





import os
import time
import requests
import json
from selenium.webdriver import Chrome
from lxml import etree
def requests_get(href):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
}
resp = requests.get(url=href, headers=headers)
if resp.status_code == 200:
return resp
else:
print(resp.status_code)
def get_skin(num,name):
char_list = ['*', '|', ':', '?', '/', '<', '>', '"', '\\']
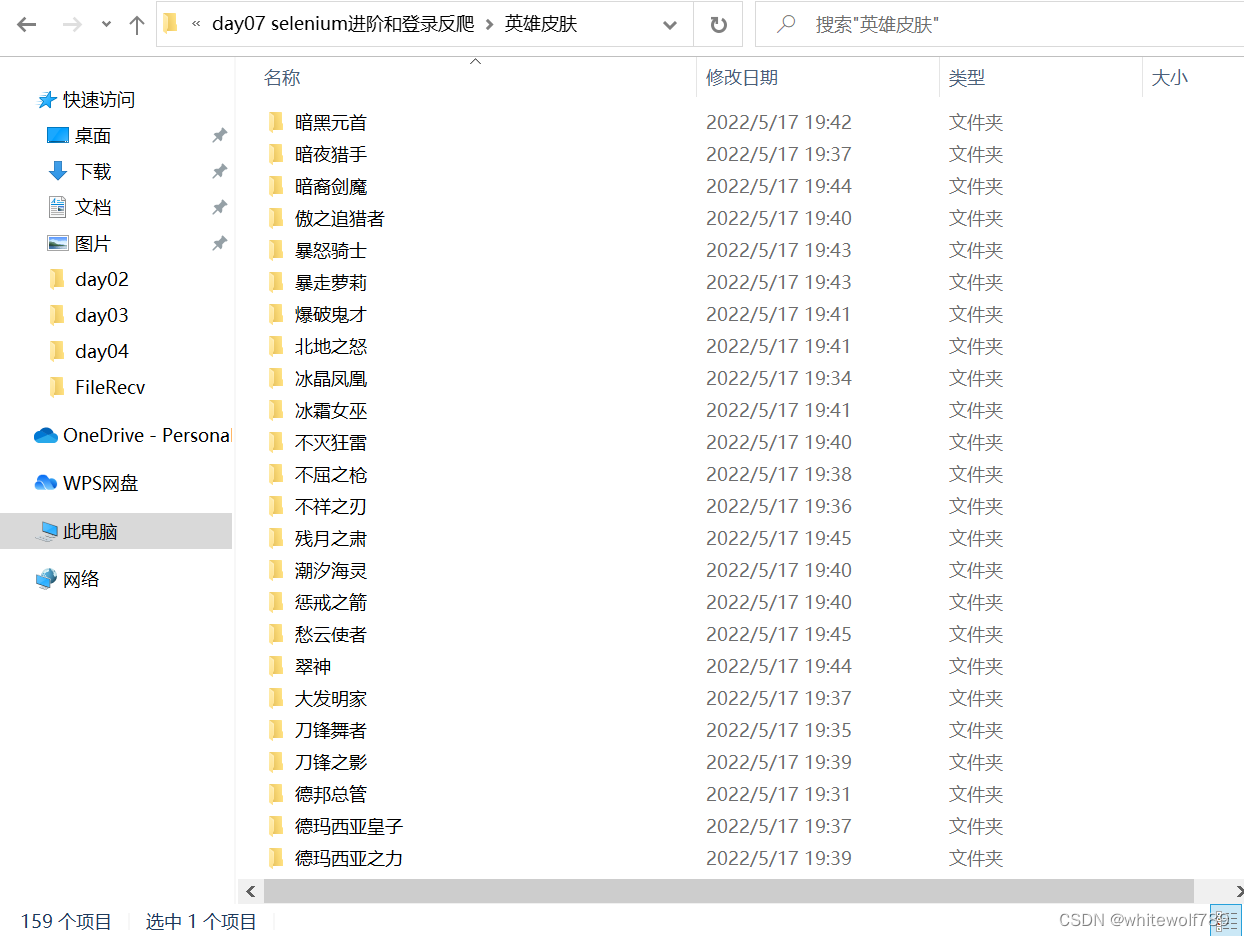
os.mkdir(f'./英雄皮肤/{name}')
hero_href = f'https://game.gtimg.cn/images/lol/act/img/js/hero/{num}.js'
resp = requests_get(hero_href)
data = resp.json()
# print(data['skins'],type(data['skins']))
for skin in data['skins']:
# print(skin['name'], skin['mainImg'])
if len(skin['mainImg']) != 0:
skin_img_url = skin['mainImg']
resp = requests.get(url=skin_img_url)
# 替换文件名中系统不支持的字符
for c in char_list:
if c in skin['name']:
skin['name'] = skin['name'].replace(c,'_')
print(skin['name'])
with open(f"./英雄皮肤/{name}/{skin['name']}.jpg", 'wb') as f:
f.write(resp.content)
b = Chrome()
b.get('https://lol.qq.com/data/info-heros.shtml')
time.sleep(1)
root = etree.HTML(b.page_source)
b.close()
heroes = root.xpath('//ul[@class="imgtextlist"]/li')
for i in heroes:
href = i.xpath('a/@href')
serial_number = href[0].split('=')[1]
print(serial_number)
hero_name = i.xpath('a/p/text()')
print(hero_name[0])
get_skin(serial_number, hero_name[0])
```
将皮肤名中的特殊字符进行了替换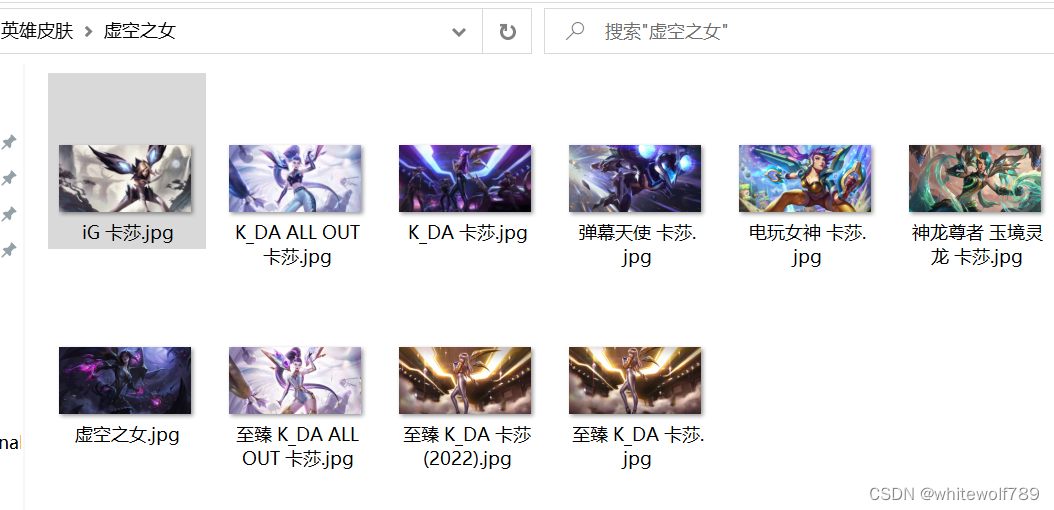
爬虫——英雄皮肤
最新推荐文章于 2025-06-21 21:39:42 发布


















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









