







CS224W: Machine Learning with Graphs
Stanford / Winter 2021
03-nodeemb
-
Why Embedding ?
Task: map nodes into an embedding space
-
Similarity of embeddings between nodes indicates their similarity in the network
-
Encode network information
-
Potentially used for many downstream predictions
-
Node Embeddings: Encoder and Decoder
ENC and DEC
-
Assume we have a graph G G G
-
V V V is the vertex set
-
A A A is the adjacency matrix (assume binary)
-
For simplicity: no node features or extra information is used
-
-
Goal: Encode nodes so that similarity in the embedding space (e.g. dot product) approximates similarity in the graph
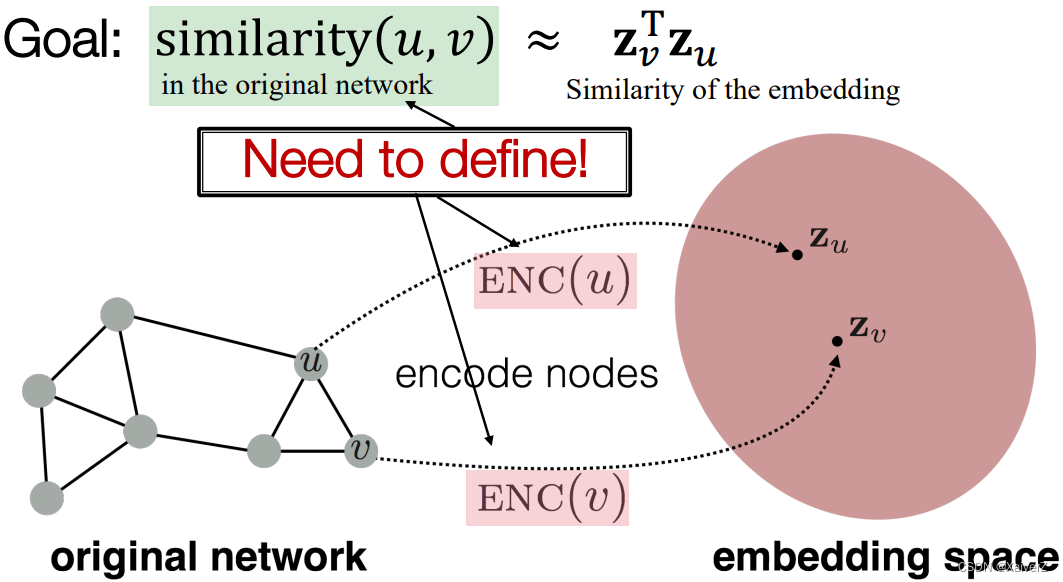
-
How to learn node embeddings ?
-
Encoders (ENC) maps from nodes to embeddings
-
Define a node similarity function (i.e. a measure of similarity in the original network)
-
Decoder (DEC) maps from embeddings to the similarity score
-
Optimiza the parameters of the encoder so that
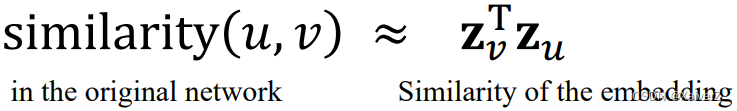
-
-
Two Key Components
-
Encoder: maps each node to a low-dimensional vector
ENC ( v ) = z v \operatorname{ENC}(v)=\mathbf{z}_{v} ENC(v)=zv
-
Decoder (Similarity Function): specifies how the relationships in vector space map to the relationship in the original network (向量空间中的关系如何映射成原图上的关系)
similarity ( u , v ) ≈ z v T z u \operatorname{similarity}(u, v) \approx \mathbf{z}_{v}^{\mathrm{T}} \mathbf{z}_{u} similarity(u,v)≈zvTzu
-
-
Note on Node Embeddings
-
This is unsupervised/self-supervised way of learning node embeddings
-
Not utilizing node labels
-
Not utilizing node features
-
Goal is to directly estimate a set of coordinates (e.g. the embedding) of a node so that some aspect of the network structure is preserved
-
-
These embeddings are task independent
- They are not trained for a specific task but can be used for any task
-
“Shallow” Encoding
“Shallow” Encoding
-
Simplest encoding approach: Encoder is just an embedding-lookup
ENC ( v ) = z v = Z ⋅ v \operatorname{ENC}(v)=\mathbf{z}_{v}=\mathbf{Z} \cdot v ENC(v)=zv=Z⋅v
Z ∈ R d × ∣ V ∣ \mathbf{Z} \in \mathbb{R}^{d \times|\mathcal{V}|} Z∈Rd×∣V∣: matrix, each column is a node embedding (exactly what we learn and optimize); v ∈ I ∣ V ∣ v \in \mathbb{I}^{|\mathcal{V}|} v∈I∣V∣: indicator vector, all zeroes except a one in column indicating node v v v
