






参考文献
Slope One Predictors for Online Rating-Based Collaborative Filtering
其是一种推荐算法,属于Rating-based collaborative filtering领域,即是预测某个user对于某个给定的item的评分,本质上是一种协同过滤算法。该算法易于实现,可以实时动态更新,响应快,给出的结果也足够好,可适用于冷启动用户,方便部署。Slope one算法可以直译为斜率为一,因据其作者认为,该算法可以近似用f(x)=x+b这个函数式来表示。具体如何,下面分解。
该算法的motivation是基于商品的’popularity differential’,即商品间受欢迎度的差异,念来十分拗口,但想法十分朴素。

如上图所示,来做个小学数学题,试想有商品ItemI,ItemJ,User A对二者的评分分别是1,1.5,已知User B 对ItemI 的评分是2,试预测UserB 对ItemJ的评分,那么我们可以这么认为,商品间受欢迎的差异从某种程度上是固定的,打个不恰当的比方,所有人都更喜欢美女,而相较而言不那么喜欢长相奇怪的,但不同人间是有差异的,某男A资深直男癌,眼光比较高,对林志玲评分为3,村东头的翠花评分为1,某男B死肥宅,是个女的都可以接受,对村东头的翠花评分都到了3,对林志玲更是疯狂打出了5分的最高分,那么注意了现在,男A和男B的喜好眼光都是不同的,但对于林志玲和翠花的打分的分数的差却是一样的,3-1=5-3,都更喜欢林志玲而不是翠花,喜欢的程度差是一定的,这就是slope one算法的精髓,据这样的思考方式,很容易就能求出UserB 对ItemJ的评分2+(1.5-1)=2.5
理解了上面那个例子就相当于理解了slope one算法的全部,剩下的就是据此朴素想法上的一些修补而产生的一些变体。
接着来比较一下slope one算法跟其它算法,试看看相对优劣。
1 Per user average: 在预测一个对新item的评分时,将用户过去对所有item的评分加以平均,简单粗暴,效果随缘。
2bias from mean
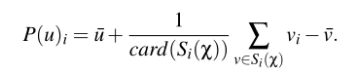
P(u)i是用户u对商品i的评分,Si(X)是有对i作过评分的用户的集合,vi是用户v对商品i的评分,其余两个上面带一横的分别是用户u,v以往做过的评分的均值,card简单来说就是其内集合的元素项的个数,整体式子不难理解,含义就是bias from mean
3adjusted cosine item-based
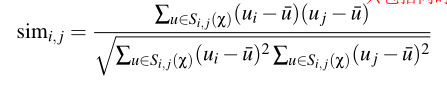
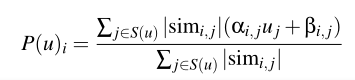
整个式子看上去较为复杂,我们一步一步来看,Si,j(X)是有对i,j都作过评分的用户的集合,其它符号与上面是一样的含义,simi,j整体是计算商品i,j间的相似度,根据这相似度的不同衡量方式可以衍生出不同的算法,然后第二个式子的P(u)i即用户u对商品i的评分便可以根据该用户对其它商品的评分进行参考(根据商品间的相似度作为权重)计算,当然两商品间越相似,用户对两商品的评分也越相似。Alpha,Belta在这里就当做某种校正因子不必深究。
4the pearson reference scheme
该算法属于memory-based,简单来说就是很耗内存,lazy learning,事先不做或很少做准备,等开始使用的时候才从内存(已经存了大量数据)中提出一堆数据开始计算并返回结果。
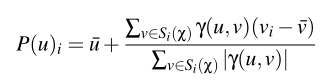
式子又比较复杂,慢慢来看,Gamma(u,v)其实就是用户u,v间的相似度,所以这其实就是在上面bias from mean算法的基础上引入用户间的相似度作为权重而已
5the slope one
终于到了我们的主角出场,
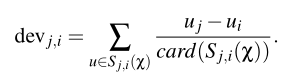
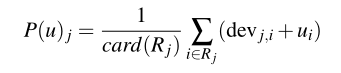
呃,跟我们上面的朴素想法不同,这式子看着也挺复杂的,慢慢来看,devj,i就是我们前面说过的不同商品i,j间受欢迎度的差异,第一个式子就是简单的对不同人取个均值,第二个式子就是简单的对不同物再取个均值,最后得到的p(u)j就是用户u对商品j的评分,果然是一个朴素的想法
6the weighted slope one scheme
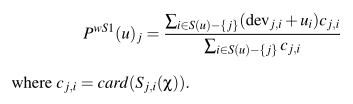
这就是slope one的一个变体,如其名所示,就是多考虑了下某方面的权重,那么这个权重究竟是哪方面的?从式子来看,就是那个cj,i,那么这个cj,i是什么?是card(Sj,i(x)),Sj,i(x)是什么,上面已经说过,其是有对i,j都作过评分的用户的集合,card(Sj,i(x))就是对i,j都作过评分的用户的个数,通常来说,若更多的人对某商品i,j对都作过评分,其相应的统计均值更接近均衡,更可靠,所以相应的权重更高也容易理解。
7the bi-polar slope one scheme

这又是对slope one的另一个变体,对比本体,我们发现,dev部分就是在左上角多了个like,对应的,这里应该还有个dislike,这里略去,领会精神,知道还存在对应的另一个就好。其实好好看上面的式子,会发现,其实这个式子的各个组成部分在上面算法的介绍中都出现过。这里只要详细介绍下Slikej,i(X)就好,Sj,i(X)表示是有对i,j都作过评分的用户的集合,Slikej,i(X)其实就是有对i,j都作过评分,而且都表示喜欢商品i,j的用户的集合,dislike与此相反,不必赘述。那么什么叫用户表示喜欢某商品呢,其实就是对某商品的评分高于其对以往所有商品评分的均值,毕竟这世界同时存在着直男癌和死肥宅,直男癌对所有商品评分都低,死肥宅对所有商品评分都高,只有取他们自己评分的均值才能知道到底什么才是他们的真爱。接下来我们来分析下为什么这么做。我们发现,对比Sj,i(X),Slikej,i(X)和Sdislikej,i(X)对集合中的元素有更严格的定义,如果有某对商品i,j,某用户a表示喜欢i却不喜欢j,则Slikej,i(X)和Sdislikej,i(X)中都将不包含某用户a这个元素,跟Sj,i(X)相比,则对应的这条信息记录就从此在式子里消失不见了,不再参与最后p(u)的计算,第一直觉是,有些数据不见了,那么根据大数据时代的基本定律,数据即石油,该算法应该是比本体slope one更差才对,但结果是更好,为什么呢?其实本质是这里做了个过滤,某用户a喜欢i却不喜欢j,与同时喜欢i,j或同时不喜欢i,j的人本质就不是同类型的人,我们预测评分,用协同过滤,要做参考当然是参考同类型的人比较好,那些不同类型的人带入的数据其实只带来了干扰,过滤掉他们当然就带来更好的效果,所以大数据时代的数据即石油,应该修正为质量高的数据才为石油更好些。

最后是各个算法间预测的比较,上面那个数值越低越好。可以看到,pearson预测性能表现也不错,但论对内存的消耗,响应速度,对冷启动用户的支持,slope one类型的算法就胜过太多了。















 681
681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









