






scrapy专利爬虫(一)——scrapy简单介绍
概述
scrapy是一款方便,快捷的开源爬虫框架。
An open source and collaborative framework for extracting the data you need from websites.
In a fast, simple, yet extensible way.
在上一版本中,笔者采用selenium的方式进行数据采集,采集速度偏慢,而且有莫名的原因会导致第一次采集失败。改用scrapy之后,就像鸟枪换大炮一般,效果显著。
特点
- 多线程
尽管python中存在着GIL锁,导致多线程的效果不是特别理想,但是对于网络请求这种本身就需要等待的事件来说,多线程的作用还是非常大的。无需使程序花大量的时间在等待请求反馈上,可以腾出手去处理别的事情。
- 默认自动去掉重复链接
不停地访问一个网站对服务器的压力也是蛮大的,scrapy使用DUPEFILTER_CLASS自动去除重复发送的请求。减轻了爬取对象服务器的压力,也降低了爬虫被发现的风险。
- 简单易用,结构清晰
借用一下官方的图
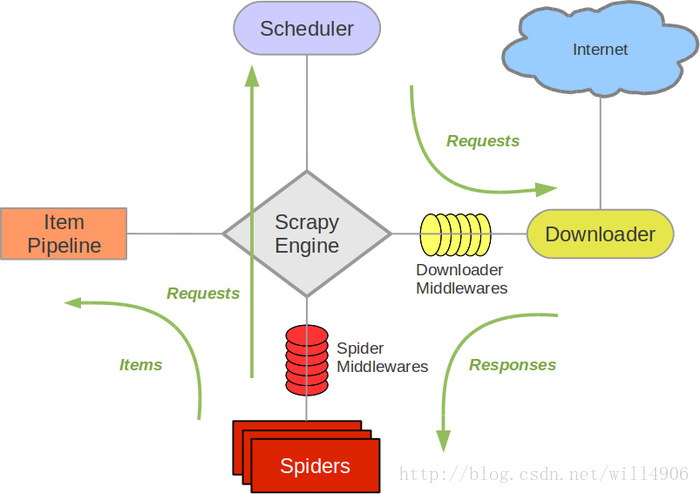
从图上可以看出scrapy分为,item,pipeline,scrapy engine,downloader,spider等几个部分。本项目只使用了一下 item, pipeline,downloader middlewares, spider等一部分组件。对于普通项目,使用这些部分也已经可以满足大部分需求。
安装
笔者只在windows系统中尝试过scrapy,至于其他系统,请自行到查询。
pip install scrapy
使用pip安装即可,但是安装过程中经常会出现各种报错,通常都是以为安装过程中一些库安装不上所致。需要开发者查看安装过程中输出的报错,根据报错再到对应库的官网上将whl文件下载下来,用pip install 将whl文件安装即可。笔者在安装过程中遇到的问题是twisted的库安装不上,下载下来安装后便可正常。
源码下载
| 赞赏 | |
 |  |
| 微信 | 支付宝 |

















 2005
2005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