Random Walk Approaches for Node Embeddings
Shallow Embedding
Given a graph and a starting point, we select a neighbor of it at random, and move to this neighbor; then we select a neighbor of this point at random, and move to it, etc. The (random) sequence of points visited this way is a random walk on the graph
Random Walk可以看作是一个算法框架,描述了Random Walk基本的算法思路,具体的算法实现(主要是随机游走的策略部分)可以有很多种,例如DeepWalk等
-
Notation
-
Vector z u z_u zu
- The embedding of node u u u
-
Probability P ( v ∣ z u ) P(v | z_u) P(v∣zu)
- The (predicted) probability of visiting node v v v on random walks starting from node u u u (从节点 u u u出发使用random walks访问到节点 v v v的概率)
-
N R ( u ) N_R(u) NR(u): Neighborhood of u u u obtained by some random walk strategy R R R ( u u u在一次随机游走中访问过的节点)
-
-
Random-Walk Embeddings
-
可以认为 z u T z v \mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{v} zuTzv约等于 u u u和 v v v同时出现在一次随机游走上的概率
-
Estimate probability of visiting node v v v on a random walk starting from node u u u using some random walk strategy R R R
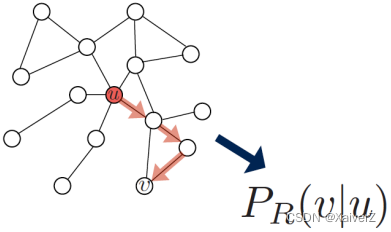
-
Optimize embeddings to encode these random walk statistics (Similarity in embedding space (Here: dot product=cos(θ)) encodes random walk “similarity”)
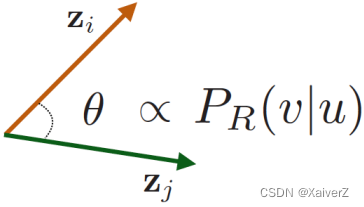
-
-
Random Walk Optimization
-
Given G = ( V , E ) G=(V,E) G=(V,E)
-
Goal: To learn a mapping f : u → R d : f ( u ) = z u f: u \rightarrow R^d: f(u)=z_u f:u→Rd:f(u)=zu
-
Run short fixed-length random walks starting from each node u u u in the graph using some random walk strategy R R R
-
For each node u u u collect N R ( u ) N_R(u) NR(u), the multiset of nodes visited on random walks starting from u u u
-
Optimize embeddings according to: Given node u u u, predict its neighbors N R ( u ) N_R(u) NR(u)
-
Log-likelihood objective
max f ∑ u ∈ V log P ( N R ( u ) ∣ z u ) \max _{f} \sum_{u \in V} \log \mathrm{P}\left(N_{\mathrm{R}}(u) \mid \mathbf{z}_{u}\right) fmaxu∈V∑logP(NR(u)∣zu)
N R ( u ) N_{\mathrm{R}}(u) NR(u) is the neighborhood of node u u u by strategy R R R -
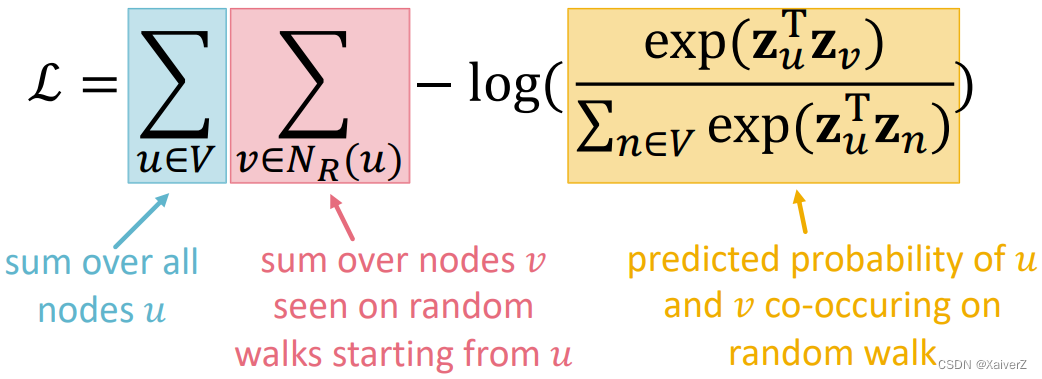
Equivalently, objective function can be rewrited as
L = ∑ u ∈ V ∑ v ∈ N R ( u ) − log ( P ( v ∣ z u ) ) \mathcal{L}=\sum_{u \in V} \sum_{v \in N_{R}(u)}-\log \left(P\left(v \mid \mathbf{z}_{u}\right)\right) L=u∈V∑v∈NR(u)∑−log(P(v∣zu))
