







Value-Based
DQN(Deep Q-Learning Network)
Paper : Playing Atari with Deep Reinforcement Learning
Q-Learning与Deep Neural Network的结合
在前述的Q-Learning算法中,我们需要维护两张核心表,R表与Q表,它们的行为状态,列为行为。而在Flappy Bird游戏中,我们采用游戏实时的画面图片作为状态,而游戏画面图片的像素矩阵格式为80x80,每一个像素又有256种不同的可能,那么一张图片就有 25 6 80 × 80 256^{80×80} 25680×80种状态,再加上Flappy Bird中“Bird”的两种行为,若单纯使用Q-Learning,则我们需要维护两张大小为 ( 2 × 256 ) 80 × 80 (2×256)^{80×80} (2×256)80×80的R表与Q表,无论是维护表格,还是查表,代价都是很大的。
而卷积神经网络的出现则打破了这一僵局,我们可以直接输入卷积神经网络当前的游戏图片(即当前的状态),让其直接生成Q值。那么,如何从游戏中合理地获取到训练模型所需要的数据呢?DQN中使用了Google DeepMind团队提出的深度强化学习的全新训练方法:经验回放。
经验回放(Experience Replay)
假设当前时刻游戏的状态为 s t s_t st,当前时刻“Bird”作出的行为为 a t a_t at,“Bird”作出该行为后获得直接奖励(即R值)为 r t r_t rt,“Bird”作出行为 a t a_t at之后的下一个游戏状态为 s t + 1 s_{t+1} st+1。
- 在DQN的训练开始之前,会对游戏进行观察(Observe)。在观察阶段,会用随机值初始化游戏刚开始所采取的行为,如 [ 0 , 1 ] [0,1] [0,1]或 [ 1 , 0 ] [1,0] [1,0]这样的独热码形式来表示所采取的动作是“跳跃”还是“无操作”。然后将初始行为输入游戏的执行接口中,该接口会按序返回游戏执行该动作后的状态、即时奖励以及游戏是否结束的布尔值,将第一次返回的状态作为初始状态后开始正式观察阶段,不断向上述的卷积神经网络输入新的游戏状态并生成预测的Q值,根据Q值选取选择效益最大行为,再将行为输入游戏接口获取到新状态、即时奖励、游戏结束标志,不断如此循环直到观察阶段结束。注意此时卷积神经网络并没有进行更新参数,观察阶段只是用初始化参数进行预测Q值并收集样本而已。
在 t t t时刻,“Bird”作出动作 a t a_t at之后,产生的样本记为 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1),并将该样本保存在经验池(双向队列)当中。也就是说,经验池中保存着“Bird”曾经的经历,当我们需要对该智能体进行训练时,便从经验池中随机抽样,取出一个批次(batch)的样本,然后进行训练。
- 如果不使用经验回放,在训练过程中直接使用游戏接口返回的连续数据,会造成样本之间具有非常强的相关性。如果用这些强相关性的样本进行训练,卷积神经网络甚至会“记住”这些样本的前后出现顺序,造成过拟合,这对卷积神经网络的训练是非常不利的。所以DQN使用了经验回放,在训练开始之前将所需的样本收集完成存分在经验池中,在训练开始之后从经验池中随机选取样本,破坏样本的相关性以及连续性,使得训练更加有效。
参数化逼近(Fixed Q-Target)
有了经验池存储的样本之后就可以开始进行下一步的训练了。但是我们输入卷积神经网络的是当前的状态,输出的是预测的Q值,并没有一个标准的Q值作为真实值,那么我们就无法通过建立损失函数并执行反向传播与梯度下降算法进行神经网络参数的不断优化了。
- 在Q-Learning算法中我们是根据如下贝尔曼公式来更新Q值的:
Q ( s , a ) = R ( s , a ) + γ ⋅ max a ~ { Q ( s ~ , a ~ ) } Q(s,a)=R(s,a)+ γ·\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a})\} Q(s,a)=R(s,a)+γ⋅a~max{Q(s~,a~)}
借鉴这种方式,我们在DQN中也应该使用卷积神经网络来计算出标准的Q值,即标准Q值由即时奖励与下一状态的Q值加权和构成。但是这会带来一个问题——标准Q值与预测Q值都使用了同一个神经网络,每次更新神经网络参数时,标准Q值也就随之更新了,这样“标准”也就没有意义了,容易导致模型参数无法收敛。因此,DQN在原先的卷积神经网络的基础上又引入了一个Fixed Q-Target 网络,即专门用来计算标准Q值的网络。它和预测Q值的卷积神经网络的结构与初始权重是一模一样的,唯一不同的是Q-Target网络的参数滞后更新。也就是说将预测Q网络当作训练网络,不断更新参数,每隔一段时间(TimeStep)后,用预测Q网络的参数去覆盖Q-Target网络的参数。
