






Python函数、模块和包
函数
定义函数
函数function,通常接收输入参数,并有返回值。
它负责完成某项特定任务,而且相较于其他代码,具备相对的独立性。
函数特征:
- 使用 def 关键词来定义一个函数
- def 后面是函数的名称,括号中是函数的参数,不同的参数用 , 隔开, def foo(): 的形式是必须要有的,参数可以为空
- 使用缩进来划分函数的内容
- docstring 用 “”" 包含的字符串,用来解释函数的用途,可省略
- return 返回特定的值,如果省略,返回 None
使用函数
- 使用函数时,只需要将参数换成特定的值传给函数。
- Python 并没有限定参数的类型,因此可以使用不同的参数类型
- 传入参数时,Python 提供了两种选项,第一种是按照位置传入参数,另一种则是使用关键词模式,显式地指定参数的值,两种模式可以混合使用
设定参数默认值
- 可以在函数定义的时候给参数设定默认值
- 可以省略有默认值的参数
- 可以修改参数的默认值
注意,在使用混合语法时,要注意不能给同一个值赋值多次,否则会报错
接收不定长参数
- 接受不定长数目的参数
def add(x, *args):
total = x
for arg in args:
total += arg
return total
这里,*args 表示参数数目不定,可以看成一个元组,把第一个参数后面的参数当作元组中的元素。
- 使用关键词传入参数
def add(x, **kwargs):
total = x
for arg, value in kwargs.items():
print("adding %s=%s"%(arg,value))
total += value
return total
这里, **kwargs 表示参数数目不定,相当于一个字典,键和值对应于键值对
- 可以接收任意数目的位置参数和键值对参数
def foo(*args, **kwargs):
print(args, kwargs)
foo(2, 3, x='bar', z=10)
不过要按顺序传入参数,先传入位置参数 args ,再传入关键词参数 kwargs 。
返回多个值
- 返回值可以用元组表示
def divid(a, b):
"""
除法
:param a: number 被除数
:param b: number 除数
:return: 商和余数
"""
quotient = a // b
remainder = a % b
return quotient, remainder
quotient, remainder = divid(7,4)
print(quotient, remainder)
- 也可以将参数用元组以这种方式传入
def divid(a, b):
"""
除法
:param a: number 被除数
:param b: number 除数
:return: 商和余数
"""
quotient = a // b
remainder = a % b
return quotient, remainder
z = (7,4)
print(divid(*z))
这里的*必不可少
- 事实上,还可以通过字典传入参数来执行函数
def divid(a, b):
"""
除法
:param a: number 被除数
:param b: number 除数
:return: 商和余数
"""
quotient = a // b
remainder = a % b
return quotient, remainder
z = {'a':7,'b':4}
print(divid(**z))
map方法生成序列
其用法为:
map(aFun, aSeq)
将函数 aFun 应用到序列 aSeq 上的每一个元素上,返回一个列表,不管这个序列原来是什么类型。
事实上,根据函数参数的多少,map 可以接受多组序列,将其对应的元素作为参数传入函数
ef divid(a, b):
"""
除法
:param a: number 被除数
:param b: number 除数
:return: 商和余数
"""
quotient = a // b
remainder = a % b
return quotient, remainder
a = (10, 6, 7)
b = [2, 5, 3]
print(list(map(divid,a,b)))
此上输出结果:[(5, 0), (1, 1), (2, 1)]
模块
- 使用import关键词导入当前目录下的模块,在导入时,Python 会执行一遍模块中的所有内容。
- 使用被导入模块下的变量、函数:
模块名.变量名(函数名) - 为了提高效率,Python 只会载入模块一次,已经载入的模块再次载入时,Python 并不会真正执行载入操作,哪怕模块的内容已经改变。
- 需要重新导入模块时
- 可以使用 reload 强制重新载入它
- remove删除之前生成的文件
- 引入模块时可以为它设置一个别名让使用更方便
import 原名 as 别名
别名.变量名(函数名)
_name_属性
有时候我们想将一个 .py 文件既当作脚本,又能当作模块用,这个时候可以使用 name 这个属性。
只有当文件被当作脚本执行的时候, __name__的值才会是 ‘main’
其他导入方法
- 可以从模块中导入变量
from 模块 import 变量
- 使用form后,可以直接使用被引入的变量
- 使用
*导入所有变量
这种导入方法不是很提倡,因为如果你不确定导入的都有哪些,可能覆盖一些已有的函数。
包
假设我们有这样的一个文件夹:
foo/
- init.py
- bar.py (defines func)
- baz.py (defines zap)
这意味着 foo 是一个包,我们可以这样导入其中的内容:
from foo.bar import func
from foo.baz import zap
bar 和 baz 都是 foo 文件夹下的 .py 文件。
导入包要求:
- 文件夹 foo 在 Python 的搜索路径中