Optimize embeddings z u z_u zu to maximize the likelihood of random walk co-occurrences (最大化在random walk中同时出现的似然概率) -
Parameterize P ( v ∣ z u ) P(v | z_u) P(v∣zu) using softmax (We want node v v v to be most similar to node u u u (out of all nodes n n n))
P ( v ∣ z u ) = exp ( z u T z v ) ∑ n ∈ V exp ( z u T z n ) P\left(v \mid \mathbf{z}_{u}\right)=\frac{\exp \left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{v}\right)}{\sum_{n \in V} \exp \left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{n}\right)} P(v∣zu)=∑n∈Vexp(zuTzn)exp(zuTzv)
-
Then we get the final objective, which uses to minimize (using SGD optimizer)
L = ∑ u ∈ V ∑ v ∈ N R ( u ) − log ( exp ( z u T z v ) ∑ n ∈ V exp ( z u T z n ) ) \mathcal{L}=\sum_{u \in V} \sum_{v \in N_{R}(u)}-\log \left(\frac{\exp \left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{v}\right)}{\sum_{n \in V} \exp \left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{n}\right)}\right) L=u∈V∑v∈NR(u)∑−log(∑n∈Vexp(zuTzn)exp(zuTzv))
-
Negative Sampling
负采样
-
上述目标函数计算softmax时间复杂度过高, O ( ∣ V ∣ 2 ) O(|V|^2) O(∣V∣2),可用层次化softmax解决,也可以用这里说的Negative Sampling
-
简单来说,不对所有节点作softmax分母的加和操作,而是采样一些负样本进行加和
log ( exp ( z u T z v ) ∑ n ∈ V exp ( z u T z n ) ) ≈ log ( σ ( z u T z v ) ) − ∑ i = 1 k log ( σ ( z u T z n i ) ) , n i ∼ P V \log \left(\frac{\exp \left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{v}\right)}{\sum_{n \in V} \exp \left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{n}\right)}\right) \approx \log \left(\sigma\left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{v}\right)\right)-\sum_{i=1}^{k} \log \left(\sigma\left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{n_{i}}\right)\right), n_{i} \sim P_{V} log(∑n∈Vexp(zuTzn)exp(zuTzv))≈log(σ(zuTzv))−i=1∑klog(σ(zuTzni)),ni∼PV
Instead of normalizing w.r.t. all nodes, just normalize against k k k random “negative samples” n i n_i ni-
Sample k k k negative nodes each with prob. proportional to its degree (以节点的度为概率参考值,度越大,选择作为负样本的概率越大)
-
Two consideration for k k k (#negative samples)
-
Higher k k k gives more robust estimates
-
Higher k k k corresponds to higher bias on negative events
-
In practice, k = 5 − 20 k=5 - 20 k=5−20
-
-
-
Why is the approximation valid ?
Paper : word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method
Why ???
