(m,n)就可以了,然后从最少频率 、最底层处起往上构建会得到下图所示的树:

此时从下往上观察叶子结点的权值1,1,2,3,5,8,13.。。。没错,这是一个缺了第一项的斐波那契数列。斐波那契数列以指数级增长,树的高度为65时,根节点的右子节点的权值为10T多,这1个数据就已经相当庞大了。(上面的处理是完全的z>max(m,n),但要满足最小的情况(可以=)的结构叶节点序列也仅仅是后移了1位的斐波那契数列)。
话虽这么说,但是实现过程中我发现几乎大部分文件最后生成的每种字节的编码最长也只有十几位。
二、Java实现
我在很久之前就接触过haffman编码,它的思想、编码、解码和压缩原理,但现在动手实现时,还是出了很多问题。事实打脸:脑子想的都白想,绝知此事要躬行。我的代码比较乱,看的话光看注释会好一点。 所有的代码我都嵌套在文章里了,就不单独贴了。
文件读写
简单说下数据读写(文件读写只是其中很小的分支):
1.要读取或者写入的是字符,就用Reader或者Writer的子类,他们都是针对字符做过优化的。
以Reader为例:
Writer和Reader几乎差不多。
2.如果要处理原始的字节,那么就应该用Stream(读是InputStream,写是OutputStream)。
InputStream:
(还好多。。。)OutputStream也差不多。
上面的两种方式都有可选的缓冲包装类 Buffered----,这些类的内部封装了一个缓冲区,可以使不用每一次的读写都需要实际从磁盘读写,减少时间和消耗。(BufferedReader的API里指明说可以用BufferedReader包装所有可能开销很大的Reader,如FileReader。这里我简单测量比较了下用BufferedInputStream包装起来的FileInputStream和不包装单独的FileInputStream,用两者写相同大小的字节数组到文件,规模到256MB时所用时间也还是相差甚微,其他的没试过,但我想既然缓冲的机制也是创建数组,那么如果我们直接写入的就是数组,应该就能和缓冲达到同样的目的?)
需要进行的是文件读写,所以需要关注文件读写的相关类。
要提的还有DataInputStream/DataOutputStream,这个类允许我们可以从流中读取Java进本数据类型,如int,long等。
3.还有一个可读可写文件的类是RandomAcessFile,它支持在文件的任意处读取和写入(上面的两种方式一定程度上也支持到达文件的任意处,但是是弱支持,我理解为很鸡肋)。
具体其他的细节和类边用边看。。。
大部分文件应该都是字节码文件,而且就算字符它本身也是字节,利用Stream也可以处理它。其实主要还是考虑到生成的过程是以‘位’为单位的,也就是说并没有字符的概念,所以写压缩文件好的选择应该是Stream。为了统一,读写文件都用Stream。
压缩
压缩框架
1.这里我想在一定范围限制每次读写文件的大小(试图想人为的减少下运行时内从的占用),所以用到了bs数组来进行每次读入时的存放,needDevide是每次读入的最大字节数。
2.因为统计词频会读一次文件,按照我上面将文件分成小段的做法,重新编码时又要读取一次文件,我选择第二次重新打开流,而不是读写机制里提供的标记位置功能。
//压缩文件的后缀(只是在源文件的文件名后面添加后缀
public final String zipSniff=".wjl_hfm";
//当要压缩的文件字节数多于这个数时,读取文件时,每次读取needDevide bytes
private int needDevide=1<<25;
private Long fileLength; //文件字节数
private String filePath; //文件名
FileInputStream fis; //文件输入流
FileOutputStream fos; //文件输出流
byte[] bs; //每次读取的字节数组
public LongCodeHFM(String filePath)
{
this.filePath=filePath;
}
//压缩
public void compress() throws IOException
{
//源文件
File src=new File(filePath);
fis=new FileInputStream(src);
// 压缩后的文件,文件名为原文件名加后缀,写入方式为追加
fos=new FileOutputStream(new File(filePath+zipSniff));
fileLength=src.length();
// System.out.println(fileLength);
if(fileLength==0)return; //文件为空不压缩
//统计词频
long b=System.currentTimeMillis(),startTime=b;
needDevide=(int) Math.min(needDevide,fileLength);
bs=new byte[needDevide];
//文件中的所有byte及其对应的频率,byte只有256种不同值
int []freqs=new int[256];
census(freqs);
b=System.currentTimeMillis();
System.out.println("统计词频耗时"+(b-startTime));
fis.close();
//通过频率数组得到编码
getHFMCode(freqs);
long c=System.currentTimeMillis();
System.out.println("编码耗时"+(c-b));
writeCodeInfo(); //写入编码相关信息
fis=new FileInputStream(src); //重新读取文件
readZipWrite(); //读取源文件,重新编码(压缩),写入压缩文件。
System.out.println("写压缩文件耗时"+(System.currentTimeMillis()-c));
}
读写文件类的选取
很明显,我们可以一定长度的数组为单位读如源文件内容;而写压缩文件之前,可以得到所有要写入的信息并将他们用字节数组的形式保存起来,然后将数组直接写入文件。按照我之前的想法,对于字节数组的读取/写入来说,用不用Buffered应该区别不大,所以我读写文件都选择不用Buffered来包装。也就是直接用文件读写流:

统计字频
所有的字节只有256中,所以词频的存放不用HashMap而是用数组(这种由byte直接映射数组下标本来就是一个简单的hash,而且比hashMap好用且省时),需要注意的是一个byte不能以(int)byteb进行强制转型,这样会扩展符号位,正确的做法直接按位与0xff,得到的int的低8位就是原来的byte,后面也还有类似的问题。
private void census(int []freqs)
{
int start=0,num=0;
while(start<fileLength)
{
//fis会从接着上一次读的开始读
try {num=fis.read(bs);}
catch (IOException e) {e.printStackTrace();}
for(int i=0;i<num;i++)
freqs[bs[i]&0xff]++;
start+=num;
}
}
建立编码树,生成编码
这个方法的参数是频率数组。
private void getHFMCode(int []freqs)
节点类我区分了分支节点和叶子结点,所有节点本身都保存了节点的编码和节点的高度(实际上就是有效编码的长度)
abstract class Node
{
int weight; //节点权值
int height; //节点的高度,根节点为0
long code; //节点编码
}
//叶子节点,保存数据的节点
class Leaf extends Node
{
byte value;
Leaf(byte Value,int Weight)
{
value=Value;
weight=Weight;
}
}
class Branch extends Node //分支节点,有两个子节点
{
Branch(Node left, Node right)
{
this.left = left;
this.right = right;
this.weight=left.weight+right.weight;
}
Node left,right;
}
然后把每种byte和其频率构成叶子结点组成集合:
//所有组合放入栈中
Stack<Node> all=new Stack<>();
int index;
for(int i=0;i<256;i++)
{
index=0xff&(byte)i;
// System.out.println((byte)i+" "+index);
if(freqs[index]!=0)all.add(new Leaf((byte)i,freqs[index]));
}
构建编码树
需要注意的是原始只有一个节点时要特殊处理:
if(all.size()==1) //只有一种字节,给这个字节编码为1(或0)都行
{
Leaf temp=(Leaf)all.pop();
index=0xff&temp.value;
codesLen[index]=1;
codes[index]=1;
return;
}
因为每次选取集合中权值最小的两个,然后组合后重新放回集合,我的想法是利用一个排序好的栈,每次弹出栈顶两个组合后重新插回。
//先将整个栈中的字符按其权值排序,栈顶是小的一端
all.sort(new Comparator<Node>()
{
@Override
public int compare(Node o1, Node o2)
{
return o1.weight>o2.weight?-1:(o1.weight<o2.weight?1:0);
}
});
//在构建树的阶段只需要权重,根节点一定是个分支节点
Branch root=null;
while(true)
{
//弹出栈中最小的两个节点,并构建新节点
Node temp1=all.pop(),temp2=all.pop();
Branch newMinNode=new Branch(temp1,temp2);
//当弹出后栈为空,说明所有节点构建完成了根节点,结束循环
if(all.size()==0)
{
root=newMinNode;
break;
}
int newIndex=all.size();
//否则,利用插入排序将新的节点插回到栈中的正确位置
Node temp;
while(true)
{
temp=all.elementAt(newIndex-1);
if(temp.weight>newMinNode.weight)
break;
newIndex--;
if(newIndex==0)break;
}
all.add(newIndex, newMinNode);
}
生成每种字节的编码
我们能操纵的最小数据单位是byte,而编码和解码的过程需要操作bit,无论是每个字节的编码,还是最后合成的序列编码,都不一定能构成完整的byte,到底选用什么数据类型保存每种字节的编码和序列编码就需要考虑了。
一种方式是用二进制String来保存每种字节的编码,同样的用String来存放序列的编码(因为序列编码需要不断地增长,选择StringBuilder会好一些),最后的把每种字节的编码二进制串、序列二进制串转换为byte数组(长度不足的就补0)然后写入压缩文件。解压缩时,将这些byte数组读出后再转换为二进制串处理。
不过我处理时使用了long来暂存每种字节的编码和序列编码。用String的话运行时每个0或1都需要占用一个字节的运行时空间,而用long可以用bit来保存这些01,节省一下运行时内存消耗。(主要是没有更多位的数据类型可以用了,BitSet不支持左右移而且它也是用long实现的)(当然这可能是我自作聪明)。
将每种byte对应的编码保存在一个long值的低位。此时考虑类似于“1”和“01”这样的编码,放进long后,他们就没有区别了(都仅仅是1)。所以我用了一个数组零时记录每种byte的编码位数。
也就是:(这两个数组保存在类里,生成编码源文件时要用)
//字节编码的hash表,因为在编码时需要,且要将它写入到文件,所以作为类字段。
private long[] codes=new long[256];
//每个编码的有效长度
private int[] codesLen=new int[256];

