







Slope One 是一系列应用于 协同过滤的算法的统称。由 Daniel Lemire和Anna Maclachlan于2005年发表的论文中提出。 [1]有争议的是,该算法堪称基于项目评价的non-trivial 协同过滤算法最简洁的形式。该系列算法的简洁特性使它们的实现简单而高效,而且其精确度与其它复杂费时的算法相比也不相上下。 [2]. 该系列算法也被用来改进其它算法。[3][4].
目录
[隐藏]
协同过滤简介及其主要优缺点[编辑]
协同过滤推荐(Collaborative Filtering recommendation)是在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
与传统文本过滤相比,协同过滤有下列优点:
1 能够过滤难以进行机器自动基于内容分析的信息。如艺术品、音乐;
2 能够基于一些复杂的,难以表达的概念(信息质量、品位)进行过滤;
3 推荐的新颖性。
尽管协同过滤技术在个性化推荐系统中获得了极大的成功,但随着站点结构、内容的复杂度和用户人数的不断增加,协同过滤技术的一些缺点逐渐暴露出来。
主要有以下三点:
1 稀疏性(sparsity):在许多推荐系统中,每个用户涉及的信息量相当有限,在一些大的系统如亚马逊网站中,用户最多不过就评估了上百万本书的1%~2%。造成评估矩阵数据相当稀疏,难以找到相似用户集,导致推荐效果大大降低。
2 扩展性(scalability):“最近邻居”算法的计算量随着用户和项的增加而大大增加,对于上百万之巨的数目,通常的算法将遭遇到严重的扩展性问题。
3 精确性(accuracy):通过寻找相近用户来产生推荐集,在数量较大的情况下,推荐的可信度随之降低。
Item-based协同过滤 和 过适[编辑]
当可以对一些项目评分的时候,比如人们可以对一些东西给出1到5星的评价的时候,协同过滤意图基于一个个体过去对某些项目的评分和(庞大的)由其他用户的评价构成的数据库,来预测该用户对未评价项目的评分。 例如: 如果一个人给披头士的评分为5(总分5)的话,我们能否预测他对席琳狄翁新专辑的评分呢?
这种情形下, item-based 协同过滤系统[5][6] 根据其它项目的评分来预测某项目的分值,一般方法为 线性回归 (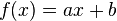 ). 于是,需要列出x^2个线性回归方程和2x^2个回归量,例如:当有1000个项目时,需要列多达1,000,000个线性回归方程, 以及多达2,000,000个回归量。除非我们只选择某些用户共同评价过的项目对,否则协同过滤会遇到过适[2](过拟合) 问题。
). 于是,需要列出x^2个线性回归方程和2x^2个回归量,例如:当有1000个项目时,需要列多达1,000,000个线性回归方程, 以及多达2,000,000个回归量。除非我们只选择某些用户共同评价过的项目对,否则协同过滤会遇到过适[2](过拟合) 问题。
另外一种更好的方法是使用更简单一些的式子,比如  :实验证明当使用一半的回归量的时候,该式子(称为Slope One)的表现有时优于[2] 线性回归方程。该简化方法也不需要那么多存储空间和延迟。
:实验证明当使用一半的回归量的时候,该式子(称为Slope One)的表现有时优于[2] 线性回归方程。该简化方法也不需要那么多存储空间和延迟。
Item-based 协同过滤只是 协同过滤的一种形式.其它还有像 user-based 协同过滤一样研究用户间的联系的过滤系统。但是,考虑到其他用户数量庞大,item-based协同过滤更可行一些。
电子商务中的Item-based协同过滤[编辑]
人们并不总是能给出评分,当用户只提供二进制数据(购买与否)的时候,就无法应用Slope One 和其它基于评分的算法。 二进制 item-based协同过滤应用的例子之一就是Amazon的 item-to-item 专利算法[7] ,该算法中用二进制向量表示用户-项目购买关系的矩阵,并计算二进制向量间的cosine相关系数。
有人认为Item-to-Item 算法甚至比Slope One 还简单,例如:
| 顾客 | 项目 1 | 项目 2 | 项目 3 |
|---|---|---|---|
| John | 买过 | 没买过 | 买过 |
| Mark | 没买过 | 买过 | 买过 |
| Lucy | 没买过 | 买过 | 没买过 |
在本例当中,项目1和项目2间的cosine相关系数为:
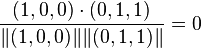 ,
,
项目1和项目3间的cosine相关系数为:
 ,
,
而项目2和项目3的cosine相关系数为:
 .