-
Technically, this is a different objective. But Negative Sampling is a form of Noise Contrastive Estimation (NCE) which approx. maximizes the log probability of softmax
-
New formulation corresponds to using a logistic regression (sigmoid func.) to distinguish the target node v v v from nodes n i n_i ni sampled from background distribution P v P_v Pv
-
Node2Vec
Node2Vec
-
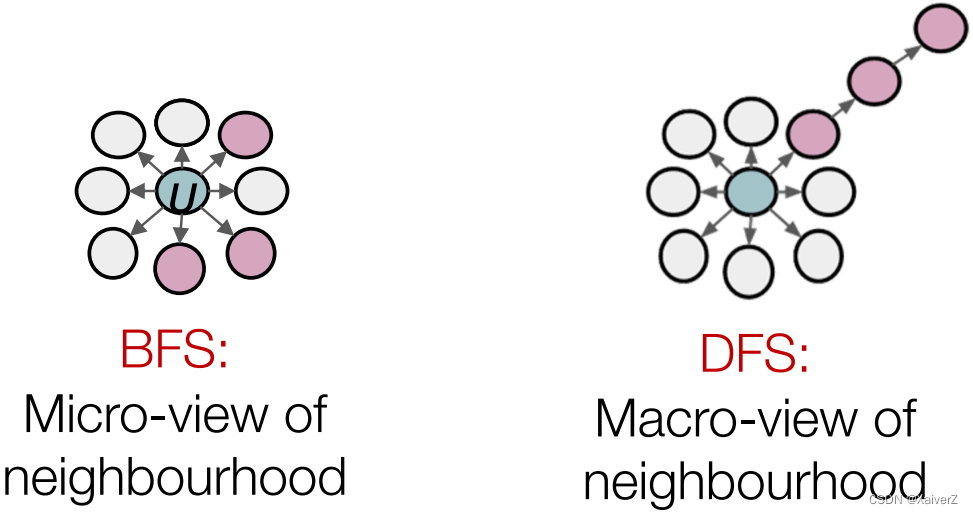
Key Idea: use flexible, biased random walks that can trade off between local and global views of the network
-
Biased 2 n d 2^{nd} 2nd-order Random Walks
-
Biased fixed-length random walk R R R that given a node u u u generates neighborhood N R ( u ) N_R(u) NR(u)
-
Two parameters
-
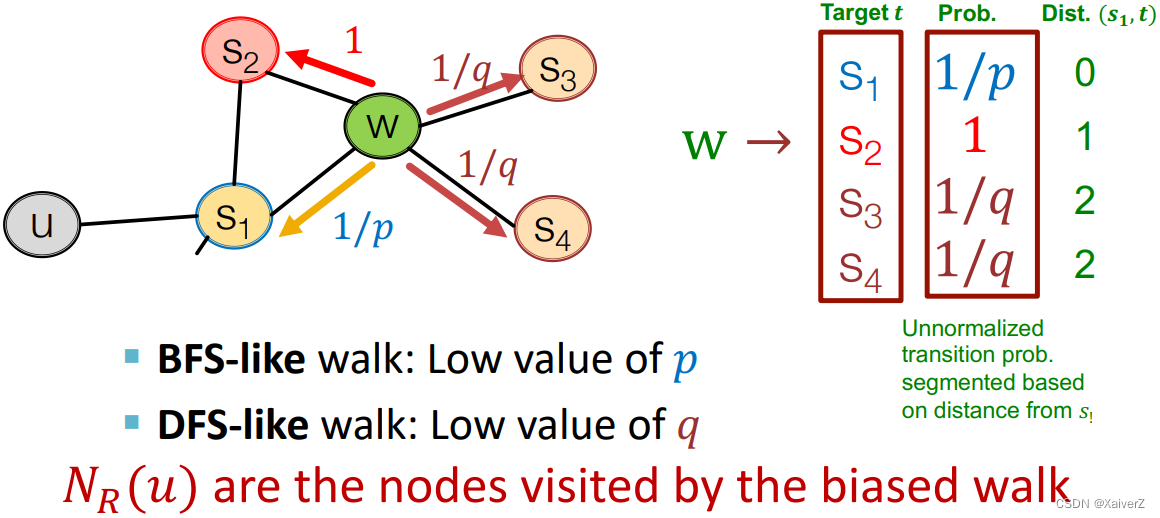
Return parameter p p p: Return back to the previous node
-
In-out parameter q q q: Moving outwards (DFS) vs. inwards (BFS). Intuitively, q q q is the ratio of BFS vs. DFS
-
-
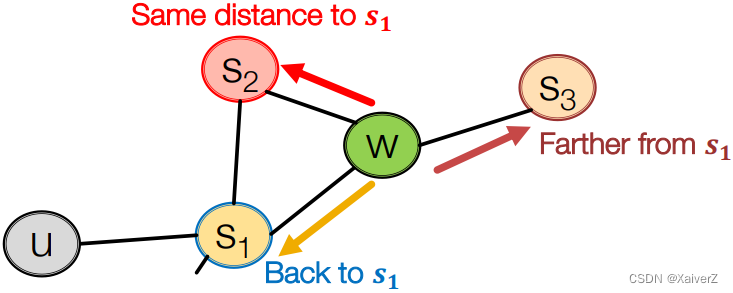
Rnd. walk just traversed edge ( s 1 , w ) (s_1, w) (s1,w) and is now at w w w, neighbors of w w w can only be (Idea: Remember where the walk came from)
-
-
Algorithm
Linear-time complexity
All 3 steps are individually parallelizable
-
Compute random walk probabilities
-
Simulate r r r random walks of length l l l starting from each node u u u
-
Optimize the node2vec objective using SGD
-
Other Random Walk Ideas
Different kinds of biased random walks
Paper : metapath2vec: Scalable Representation Learning for Heterogeneous Networks
Paper : Watch Your Step: Learning Node Embeddings via Graph Attention
Different kinds of biased random walks
