







数据
数据爬虫所得,为安居客广州二手房信息,由于数据量不大,所有分析只是针对这个二手房网站上发布的二手房信息所进行的一些简单分析,不能避免偶然性。本人对房价分析亦没什么了解,以下均只是当作数据分析的练习。下面展示一部分目标文本文件内的数据:
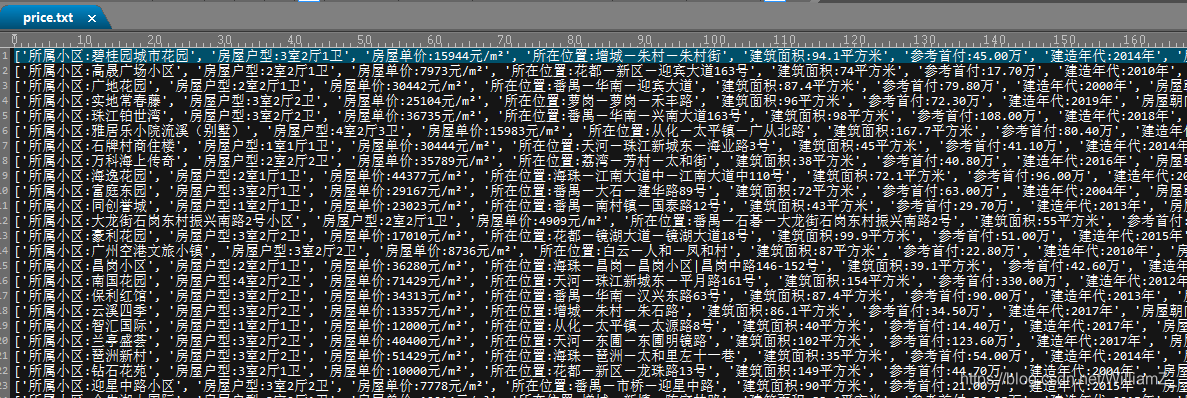
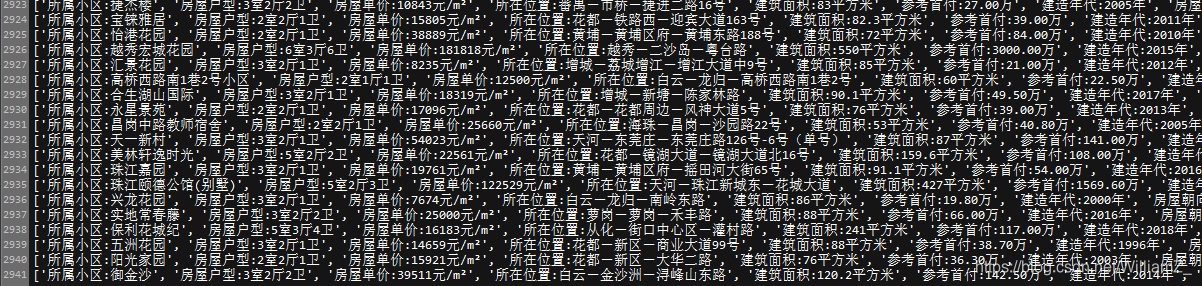
一共有2941条记录。
清洗数据
jupyter notebook 环境下创建python3文件,先用pandas read_csv函数读入文本文件所有内容,默认逗号为分隔符,指定各个字段的名称:
names=[‘小区’,‘户型’,‘房屋单价(元/m²)’,‘位置’,‘面积(平方米)’,‘参考首付(万)’,‘建造年代(年)’,‘朝向’,‘房屋类型’,‘所在楼层’,‘装修程度’,‘产权(年)’,‘电梯’,‘房本年限(年)’,‘产权性质’,‘唯一住房’,‘一手房源’],一共17个字段。

显示读入的数据的数据框前五行:

我们目的只需要每条记录中每个字段冒号后面的内容,以及对于位置字段,我们打算将这个字段分成三个字段,分别为:区域,街道/周边城市,街号,所在楼层字段分成表示高、中、低的所在楼层字段以及表示楼盘共有多少层的层数字段。除了户型字段,其他含有数字的字段均只取数字部分,经过一些列操作,代码如下


经过一系列清洗后,显示数据框前五行:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5559
5559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









