






在这篇博客中,我们将学习如何使用Python将Word文档中的图片提取出来并生成一个PowerPoint幻灯片。我们将借助wxPython、python-docx和python-pptx这三个强大的库来实现这一目标。以下是实现这个功能的完整过程。
C:\pythoncode\new\wordTOppt.py
所需库
首先,我们需要安装以下Python库:
- wxPython:用于创建图形用户界面(GUI)。
- python-docx:用于处理Word文档。
- python-pptx:用于生成PowerPoint幻灯片。
你可以通过以下命令安装这些库:
pip install wxPython python-docx python-pptx
创建GUI
我们将使用wxPython创建一个简单的GUI,让用户选择一个Word文档,并点击按钮来执行图片提取和PPT生成的过程。以下是实现这个功能的代码:
import wx
import os
import docx
from pptx import Presentation
from pptx.util import Inches, Pt
class MyFrame(wx.Frame):
def __init__(self, parent, title):
super(MyFrame, self).__init__(parent, title=title, size=(600, 300))
self.panel = wx.Panel(self)
self.create_widgets()
def create_widgets(self):
vbox = wx.BoxSizer(wx.VERTICAL)
self.file_picker = wx.FilePickerCtrl(self.panel, message="选择 Word 文档", wildcard="Word files (*.docx)|*.docx")
vbox.Add(self.file_picker, 0, wx.ALL | wx.EXPAND, 5)
self.extract_button = wx.Button(self.panel, label="提取并生成幻灯片")
self.extract_button.Bind(wx.EVT_BUTTON, self.on_extract)
vbox.Add(self.extract_button, 0, wx.ALL | wx.EXPAND, 5)
self.panel.SetSizer(vbox)
def on_extract(self, event):
word_file_path = self.file_picker.GetPath()
if not os.path.exists(word_file_path):
wx.MessageBox("文件未找到!", "错误", wx.OK | wx.ICON_ERROR)
return
# Create images directory to store extracted images
images_dir = os.path.join(os.path.dirname(word_file_path), 'images')
if not os.path.exists(images_dir):
os.makedirs(images_dir)
# Extract images from Word document
try:
doc = docx.Document(word_file_path)
for r_id, rel in doc.part.rels.items():
if str(rel.target_ref).startswith('media') or str(rel.target_ref).startswith('embeddings'):
file_suffix = str(rel.target_ref).split('.')[-1:][0].lower()
if file_suffix not in ['png', 'jpg', 'jpeg', 'gif', 'bmp']:
continue
file_name = r_id + '_' + str(rel.target_ref).replace('/', '_')
file_path = os.path.join(images_dir, file_name)
with open(file_path, "wb") as f:
f.write(rel.target_part.blob)
print('Extracted image:', file_name)
except Exception as e:
wx.MessageBox(f"Error extracting images: {str(e)}", "Error", wx.OK | wx.ICON_ERROR)
return
# Create PowerPoint presentation from extracted images
try:
ppt = Presentation()
slide_width = ppt.slide_width
slide_height = ppt.slide_height
for filename in os.listdir(images_dir):
if filename.endswith((".png", ".jpg", ".jpeg", ".gif", ".bmp")):
image_path = os.path.join(images_dir, filename)
slide = ppt.slides.add_slide(ppt.slide_layouts[6]) # Use a blank slide layout
picture = slide.shapes.add_picture(image_path, Inches(0), Inches(0), height=slide_height)
# Scale and center the picture
picture_width = picture.width
picture_height = picture.height
max_picture_width = slide_width - Inches(1)
max_picture_height = slide_height - Inches(1)
scale_ratio = min(max_picture_width / picture_width, max_picture_height / picture_height)
new_picture_width = int(picture_width * scale_ratio)
new_picture_height = int(picture_height * scale_ratio)
picture.left = (slide_width - new_picture_width) // 2
picture.top = (slide_height - new_picture_height) // 2
picture.width = new_picture_width
picture.height = new_picture_height
ppt_file_path = os.path.splitext(word_file_path)[0] + '.pptx'
ppt.save(ppt_file_path)
wx.MessageBox(f"幻灯片生成成功!PPT 已保存到 {ppt_file_path}", "成功", wx.OK | wx.ICON_INFORMATION)
except Exception as e:
wx.MessageBox(f"Error creating PPT: {str(e)}", "Error", wx.OK | wx.ICON_ERROR)