基于上述思想,我们将DQN中的标准Q值、预测Q值记为:
Q
t
a
r
g
e
t
=
R
(
s
,
a
)
+
γ
⋅
max
a
~
{
Q
(
s
~
,
a
~
∣
θ
i
−
1
)
}
Q_{target}=R(s,a)+ γ·\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a}|θ_{i-1})\}
Qtarget=R(s,a)+γ⋅a~max{Q(s~,a~∣θi−1)}
Q
p
r
e
d
i
c
t
=
Q
(
s
,
a
∣
θ
i
)
Q_{predict} = Q(s,a|θ_i)
Qpredict=Q(s,a∣θi)
其中, Q ( s , a ∣ θ i ) Q(s,a|θ_i) Q(s,a∣θi)表示用当前的网络参数去预测Q值, Q ( s ~ , a ~ ∣ θ i − 1 ) Q(\tilde{s},\tilde{a}|θ_{i-1}) Q(s~,a~∣θi−1)表示用旧网络参数去逼近标准Q值。
基于上述算法,我们现在可以建立损失函数:
L = ∑ i = 1 n ( Q t a r g e t − Q p r e d i c t ) 2 n L = \frac{\sum\limits_{i=1}^{n}{(Q_{target} - Q_{predict})^2}}{n} L=ni=1∑n(Qtarget−Qpredict)2
其中,n表示样本个数。
调参
在实验时,最开始使用了经验参数GAMMA=0.99、LR=1e-6这个值,效果非常的差,模型非常难收敛。
-
根据前述算法,在DQN中,目标Q值是根据以下公式得出的:
Q t a r g e t = R ( s , a ) + γ ⋅ max a ~ { Q ( s ~ , a ~ ∣ θ i − 1 ) } Q_{target}=R(s,a)+ γ·\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a}|θ_{i-1})\} Qtarget=R(s,a)+γ⋅a~max{Q(s~,a~∣θi−1)}
其中 γ γ γ就是经验参数GAMMA。 -
γ ⋅ max a ~ { Q ( s ~ , a ~ ∣ θ i − 1 ) } γ·\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a}|θ_{i-1})\} γ⋅a~max{Q(s~,a~∣θi−1)}这一项代表了当前状态下选择的行为对下一个状态的影响程度,所以 γ γ γ就控制了这个影响程度的大小。正因为如此,当 γ γ γ取值非常接近于1时,就表明模型不仅需要关注当前状态的奖励值,还要更多的关注该步行为对后续几步(窗口期)行为的影响,这就导致了模型很难收敛。
-
其实该式也运用了指数衰减的思想,如果把 γ ⋅ max a ~ { Q ( s ~ , a ~ ∣ θ i − 1 ) } γ·\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a}|θ_{i-1})\} γ⋅a~max{Q(s~,a~∣θi−1)}用 Q t a r g e t Q_{target} Qtarget递归代入,那么当前行为的Q值就考虑到了往后无限多步的大小,这种大小程度会随时间不断缩小,如下公式所示:
Q t a r g e t = ( 1 + γ + γ 2 + ⋯ + γ n ) R ( s , a ) + γ n + 1 max a ~ { Q ( s ~ , a ~ ∣ θ i − 1 ) } Q_{target} = (1 + γ + γ^2 +⋯+ γ^n)R(s,a) + γ^{n+1}\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a}|θ_{i-1})\} Qtarget=(1+γ+γ2+⋯+γn)R(s,a)+γn+1a~max{Q(s~,a~∣θi−1)}
其中, n n n表示当前状态之后的 n n n步。该式说明了 γ γ γ控制了一个衰减窗口期,其值越大,窗口期越长,模型在一次迭代中就需要学习当前行为对往后窗口期中的多步造成的影响,所以更难学习,更难收敛。 -
GAMMA = 0.9、LR = 1e-4是一个比较好的组合。训练到后期再将学习率衰减10倍变为LR = 1e-5。
Double DQN(DDQN)
Paper : Deep Reinforcement Learning with Double Q-learning
解决Overestimate
-
