







 本文通过对广州二手房数据的深入分析,揭示了各区域房价差异及影响因素。分析显示,天河、越秀、海珠等地房价较高,地区、装修类型、是否近地铁等显著影响房价。
本文通过对广州二手房数据的深入分析,揭示了各区域房价差异及影响因素。分析显示,天河、越秀、海珠等地房价较高,地区、装修类型、是否近地铁等显著影响房价。
上一篇我们利用了python抓取了链家网广州地区的历史二手房数据,上一篇爬虫文章。这次将如何对数据进行分析。
问题定义
对于数据分析,第一步是定义问题,由于数据的获已经固定,所以问题固定住了是在广州地区二手房的问题上,所以我们有如下的问题:- 广州二手房各地区的房价概况
- 各因素对房价的影响程度
- 给定一定条件后的大概房价是多少
数据预处理
首先将数据从数据库中导出转为csv文件。在Excel中进行数据的清洗,有的时候能用简单的就用简单的方法实现数据清洗,对数据的清洗有以下的几个环节:缺失值的处理
在抓取的原始数据,有一些字段存在着缺失值的情况,对于缺失值的处理通常有利用均值来填充、利用特殊值来填写、临近数值填写、删除元组等处理方式,在此次抓取的过程中,有房屋报价为空的元组、楼层信息未知的元组、对于这些无法获取到的数据做直接删除处理。异常值的处理
对于异常值,在此次数据中,出现了房屋类型是“9室1厅”,“车位”等数据,这些数据显然不是我们所要关系的数据,此次我们直接将房屋类型数据异常的元组作删除处理。还有对于其中的利群点处理,箱线图是一个可以很好的将离群点检测出来的图形,利用Excel画出房屋单价的箱线图,如图所示:   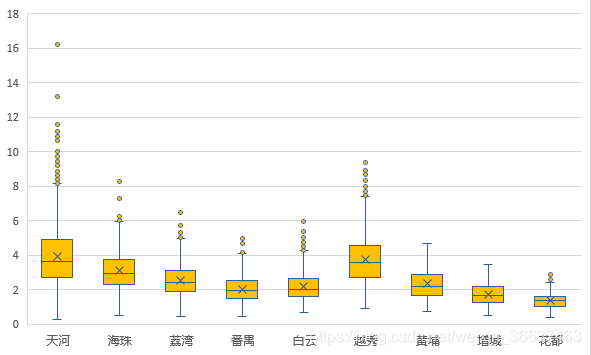
可以看到各个地区的箱体差距大,对于离群点这里也是做简单的删除处理
数据转换
为了方便后续的分析,我们需要对数据进行转换,这里主要是将房屋的类型,地铁电梯等数据做处理。- 将房屋类型转变成两个字段,一个是厅数,一个是房间数。
- 将电梯的有无转变成二分类数据 1 和 0。
数据分析与建模
数据导入
data = pd.read_excel(r'C:\Users\11060\Desktop\house_info.xlsx') # 导入数据
利用pandas将数据导入
描述性统计
首先来看各个地区的房源数量data.house_position.value_counts().plot.pie(autopct='%.2f%%',fontsize=12,figsize=(10,10))
data.house_position.agg(['value_counts']).T
   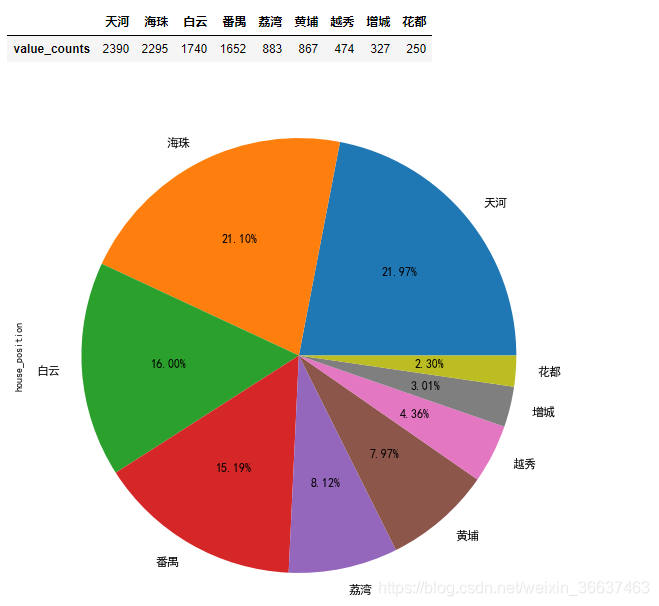
可以看到排在前三的分别是天河、海珠、白云。由于南沙还有从化数量只有个位数在原始数据已经删除了。
接下来看地区因素对房价的影响
data.unit_price.groupby(data.house_position).mean().sort_values(ascending=True).plot(kind='barh')
plt.xlabel('单位房价')
    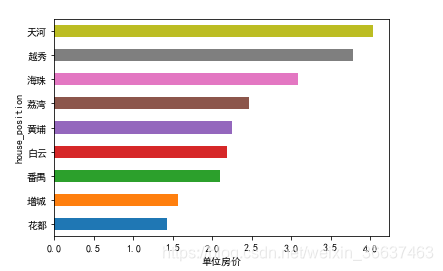
可以看到前三甲分别是天河、越秀、海珠。这样子很难看出什么,我们将它转变成地图,画出地图来更直观
quyu = ['花都区','增城区','番禺区','白云区','黄埔区','荔湾区','海珠区','越秀区','天河区']
danjia = [1.403236,1.561185,2.104040,2.154553,2.244508,2.445613,3.064517,3.689216,3.956770]
