







信息熵
一条信息的信息量和它的不确定性有着直接的关系。那么如何量化信息的度量呢?香农用“比特(bit)”这个概念来度量信息量。香农提出,它的准确信息量应该是:
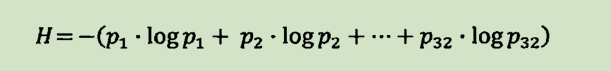
因此,对于任意一个随机变量X,它的熵定义如下:
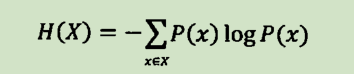
决策树
我们经常使用决策树处理分类问题,近来的调查表明决策树也是最经常使用的数据挖掘算法。
决策树的一般流程:
- 收集数据:可以使用任何方法
- 准备数据:树构造算法只适用于标称型数据 ,因此数值型数据必须离散化
- 分析数据:可以使用任何方法,构造树完成之后 , 我们应该检查图形是否符合预期
- 训练算法:构造树的数据结构
- 测试算法:使用经验树计算错误率
- 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义
计算给定数据集的信息熵


按照给定特征划分数据集


选择最好的数据集划分方式
接下来我们将遍历整个数据集,循环计算香农熵和函数找到最好的特征划分方式。熵计算将会告诉我们如何划分数据集是最好的数据组织方式 。


递归创建决策树
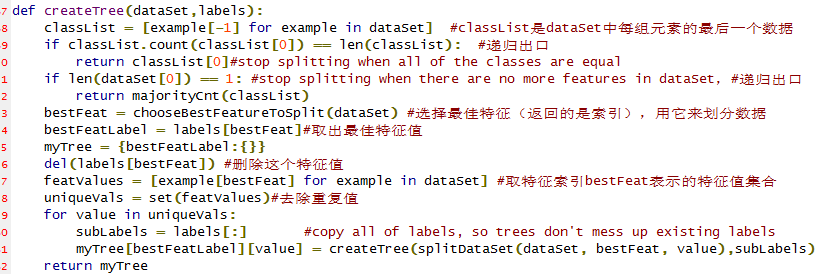

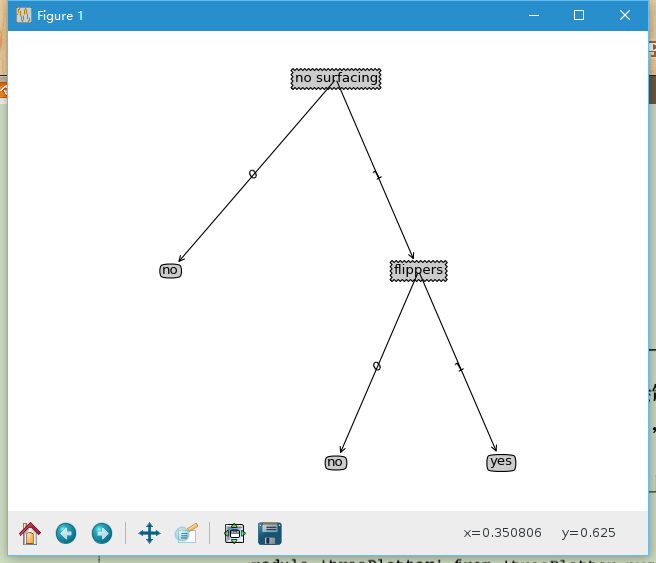
在Python中使用 Matplotlib 注解绘制树形图
上述用字典的形式表示决策树不易于理解,而且直接绘制图形也比较困难。这里将使用Mapplotlib库创建树形图。


测试算法:使用决策树执行分类
使用决策树的分类函数
![示例-分别测试[1,0]和[1,1]两组数据的分类](https://img-blog.csdn.net/20160822182728727)
使用算法:决策树的存储
构造决策树很耗时,如果数据集很大,将会耗费很多计算时间。然而用创建好的决策树解决分类问题,则何以很快完成。因此,为了节省计算时间,最好能够在每次执行分类时调用巳经构造好的决策树。为了解决这个问题,需要使用python 模块pickle序列化对象。

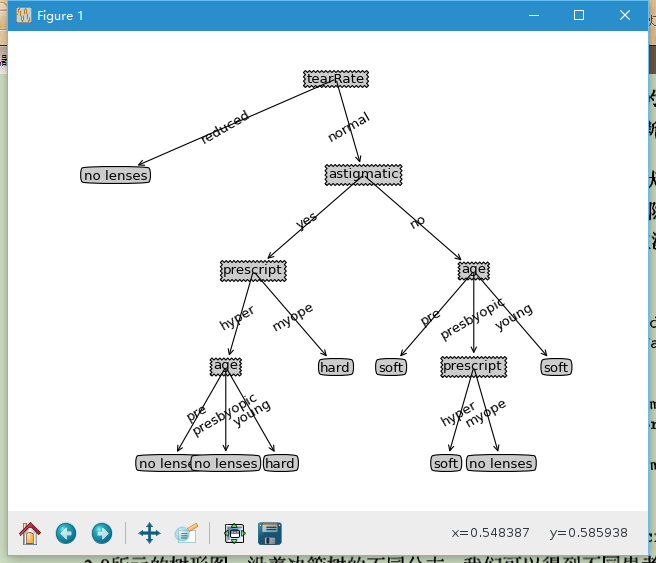
示例:使用决策树预测隐形眼镜类型
通过一个例子讲解决策树如何预测患者需要佩戴的隐形眼镜类型。

小结
这里使用的算法称为ID3,它无法直接处理数值型数据。而且可能产生过度匹配的问题,即匹配选项过多。
决策树分类器就像带有终止块的流程图,终止块表示分类结果。开始处理数据集时,我们首先需要测量集合中数据的不一致性,也就是熵,然后寻找最优方案划分数据集,直到数据集中的所有数据属于同一分类。
使用Matplotlibde注解功能,我们可以将存储的树结构转化为容易理解的图形。python语言的pickle模块可用于存储决策树的结构。隐形眼镜的例子表明决策树可能会产生过多的数据集划分,从而产生过度匹配数据集的问题。我们可以通过裁剪决策树,合并相邻的无法产生大量信息增益的叶节点,消除过度匹配问题。
还有其他的决策树的构造算法, 最流行的是C4.5 和CART。以后讨论。















 4508
4508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