if __name__ == '__main__':
app = wx.App(False)
frame = MyFrame(None, "Word to PPT Converter")
frame.Show()
app.MainLoop()
代码解析
初始化和创建GUI
我们首先创建了一个wxPython的框架(Frame),并在其中添加了一个面板(Panel)。然后,我们在面板上添加了文件选择器和按钮。
class MyFrame(wx.Frame):
def __init__(self, parent, title):
super(MyFrame, self).__init__(parent, title=title, size=(600, 300))
self.panel = wx.Panel(self)
self.create_widgets()
创建控件
我们使用了垂直布局(VBoxSizer),并在其中添加了文件选择器和按钮。
def create_widgets(self):
vbox = wx.BoxSizer(wx.VERTICAL)
self.file_picker = wx.FilePickerCtrl(self.panel, message="选择 Word 文档", wildcard="Word files (*.docx)|*.docx")
vbox.Add(self.file_picker, 0, wx.ALL | wx.EXPAND, 5)
self.extract_button = wx.Button(self.panel, label="提取并生成幻灯片")
self.extract_button.Bind(wx.EVT_BUTTON, self.on_extract)
vbox.Add(self.extract_button, 0, wx.ALL | wx.EXPAND, 5)
self.panel.SetSizer(vbox)
提取图片
在用户选择Word文档并点击按钮后,我们提取其中的图片。我们遍历Word文档中的所有关系项,查找指向图片的关系,并将图片保存到 images 目录中。
def on_extract(self, event):
word_file_path = self.file_picker.GetPath()
if not os.path.exists(word_file_path):
wx.MessageBox("文件未找到!", "错误", wx.OK | wx.ICON_ERROR)
return
images_dir = os.path.join(os.path.dirname(word_file_path), 'images')
if not os.path.exists(images_dir):
os.makedirs(images_dir)
try:
doc = docx.Document(word_file_path)
for r_id, rel in doc.part.rels.items():
if str(rel.target_ref).startswith('media'):
file_suffix = str(rel.target_ref).split('.')[-1:][0].lower()
if file_suffix not in ['png', 'jpg', 'jpeg', 'gif', 'bmp']:
continue
file_name = r_id + '_' + str(rel.target_ref).replace('/', '_')
file_path = os.path.join(images_dir, file_name)
with open(file_path, "wb") as f:
f.write(rel.target_part.blob)
print('Extracted image:', file_name)
except Exception as e:
wx.MessageBox(f"Error extracting images: {str(e)}", "Error", wx.OK | wx.ICON_ERROR)
return
创建PPT文档
我们使用 python-pptx 创建一个新的PPT文档,并将提取的图片插入到幻灯片中。每张图片占据一张幻灯片,并居中显示。
try:
ppt = Presentation()
slide_width = ppt.slide_width
slide_height = ppt.slide_height
for filename in os.listdir(images_dir):
if filename.endswith((".png", ".jpg", ".jpeg", ".gif", ".bmp")):
image_path = os.path.join(images_dir, filename)
slide = ppt.slides.add_slide(ppt.slide_layouts[6]) # Use a blank slide layout
picture = slide.shapes.add_picture(image_path, Inches(0), Inches(0), height=slide_height)
picture_width = picture.width
picture_height = picture.height
max_picture_width = slide_width - Inches(1)
max_picture_height = slide_height - Inches(1)
scale_ratio = min(max_picture_width / picture_width, max_picture_height / picture_height)
new_picture_width = int(picture_width * scale_ratio)
new_picture_height = int(picture_height * scale_ratio)
picture.left = (slide_width - new_picture_width) // 2
picture.top = (slide_height - new_picture_height) // 2
picture.width = new_picture_width
picture.height = new_picture_height
ppt_file_path = os.path.splitext(word_file_path)[0] + '.pptx'
ppt.save(ppt_file_path)
wx.MessageBox(f"幻灯片生成成功!PPT 已保存到 {ppt_file_path}", "成功", wx.OK | wx.ICON_INFORMATION)
except Exception as e:
wx.MessageBox
(f"Error creating PPT: {str(e)}", "Error", wx.OK | wx.ICON_ERROR)
效果如下:
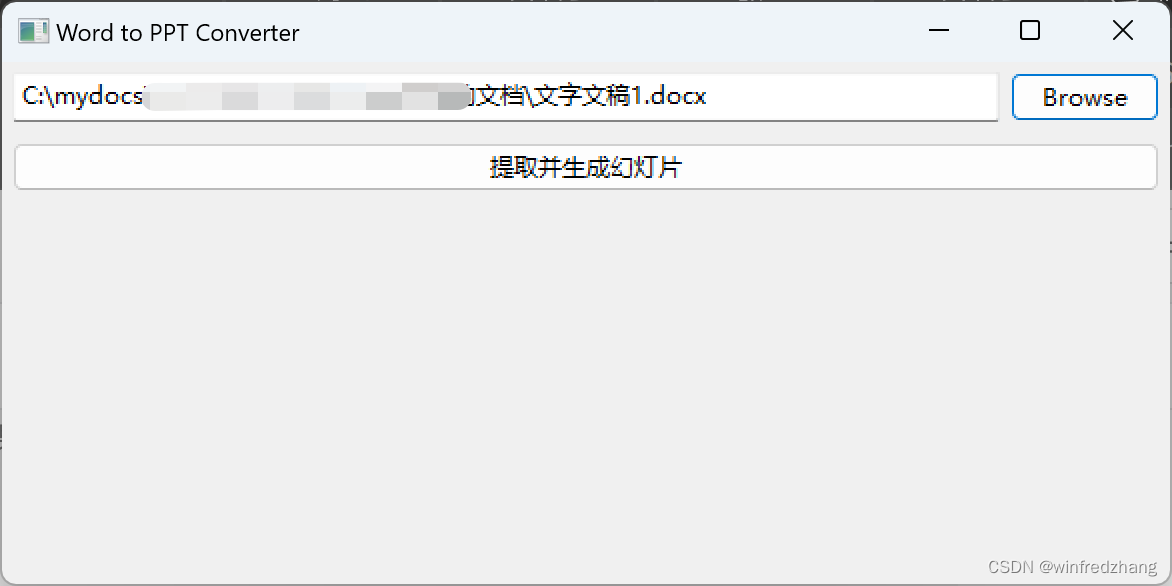


总结
通过本文,你已经学会了如何使用Python提取Word文档中的图片并生成一个包含这些图片的PowerPoint幻灯片。wxPython为我们提供了一个用户友好的界面,python-docx使我们能够轻松地处理Word文档,而python-pptx则让我们能够方便地创建和操作PPT文档。希望这篇博客能对你有所帮助!如果你有任何问题或建议,欢迎留言讨论。















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