Overestimate:DQN的这种Max更新方式,Select Action和Evaluate Action都是用同一个Model Value,容易造成Overoptimistic Value Estimate。而DDQN将Action Select和Action Evaluate分开,分别用两个Model Value进行计算,一定程度上避免Overestimate
-
Natural DQN:使用 Q T a r g e t Q_{Target} QTarget计算出状态 S t + 1 S_{t+1} St+1的最大Q值
Y t D Q N ≡ R t + 1 + γ max a Q ( S t + 1 , a ; θ t − ) \bm{ Y_{t}^{\mathrm{DQN}} \equiv R_{t+1}+\gamma \max _{a} Q\left(S_{t+1}, a ; \boldsymbol{\theta}_{t}^{-}\right) } YtDQN≡Rt+1+γamaxQ(St+1,a;θt−)
- Double DQN:先使用 Q P r e d i c t Q_{Predict} QPredict计算出 S t + 1 S_{t+1} St+1所对应最大Q值的行为 a a a,然后再用 Q T a r g e t Q_{Target} QTarget计算 Q ( S t + 1 , a ) Q(S_{t+1}, a) Q(St+1,a)的值
Y t DoubleQ ≡ R t + 1 + γ Q ( S t + 1 , argmax a Q ( S t + 1 , a ; θ t ) ; θ t ′ ) \bm{ Y_{t}^{\text {DoubleQ }} \equiv R_{t+1}+\gamma Q\left(S_{t+1}, \underset{a}{\operatorname{argmax}} Q\left(S_{t+1}, a ; \boldsymbol{\theta}_{t}\right) ; \boldsymbol{\theta}_{t}^{\prime}\right) } YtDoubleQ ≡Rt+1+γQ(St+1,aargmaxQ(St+1,a;θt);θt′)
-
一个能显示出Overestimate的简单例子:当环境由某一状态转换成终态时,最标准的 Q T a r g e t Q_{Target} QTarget应为:
r e w a r d + γ ∗ max a Q ( s ′ , a ′ ) = 0 + γ ∗ 0 \bm{ reward + \gamma * \max\limits_{a}Q(s^{'},a^{'}) = 0 + \gamma * 0 } reward+γ∗amaxQ(s′,a′)=0+γ∗0
但是实际上用DQN的更新方式计算出的 Q T a r g e t Q_{Target} QTarget基本是不为零的(因为更新公式中选取了神经网络输出的最大的那个Q值, max a Q ( s ′ , a ′ ) \max\limits_{a}Q(s^{'},a^{'}) amaxQ(s′,a′)肯定会大于0,总体肯定也大于0)。而采用DDQN的更新方式以后,用当前拥有最新参数的 Q P r e d i c t Q_{Predict} QPredict选取出使 Q ( s ′ , : ) Q(s^{'}, :) Q(s′,:)最大的行为 a a a,再利用 Q T a r g e t Q_{Target} QTarget去计算Q值,这样就在一定程度上(有概率)避免了DQN那种更新方式选取到最大的Q值- 换一个角度,DQN的更新方式一定会选到 Q T a r g e t ( s ′ , : ) Q_{Target}(s^{'}, :) QTarget(s′,:)的最大值,而DDQN的更新方式由于先采用 Q P r e d i c t Q_{Predict} QPredict计算出行为 a a a,再代入到 Q T a r g e t Q_{Target} QTarget中计算 Q T a r g e t ( s ′ , a ) Q_{Target}(s^{'}, a) QTarget(s′,a)的值,又因为 Q T a r g e t ( s ′ , a ) Q_{Target}(s^{'}, a) QTarget(s′,a)不一定等于 max Q T a r g e t ( s ′ , : ) \max Q_{Target}(s^{'}, :) maxQTarget(s′,:),也就是说由 Q P r e d i c t Q_{Predict} QPredict选出的行为 a a a并不一定是能使 Q T a r g e t Q_{Target} QTarget最大的那个行为,这样的话按照期望来说,DDQN的估计值就比DQN要“保守”(小)一些,缓解了Overestimate的问题