- init.py 表示 foo 是一个包,它可以是个空文件。
Python异常和警告
异常
try:
pass
except 值 as exc:
pass
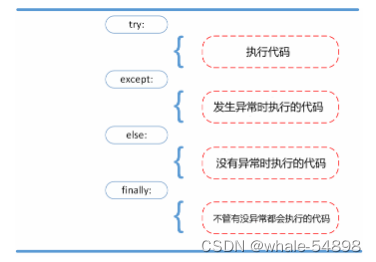
一旦 try 块中的内容出现了异常,那么 try 块后面的内容会被忽略,Python 会寻找 except 里面有没有对应的内容,如果找到,就执行对应的块,没有则抛出这个异常。
捕捉不同的错误类型
捕捉所有异常
将except 的值改成 Exception 类,来捕获所有的异常。
指定特定异常
把欲检测的异常类型值指定到except的值中
得到异常的具体信息
为了得到异常的具体信息,将 ValueError 具体化
exc.message 显示的内容是异常对应的说明
当我们使用 except Exception 时,会捕获所有的 Exception 和它派生出来的子类,但不是所有的异常都是从 Exception 类派生出来的,可能会出现一些不能捕获的情况,因此,更加一般的做法是使用这样的形式:
try:
pass
except:
pass
这样不指定异常的类型会捕获所有的异常,但是这样的形式并不推荐。
else
try/except 块有一个可选的关键词 else。
如果使用这个子句,那么必须放在所有的 except 子句之后。else 子句将在 try 子句没有发生任何异常的时候执行。
finally
try/except 块还有一个可选的关键词 finally。
不管 try 块有没有异常, finally 块的内容总是会被执行,而且会在抛出异常前执行,因此可以用来作为安全保证,比如确保打开的文件被关闭。
异常的处理流程:
Python全部的错误类型
- ZeroDivisionError——除(或取模)零 (所有数据类型)
- ValueError——传入无效的参数
- AssertionError——断言语句失败
- StopIteration——迭代器没有更多的值
- IndexError——序列中没有此索引(index)
- IndentationError——缩进错误
- OSError——输入/输出操作失败
- ImportError——导入模块/对象失败
- NameError——未声明/初始化对象 (没有属性)
- AttributeError——对象没有这个属性
- GeneratorExit——生成器(generator)发生异常来通知退出
- TypeError——对类型无效的操作
- KeyboardInterrupt——用户中断执行(通常是输入^C)
- OverflowError——数值运算超出最大限制
- FloatingPointError——浮点计算错误
- BaseException——所有异常的基类
- SystemExit——解释器请求退出
- Exception——常规错误的基类
- StandardError——所有的内建标准异常的基类
- ArithmeticError——所有数值计算错误的基类
- EOFError——没有内建输入,到达EOF 标记
- EnvironmentError——操作系统错误的基类
- WindowsError——系统调用失败
- LookupError——无效数据查询的基类
- KeyError——映射中没有这个键
- MemoryError——内存溢出错误(对于Python 解释器不是致命的)
- UnboundLocalError——访问未初始化的本地变量
- ReferenceError——弱引用(Weak reference)试图访问已经垃圾回收了的对象
- RuntimeError——一般的运行时错误
- NotImplementedError——尚未实现的方法
- SyntaxError Python——语法错误
- TabError——Tab 和空格混用
- SystemError——一般的解释器系统错误
- UnicodeError——Unicode 相关的错误
- UnicodeDecodeError——Unicode 解码时的错误
- UnicodeEncodeError——Unicode 编码时错误
- UnicodeTranslateError——Unicode 转换时错误
警告
出现了一些需要让用户知道的问题,但又不想停止程序时使用警告
使用步骤:
- 导入警告模块
- 调用函数
警告类型
- Warning——警告的基类
- DeprecationWarning——关于被弃用的特征的警告
- FutureWarning——关于构造将来语义会有改变的警告
- OverflowWarning——旧的关于自动提升为长整型(long)的警告
- PendingDeprecationWarning——关于特性将会被废弃的警告
- RuntimeWarning——可疑的运行时行为(runtime behavior)的警告
- SyntaxWarning——可疑的语法的警告
- UserWarning——用户代码生成的警告
Python文件读写
文件读写
读文件
- 使用open函数来去文件,使用文件名的字符串作为输入参数
- 默认以读的方式打开文件,如果文件不存在会报错
f1 = open('test.txt')
- 可以使用read方法来读入文件中的所有内容
text = f.read()
- 也可以按照行读入内容,readlines的方法返回一个列表,每个元素代表文件中的每一行的内容
f = open('test.txt')
lines = f.readlines()
- 使用完文件之后,需要将文件关闭
f.close()
- 也可以将f放在一个循环中,得到它每一行的 内容
f = open('test.txt)
for line in f:
print(line)
f.close()
- 删除刚才创建的文件
import os
os.remove('test.txt')
写文件
- 使用open函数的写入模式来写文件
f = open('myfile.txt', 'w')
f.write('hello world!')
