









 本文介绍了使用Scrapy框架进行专利信息爬取的实际操作过程,包括确定请求链接、构造请求头及表单数据、发送请求、利用BeautifulSoup解析网页内容等步骤。
本文介绍了使用Scrapy框架进行专利信息爬取的实际操作过程,包括确定请求链接、构造请求头及表单数据、发送请求、利用BeautifulSoup解析网页内容等步骤。
scrapy专利爬虫(三)——简单实际操作
确定链接
在chrome中打开审查元素中的network选项,查看查询专利时发送的请求。观察后发现在每次查询的时候,浏览器都会先发送两条请求给服务器。
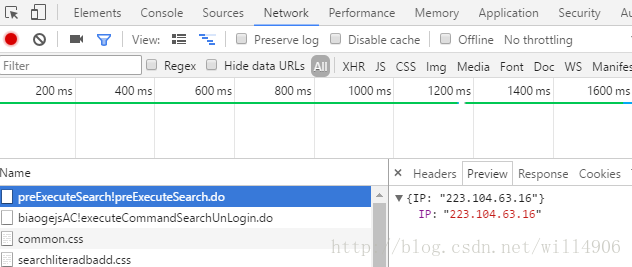
发送相关请求
经过观察发现,网站的查询流程是
- 先发送不带参数的post请求preExecuteSearch!preExcuteSearch.do将ip地址传给服务器
- 然后再发送biaogejsAC!executeCommandSearchUnLogin.do将查询参数发给服务器
填写表单,发送请求
这里只给出一个简单的例子,具体实现见github或代码附件
headers = {
"Content-Type": "application/x-www-form-urlencoded"
}
searchExp = SearchService.getCnSearchExp(self.startDate, proposer, inventor, type)
formData = {
"searchCondition.searchExp": searchExp,
"searchCondition.dbId": "VDB",
"searchCondition.searchType": "Sino_foreign",
"searchCondition.power": "false",
"wee.bizlog.modulelevel": "0200201",
"resultPagination.limit": BaseConfig.CRAWLER_SPEED
}
yield FormRequest(
url="http://www.pss-system.gov.cn/sipopublicsearch/patentsearch/biaogejsAC!executeCommandSearchUnLogin.do",
callback=self.parsePatentList,
method="POST",
headers=headers,
formdata=formData,
meta={
'searchExp': searchExp,
'inventionType': type,
'startDate': self.startDate,
'proposer': proposer,
'inventor': inventor
}
)数据解析
通过观察chrome的Element,可以逐个找出我们所需要的元素,例如:
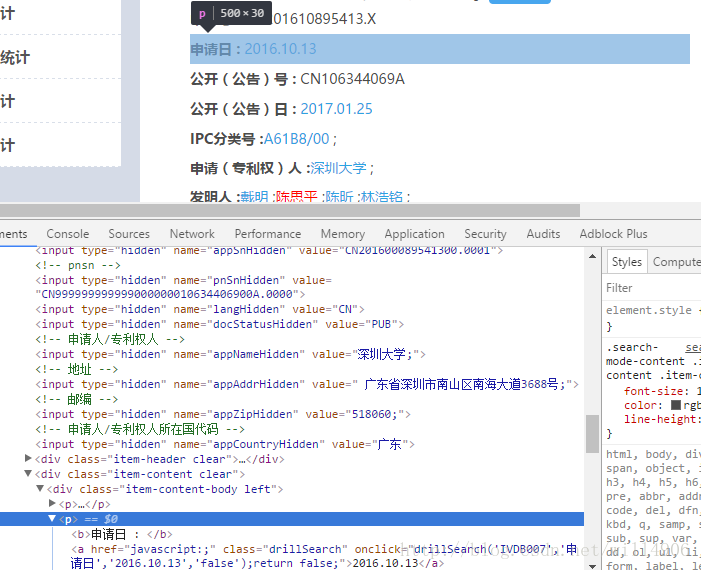
本工程使用beautifulsoup进行解析,对于带class的元素,使用find(attrs={"class": "className"})的方法采集即可,其他参数也类似。这里提供简单的例子
itemSoup = BeautifulSoup(item.prettify(), "lxml")
header = itemSoup.find(attrs={"class": "item-header"})
pi['name'] = header.find("h1").get_text(strip=True)
pi['type'] = header.find(attrs={"class": "btn-group left clear"}).get_text(strip=True)
pi['patentType'] = QueryInfo.inventionTypeToString(type)
content = itemSoup.find(attrs={"class": "item-content-body left"})数据收集
同样的需要对item使用yield,然后将数据传入pipeline中进行处理,关于更多数据处理的详细内容将会在下节内容中介绍。
源码下载
| 赞赏 | |
 |  |
| 微信 | 支付宝 |

















 3492
3492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









