






结构体是c语言的一种自定义类型,自定义类型对于开发者及其重要的类型,它可以随意由开发者进行谱写功能,而今天的结构体可以用来表示一种变量的单个或多种具体属性,再编写代码时有着不可替代的作用!!!!
目录
前言:自定义类型
什么是自定义类型?我们在编写代码的过程中,会遇到许多类型,比如:短整型,整型,字符类型,布尔型,浮点型等多种类型,可这些都是c语言库中自带的,编写者在编写过程中只需要记住就好。
举个例子:你要定义一个变量为整数,就需要定义该变量为int型,写一个字符,就要定义一个char类型。定义时只需对应拿出即可,但是你要定义一个人的基本信息怎么办,如电话,地址,性别,名字,身份等多种属性,在c语言给出的类型中,并没有具体的类型可以去定义,所以这时就需要编写者自己根据具体的需求,去编写自己的类型,我们称为自定义类型.
而结构体类型就是常见的自定义类型的一种。
提示:以下是本篇文章正文内容,下面案例可供参考
一、结构体类型的声明
1.1结构体的面貌
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
例如我们要表示一个人,那么他的名字,电话号码,身份,性别,年龄就是他的成员变量,名字可以是字符型,电话可以是整型,身份,性别都可以是整型,就是这些成员变量构成了一个结构。
1.2结构体的定义
struct tag
{
成员列表1.;
成员列表2.;
}列表变量;
struct 为结构的关键字,tag 则为这个结构的类型名
为了更进一步了解,我们描述一位学生
struct su
{
char name[20];//名字
int age;//年龄
char sex[];//性别
};其中“;”(分号)是千万不能丢的。
1.3特殊的声名-----匿名结构体类型
什么叫匿名结构体类型,顾名思义,就是结构体的类型是匿名的
struct
{
char name[20];//名字
int age;//年龄
char sex[];//性别
};
对比一下,少了“su”结构体类型,匿名结构体固然很帅,但是也是有很大的弊端的。
先对比两组代码
代码一:
struct
{
char name[20];//名字
int age;//年龄
char sex[];//性别
}li;
代码二:
struct
{
char name[20];//名字
int age;//年龄
char sex[];//性别
}*p;我们在编译器上运行一下

我们会发现:
因为如果我们不写类型名,系统就不知道它们两个各自是什么类型
注意:指针是指向同类型的变量的,而这两个结构没有明确的类型。所以系统不认为他们是同一类型的结构,所以会报错。
就像一个字符指针无法接收一个整型变量。匿名结构体也是一样的,所以是非法的。
1.4结构体的自引用、
在内存中有可能是连续存放的,也有可能是像这样不连续存放的,随机存放的。

这样的1,2,3,4,5的数字我们称作节点,在节点里除了存放数据外,还有可能存放下一个节点的信息,我们将一个节点看作一个结构体,那么,结构体可以自己找到自己吗?
自引用类型:Node;
所以我们可以写出自引用代码
struct Node
{
int data;
struct Node next;
};

为什么这个不行哪???
仔细分析,其实本来就不行,结构体引用了同类型的结构体,结构体的大小会变的无限大,最终可能会导致内存崩溃。
但是如果不能自引用,那么为什么还要说明自引用哪?
所以是有正确的自引用方式的
我们在每个节点存放下一个节点的信息,在一个节点处存放下一个节点的地址,因此可以在结构体中存放一个结构体指针类型,这样既能解决同类型的问题不会导致无限大,还能找到下一个结构体节点的信息。
struct Node
{
int data;
struct Node *next;
};
这次我们发现,编译器不再报错。。。

问题:在结构体⾃引⽤使⽤的过程中,夹杂了 typedef 对匿名结构体类型重命名,也容易引⼊问题,看看 下⾯的代码,可⾏吗?