Prioritized DQN
Paper : Prioritized Experience Replay
Prioritized DQN
-
提出原因:在Natural DQN训练时,会从Experience Replay Memory中随机采样一个批次的样本。对于一些Sparse Reward的场景,这种方式很难采样到那些产生有效Reward的样本,造成训练速度缓慢,效果不好等负面效果
-
Prioritized DQN根据 T D − e r r o r ( Q T a r g e t − Q P r e d i c t ) TD-error(Q_{Target} - Q_{Predict}) TD−error(QTarget−QPredict)对经验池中的每个样本赋予一个优先级 p p p,每次训练时根据Sum-Tree选取样本,且每次训练时根据即时计算出的 T D − e r r o r TD-error TD−error更新经验池中样本的优先级
-
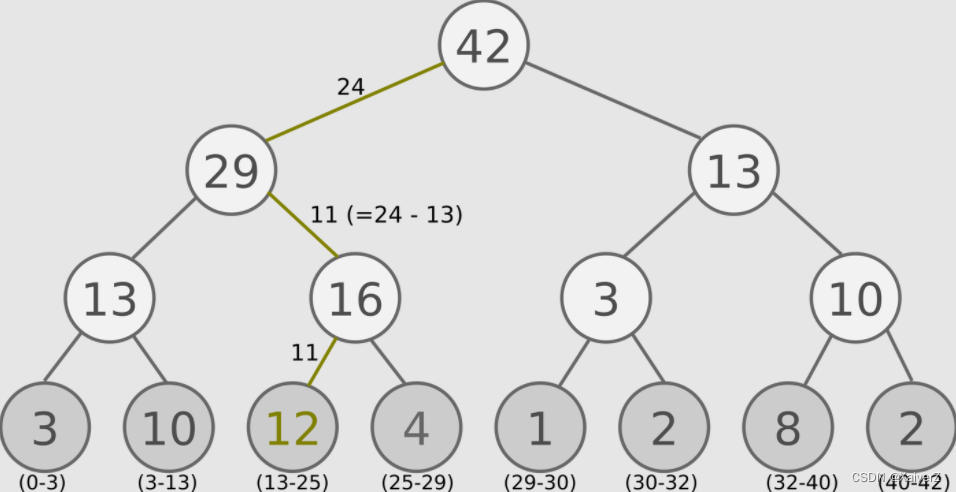
Sum-Tree
-
在[0, 42]随机采样,例如采样到24,则沿图中所示路径往下查找(注意这里采样的24不是指查找优先级为24的叶节点,而是找到图下方所示的优先级区间对应的叶节点)
-
优先级越高的叶节点所对应的优先级区间也就越大,被采样到的概率也就越高
-
Dueling DQN
Paper : Dueling Network Architectures for Deep Reinforcement Learning
Dueling DQN(没太看懂,原论文完整看一遍)
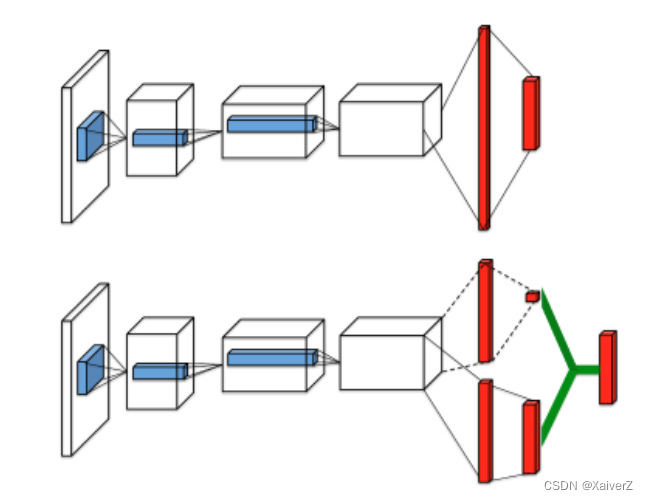
- Dueling DQN将Q值分解为V和A两部分,V(Value function)代表状态的重要性程度,A(Advantage function)代表该状态下各行为的重要性程度
Q ( s , a ; θ , α , β ) = V ( s ; θ , β ) + A ( s , a ; θ , α ) Q(s, a ; \theta, \alpha, \beta)=V(s ; \theta, \beta)+A(s, a ; \theta, \alpha) Q(s,a;θ,α,β)=V(s;θ,β)+A(s,a;θ,α)
- 但上述公式存在Unidentifiable Problem,即V与A的组合有无数多种,无法体现出V与A的独立性。
Q ( s , a ; θ , α , β ) = V ( s ; θ , β ) + ( A ( s , a ; θ , α ) − 1 ∣ A ∣ ∑ a ′ A ( s , a ′ ; θ , α ) ) \begin{aligned} &Q(s, a ; \theta, \alpha, \beta)=V(s ; \theta, \beta)+ \\ &\quad\left(A(s, a ; \theta, \alpha)-\frac{1}{|\mathcal{A}|} \sum_{a^{\prime}} A\left(s, a^{\prime} ; \theta, \alpha\right)\right) \end{aligned} Q(s,a;θ,α,β)=V(s;θ,β)+(A(s,a;θ,α)−∣A∣1a′∑A(s,a′;θ,α))
- 上式将A强制做了均值归一化,使某一状态下的A值之和为0,加强V与A的关联性
A3C with DQN(Multi-Step Learning)
Paper : Asynchronous Methods for Deep Reinforcement Learning
Paper : Rainbow: Combining Improvements in Deep Reinforcement Learning
A3C with DQN(Multi-Step Learning)
Distributional DQN
Paper : A Distributional Perspective on Reinforcement Learning
Distributional DQN
Noisy DQN
Paper : NOISY NETWORKS FOR EXPLORATION
Noisy DQN
Rainbow DQN
Paper : Rainbow: Combining Improvements in Deep Reinforcement Learning
Rainbow DQN















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