然后填充这两个数组。过程就是从根节点往下,利用二叉树的任意一种遍历方式,得到所有叶子结点的编码及其长度并保存。将每个分支节点的编码左移1位,它的左子节点的编码就是再在后面补个‘0’(左移就可以完成),右子节点需要补‘1’。
//用层次遍历将所有的字节和对应的HFMcode
LinkedList<Node> ll=new LinkedList<>();
root.height=0; //节点高度等同于每个节点的编码长度
ll.push(root);
Node temp,tl,tr;
Branch tb;
Leaf tLeaf;
while(!ll.isEmpty())
{
temp=ll.pop();
if(temp instanceof Branch) //如果是分支节点就将它的两个子节点放入队列
{
tb=(Branch)temp;
tl=tb.left;tr=tb.right;
tl.code=temp.code<<1;
tl.height=tb.height+1;
tr.code=(temp.code<<1)|1;
tr.height=tb.height+1;
ll.push(tl);
ll.push(tr);
}
else if(temp instanceof Leaf)
{
tLeaf=(Leaf)temp;
index=0xff&tLeaf.value;
codes[index]=tLeaf.code;
codesLen[index]=temp.height;
// System.out.print(" "+tLeaf.value);
}
// System.out.println();
}
生成压缩文件
将编码信息写入压缩文件:
private void writeCodeInfo()
前面已经说过,原来的序列编码后不一定能刚好占满一个byte,所以需要处理下后面的无效编码。可以直接将源文件长度写入压缩文件头部,解压时反编码出源文件长度的字节后就停止。故所有编码信息就包括:源文件字节数(8字节)、源文件字节种类数(1字节)、每种字节的编码信息(包括编码所用bit位数;有效编码的那部分字节;字节本身)
private void writeCodeInfo() throws IOException
{
int byteKinds=-1; //用[0,255]表示[1,256]种字符
int allBytesCodeNum=0; //统计所有字节的有效编码一共占了多少个字节
int codeUseBytes[]=new int[256]; //每个编码用到的有效字节数目,最多为8字节
for(int i=0;i<256;i++)
if(codesLen[i]!=0)
{
byteKinds++;
codeUseBytes[i]=(codesLen[i]%8==0?(codesLen[i]/8):(codesLen[i]/8+1));
allBytesCodeNum+=codeUseBytes[i];
}
byte []bys=new byte[11+2*byteKinds+allBytesCodeNum];
for(int i=0;i<8;i++) //写入原文件总共的字节数目,一个long值
bys[7-i]=(byte)(fileLength>>(8*i));
bys[8]=((byte)byteKinds); //写入字节种类
// System.out.println(fileLength+" "+((0xff&byteKinds)+1)+" 0");
int index=8,temp;
for(int i=0;i<256;i++)
if(codesLen[i]!=0)
{
//对于某个字节,写入信息的顺序是:编码有效位数-编码的codeUseBytes[i]个字节-该字节
bys[++index]=(byte)codesLen[i]; //该种字节编码所用位数
index+=codeUseBytes[i];
temp=index;
for(int j=0;j<codeUseBytes[i];j++)
bys[temp--]=(byte)(codes[i]>>(8*j));
bys[++index]=(byte)i; //字节本身
}
// for(int i=0;i<bys.length;i++)System.out.print(bys[i]+" ");
// System.out.println();
fos.write(bys);
}
编码源文件:
还是用long来组合编码,画个简单的示意图。
就是说从long的高位开始填充下一个字节对应的编码,然后接着下一个。如果放不下下一个字节的编码,那么就先放它的一部分,然后用下一个long的高位再保存剩余的部分(如下图黄色部分示意)。把这些编码源文件的long先保存,积攒一定量后,转为byte数组写入压缩文件(DataOutput类可以直接写入long,但它只能一个一个写入,与其再加缓冲类,还不如我自己转byte数组)。