map3 = Map("广州单价图", width=1000, height=1000)
map3.add("", quyu, danjia, visual_range=[1, 5], maptype='广州', is_visualmap=True,is_label_show=True,visual_text_color='#000')
map3.render(path="广州地图.html")
    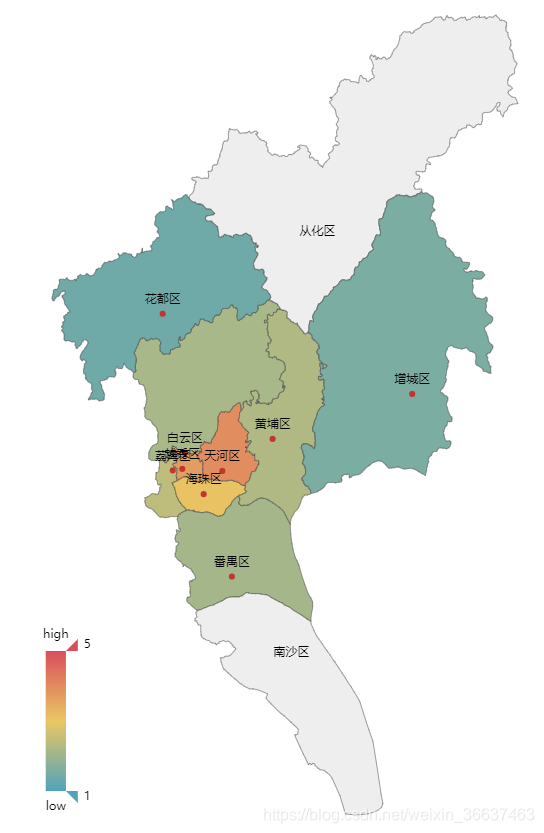
从地图可以很直观的看出,离天河市中心最近的地区颜色越深,也就代表着房屋的单价越高。所以最高的分别是天河、越秀、海珠、荔湾
接下来看其他因素对房价的影响
地铁和电梯因素
data_5 = data[['subway','unit_price']]
data_6 = data[['elevator','unit_price']]
data_5.boxplot(by='subway',patch_artist=True)
plt.xlabel('地铁')
data_6.boxplot(by='elevator',patch_artist=True)
plt.xlabel('电梯')
    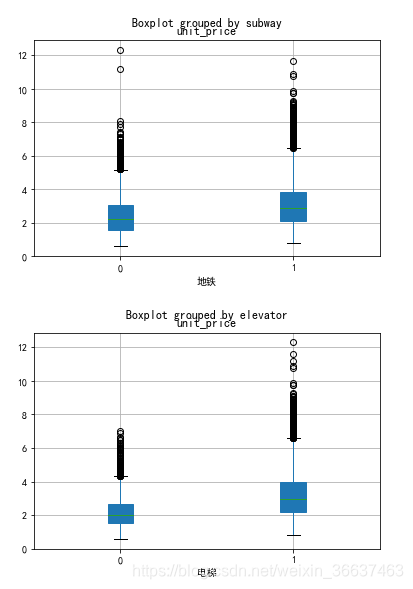
从箱线图的两个箱体的均值差距可以看到地铁和电梯对房价有明显的影响
装修类型因素
data_7 = data[['house_decorate','unit_price']]
data_7.unit_price.groupby(data_7.house_decorate).mean().plot(kind='bar')
plt.xlabel('装修类型')
data_7.boxplot(by='house_decorate',patch_artist=True)
plt.xlabel('装修类型')
    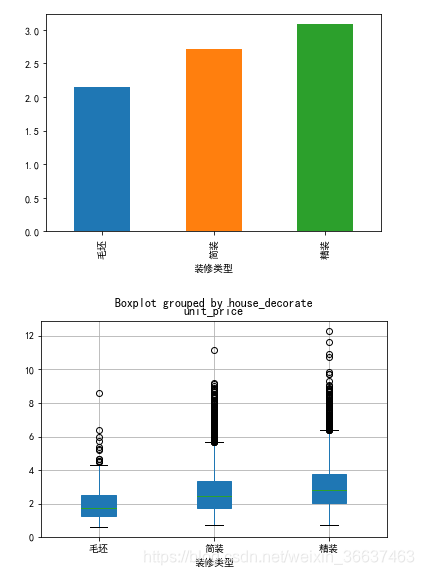
显而易见,装修类型对单价有明显的强相关性
楼层因素
data_4=data[['floor','unit_price']]
data_4.floor=data_4.floor.astype("category")
data_4.floor.cat.set_categories(["低楼层","中楼层","高楼层"],inplace=True)
data_4.sort_values(by=['floor'],inplace=True)
data_4.boxplot(by='floor',patch_artist=True)
plt.xlabel('楼层')
    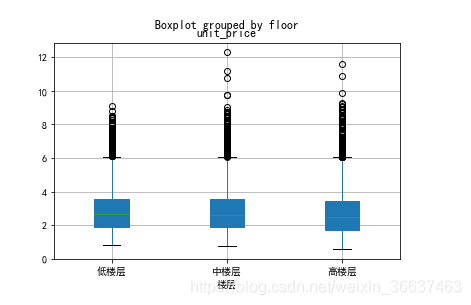
可以看到楼层对单价的影响不显著,三个箱体的均值线几乎都在一条线上
客厅因素
data_3 = data[['keting_num','unit_price']]
data_3.unit_price.groupby(data_3.keting_num).mean().plot(kind='bar')
plt.xlabel('客厅数量')
data_3.boxplot(by='keting_num',patch_artist=True)
plt.xlabel('客厅数量')
    
可以看到客厅数量对房价也有一定的影响
房间因素
data_2 = data[['room_num','unit_price']]
data_2.unit_price.groupby(data_2.room_num).mean().plot(kind='bar')
plt.xlabel('房间数量')