.
于是,浏览项目1的顾客会被推荐买项目3(两者相关系数最大),而浏览项目2的顾客会被推荐买项目3,浏览了项目3的会首先被推荐买项目1(再然后是项目2,因为2和3的相关系数小于1和3)。该模型只使用了每对项目间的一个参数(cosine相关系数)来产生推荐。因此,如果有n个项目,则需要计算和存储 n(n-1)/2 个cosine相关系数。
Slope One 协同过滤[编辑]
为了大大减少过适(过拟合)的发生,提升算法简化实现, Slope One 系列易实现的Item-based协同过滤算法被提了出来。本质上,该方法运用更简单形式的回归表达式() 和单一的自由参数,而不是一个项目评分和另一个项目评分间的线性回归 ()。 该自由参数只不过就是两个项目评分间的平均差值。甚至在某些实例当中,它比线性回归的方法更准确[2],而且该算法只需要一半(甚至更少)的存储量。

例:
- User A 对 Item I 评分为1 对Item J.评分为1.5
- User B 对 Item I 评分为2.
- 你认为 User B 会给 Item J 打几分?
- Slope One 的答案是:2.5 (1.5-1+2=2.5).
举个更实际的例子,考虑下表:
| 顾客 | 项目 1 | 项目 2 | 项目 3 |
|---|---|---|---|
| John | 5 | 3 | 2 |
| Mark | 3 | 4 | 未评分 |
| Lucy | 未评分 | 2 | 5 |
在本例中,项目2和1之间的平均评分差值为 (2+(-1))/2=0.5. 因此,item1的评分平均比item2高0.5。同样的,项目3和1之间的平均评分差值为3。因此,如果我们试图根据Lucy 对项目2的评分来预测她对项目1的评分的时候,我们可以得到 2+0.5 = 2.5。同样,如果我们想要根据她对项目3的评分来预测她对项目1的评分的话,我们得到 5+3=8.
如果一个用户已经评价了一些项目,可以这样做出预测:简单地把各个项目的预测通过加权平均值结合起来。当用户两个项目都评价过的时候,权值就高。在上面的例子中,项目1和项目2都评价了的用户数为2,项目1和项目3 都评价了的用户数为1,因此权重分别为2和1. 我们可以这样预测Lucy对项目1的评价:
 于是,对“n”个项目,想要实现 Slope One,只需要计算并存储“n”对评分间的平均差值和评价数目即可。
于是,对“n”个项目,想要实现 Slope One,只需要计算并存储“n”对评分间的平均差值和评价数目即可。
Slope One 的java/c#实现[编辑]
java实现
package test;
import java.util.*;
/**
* Daniel Lemire A simple implementation of the weighted slope one algorithm in * Java for item-based collaborative filtering. Assumes Java 1.5. * * See main function for example. * * June 1st 2006. Revised by Marco Ponzi on March 29th 2007 */
public class SlopeOne {
public static void main(String args[]) {
// this is my data base
Map<UserId, Map<ItemId, Float>> data = new HashMap<UserId, Map<ItemId, Float>>();
// items
ItemId item1 = new ItemId(" candy");
ItemId item2 = new ItemId(" dog");
ItemId item3 = new ItemId(" cat");
ItemId item4 = new ItemId(" war");
ItemId item5 = new ItemId("strange food");
mAllItems = new ItemId[] { item1, item2, item3, item4, item5 };
// I'm going to fill it in
HashMap<ItemId, Float> user1 = new HashMap<ItemId, Float>();
HashMap<ItemId, Float> user2 = new HashMap<ItemId, Float>();
HashMap<ItemId, Float> user3 = new HashMap<ItemId, Float>();
HashMap<ItemId, Float> user4 = new HashMap<ItemId, Float>();
user1.put(item1, 1.0f);
user1.put(item2, 0.5f);
user1.put(item4, 0.1f);
data.put(new UserId("Bob"), user1);
user2.put(item1, 1.0f);
user2.put(item3, 0.5f);
user2.put(item4, 0.2f);
data.put(new UserId("Jane"), user2);
user3.put(item1, 0.9f);
user3.put(item2, 0.4f);
user3.put(item3, 0.5f);
user3.put(item4, 0.1f);
data.put(new UserId("Jo"), user3);
user4.put(item1, 0.1f);
// user4.put(item2,0.4f);
// user4.put(item3,0.5f);
user4.put(item4, 1.0f);
user4.put(item5, 0.4f);
data.put(new UserId("StrangeJo"), user4);
// next, I create my predictor engine
SlopeOne so = new SlopeOne(data);
System.out.println("Here's the data I have accumulated...");
so.printData();
// then, I'm going to test it out...
