







下载
spark-2.3.2-bin-hadoop2.7.tgz
设置环境变量
![]()
修改配置
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
![]()
注意:由于是On Yarn的配置,无需配置worker、slaves这些
启动
spark-shell

根据启动日志,spark-shell启动的本地模式,不是OnYarn的模式。我们查看Hadoop ResoureManager的界面,没有看到新提交的Application。
OnYarn启动
spark-shell --master yarn --deploy-mode client

见上图,master=yarn,是基于yarn的模式了。
查看Hadoop ResoureManager的界面,可见新提交的Spark shell任务。

补充一:spark on yarn还有cluster模式,--deploy-mode cluster即为cluster模式,二者的差异这里暂不介绍。
补充二:用spark-submit的方式提交spark任务,设置--master yarn即是把spark任务基于yarn进行提交。
程序测试
从如下四个方面进行测试
spark shell执行spark程序
在spark shell环境下输入spark代码,程序如下:
val rdd01 = sc.makeRDD(List(1,2,3,4,5,6))
val r01 = rdd01.map { x => x * x }
println(r01.collect().mkString(","))

看上图,程序执行成功。
spark shell操作hive表
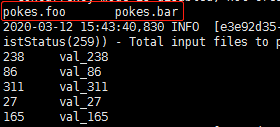
如上是hive default库中的pokes表,先再hive中查看一下,等下会用到。
程序如下:
val sqldf = spark.sql("SELECT * FROM default.pokes")
sqldf.show()
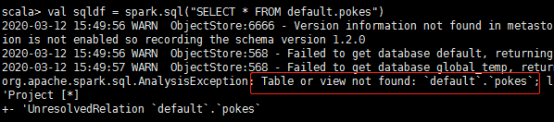
报错,table not found
解决方案:
配置spark读写hive。拷贝hive_home/conf/hive-site.xml 到spark_home/conf/目录下。否则,spark读写的hive仓库和hive自己读写的是独立的。
Mysql的驱动包,也拷到spark_home/jars/目录下
cp mysql-connector-java-5.1.39.jar spark_home/jars/
修改完成,重启spark shell --master yarn,再执行程序。
程序执行成功

默认显示了20条数据。如此spark可以正常访问hive数据。
spark-submit提交任务到yarn
找到官网的例子,在spark_home下执行,命令如下:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.2.jar \
10
一会后,执行完成。

查看ResourceManager的页面
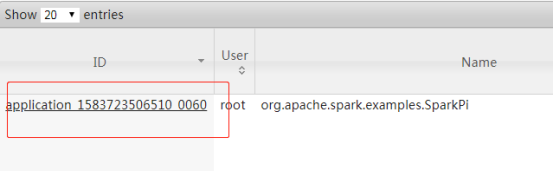
spark-submit提交任务到yarn成功!
spark-submit自定义spark程序
我的程序:

程序很简单,从hive中读取一张表,进行groupBy计算,并将结果存入一张新表。把程序打包,生成yss_bi_spark-1.0.jar。
spark-submit命令如下:
./bin/spark-submit \
--class com.yss.HelloSpark \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
myjar/yss_bi_spark-1.0.jar
程序报错了:table or view not found
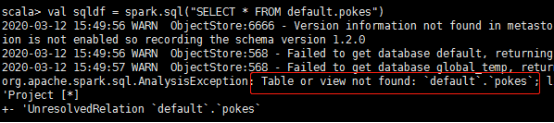
报如上错误的一般原因就是当前应用程序找不到hive-site.xml的配置,以致于读取hive table失败。
针对spark访问hive表table or view not found的问题,有好几种解决方案,一般来说任选其一都是可以的。
解决方案如下:
方案一:将hive/conf/hive-site.xml拷贝到spark/conf/下。很明显,这个步骤之前就做过。
方案二:在spark-submit命令中添加--file的参数配置,指定XML所在的地址,例如:
./bin/spark-submit --files /home/root/app/spark-2.3.2/conf/hive-site.xml ......
方案三:在你的project中添加hive-site.xml,打包进jar。
一般在src/main/resource添加hive-site.xml,maven执行package操作,默认会自动将XML配置打包到jar的根目录下。
结果如上三种方法,我都试了,还是报错table or view not found的问题。
方案四:检查代码
发现我用sparksession类生成spark对象时,少了enableHiveSupport()方法。
在官网上查看下spark操作hive的代码。
Spark2.3.2
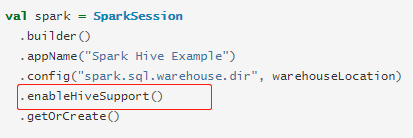
需要加enableHiveSupport()这一段。
Spark1.6.1

经对比,版本升级后,Spark2.x操作hive发生了变化。修改代码之后,方案二、方案三都不再需要尝试了。
注意:不要盲目自信,首先请检查代码的正确!
完毕,SparkOnYarn可以正常使用。















 1765
1765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