Alternative optimization schemes
Paper : LINE: Large-scale Information Network Embedding
Alternative optimization schemes
Network preprocessing techniques
Paper : struc2vec: Learning Node Representations from Structural Identity
Paper : HARP: Hierarchical Representation Learning for Networks
Network preprocessing techniques
- No one method wins in all cases
Paper : Graph Embedding Techniques, Applications, and Performance: A Survey
- In general: Must choose definition of node similarity that matches your application!
Embedding Entire Graphs
Embedding Entire Graphs
- Goal: Embed a subgraph or an entire graph G G G to z G z_G zG
Approach 1
Paper : Convolutional Networks on Graphs for Learning Molecular Fingerprints
Approach 1
-
Algorithm
-
Run a standard graph embedding technique on the (sub)graph G G G
-
Then just sum (or average) the node embeddings in the (sub)graph G G G (简单平均或加和图中所有节点的embedding vector)
Z G = ∑ v ∈ G Z v \boldsymbol{Z}_{\boldsymbol{G}}=\sum_{v \in G} Z_{v} ZG=v∈G∑Zv
-
Approach 2
Paper : GATED GRAPH SEQUENCE NEURAL NETWORKS
Approach 2
-
Algorithm
-
Introduce a “virtual node” to represent the (sub)graph and run a standard graph embedding technique (引入一个“虚拟节点”,连接需要embedding的子图区域中的所有节点,而后进行Node Embedding,以该虚拟节点的embedding vector代表子图区域的embedding vector)
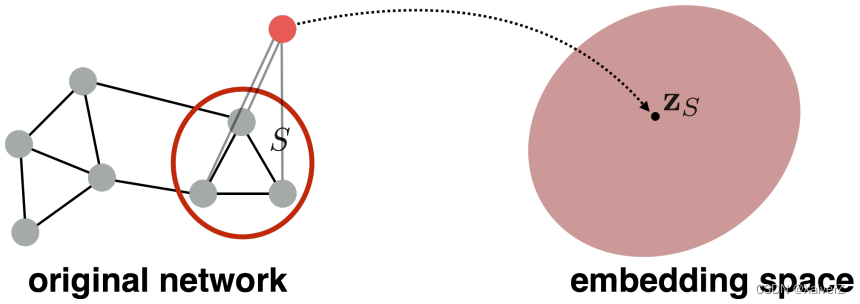
-
Approach 3: Anonymous Walk Embeddings
Paper : Anonymous Walk Embeddings
Approach 3: Anonymous Walk Embeddings
-
States in anonymous walks correspond to the index of the first time we visited the node in a random walk(核心算法与Random Walk一致,只不过节点是“匿名”的,如下图所示)
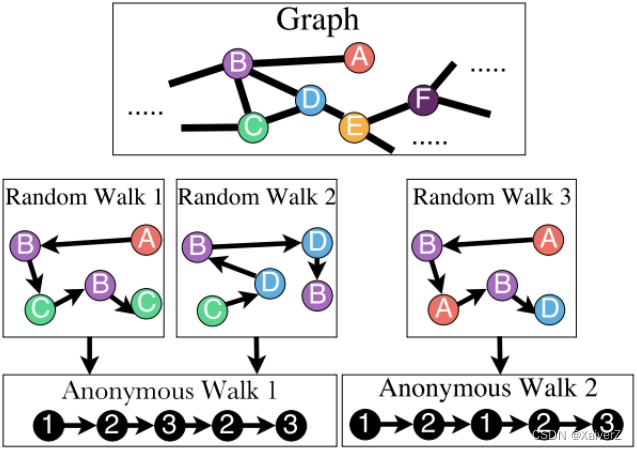