HashMap<ItemId, Float> user = new HashMap<ItemId, Float>();
System.out.println("Ok, now we predict...");
user.put(item5, 0.4f);
System.out.println("Inputting...");
SlopeOne.print(user);
System.out.println("Getting...");
SlopeOne.print(so.predict(user));
//
user.put(item4, 0.2f);
System.out.println("Inputting...");
SlopeOne.print(user);
System.out.println("Getting...");
SlopeOne.print(so.predict(user));
}
Map<UserId, Map<ItemId, Float>> mData; Map<ItemId, Map<ItemId, Float>> mDiffMatrix; Map<ItemId, Map<ItemId, Integer>> mFreqMatrix;
static ItemId[] mAllItems;
public SlopeOne(Map<UserId, Map<ItemId, Float>> data) {
mData = data;
buildDiffMatrix();
}
/**
* Based on existing data, and using weights, try to predict all missing
* ratings. The trick to make this more scalable is to consider only
* mDiffMatrix entries having a large (>1) mFreqMatrix entry.
*
* It will output the prediction 0 when no prediction is possible.
*/
public Map<ItemId, Float> predict(Map<ItemId, Float> user) {
HashMap<ItemId, Float> predictions = new HashMap<ItemId, Float>();
HashMap<ItemId, Integer> frequencies = new HashMap<ItemId, Integer>();
for (ItemId j : mDiffMatrix.keySet()) {
frequencies.put(j, 0);
predictions.put(j, 0.0f);
}
for (ItemId j : user.keySet()) {
for (ItemId k : mDiffMatrix.keySet()) {
try {
float newval = (mDiffMatrix.get(k).get(j).floatValue() + user.get(j)
.floatValue()) * mFreqMatrix.get(k).get(j).intValue();
predictions.put(k, predictions.get(k) + newval);
frequencies.put(k, frequencies.get(k)
+ mFreqMatrix.get(k).get(j).intValue());
} catch (NullPointerException e) {
}
}
}
HashMap<ItemId, Float> cleanpredictions = new HashMap<ItemId, Float>();
for (ItemId j : predictions.keySet()) {
if (frequencies.get(j) > 0) {
cleanpredictions.put(j, predictions.get(j).floatValue()
/ frequencies.get(j).intValue());
}
}
for (ItemId j : user.keySet()) {
cleanpredictions.put(j, user.get(j));
}
return cleanpredictions;
}
/**
* Based on existing data, and not using weights, try to predict all missing
* ratings. The trick to make this more scalable is to consider only
* mDiffMatrix entries having a large (>1) mFreqMatrix entry.
*/
public Map<ItemId, Float> weightlesspredict(Map<ItemId, Float> user) {
HashMap<ItemId, Float> predictions = new HashMap<ItemId, Float>();
HashMap<ItemId, Integer> frequencies = new HashMap<ItemId, Integer>();
for (ItemId j : mDiffMatrix.keySet()) {
predictions.put(j, 0.0f);
frequencies.put(j, 0);
}
for (ItemId j : user.keySet()) {
for (ItemId k : mDiffMatrix.keySet()) {
// System.out.println("Average diff between "+j+" and "+ k +
// " is "+mDiffMatrix.get(k).get(j).floatValue()+" with n ="+mFreqMatrix.get(k).get(j).floatValue());
float newval = (mDiffMatrix.get(k).get(j).floatValue() + user.get(j)
.floatValue());
predictions.put(k, predictions.get(k) + newval);
}
}
for (ItemId j : predictions.keySet()) {
predictions.put(j, predictions.get(j).floatValue() / user.size());
}
for (ItemId j : user.keySet()) {
predictions.put(j, user.get(j));
}
return predictions;
}
public void printData() {
for (UserId user : mData.keySet()) {
System.out.println(user);
print(mData.get(user));
}
for (int i = 0; i < mAllItems.length; i++) {
System.out.print("\n" + mAllItems[i] + ":");
printMatrixes(mDiffMatrix.get(mAllItems[i]),
mFreqMatrix.get(mAllItems[i]));
}
}
private void printMatrixes(Map<ItemId, Float> ratings,
Map<ItemId, Integer> frequencies) {