f.close()
- 使用w模式时,如果文件不存在会被创建;如果文件已存在,w模式会覆盖之前写的所有内容
- 除了写入模式,还有追加模式a,追加模式不会覆盖之前已经写入的内容,而是在之后继续写入
- 写入结束之后一定要将文件关闭,否则看你出现内容没有完全写入文件中的情况
- 读写模式w+
f = open('myfile.txt', 'w+')
f.write('hello world!')
f.seek(6)
print(f.read())
f.close()
f.seek(n)移动到文件的第n个字符处,然后f.read()读出剩下的内容
关闭文件
- 在 Python 中,如果一个打开的文件不再被其他变量引用时,它会自动关闭这个文件。
- 所以正常情况下,如果一个文件正常被关闭了,忘记调用文件的 close 方法不会有什么问题。
- 关闭文件可以保证内容已经被写入文件,而不关闭可能会出现意想不到的结果
- 虽写入了内容,但在关闭之前,内容并没有被写入磁盘
- 使用循环写入的内容也不完整
- 出现异常时,磁盘读写也没有完成
with方法
- 事实上,Python 提供了更安全的方法,当 with 块的内容结束后,Python 会自动调用它的close 方法,确保读写的安全
- 与 try/exception/finally 效果相同,但更简单。
CSV文件和csv模块
标准库中有自带的 csv 模块处理 csv 格式的文件
读csv文件
import csv
# 打开 data.csv 文件
fp = open("data.csv")
# 读取文件
r = csv.reader(fp)
# 可以按行迭代数据
for row in r:
print(row)
# 关闭文件
fp.close()
写csv文件
可以使用 csv.writer 写入文件,不过相应地,传入的应该是以写方式打开的文件,不过一般要用 ‘wb’ 即二进制写入方式,防止出现换行不正确的问题
Matplotlib基础
导入matplotlib 和 numpy
import matplotlib.pyplot as plt
from numpy import *
import numpy as np
plot二维图
x = linspace(0, 10, 30)
%只给定y值,默认以下标为x轴
plt.plot(y)
%给定x和y值
plt.plot(x, y)
%多条数据线
plt.plot(x, y, x1, y1)
%使用字符串,给定线条参数
plt.plot(x, y, format_string)
scatter散点图
scatter(x, y)
scatter(x, y, size)
scatter(x, y, size, color)
plt.scatter(x, sin(x), marker='^', color='r');
plt.plot(x, sin(x), ‘bo’);
plt.scatter(x, sin(x));
二者效果相同
多图
- 使用**figure()**命令产生新的图像
- 使用 subplot 在一幅图中画多幅子图
subplot(row, column, index)
向图中添加数据
- 默认多次 plot 会叠加
标签
- 可以在 plot 中加入 label ,使用 legend 加上图例
plt.plot(x, label='sin')
plt.plot(y, label='cos')
plt.legend();
- 直接在 legend中加入
plt.plot(x)
plt.plot(y)
plt.legend(['sin', 'cos']);
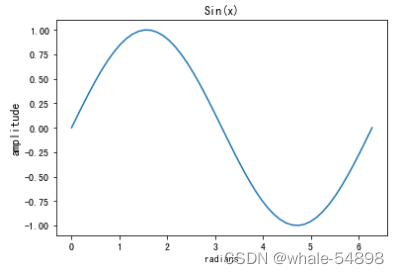
坐标轴,标题,网格
- 可以设置坐标轴的标签和标题
x = linspace(0, 2 * pi, 50)
plt.plot(x, sin(x))
plt.xlabel('radians')
# 可以设置字体大小
plt.ylabel('amplitude', fontsize='large')
plt.title('Sin(x)');
 - 用 ‘grid()’ 来显示网格
- 用 ‘grid()’ 来显示网格
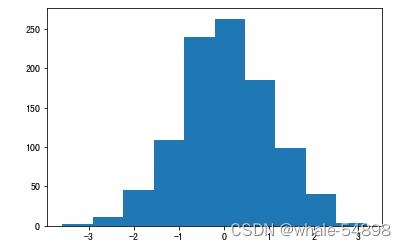
直方图
- 从高斯分布随机生成1000个点得到的直方图
plt.hist(np.random.randn(1000));
 更多例子参考:https://matplotlib.org/2.0.2/gallery.html
更多例子参考:https://matplotlib.org/2.0.2/gallery.html
Numpy基础
- NumPy(Numerical Python)是一个开源的 Python 科学计算库,用于快速处理任意维度的数组。