解答:这段代码其实是错误的,他将Node的重命名定义在了使用Node的后面,这样会导致系统无法正常识别Node是什么,所以程序错误。
二、结构体的定义和引用
初始化方式:
1.最标准的定义:
struct su
{
char name[20];//名字
int age;//年龄
char sex[];//性别
};
int main()
{
struct su a = { "qingkai",18,"n"};//初始化
printf("名字%s\n年龄%d\n性别%c\n", a.name, a.age, a.sex);//引用
return 0;
}2.最不环保的方式:
#include <stdio.h>
struct student /*声明时直接定义*/
{
int age; /*年龄*/
float score; /*分数*/
char sex; /*性别*/
/*这种方式不环保,只能用一次*/
} a={21,80,'n'};
int main ()
{
printf("年龄:%d 分数:%.2f 性别:%c\n", a.age, a.score, a.sex );
return 0;
}3.最烂的方式
2.
struct //直接定义结构体变量,没有结构体类型名。这种方式最烂
{
int age;
float score;
char sex;
} t={21,79,'f'};
int main ()
{
printf("年龄:%d 分数:%f 性别:%c\n", t.age, t.score, t.sex);
return 0;
}2.1.2引用的方式 :
2.1.1.1"操作符引用
"."操作符引用:结构体变量.成员列表
如a.name,a.age,a.sex;
这种直接使用成员列表。
2.2.2.2"->"操作符引用:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
struct book
{
char book_name[20];//书名
char author[20];//作者
char id[20];//编号
float price;//价格
};
int main()
{
struct book s1 = { "c语言","谭浩强","THQ3324",55.5f };
struct book s2 = { .author = "谭浩强",.book_name = "c语言",.id = "THQ3324",55.5f };//.引用
struct book* ps = &s2;
printf("%s %s %s %f\n", s1.author, s1.book_name, s1.id, s1.price);
printf("%s %s %s %f\n", ps->author, ps->book_name, ps->id, ps->price);//->引用
return 0;
}
我们可以看出:
我们看到这两种引用方式的结果一模一样,区别是箭头引用只能是指针变量使用。2.
2.2 结构体内存对齐
内存是什么???,为什么会有内存对齐???
我们都知道一个整型占4个字节,一个字符类型占1个字节,而占的字节数,就是所需内存
。但是一个结构体因为定义的类型各有不同,那么结构体占多少内存哪??
别急,我们对比代码
代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
struct book1
{
char book_name;//书名
char author;//作者
char id;//编号
int price;//价格
};
struct book2
{
char bok_na;
char auy;
int price;
char id;
};
int main()
{
printf("%d\n", sizeof(struct book1));
printf("%d\n", sizeof(struct book2));
return 0;
}
不妨先猜一猜:char类型有三个,占3个字节,int类型有一个,占4个字节,最后一定都是占4+3==7个字节吧!!!
运行代码:

????,为什么哪,不要疑惑,不要惊讶,这就是内存对齐!!!!
2.2.1内存对齐
对齐规则
- 结构体的第⼀个成员对⻬到和结构体变量起始位置偏移量为0的地址处
- 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。
- 对⻬数 = 编译器默认的⼀个对⻬数 与 该成员变量⼤⼩的较⼩值
- VS 中默认的值为 8
- Linux中 gcc 没有默认对⻬数,对⻬数就是成员⾃⾝的⼤⼩
- 结构体总⼤⼩为最⼤对⻬数(结构体中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的 整数倍。
- .如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构 体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。
这里我们先介绍一种宏offsetof作用是计算结构体成员相较结构体变量起始位置的偏移量。
偏移量就是相较于起始位置的字节偏移量

这里我们以struct book1类型结构体为例,
、
#include<stdio.h>
#include<stddef.h>//头文件
struct book1
{
char book_name;//书名
char author;//作者
char id;//编号
int price;//价格
};
int main()
{
printf("%d\n", offsetof(struct book1, book_name));
printf("%d\n", offsetof(struct book1, author));
printf("%d\n", offsetof(struct book1, id));
printf("%d\n", offsetof(struct book1,price ));
return 0;
}运行代码:

接下来我们就一点一点深挖这结果的由来
1.无结构体嵌套
我们已经知道4个成员的偏移量分别是:0,1,2,4
由此我们可以画出

我们可以看出,正好8个字节,与程序运行的结果相同

中间的画红×的字节就被舍弃了,舍弃的原因我们稍后讲解。
2.代码2
struct s2
{
char c1;
int n;
char c2;
};
int main()
{
printf("%zd\n", offsetof(struct s2, c1));
printf("%zd\n", offsetof(struct s2, c2));
printf("%zd\n", offsetof(struct s2, n));
return 0;
}
乍一看没什么不一样,我们运行结果试一试
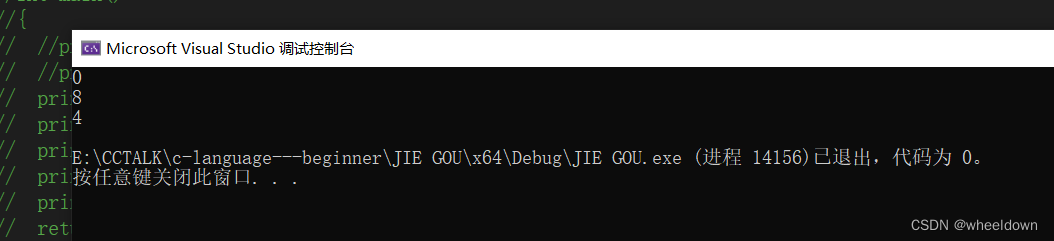
三个成员的偏移量为0,4,8

