






1.Tesseract-OCR引擎简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
2.Tesseract-OCR的下载安装
google下载地址:http://code.google.com/p/tesseract-ocr
需要下载安装程序(tesseract-ocr-setup-3.02.02.exe)和语言库,默认有英文的语言库只能识别英文,所以还需要下载中文语言库,
由于google经常打不开,所以通过代理下载后,上传到了CSDN,
安装程序下载地址:http://download.csdn.net/detail/whatday/7740469
简体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740531
繁体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740429
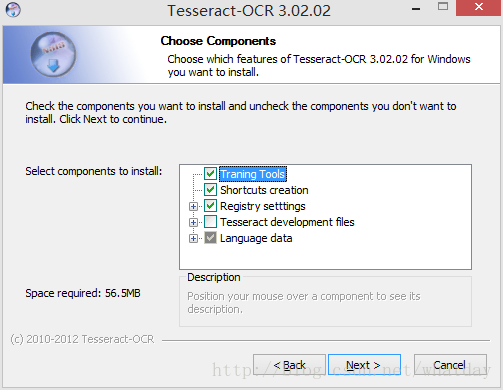
因为如果选择了其他项,安装程序会自动从网上下载,语言库和其他文件,有很大一部分是从google下载,由于不能打开所以会出错,先默认安装上,需要什么文件再下载就行。
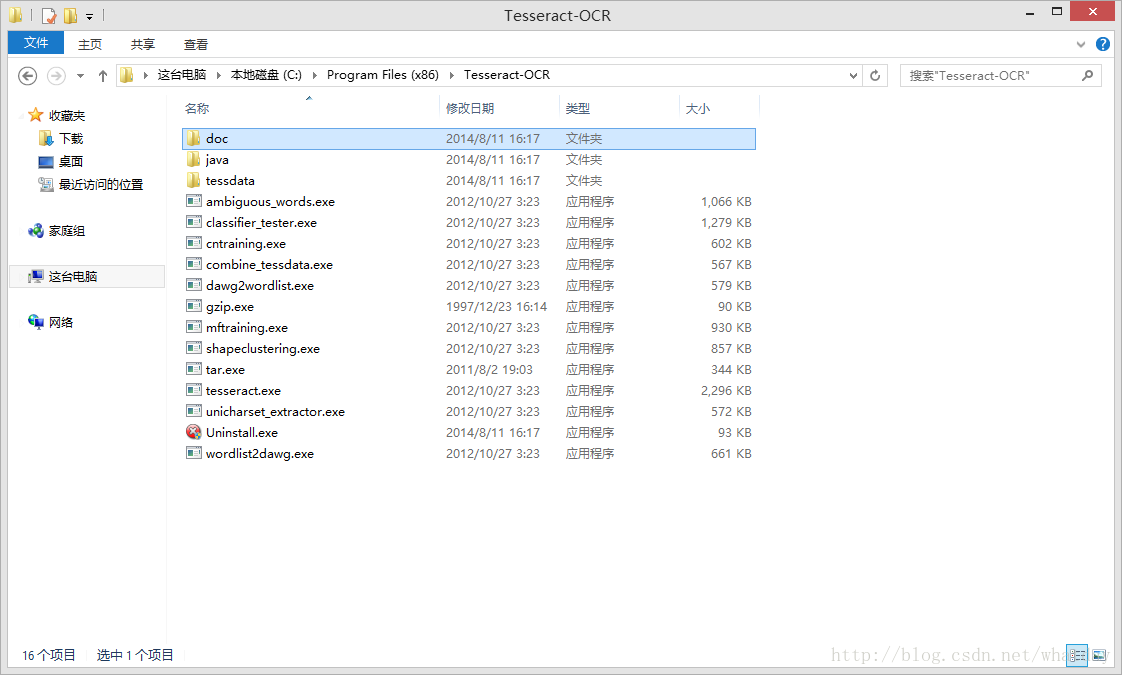
我系统是windows8.1 默认安装好后目录如下:
其中tesseract.exe是主程序, tessdata目录是存放语言文件 和 配置文件的,下载或自己生成的语言文件放到此目录里就可以了。
3.Tesseract-OCR的命令行使用
打开DOS界面,输入tesseract:
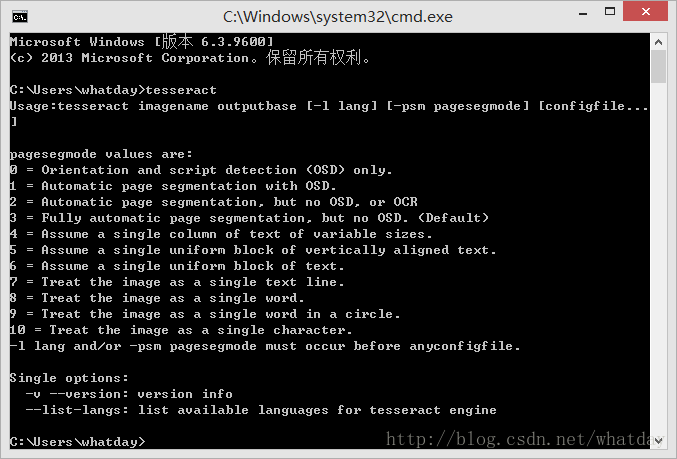
如果出现如上输出,表示安装正常。
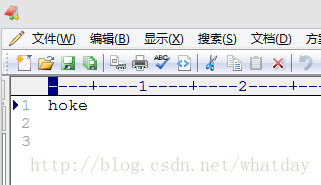
我准备了一张验证码1.png放在D盘根目录下
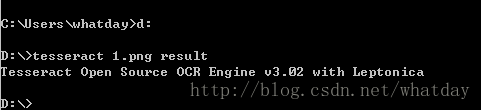
其中 1.png是验证码图片 result是结果文件的名称 默认是.TXT文件 执行成功后会在验证码图片所在位置生成result.txt 打开结果为:
命令详解:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
4.Tesseract-OCR的QA合集
A.ImageMagick是什么?
ImageMagick是一个用于查看、编辑位图文件以及进行图像格式转换的开放源代码软件套装
我在这里之所以提到ImageMagick是因为某些图片格式需要用这个工具来转换。