- 对于同样的数值计算任务,使用 NumPy 比直接使用 Python 要简洁的多。
- 导入numpy
import numpy as np
ndarray介绍
NumPy 提供了一个N 维数组类型 ndarray,它描述了相同类型的 items 的集合。
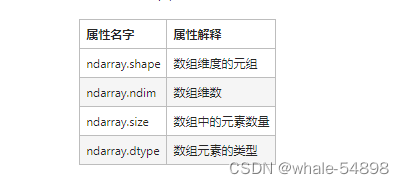
ndarray的属性
数组属性反映了数组本身固有.
ndarray的类型
| 名称 | 描述 |
|---|---|
| np.bool | 用一个字节存储的布尔类型(True或False |
| np.int8 | 一个字节大小,-128至127 |
| np.int16 | 整数,-32768至32767 |
| np.int32 | 整数,-231至232-1 |
| np.int64 | 整数,-263至263-1 |
| np.uint8 | 无符号整数,0至255 |
| np.uint16 | 无符号整数,0至65535 |
| np.uint32 | 无符号整数,0至232-1 |
| np.uint64 | 无符号整数,0至264-1 |
| np.float16 | 半精度浮点数数:16位,正负号1位,指数5位,精度10位 |
| np.float32 | 单精度浮点数数:32位,正负号1位,指数8位,精度23位 |
| np.float64 | 双精度浮点数数:64位,正负号1位,指数11位,精度52位 |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部 |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部 |
| np.objext_ | python对象 |
| np.string_ | 字符串 |
| np.unicode_ | unicode类型 |
注创建数组的时候指定类型
基础操作
生成元素值为0和1的数组的方法
- 生成全部元素值为0的数组
np.zeros([m,n])
- 生成全部元素值为1的数组
np.ones([m,n])
- 生成对角数组(对角线的地方是1,其余地方是0)
np.eye(m,n)
- 创建方阵对角矩阵
np.eye(n,n)
#可简写为
np.eye(n)
- 从现有数组生成
np.array(数组名)
- 生成固定范围的数组
#生成等间隔的数组
#第一种:数组单个元素值为浮点型
np.linspace(start,end,step)
#第二种:数组单个元素值为整型
np.arange(start,end,step)
- 形状修改
在转换形状的时候,一定要注意数组的元素匹配
只是将形状进行了修改,但并没有将行列进行转换
数组名.reshape([m,n])
若m=-1:表示经过自动计算得到此处的值
- 类型修改
数组名.astype(指定类型)
数组去重
np.unique(数组名)
数组运算
数组的算术运算是元素级别的操作,新的数组被创建并且被结果填充。
| 运算 | 函数 |
|---|---|
| a + b | add(a,b) |
| a - b | subtract(a,b) |
| a * b | multiply(a,b) |
| a / b | divide(a,b) |
| a ** b | power(a,b) |
| a % b | remainder(a,b) |
- 以乘法为例,数组与标量相乘,相当于数组的每个元素乘以这个标量
- 数组按元素相乘
- 使用函数
- 函数还可以接受第三个参数,表示将结果存入第三个参数中
矩阵
- 使用 mat 方法将 2 维数组转化为矩阵
- 也可以使用 Matlab 的语法传入一个字符串来生成矩阵
np.mat(数组名)
- 矩阵乘法
- 矩阵与向量的乘法
A.I表示A矩阵的逆矩阵- 矩阵指数表示矩阵连乘
统计函数
| 方法 | 作用 |
|---|---|
| a.sum(axis=None | 求和 |
| a.prod(axis=None | 求积 |
| a.min(axis=None | 最小值 |
| a.max(axis=None | 最大值 |
| a.argmin(axis=None | 最小值索引 |
| a.argmax(axis=None | 最大值索引 |
| a.ptp(axis=None | 最大值减最小值 |
| a.mean(axis=None | 平均值 |
| a.std(axis=None | 标准差 |
| a.var(axis=None | 方差 |
axis指定维度,当值为-1即为最后一个维度
比较和逻辑函数
| 运算符 | 函数 |
|---|---|
| == | equal |
| != | not_equal |
| > | greater |
| >= | greater_equal |
| < | less |