这里的字节最高字节数看着是9,但是还记得对齐规则吗?
所以在以上struct s2中一开始第一个成员c1的大小为1,比vs默认偏移数8小,所以偏移数就是1,c1大小为1

第二个成员n的大小为4,比vs默认偏移数8小,所以偏移数就是4,所以n从第五个字节开始,n大小为4字节

第三个成员c2的大小为1,比vs默认偏移数8小,所以偏移数就是1,所以n从第九个字节开始,c2大小为1字节
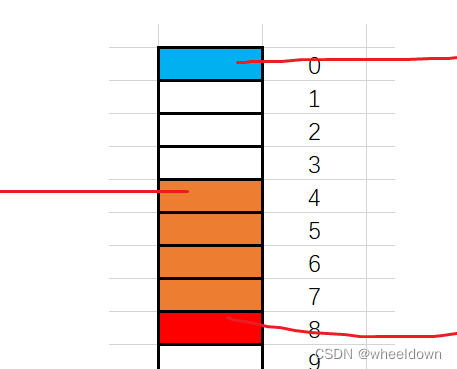
在此还未结束,因为结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍,
该结构体struct s2最大对齐数为4,所以结构体大小必须是4的整数倍,
9字节并不是4的整数倍,所以struct s2大小为12字节

2.有结构体嵌套的内存对齐
#include<stdio.h>
struct S3
{
double x;
char c;
int n;
};
struct S4
{
char c1;
struct S3 s3;
double d;
};
int main()
{
printf("%zd\n", sizeof(struct S4));
return 0;
}- 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍
所以对于嵌套结构体来说,在s4结构体中,s3的结构体成员要对齐到8的整数倍
s4的整体大小是所有最大对齐数的整数倍
- c1的大小为1个字节,偏移量为0
- s3偏移量为8,大小为16字节
- d的大小为8个字节,偏移量为24
最终结构体struct S4大小就为32个字节

2.2 为什么存在内存对齐
1. 平台原因 (移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对⻬的内存,处理器需要作两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。假设⼀个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对齐成8的倍数,那么就可以用⼀个内存操作来读或者写值了。否则,我们可能需要执行两次内存访问,因为对象可能被分放在两个8字节内存块中。

例如在以上结构体struct S中如果机器每次内存读取4个字节,在未对齐情况下就要读取两次,而在对齐的情况下就只要读取一次
总体来说:结构体的内存对齐是拿空间来换取时间的做法
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到:
让占用空间小的成员尽量集中在一起
2.3 修改默认对齐数
在以上的学习中我们知道了VS的默认对齐数是8,那么有什么办法可以修改默认对齐数呢?
其实是有办法的,利用#pragma 这个预处理指令,可以改变编译器的默认对齐数。
#include<stdio.h>
#pragma pake(1)//修改默认对齐数为2
struct s1
{
char c1;
char c2;
int n;
};
#pragma pake()//恢复默认对齐数
int main()
{
printf("%zd", sizeof(struct s1));
return 0;
}
使用了#pragma后默认对齐数就被修改为了2,结构体struct s1的大小就变成6字节
结构体传参
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
struct S
{
int data[1000];
int num;
};
struct S s = { {1,2,3,4}, 1000 };
//结构体传参
void print1(struct S s)
{
for (int i = 0; i < 4; i++)
{
printf("%d ", s.data[i]);
}
printf("\n");
printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{
for (int i = 0; i < 4; i++)
{
printf("%d ", ps->data[i]);
}
printf("\n");
printf("%d\n", ps->num);
}
int main()
{
print1(s); //传结构体
print2(&s); //传地址
return 0;
}
在函数传参的时候分为传值调用和传址调用,结构体中也有两种调用,如print1是传值调用,print2是传址调用。虽然两种方式都能找到结构体成员,但是对于系统来说,传值调用是很不利的,原因是使用传址调用不用再开辟一块内存空间,新创建的指针就指向了原来的那块内存空间,而使用传值调用时,需要再创建一块新的内存空间,如果这个结构体像以上struct S一样所占内存空间很大的话,再创建新的内存就很浪费内存,还有函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
结论:结构体传参最好用传址调用。
















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











