







这一次讲django实现的爬虫,而且是爬图片。
爬图片会有两个问题:
1. 爬到的图片怎么保存?
2. 怎么将爬到的图片显示在页面上?
接下来我们一一解答。
第一,我们要将爬到的图片显示出来,那就要图片的链接,所以我们只要保存图片的原地址就可以了。
第二,django中的for标签会帮我们新建元素并将元素添加到文档流中。举个例子,
{% for item in results %}
<img src={{ item|escape }}>
{% endfor %}
前提是results不为空。
这也将是我们显示爬到的图片的代码。
下面细说具体步骤。
首先在templates目录下建立文件crawler.html,添加代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>抓取图片</title>
<style type="text/css">
body, div {
padding: 0;
margin: 0;
}
#container {
width: 1070px;
margin: 0 auto;
}
.wrap {
width: 360px;
height: 48px;
margin: 0 auto;
}
.wrap form input {
width: 240px;
height: 24px;
margin-top: 12px;
}
.showcase {
width: 1070px;
height: 100%;
margin: 0 auto;
}
.showcase img {
width: 450px;
height: 350px;
}
</style>
</head>
<body>
<div id="container">
<div class="wrap">
<form action="." class="crawl" method="GET">
<input type="text" name="q" autocomplete="off">
<button type="submit">抓一抓</button>
</form>
</div>
<div class="showcase">
{% if results %}
<h3>从{{query}}抓取到下面的图片</h3>
{% for item in results %}
<img src={{ item|escape }}>
<!-- <p>{{ item|escape }}</p> -->
{% endfor %}
{% endif %}
</div>
</div>
</body>
</html>页面就这么简单,下面看核心—爬虫函数。
在views.py中添加代码:
#-*- coding: utf-8 -*-
import re
import urllib
from django.shortcuts import render,render_to_response
# Create your views here.
def getImg(url, imgType):
page = urllib.urlopen(url)
html = page.read()
reg = r'src="(.*?\.+'+imgType+'!slider)"' #这个正则表达式是最关键的,取得图片链接就靠它了
imgre = re.compile(reg)
imgList = re.findall(imgre, html)
return imgList
def issue(request):
query = request.GET.get('q','')
if query:
imglist = getImg(query, 'jpg')
else:
imglist = []
return render_to_response('issue/crawler.html', {'query': query, 'results': imglist})下面主要解释一下getImg函数。
注释也说明了,最关键的是这一行reg = r'src="(.*?\.+'+imgType+'!slider)"'
这一行什么用呢?匹配图片地址的正则表达式。但是这只适用于http://www.36kr.com/这个网站,其他网站的图片地址不是这样的格式。所以要想能够爬到任意一个网址上的图片,还得从获取的源文件中分析得到地址格式,而不能在代码里面写死了。
接下来在urls.py中添加:(r'^issue/', 'issue'),,然后在浏览器中打开127.0.0.1:8000/issue/
运行效果:
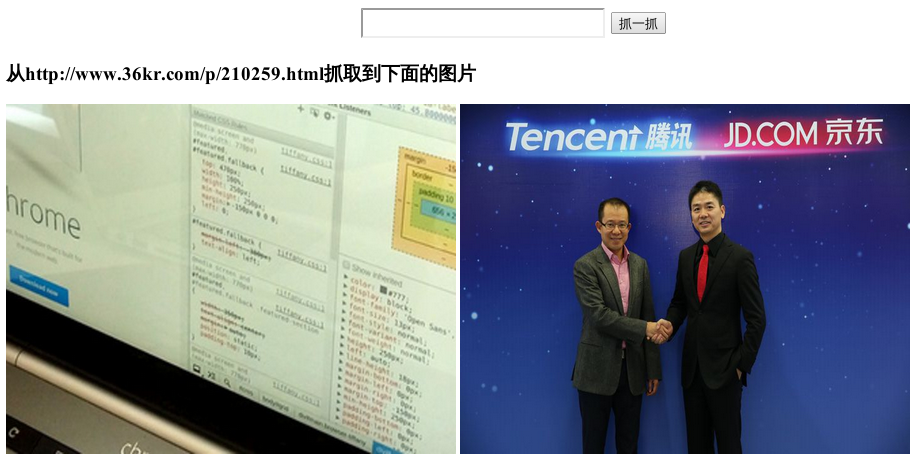
这样最简单的图片爬虫就完成了,大家可以根据自己的需要和功力自己完善。















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