data_2.boxplot(by='room_num',patch_artist=True)
plt.xlabel('房间数量')
    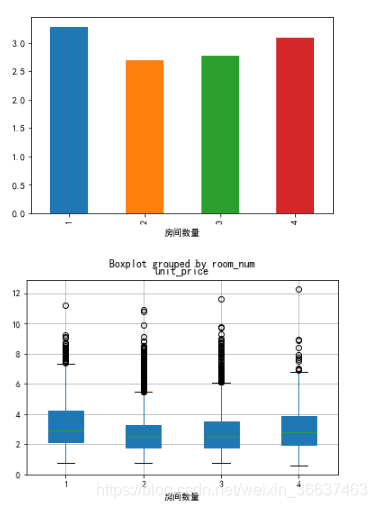
房间的数量和客厅的情况差不多,都是有一定的影响
我们画出房屋单价的QQ图
from scipy.stats import *
from sklearn.preprocessing import StandardScaler
from scipy import stats
sns.distplot(data['unit_price'],fit=norm)
fig = plt.figure()
plt.xlabel('单位单价(万/平方)')
res = stats.probplot(data.unit_price,plot=plt)
plt.show()
    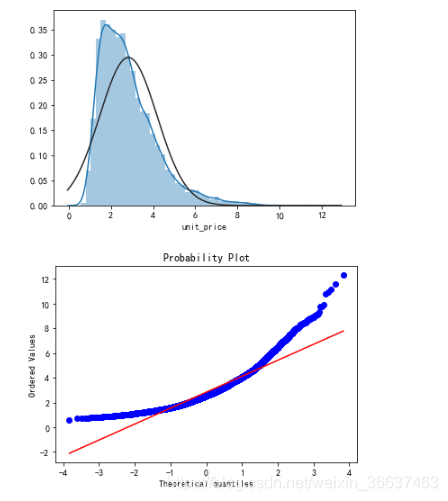
由图可以看到数据呈现最常见的右偏,对于右偏的数据会在后面影响我们的建模,所以在后续的建模我们会做取对数处理。
数据建模
由于在数据量超过5000后,P值会失去意义。所以就统计分析来看应该对数据进行抽样,这里我们使用分层抽样,对数据基于地区这个特征进行分层抽样,每一层抽取200。 对抽取后的数据进行方差分析,分析各个因素与房屋单价的P值:import statsmodels.api as sm
from statsmodels.formula.api import ols
print("house_position的P值为:%.4f" %sm.stats.anova_lm(ols('unit_price ~ C(house_position)',data=data_7).fit())._values[0][4])
print("room_num的P值为:%.4f" %sm.stats.anova_lm(ols('unit_price ~ C(room_num)',data=data_7).fit())._values[0][4])
print("keting_num的P值为:%.4f" %sm.stats.anova_lm(ols('unit_price ~ C(keting_num)',data=data_7).fit())._values[0][4])
print("floor的P值为:%.4f" %sm.stats.anova_lm(ols('unit_price ~ C(floor)',data=data_7).fit())._values[0][4])
print("house_decorate的P值为:%.4f" %sm.stats.anova_lm(ols('unit_price ~ C(house_decorate)',data=data_7).fit())._values[0][4])
print("subway的P值为:%.4f" %sm.stats.anova_lm(ols('unit_price ~ C(subway)',data=data_7).fit())._values[0][4])
print("elevator的P值为:%.4f" %sm.stats.anova_lm(ols('unit_price ~ C(elevator)',data=data_7).fit())._values[0][4])
# 运行结果
house_position的P值为:0.0000
room_num的P值为:0.0000
keting_num的P值为:0.0000
floor的P值为:0.1044
house_decorate的P值为:0.0000