| <= | less_equal |
- 数组元素的比对,我们可以直接使用运算符进行比较
- 当数组元素较多时,查看输出结果便变得很麻烦,这时我们可以使用**all()**方法,直接比对矩阵的所有对应的元素是否满足条件。
- 使用 any() 来判断数组某个区间的元素是否存在大于 20的元素
IO操作
savetxt 可以将数组写入文件,默认使用科学计数法的形式保存
- 可以通过open方法读取文件,读取的数据按科学计数法表示
- 通过np.loadtxt()方法读取文件,读取的数据是浮点型
Pandas基础
Pandas 基于 NumPy 创建,并纳入了大量库及一些标准的数据模型,提供了大量能使我们快速便捷地处理数据的函数与方法,可以高效的操作大型数据集。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
产生Pandas对象
pandas 中有三种基本结构:
- Series
一维Series可以用一维列表初始化
pd.Series(列表)
默认情况下,Series 的下标都是数字(可以使用额外参数指定),类型是统一的。
- DataFrame
- DataFrame 则是个二维结构,这里首先构造一组时间序列,作为我们第一维的下标,然后创建一个 DataFrame 结构
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns
结果为dates:DatetimeIndex([‘2013-01-01’, ‘2013-01-02’, ‘2013-01-03’, ‘2013-01-04’, ‘2013-01-05’,‘2013-01-06’],dtype=‘datetime64[ns]’,freq=‘D’)
df:
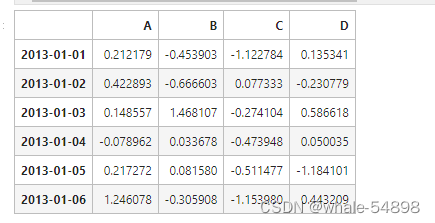
默认情况下,如果不指定 index 参数和 columns,那么他们的值将用从 0 开始的数字替代。
- 除了向 DataFrame 中传入二维数组,我们也可以使用字典传入数据,字典的每个 key 代表一列,其 value 可以是各种能够转化为 Series 的对象。
- 与 Series 要求所有的类型都一致不同,DataFrame 值要求每一列数据的格式相同
- Panal
查看数据
头尾数据
head 和 tail 方法可以分别查看最前面几行和最后面几行的数据(默认为 5)
下标,列标,数据
- 下标使用 index 属性查看
- 列标使用 columns 属性查看
- 数据值使用 values 查看
统计数据
- 查看简单的统计数据
df.describe()
转置
df.T
排序
- sort_index(axis=0, ascending=True) 方法按照下标大小进行排序,axis=0 表示按第 0 维进行排序,ascending的值为True时从小到大排序
- sort_values(by, axis=0, ascending=True) 方法按照 by 的值的大小进行排序
索引
虽然 DataFrame 支持 Python/Numpy 的索引语法,但是推荐使用 .at, .iat, .loc, .iloc 和 .ix 方法进行索引。
读取数据
- 选择单列数据:
df["A"]df.A- 使用切片读取多行
df[0:3] - index名字也可以进行切片
df["20130101":"20130103"]
- 使用label索引
- loc可以方便的使用label进行索引
- 多列数据
- 选择多行多列
- 数据降维
- 得到标量值(也可用at,速度更快)
df.loc[y,x]
df.at[]
- 使用位置索引
- iloc使用位置进行索引
- 连续切片
- 索引不连续的部分
- 索引整行
- 索引整列
- 标量值(使用iat索引更快)
df.iloc[y,x]
df.iat[]
- 布尔索引
#所有列(列标对应的)大于0的行
df[df.列标>0]
#只留下所有大于0的数值
df[df>0]
- 使用isin方法做filter过滤
设定数据的值
- 像字典一样,直接指定某列的值,此时以 df 已有的 index 为标准将二者进行合并,值中没有的 index 项设为 NaN,多余的项舍去
- 使用at或iat修改单个值
- 设定一整列
df.loc[y,x]
缺失数据
- 丢弃所有缺失数据的行得到的新数据
df.dropna(how='any')
- 填充缺失数据
df.fillna(value='值')
- 检查缺失数据的位置
pd.isnull(df)
计算操作
统计信息
- 每一列的均值
df.mean()
- 每一行的均值
df.mean(1)
- 多个对象之间的操作,如果维度不对,pandas 会自动调用 broadcasting 机制
apply操作