- Agnostic to the identity of the nodes visited (hence anonymous)
-
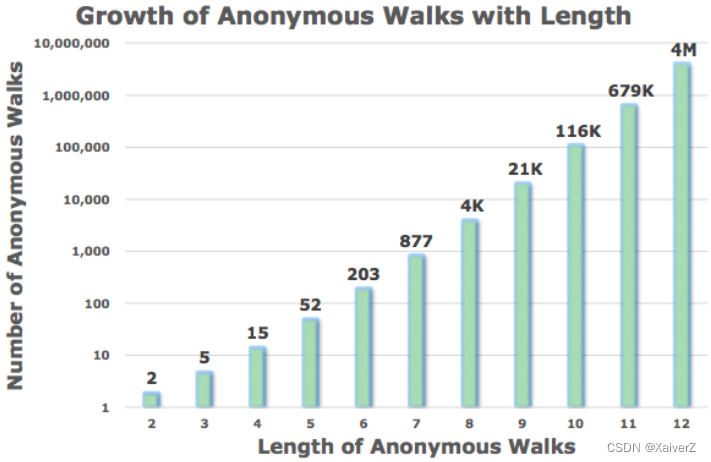
Number of Walks Grows
-
There are 5 anonymous walks w i w_i wi of length 3
w 1 = 111 , w 2 = 112 , w 3 = 121 , w 4 = 122 , w 5 = 123 w_{1}=111, w_{2}=112, w_{3}=121, w_{4}=122, w_{5}=123 w1=111,w2=112,w3=121,w4=122,w5=123
-
Simple Use of Anonymous Walks
Simple Use of Anonymous Walks
-
Key Idea: Simulate anonymous walks w i w_i wi of l l l steps and record their counts. Represent the graph as a probability distribution over these walks
-
For example
将Graph Embedding表示为各个匿名随机游走序列出现的频率向量
-
Set l = 3 l = 3 l=3
-
Generate independently a set of m m m random walks
-
Deciding m m m: We want the distribution to have error of more than ε \varepsilon ε with prob. less than δ \delta δ (误差超过 ε \varepsilon ε的概率小于 δ \delta δ)
m = [ 2 ε 2 ( log ( 2 η − 2 ) − log ( δ ) ) ] m=\left[\frac{2}{\varepsilon^{2}}\left(\log \left(2^{\eta}-2\right)-\log (\delta)\right)\right] m=[ε22(log(2η−2)−log(δ))]
η \eta η为长为 l l l的随机游走所有可能的匿名序列组合数量
-
-
Then we can represent the graph as a 5-dim vector (since there are 5 anonymous walks w i w_i wi of length 3)
-
Z G [ i ] Z_G[i] ZG[i]: the probability of anonymous walk w i w_i wi in G G G
-
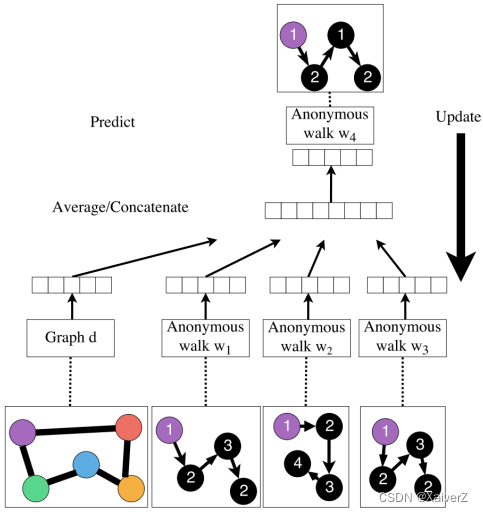
Learn Walk Embeddings
Learn Walk Embeddings
-
Key Idea: Rather than simply represent each walk by the fraction of times it occurs, we learn embedding z i z_i zi of anonymous walk w i w_i wi
- In the meantime, we also learn a graph embedding Z G Z_G ZG together with all the anonymous walk embeddings z i z_i zi (学习每个 w i w_i wi的Embedding,顺便把图表示 Z G Z_G ZG也学了)