subway的P值为:0.0000
elevator的P值为:0.0000
可以看到各个因素对单价都是有影响的,楼层这个因素不显著,在后续建模会剔除
对楼层、地区、装修类型进行one-hot编码
data_8=pd.get_dummies(data[['house_position','floor','house_decorate']])
data_8.head()
利用statsmodels的ols模型来拟合数据
lm1 = ols("""unit_price ~ + house_position_天河+house_position_海珠+house_position_番禺+house_position_白云
+ house_position_花都+ house_position_荔湾+house_position_越秀+house_position_黄埔+house_decorate_简装+house_decorate_精装
+ elevator+subway+area+room_num+keting_num
""", data=data_9).fit()
lm1_summary = lm1.summary()
lm1_summary
画出拟合模型后的残差图,关于残差图可以查看这篇文章 点这里
data_9['pred1']=lm1.predict(data_9)
data_9['resid1']=lm1.resid
data_9.plot('pred1','resid1',kind='scatter')
    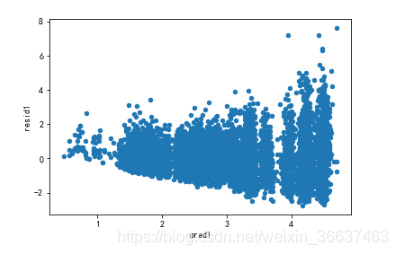
可以看到残差图曾现分散,也就是越往后的数据偏差越大,这是因为我们没有对房屋单价还有面积取对数的原因,接下来取对数
data_9['unit_price_ln'] = np.log(data_9['unit_price']) #对单价取对数
data_9['area_ln'] = np.log(data_9['area'])#对面积取对数
lm2 = ols("""unit_price_ln ~ + house_position_天河+house_position_海珠+house_position_番禺+house_position_白云
+ house_position_花都+ house_position_荔湾+house_position_越秀+house_position_黄埔
+ elevator+subway+area_ln+room_num+keting_num""", data=data_9).fit()
lm2_summary = lm2.summary()
lm2_summary #回归结果展示
同样画出残差图
    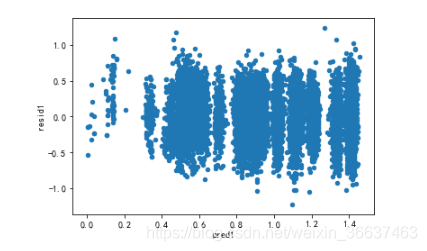
可以看到这次的残差图为标准的残差图。至此模型已经建立完成。
结论
通过分析我们可以对开始提出的问题进行回答- 各地区的房价差异大,其中由大到小的地区分别是天河、越秀、海珠、荔湾、黄埔、白云、番禺、增城、花都。其中最贵的天河均价到达了4w/平,最便宜为花都,均价1.4w/平
- 由方差分析可以看到各个因素对房价都有影响,只有楼层对房价没有影响,而从分组箱线图可以看到地区对单价的影响是最为显著的
- 在给定一定的条件下预测一个大概房价,这里我们预测一个番禺地区、三房一厅、有电梯、有地铁、精装、高楼层的100平的房子,得到的价格如下:
    
至此分析完成。


















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











