







因为C语言不检查数组越界,而数组又是我们经常用的数据结构之一,所以程序中经常会遇到数组越界的情况,并且后果轻者读写数据不对,重者程序crash。下面我们来分析一下数组越界的情况:
结合我的另外一篇文章 C语言的内存管理 http://blog.csdn.net/wind19/archive/2010/10/25/5964090.aspx
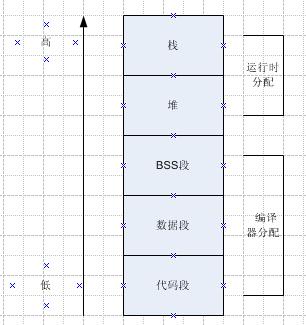
1) 堆中的数组越界
因为堆是我们自己分配的,如果越界,那么会把堆中其他空间的数据给写掉,或读取了其他空间的数据,这样就会导致其他变量的数据变得不对,如果是一个指针的话,那么有可能会引起crash
2) 栈中的数组越界
因为栈是向下增长的,在进入一个函数之前,会先把参数和下一步要执行的指令地址(通过call实现)压栈,在函数的入口会把ebp压栈,并把esp赋值给ebp,在函数返回的时候,将ebp值赋给esp,pop先前栈内的上级函数栈的基地址给ebp,恢复原栈基址,然后把调用函数之前的压入栈的指令地址pop出来(通过ret实现)。
栈是由高往低增长的,而数组的存储是由低位往高位存的,如果越界的话,会把当前函数的ebp和下一跳的指令地址覆盖掉,如果覆盖了当前函数的ebp,那么在恢复的时候esp就不能指向正确的地方,从而导致未可知的情况,如果下一跳的地址也被覆盖掉,那么肯定会导致crash。
-------------------------
压入的参数和函数指针
-------------------------
aa[4]
aa[3]
合法的数组空间 aa[2]
aa[1]
aa[0]
-------------------------
###sta.c###
#include <stdio.h>
void f(int ai)
{
int aa[5]={1,2,3};
int i = 1;
for (i=0;i<10;i++)
aa[i]=i;
printf("f()/n");
}
void main()
{
f(3);
printf("ok/n");
}
###sta.s###
.file "sta.c" ;说明汇编的源程序
.section .rodata ;说明以下是只读数据区
.LC0:
.string "f()" ;"f()" 的类型是string,地址为LC0
.text ;代码段开始
.globl f ;f为全局可访问
.type f, @function ; f是函数
f:
pushl %ebp
movl %esp, %ebp
subl $40, %esp
movl $0, -24(%ebp)
movl $0, -20(%ebp)
movl $0, -16(%ebp)
movl $0, -12(%ebp)
movl $0, -8(%ebp)
movl $1, -24(%ebp)
movl $2, -20(%ebp)
movl $3, -16(%ebp)
movl $1, -4(%ebp)
movl $0, -4(%ebp)
jmp .L2
.L3:
movl -4(%ebp), %edx
movl -4(%ebp), %eax
movl %eax, -24(%ebp,%edx,4)
addl $1, -4(%ebp)
.L2:
cmpl $9, -4(%ebp)
jle .L3
movl $.LC0, (%esp)
call puts
leave
ret
.size f, .-f ;用以计算函数f的大小
.section .rodata
.LC1:
.string "ok"
.text
.globl main
.type main, @function
main:
leal 4(%esp), %ecx
andl $-16, %esp
pushl -4(%ecx)
pushl %ebp
movl %esp, %ebp
pushl %ecx
subl $4, %esp
movl $3, (%esp)
call f
movl $.LC1, (%esp)
call puts
addl $4, %esp
popl %ecx
popl %ebp
leal -4(%ecx), %esp
ret
.size main, .-main
.ident "GCC: (GNU) 4.1.2 20070115 (SUSE Linux)" ;说明是用什么工具编译的
.section .note.GNU-stack,"",@progbits
从main函数开始压入f函数的参数开始,堆栈的调用情况如下
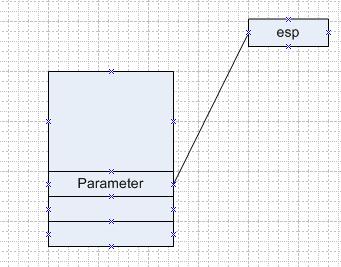
图1 压入参数
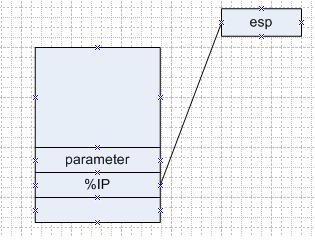
图二 通过call 命令压入下一跳地址 IP
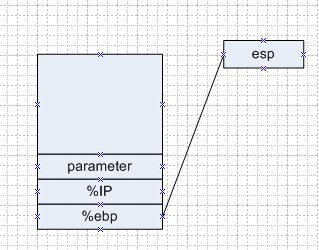
图三 函数f 通过pushl %ebp 把 ebp保存起来
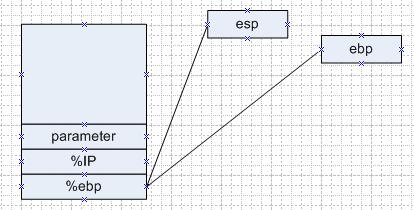
图四 函数 f 通过movl %esp, %ebp让ebp指向esp,这样esp就可以进行修改,在函数返回的时候用ebp的值对esp进行恢复
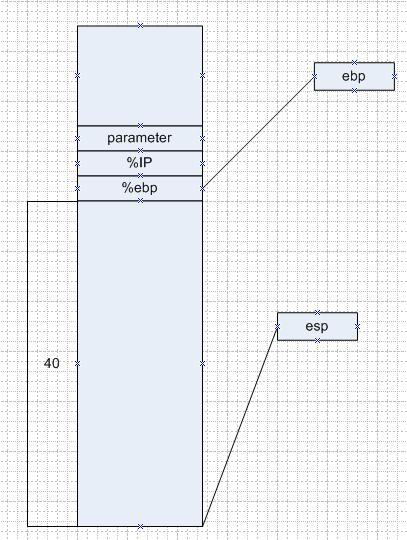
图五 函数 f 通过subl $40, %esp 给函数的局部变量预留空间

图六 int数组 aa[5]占用了20个字节的空间,然后 int i占用了4个字节的空间(紧邻着之前压入栈的%ebp)
故,如果aa[5]进行赋值,则会把 i 的值覆盖掉,
如果对aa[6]进行赋值,则会把 栈中的 %ebp 覆盖掉,那么在函数 f 返回的时候则不能对ebp进行恢复,即main函数的ebp变成了我们覆盖掉的值,程序不知道会发生什么事情,但因为我们的程序接下来没有调用栈中的内容,故还是可以运行的。
如果对aa[7]进行赋值,则会把栈中的 %IP 覆盖掉,在函数 f 返回的时候就不能正确地找到下一跳的地址,会crash
对于汇编代码中
leave ; 将ebp值赋给esp,pop先前栈内的上级函数栈的基地址给ebp,恢复原栈基址
ret ; main函数返回,回到上级调用,隐含了pop %eip操作,返回值由%eax带回
推荐文章 http://bbs.bccn.net/thread-106533-1-1.html















 2777
2777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