B.Leptonica 是什么?
Leptonica 是一图像处理与图像分析工具,tesseract依赖于它。而且不是所有的格式(如jpg)都能处理,所以我们需要借助imagemagick做格式转换。
Here's a summary of compression support and limitations:
- All formats except JPEG support 1 bpp binary.
- All formats support 8 bpp grayscale (GIF must have a colormap).
- All formats except GIF support 24 bpp rgb color.
- All formats except PNM support 8 bpp colormap.
- PNG and PNM support 2 and 4 bpp images.
- PNG supports 2 and 4 bpp colormap, and 16 bpp without colormap.
- PNG, JPEG, TIFF and GIF support image compression; PNM and BMP do not.
- WEBP supports 24 bpp rgb color.
C.提高图片质量?
识别成功率跟图片质量关系密切,一般拿到后的验证码都得经过灰度化,二值化,去噪,利用imgick就可以很方便的做到.
convert -monochrome foo.png bar.png #将图片二值化
D.我只想识别字符和数字?
结尾仅需要加digits
命令实例:tesseract imagename outputbase digits
E.训练你的tesseract
不得不说,tesseract英文识别率已经很不错了(现有的tesseract-data-eng),但是验证码识别还是太鸡肋了。但是请别忘记,tesseract的智能识别是需要训练的.
F.命令执行出现empty page!!错误
严格来说,这不是一个bug(tesseract 3.0),出现这个错误是因为tesseract搞不清图像的字符布局
-psm N
Set Tesseract to only run a subset of layout analysis and assume a certain form of image. The options for N are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR.