//一边读一边根据编码压缩后写入
private void readZipWrite() throws IOException
{
long temp=0; //用来存贮连接后编码
int emptyBits=64; //temp中右边的未填充位数
byte []bys; //用于缓冲的byte数组
//下面的变量只在while循环中用到
int start=0,num=0;
int index,cha;
//用al暂存所有编码形成的long,假设编码后的序列和原序列所用bit长度相同
ArrayList<Long> al=new ArrayList<>(needDevide/8);
// System.out.println(fileLength);
while(start<fileLength)
{
//bis会从接着上一次读的开始读
try {num=fis.read(bs);}
catch (IOException e) {e.printStackTrace();}
// System.out.println(num);
for(int i=0;i<num;i++)
{
index=bs[i]&0xff;
cha=emptyBits-codesLen[index];
if(cha>0) //temp中空位可以容纳该字节的编码且还有剩余
{
temp=temp|(codes[index]<<cha);
emptyBits=cha;
}
else if(cha==0)//刚好容纳,没有剩余
{
al.add(temp|codes[index]);
temp=0;
emptyBits=64;
}
else //容纳不下
{
//先把code的前empty位放到temp里,并且将temp放进容器
al.add(temp|(codes[index]>>(-cha)));
emptyBits=64+cha;
temp=codes[index]<<emptyBits;
}
} //temp暂时不能动,因为它里面可能还包含了编码
long temp2;
bys=new byte[al.size()*8];
for(int i=0;i<al.size();i++)
{
temp2=al.get(i);
// System.out.println(Long.toBinaryString(temp2));
for(int j=0;j<8;j++)
{
bys[8*i+7-j]=(byte)(temp2>>(8*j));
// System.out.print(bys[8*i+7-j]+" ");
}
// System.out.println();
}
fos.write(bys);
start+=num;
al.clear();
}
bys=new byte[8];
//将temp整个都写入压缩文件,虽然有些位没有用到,但全部写入方便解压缩时读取
for(int i=0;i<8;i++)
bys[7-i]=(byte)(temp>>(8*i));
// for(int i=0;i<bys.length;i++)System.out.print(bys[i]+" ");
// System.out.println();
fos.write(bys);
fos.close();
fis.close();
}
解压缩
解压缩框架
private Long fileLength; //文件长度
private String filePath;
//压缩文件的后缀,只有有这个后缀才能解压缩
public final String zipSniff=".wjl_hfm";
private int needDevide=1<<25;
public DecodeHFM(String filePath)
{
this.filePath=filePath;
}
BufferedInputStream bfis; //文件的缓冲输入
DataInputStream dbfis; //这个需要用到文件缓冲
FileOutputStream fos; //文件输出流
public void uncompress()
{
File zipFile=new File(FileCompression.userDir+filePath);
if(!filePath.endsWith(zipSniff)||
!zipFile.exists()||
zipFile.length()==0)return;
String unCompfilePath=FileCompression.userDir+"un"+filePath.substring(0,filePath.lastIndexOf('.'));
File unFile=new File(unCompfilePath);
try {
bfis=new BufferedInputStream(new FileInputStream(zipFile));
dbfis=new DataInputStream(bfis);
fos=new FileOutputStream(unFile);
long b=System.currentTimeMillis();
readCodeInfo(); //编码信息
readUnzipWrite(); //解压
fos.close();
dbfis.close();
System.out.println("解压耗时:"+(System.currentTimeMillis()-b));
} catch (IOException e) {e.printStackTrace();}
}
读写文件类的选取
其实依旧可以选择只用文件输入输出流。读的时候读出所有的字节数组,反编译出所有的原文件(压缩前的文件)字节数组然后一下直接写入。但我这里读取文件选了用BufferedInputStream包装FileInputSream,然后再传给DataOutputStream。