- 与 R 中的 apply 操作类似,接收一个函数,默认是对将函数作用到每一列上
直方图
s = pd.Series(np.random.randint(0, 7, size=10))
#直方图信息
s.value_counts()
#绘制直方图信息
h = s.hist()
字符串方法
当 Series 或者 DataFrame 的某一列是字符串时,我们可以用 .str 对这个字符串数组进行字符串的基本操作
合并
连接
- 使用 pd.concat 函数将多个 pandas 对象进行连接
数据库中的join
- merge 可以实现数据库中的 join 操作
append
- 向 DataFrame 中添加行
Grouping
按照某个值进行分类
df.grouby()
改变形状
Stack
- 产生一个多 index 的 DataFrame
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz','foo', 'foo', 'qux', 'qux'], ['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples,names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
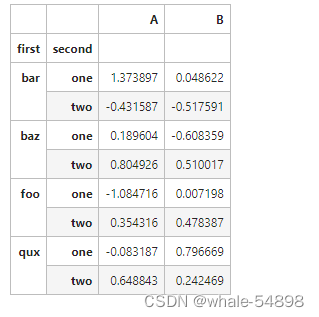
- stack 方法将 columns 变成一个新的 index 部分
df2 = df[:4]
stacked = df2.stack()

- 可以使用 unstack() 将最后一级 index 放回 column
stacked.unstack()
- 也可以指定其他的级别
stacked.unstack(1)
时间序列
- 金融分析中常用到时间序列数据:
rng = pd.date_range('3/6/2012 00:00', periods=5, freq='D')
ts = pd.Series(np.random.randn(len(rng)), rng)
- 标准时间表示:
ts_utc = ts.tz_localize('UTC')
- 改变时区表示
ts_utc.tz_convert('US/Eastern')
CateGoricals
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})
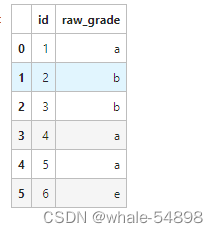
- 将某一列变成类别
df["grade"] = df["raw_grade"].astype("category")
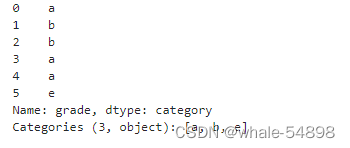
- 将类别的表示转化为有意义的字符
df["grade"].cat.categories = ["very good", "good", "very bad"]

- 添加缺失的类别
df["grade"] = df["grade"].cat.set_categories(["very bad", "bad", "medium", "good", "very good"])

- 使用 grade 分组
df.groupby("grade").size()

绘制
- 使用ggplot风格
plt.style.use('ggplot')
- Series绘图
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
p = ts.cumsum().plot()
- DataFrame按照columns绘图
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index,columns=['A', 'B', 'C', 'D'])
df.cumsum().plot()
p = plt.legend(loc="best")
文件读写
csv
- 写入文件
- 从文件中读取
df.to_csv('foo.csv')
pd.read_csv('foo.csv').head()
excel
- 写入文件
- 读取文件
df.to_excel('foo.xlsx', sheet_name='Sheet1')
pd.read_excel('foo.xlsx', 'Sheet1', index_col=None, na_values=['NA']).head()
- 清理生成的临时文件
import glob
import os
for f in glob.glob("foo*"):
os.remove(f)















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