for (int j = 0; j < mAllItems.length; j++) {
System.out.format("%10.3f", ratings.get(mAllItems[j]));
System.out.print(" ");
System.out.format("%10d", frequencies.get(mAllItems[j]));
}
System.out.println();
}
public static void print(Map<ItemId, Float> user) {
for (ItemId j : user.keySet()) {
System.out.println(" " + j + " --> " + user.get(j).floatValue());
}
}
public void buildDiffMatrix() {
mDiffMatrix = new HashMap<ItemId, Map<ItemId, Float>>();
mFreqMatrix = new HashMap<ItemId, Map<ItemId, Integer>>();
// first iterate through users
for (Map<ItemId, Float> user : mData.values()) {
// then iterate through user data
for (Map.Entry<ItemId, Float> entry : user.entrySet()) {
if (!mDiffMatrix.containsKey(entry.getKey())) {
mDiffMatrix.put(entry.getKey(), new HashMap<ItemId, Float>());
mFreqMatrix.put(entry.getKey(), new HashMap<ItemId, Integer>());
}
for (Map.Entry<ItemId, Float> entry2 : user.entrySet()) {
int oldcount = 0;
if (mFreqMatrix.get(entry.getKey()).containsKey(entry2.getKey()))
oldcount = mFreqMatrix.get(entry.getKey()).get(entry2.getKey())
.intValue();
float olddiff = 0.0f;
if (mDiffMatrix.get(entry.getKey()).containsKey(entry2.getKey()))
olddiff = mDiffMatrix.get(entry.getKey()).get(entry2.getKey())
.floatValue();
float observeddiff = entry.getValue() - entry2.getValue();
mFreqMatrix.get(entry.getKey()).put(entry2.getKey(), oldcount + 1);
mDiffMatrix.get(entry.getKey()).put(entry2.getKey(),
olddiff + observeddiff);
}
}
}
for (ItemId j : mDiffMatrix.keySet()) {
for (ItemId i : mDiffMatrix.get(j).keySet()) {
float oldvalue = mDiffMatrix.get(j).get(i).floatValue();
int count = mFreqMatrix.get(j).get(i).intValue();
mDiffMatrix.get(j).put(i, oldvalue / count);
}
}
}
}
class UserId {
String content;
public UserId(String s) {
content = s;
}
public int hashCode() {
return content.hashCode();
}
public String toString() {
return content;
}
}
class ItemId {
String content;
public ItemId(String s) {
content = s;
}
public int hashCode() {
return content.hashCode();
}
public String toString() {
return content;
}
}
C#实现: using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace SlopeOne {
public class Rating
{
public float Value { get; set; }
public int Freq { get; set; }
public float AverageValue
{
get { return Value / Freq; }
}
}
public class RatingDifferenceCollection : Dictionary<string, Rating>
{
private string GetKey(int Item1Id, int Item2Id)
{
return (Item1Id < Item2Id) ? Item1Id "/" Item2Id : Item2Id "/" Item1Id ;
}
public bool Contains(int Item1Id, int Item2Id)
{
return this.Keys.Contains<string>(GetKey(Item1Id, Item2Id));
}
public Rating this[int Item1Id, int Item2Id]
{
get {
return this[this.GetKey(Item1Id, Item2Id)];
}
set { this[this.GetKey(Item1Id, Item2Id)] = value; }
}
}
public class SlopeOne
{
public RatingDifferenceCollection _DiffMarix = new RatingDifferenceCollection(); // The dictionary to keep the diff matrix
public HashSet<int> _Items = new HashSet<int>(); // Tracking how many items totally
public void AddUserRatings(IDictionary<int, float> userRatings)
{
foreach (var item1 in userRatings)
{
int item1Id = item1.Key;
float item1Rating = item1.Value;
_Items.Add(item1.Key);
foreach (var item2 in userRatings)
{
if (item2.Key <= item1Id) continue; // Eliminate redundancy
int item2Id = item2.Key;
float item2Rating = item2.Value;
Rating ratingDiff;
if (_DiffMarix.Contains(item1Id, item2Id))
{
ratingDiff = _DiffMarix[item1Id, item2Id];