-
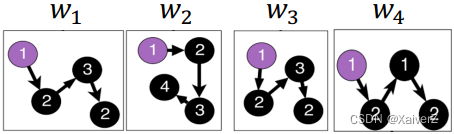
Algorithm
-
Sample anonymous random walks
-
Learn to predict walks that co-occur in Δ-size window (e.g. predict w 2 w_2 w2 given w 1 , w 3 w_1, w_3 w1,w3 if Δ = 1 Δ=1 Δ=1, something like Skip-gram)
-
Objective
max Z , d 1 T ∑ t = Δ T − Δ log P ( w t ∣ { w t − Δ , … , w t + Δ , z G } ) \max _{\mathrm{Z}, \mathrm{d}} \frac{1}{T} \sum_{t=\Delta}^{T-\Delta} \log P\left(w_{t} \mid\left\{w_{t-\Delta}, \ldots, w_{t+\Delta}, \boldsymbol{z}_{\boldsymbol{G}}\right\}\right) Z,dmaxT1t=Δ∑T−ΔlogP(wt∣{wt−Δ,…,wt+Δ,zG})
-
我们可以用softmax去建模log-prob条件概率,并用一个函数 y ( ⋅ ) y(·) y(⋅)去整合信息
P ( w t ∣ { w t − Δ , … , w t + Δ , z G } ) = exp ( y ( w t ) ) ∑ i = 1 η exp ( y ( w i ) ) P\left(w_{t} \mid\left\{w_{t-\Delta}, \ldots, w_{t+\Delta}, \boldsymbol{z}_{\boldsymbol{G}}\right\}\right)=\frac{\exp \left(y\left(w_{t}\right)\right)}{\sum_{i=1}^{\eta} \exp \left(y\left(w_{i}\right)\right)} P(wt∣{wt−Δ,…,wt+Δ,zG})=∑i=1ηexp(y(wi))exp(y(wt))
y ( w t ) = b + U ⋅ ( cat ( 1 2 Δ ∑ i = − Δ Δ z i , z G ) ) y\left(w_{t}\right)=b+U \cdot\left(\operatorname{cat}\left(\frac{1}{2 \Delta} \sum_{i=-\Delta}^{\Delta} z_{i}, \boldsymbol{z}_{\boldsymbol{G}}\right)\right) y(wt)=b+U⋅(cat(2Δ1i=−Δ∑Δzi,zG))
其中 cat ( 1 2 Δ ∑ i = − Δ Δ Z i , Z G ) \operatorname{cat}\left(\frac{1}{2 \Delta} \sum_{i=-\Delta}^{\Delta} Z_{i}, \boldsymbol{Z}_{G}\right) cat(2Δ1∑i=−ΔΔZi,ZG)表示以 w t w_t wt为中心的窗口内随机游走embedding的加和平均,再拼接上图Embedding Z G Z_G ZG。 b ∈ R , U ∈ R D b \in \mathbb{R}, U \in \mathbb{R}^{D} b∈R,U∈RD都是可学习参数。 y ( ⋅ ) y(·) y(⋅)表示一个线性层
-
-















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