读取、存贮编码信息
编码信息就是压缩时写入的源文件字节数(8字节)、源文件字节种类数(1字节)、每种字节的编码信息(包括编码所用bit位数;有效编码的那部分字节;字节本身)。
现在要做的是根据每种字节的编码,然后把一个长的编码序列还原,也就是需要【编码=》字节】的映射,这个时候我能想到的最好的选择只能是用Hash表存贮编码。key值是编码,value是对应的字节。
还用long来存贮编码,但是现在再考虑“01”和“1”这样的编码,给它额外定义有效编码长度这个属性就有点麻烦了,所以给它的有效编码的前一位置1,这样就可以区别他们了,也就是编码变成了“101”和“11”,反编码序列时对应再做些处理就可以了。
//用一个hashMap存贮编码信息,编码长度最多63位,最高位置1
HashMap<Long,Byte> codes;
//从压缩文件头部读取文件压缩时写入的压缩信息
private void readCodeInfo() throws IOException
{
codes=new HashMap<>();
fileLength=dbfis.readLong(); //读取源文件的文件字节数
int byteKind=(0xff&dbfis.readByte())+1;//源文件中的字节种类数
// System.out.println(fileLength+" "+byteKind);
int codeUseBytes,codeLen;
long code;
for(int i=0;i<byteKind;i++)
{
codeLen=0xff&dbfis.readByte(); //该字节所用编码位数
codeUseBytes=(codeLen%8==0?(codeLen/8):(codeLen/8+1)); //该字节所用编码字节数
code=0;
for(int j=1;j<=codeUseBytes;j++)
code=code|(((long)(dbfis.readByte()&0xff))<<(8*(codeUseBytes-j)));
// System.out.print(code+" "+codeLen);
code=code|(1<<codeLen); //将有效编码的前1位置1,防止hash表将数值相同的编码给同化掉,比如01,1
codes.put(code,dbfis.readByte());
// System.out.println(Long.toBinaryString(code)+" "+codes.get(code));
}
// System.out.println(codes);
}
(保存编码依旧可以选择用字符串,然后反编码序列时也用字符串处理)
解码生成解压文件
有了上面的的解码规则,以及利用编码时long的方法,解码很容易。
每次从文件中读取一个long(用BufferedInputStream包装FileInputStream来缓冲的原因)。解码的过程就是从左边开始1bit,2bit,…把它们移到低位上,查找我们的码表中没有这样的编码(要在前面补个1,因为我们的编码前面多个1),这个过程好像有点麻烦,但是用字符串我也没想到能好到哪去。
1bit:
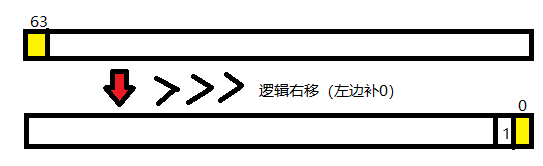
然后2bit:
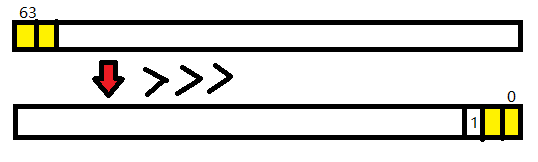
注意是逻辑右移,就是左边补0。
。。。直到找到一个编码。
一开始这个long中未处理位数restBits为64,找到一个n bit的编码后就把restBits减n。很明显,这个long最后可能有一部分编码并不完整,存放在了下一个long中,只要稍加变动就可以了,如下图。

