







前面的总结三介绍了pandas入门的知识,本文将进一步总结pandas在数据分析中常见的操作。
一、数据清洗与准备
(1)缺失值的检测
isnull():
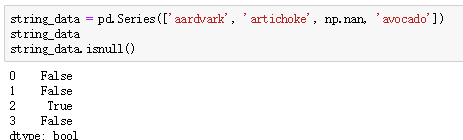
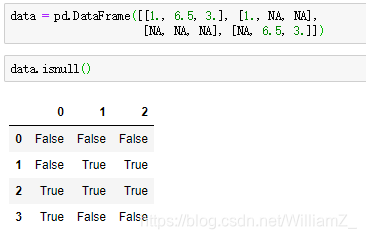
使用any函数直接检测是否存在缺失值,如any(df.isnull()),返回True or False。
notnull:不是缺失值检测,

(2)处理缺失值
一般而言,遇到缺失值时,可采用的三种方法:删除法、替换法、插补法。
删除法: 当缺失的观测比例非常低(如5%以内),直接删除存在缺失值的观测,或者某些变量的缺失比例非常高时(如85%以上),直接删除这些变量。
替换法: 用某种常数直接替换那些缺失值,对于连续变量,可以使用均值或中位数替换,对于离散变量,可以使用众数替换。
插补法: 插补法是根据其他非缺失的变量或观测来预测缺失值,常见的插补法有回归插补法、K近邻插补法、拉格朗日插补法。
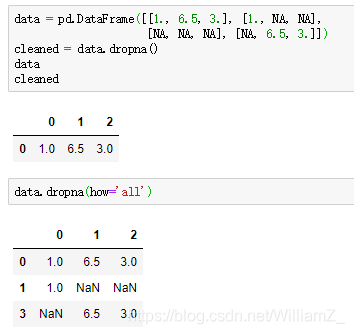
dropna:
subset参数指定需要删除的观测中哪列包含缺失值,若指定的列没有缺失值,没有指定的列存在缺失值的观测不会删除。
how参数为’all’时,删除所有值均为缺失值的行
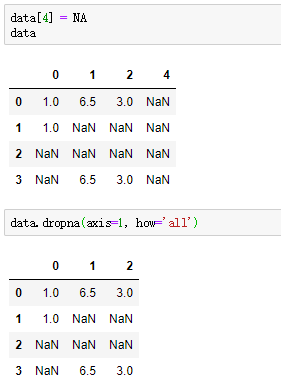
axis参数默认为0,删除缺失值行,设置为1则删除列
inplace参数默认为False,操作不反映到原数据集,设置为True才生效
例:

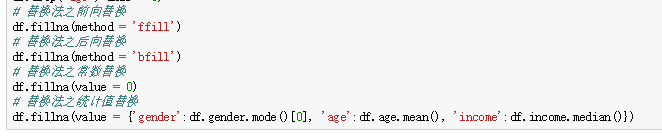
fillna:缺失值填充
inplace参数设置为True才对原数据集生效
limit参数用于前向后向填充时最大的填充范围
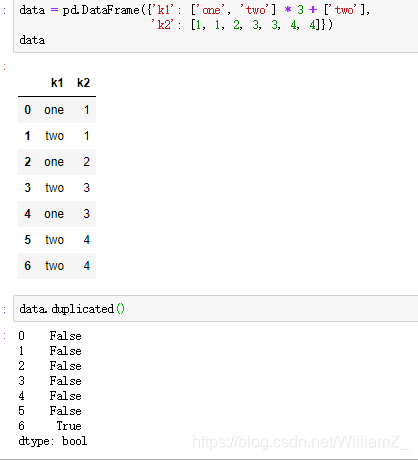
(3)重复观测的检测
duplicated:

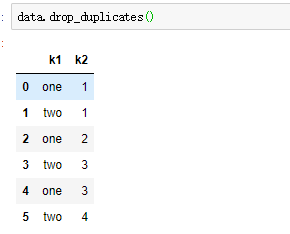
(4)重复观测删除
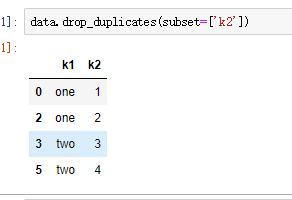
drop_duplicates()
subset参数指定需要删除的观测是关于哪列存在重复值的情况下,默认为全部列
keep参数指定保留第几条重复观测,默认保留第一条,keep='last’则保留最后一条
inplace参数默认为False,设置True才对数据集操作生效
(5)异常值处理
异常值处理一般采用2种方法,一种是n个标准差法,另一种是箱线图判别法。
标准差判断公式为outlinear>|样本均值±n*样本标准差|,当n=2时,为异常值,n=3时为极端异常值。箱线图判断公式outliear>Q3+n*IQR或者outliear<Q1-n*IQR,Q3为上四分位数,Q1为下四分位数,IQR为Q3-Q1,n=1.5,为异常值,n=3,极端异常值;
两种方法选择的标准:如果数据近似正态分布,优先选标准差法,否则选箱线图法
存在异常时,一般使用删除法删除异常值(异常观测比例不大)
替换法:使用低于判别上限的最大值或高于判别下限的最小值替换、使用均值、中位数替换等。
例:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 8358
8358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