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
对于我们的验证码a.tif排列来说,采用-psm 7(single text line)比较合适。
5.Tesseract-OCR的训练方法
A.使用jTessBoxEditor工具
1.下载地址:http://download.csdn.net/detail/whatday/7740739
这个工具是用来训练样本用的,由于该工具是用JAVA开发的,需要安装JAVA虚拟机1.6才能运行。
2. 获取样本图像。用画图工具绘制了5张0-9的文样本图像(当然样本越多越好),如下图所示:
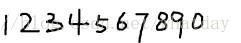
4.生成Box File文件。打开命令行,执行命令:
tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
生成的BOX文件为num.font.exp0.box,BOX文件为Tessercat识别出的文字和其坐标。
注:Make Box File的命令格式为:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
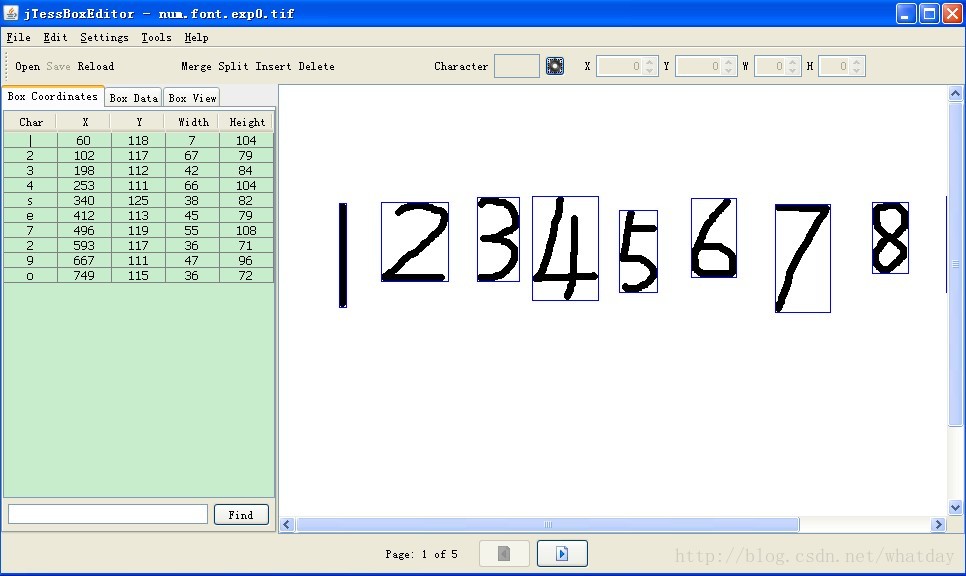
5.文字校正。运行jTessBoxEditor工具,打开num.font.exp0.tif文件(必须将上一步生成的.box和.tif样本文件放在同一目录),如下图所示。可以看出有些字符识别的不正确,可以通过该工具手动对每张图片中识别错误的字符进行校正。校正完成后保存即可。
font_properties不含有BOM头,文件内容格式如下:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
font 0 0 0 0 07.生成语言文件。在样本图片所在目录下创建一个批处理文件,输入如下内容。
rem 执行改批处理前先要目录下创建font_properties文件
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.将批处理通过命令行执行。执行后的结果如下:
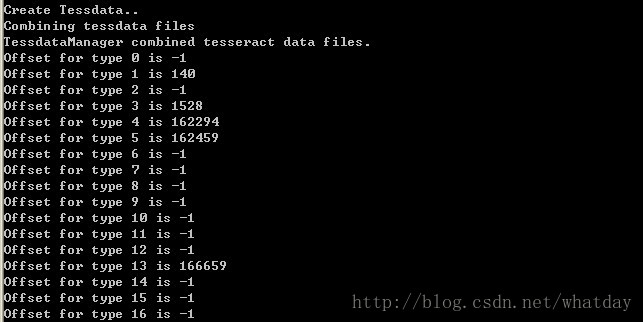
需确认打印结果中的Offset 1、3、4、5、13这些项不是-1。这样,一个新的语言文件就生成了。
num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到Tesseract-OCR-->tessdata目录下。可以用它来进行字符识别了。
训练前:
2. 打开命令行,定位到Tesseract-OCR目录,输入命令:
tesseract.exe number.jpg result -l eng
其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。
3. 打开Tesseract-OCR目录下的result.txt文件,看到识别的结果为7542315857,有3个字符识别错误,识别率还不是很高,那有没有什么方法来提供识别率呢?Tesseract提供了一套训练样本的方法,用以生成自己所需的识别语言库。下面介绍一下具体训练样本的方法。
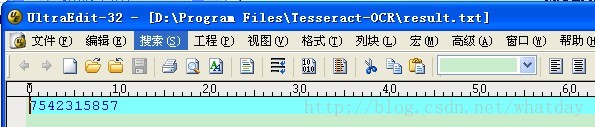
训练后:
用训练后的语言库识别number.jpg文件, 打开命令行,定位到Tesseract-OCR目录,输入命令:
tesseract.exe number.jpg result -l eng
识别结果如如图所示,可以看到识别率提高了不少。通过自定义训练样本,可以进行图形验证码、车牌号码识别等。感兴趣的朋友可以研究研究。

B.使用 CowBoxer工具
下载地址为:http://download.csdn.net/detail/whatday/7740815
第一步生成第一个 box 文件演示中将 Tesseract 解压到了 E:\tesseract-ocr 目录。然后在该目录中建立了一个 build 目录用于存放原始数据和训练过程中生成的文件。原始图片数据一个有 3 个 (test.001.tif - test.003.tif):