}
else
{
ratingDiff = new Rating();
_DiffMarix[item1Id, item2Id] = ratingDiff;
}
ratingDiff.Value = item1Rating - item2Rating;
ratingDiff.Freq = 1;
}
}
}
// Input ratings of all users
public void AddUerRatings(IList<IDictionary<int, float>> Ratings)
{
foreach(var userRatings in Ratings)
{
AddUserRatings(userRatings);
}
}
public IDictionary<int, float> Predict(IDictionary<int, float> userRatings)
{
Dictionary<int, float> Predictions = new Dictionary<int, float>();
foreach (var itemId in this._Items)
{
if (userRatings.Keys.Contains(itemId)) continue; // User has rated this item, just skip it
Rating itemRating = new Rating();
foreach (var userRating in userRatings)
{
if (userRating.Key == itemId) continue;
int inputItemId = userRating.Key;
if (_DiffMarix.Contains(itemId, inputItemId))
{
Rating diff = _DiffMarix[itemId, inputItemId];
itemRating.Value = diff.Freq * (userRating.Value diff.AverageValue * ((itemId < inputItemId) ? 1 : -1));
itemRating.Freq = diff.Freq;
}
}
Predictions.Add(itemId, itemRating.AverageValue);
}
return Predictions;
}
public static void Test()
{
SlopeOne test = new SlopeOne();
Dictionary<int, float> userRating = new Dictionary<int, float>();
userRating.Add(1, 5);
userRating.Add(2, 4);
userRating.Add(3, 4);
test.AddUserRatings(userRating);
userRating = new Dictionary<int, float>();
userRating.Add(1, 4);
userRating.Add(2, 5);
userRating.Add(3, 3);
userRating.Add(4, 5);
test.AddUserRatings(userRating);
userRating = new Dictionary<int, float>();
userRating.Add(1, 4);
userRating.Add(2, 4);
userRating.Add(4, 5);
test.AddUserRatings(userRating);
userRating = new Dictionary<int, float>();
userRating.Add(1, 5);
userRating.Add(3, 4);
IDictionary<int, float> Predictions = test.Predict(userRating);
foreach (var rating in Predictions)
{
Console.WriteLine("Item " rating.Key " Rating: " rating.Value);
}
}
}
}
Slope One 的算法复杂度[编辑]
设有“n”个项目,“m”个用户,“N”个评分。计算每对评分之间的差值需要n(n-1)/2 单位的存储空间,最多需要 m n2步. 计算量也有可能挺悲观的:假设用户已经评价了最多 y 个项目, 那么计算不超过n2+my2个项目间计算差值是可能的。 . 如果一个用户已经评价过“x”个项目,预测单一的项目评分需要“x“步,而对其所有未评分项目做出评分预测需要最多 (n-x)x 步. 当一个用户已经评价过“x”个项目时,当该用户新增一个评价时,更新数据库需要 x步.
可以通过分割数据(参照分割和稀疏存储(没有共同评价项目的用户可以被忽略)来降低存储要求,
应用Slope One的推荐系统[编辑]
- hitflip DVD推荐系统
- How Happy
- inDiscover MP3推荐系统
- RACOFI Composer
- Value Investing News 股票新闻网站
- AllTheBests 购物推荐引擎
脚注[编辑]
- ^ Slope One Predictors for Online Rating-Based Collaborative Filtering
- ^ 2.0 2.1 2.2 2.3 Daniel Lemire, Anna Maclachlan, Slope One Predictors for Online Rating-Based Collaborative Filtering, In SIAM Data Mining (SDM'05), Newport Beach, California, April 21-23, 2005.
- ^ Pu Wang, HongWu Ye, A Personalized Recommendation Algorithm Combining Slope One Scheme and User Based Collaborative Filtering, IIS '09, 2009.
- ^ DeJia Zhang, An Item-based Collaborative Filtering Recommendation Algorithm Using Slope One Scheme Smoothing, ISECS '09, 2009.
- ^ Slobodan Vucetic, Zoran Obradovic: Collaborative Filtering Using a Regression-Based Approach. Knowl. Inf. Syst. 7(1): 1-22 (2005)
- ^ Badrul M. Sarwar, George Karypis, Joseph A. Konstan, John Riedl: Item-based collaborative filtering recommendation algorithms. WWW 2001: 285-295
- ^ Greg Linden, Brent Smith, Jeremy York, "Amazon.com Recommendations: Item-to-Item Collaborative Filtering," IEEE Internet Computing, vol. 07, no. 1, pp. 76-80, Jan/Feb, 2003
- 转自















 2294
2294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









