






最近看到数据挖掘中的K-Means算法,想到它经常和图像分类中的BOF算法结合,恰好自己最近在做图像检索方面的研究,就试着实现了一下,代码资源我会在文后附上链接
BOF(Bag of Features)算法实际上就是BOW(Bag of Words)算法在图像领域的应用。可以参考下图:
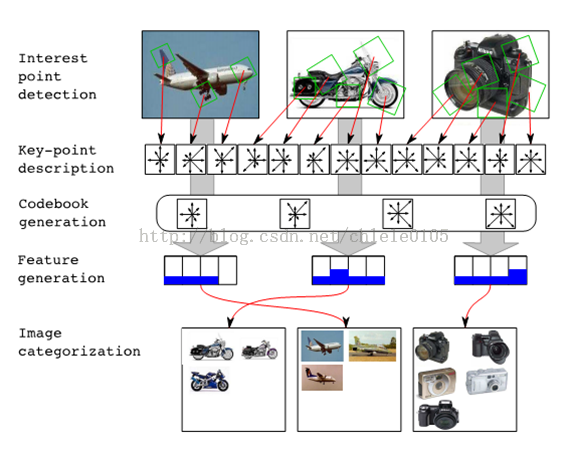
图片来源 Bag of Features (BOF)图像检索算法
BOF算法的主要操作步骤如下:
- 视觉单词提取:首先我们先提取图片库中所有图片的图片特征,这里图片特征可以是SIFT,SURF,MSER特征等等,我在实现时使用的SIFT特征. BOW算法中是以“词”为单位形成词袋的,BOF算法中我们以每个特征作为一个patch,相当于一个视觉单词。
- 视觉词典构建:以一定的算法对所有的图片特征进行分类,K-Means和SVM算法均可,但是K-Means算法最为常用。比如K=500时,我们可以把所有的特征按照相似度量分成500个聚类,每个聚类有一个类心,那么这500个类心就相当于词袋中的500个基本词汇。
- 图像表示:统计每张图片在每个聚类中的特征个数,这样每个图片就可以由一个分布直方图表示,或者说用一个K维的向量表示,向量第 i 维的值为该图片在第 i 个聚类中的特征个数。那么每个图像都可以由基本词汇表示。
- 图像检索:对于一个待检索的图像,我们先提取该图像的图像特征,并产生该图像的分布直方图,即或者一个K维向量。然后,根据余弦相似定理,计算该向量与图片库中每个图像的余弦夹角。夹角越小,相似度越大,夹角越大,相似度越小。
或者需要详细的BOF讲解可以参考这个链接:Bag of Features (BOF)图像检索算法
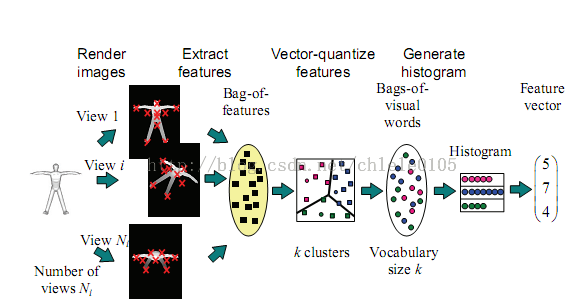
本实验中采用SIFT特征,K-means聚类算法,初始类心随机选择,图片库图片数量625。
最后实验表明,BOF算法的检索效果确实很不错,好的时候查准率可以达到90%,最差情况下也能满足50%左右的查准率。
在实验中,我总结了一些需要注意的地方:
- 图片库大有利于特征聚类,当图片数量较少,图像特征不多的情况下,每个聚类的中特征点个数也就几十个。这对于统计分类来说,结果不够可信,误差也较大。
- 图片库特征点个数(至少20万个)较多情况下,聚类个数多一些检索效果较好,但是也不能太多,不然会出现上面的情况。一般都是成百上千个。
- 初始类心的选择对结果有一定的影响,不同初始类心的选择可能导致查准率有较大的波动。一般来说图片越多,它的影响就会越小。也可以通过指定初始类心,使得结果更优。
- 带检索图片的特征点个数太少,检索结果会比较差,但也不是越多越好。
- TF-IDF算法是用来在信息检索中确定关键字权值,也常和BOF算法结合使用,用来确定每个类心的权值,理论上会对实验结果有一定的提高。我在实验中没有使用,苦于没有找到合适的参考方法,TF-IDF怎么统计并确定每个类心的权值?以及这种权值对于求余弦相似度的影响是怎样的?如果有明白的同学,希望能够告诉我具体方法,谢谢了。
对K-Means算法和TF-IDF算法不太熟悉的同学可以参考一下这个链接,里面会有说明数据挖掘经典算法概述以及详解链接















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