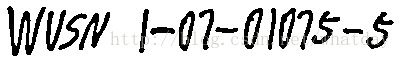
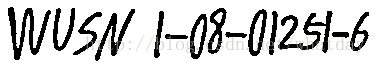
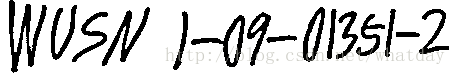
首先生成第一个图片 test.001.tif 的 box 文件,这里使用官方的 eng 语言数据进行文字识别:
Tesseract Open Source OCR Engine with Leptonica
Number of found pages: 1.
执行完这个命令之后,build 目录下就生成了一个 test.001.box。使用 CowBoxer 打开这个 box 文件,CowBoxer 会自动找到同名的 tif 文件显示出来。
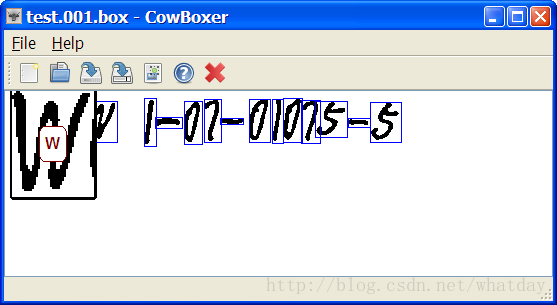
CowBoxer 的使用方法可以看 Help -> About 中的说明。修改完成之后 File -> Save box file 保存文件。
生成初始的 traineddata
接下来使用这一个 box 文件先生成一个 traineddata,在接下来生成其他图片的 box 文件时,使用这个 traineddata 有利于提高识别的正确率,减少修改次数。
..\training\unicharset_extractor test.001.box
..\training\mftraining -U unicharset -O test.unicharset test.001.tr
..\training\cntraining test.001.tr
rename normproto test.normproto
rename Microfeat test.Microfeat
rename inttemp test.inttemp
rename pffmtable test.pffmtable
..\training\combine_tessdata test.
在 build 目录下执行完这一系列命令之后,就生成了可用的 test.traineddata。
生成其余 box 文件
将上一步生成的 test.traineddata 移动到 tesseract-ocr\tessdata 目录中,接下来生成其他 box 文件时就可以通过 -l test 参数使用它了。
..\tesseract test.003.tif test.003 -l test batch.nochop makebox
这里仅仅是使用 3 个原始文件作为例子。实际制作训练文件时,什么时候生成一个 traineddata 根据情况而定。中途生成 traineddata 的目的只是为了提高文字识别的准确率,使后面生成的 box 文件能少做修改。
生成最终的 traineddata
在所有的 box 都制作完成后,就可以生成最终的 traineddata 了。
..\tesseract test.002.tif test.002 nobatch box.train
..\tesseract test.003.tif test.003 nobatch box.train
..\training\unicharset_extractor test.001.box test.002.box test.003.box
..\training\mftraining -U unicharset -O test.unicharset test.001.tr test.002.tr test.003.tr
..\training\cntraining test.001.tr test.002.tr test.003.tr
rename normproto test.normproto
rename Microfeat test.Microfeat
rename inttemp test.inttemp
rename pffmtable test.pffmtable
..\training\combine_tessdata test.
在文件较多时可以用程序生成这种脚本执行。
未完。。。















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