private void readUnzipWrite() throws IOException
{
needDevide=(int) Math.min(needDevide, fileLength);
byte []bs=new byte[needDevide]; //缓冲大小
long temp1,temp2=0;
long unZipedBytes=0; //用来表示一共解码出的字节,当等于原文件大小时,解压结束
int bsIndex=0; //bs中当前解压的字节数
int restBits=0; //读取的一个long中未处理的位数
long code;
int i,j,k;
while(dbfis.available()>=8)
{
temp1=dbfis.readLong();
// System.out.println(Long.toBinaryString(temp1));
//temp2的低restbits中保存上一次未处理的位
if(restBits!=0) //上一次读取的long里有剩余未处理的
{
for(i=63,j=1;i>0;i--,j++)
{
code=((temp2<<j)|(temp1>>>i))|(1<<(restBits+j));
// System.out.print(Long.toBinaryString(code)+" ");
if(codes.containsKey(code))
{
bs[bsIndex++]=codes.get(code);
// System.out.println(bs[bsIndex-1]);
temp1=(temp1<<j)>>>j;
restBits=i;
unZipedBytes++;
temp2=0;
if(unZipedBytes==fileLength)
{
fos.write(bs,0,bsIndex);
return;
}
else if(bsIndex==needDevide)
{
fos.write(bs);
bsIndex=0;
}
break;
}
}
// System.out.println();
}
else restBits=64;
// System.out.println(Long.toBinaryString(temp1));
for(i=restBits-1,k=1;i>=0;i--,k++)
{
code=((temp1>>>i)|(1<<k));
// System.out.print(Long.toBinaryString(code)+" ");
if(codes.containsKey(code))
{
bs[bsIndex++]=codes.get(code);
// System.out.println(bs[bsIndex-1]);
j=64-i;
temp1=(temp1<<j)>>>j;
k=0;
restBits=i;
unZipedBytes++;
if(unZipedBytes==fileLength)
{
fos.write(bs,0,bsIndex);
return;
}
else if(bsIndex==needDevide)
{
fos.write(bs);
bsIndex=0;
}
}
}
// System.out.println();
if(restBits!=0)temp2=temp1; //保存
}
}
压缩效果测试
暴力对比下源文件与解压后文件内容:
//用字节流通过一个字节一个字节判断两个文件内容是否相等
public static boolean fileContentEqual(String fn1,String fn2) throws IOException
{
File f1=new File(userDir+fn1);
File f2=new File(userDir+fn2);
long len1=f1.length(),len2=f2.length();
if(len1!=len2)return false;
FileInputStream fis1,fis2;
fis1=new FileInputStream(f1);
fis2=new FileInputStream(f2);
byte []bs1=new byte[(int)len1];
byte []bs2=new byte[(int)len2];
fis1.read(bs1);
fis2.read(bs2);
for(int i=0;i<len1;i++)
if(bs1[i]!=bs2[i])return false;
fis1.close();
fis2.close();
return true;
}
比较的是源文件和解压后的文件,我图片中所示的代码输出写错了😅
几种不同文件的压缩效果:
英文文本:(几乎只有这个勉强能说是压缩)

字母加少量汉字文本:

mp3文件:

docx文件:

ppt
其实通过上面的简单测试更能体会到haffman压缩的压缩能力限制了。
时间也是慢的不可恭维,我拿它试图压缩和解压一个200多MB的小电影时,时间长的我一度以为程序出了bug进入了死循环。 ,不过这个主要是我实现上的问题,解压那部分花了大部分时间,感觉就是因为一个一个读取long造成的(或者还有可能是频繁的重复的移位操作?)不过怎么说慢的问题是很容易可以改善的。
呼~~~~终于写完了。














 3110
3110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









