







 本文深入解析线性回归模型,涵盖其数学定义、均方误差计算、梯度下降优化及最小二乘估计方法,同时探讨了最大似然估计原理,是理解机器学习中回归任务的基础。
本文深入解析线性回归模型,涵盖其数学定义、均方误差计算、梯度下降优化及最小二乘估计方法,同时探讨了最大似然估计原理,是理解机器学习中回归任务的基础。
线性回归模型
线性函数的定义如下:
h
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
=
w
T
x
+
b
h(\bm{x})=w_{1}x_{1}+w_{2}x_{2}+...+w_{d}x_{d}+b=\bm{w}^{T}\bm{x}+b
h(x)=w1x1+w2x2+...+wdxd+b=wTx+b
给定数据集
D
=
{
(
x
i
,
y
i
)
}
1
N
D=\{(\bm{x}_{i},y_{i})\}_{1}^{N}
D={(xi,yi)}1N,其中
x
i
,
y
i
\bm{x}_{i},y_{i}
xi,yi都是连续型变量。线性回归试图去学习到
h
(
x
)
h(\bm{x})
h(x)能准确地预测
y
y
y。
回归任务最常用的性能度量就是均平方误差(MSE,mean squared error):
J
(
w
,
b
)
=
1
2
∑
i
=
1
N
(
y
i
−
h
(
x
i
)
)
2
=
1
2
∑
i
=
1
N
(
y
i
−
w
T
x
i
+
b
)
2
J(\bm{w},b)=\frac{1}{2}\sum_{i=1}^{N}(y_{i}-h(\bm{x}_{i}))^{2}=\frac{1}{2}\sum_{i=1}^{N}(y_{i}-\bm{w}^{T}\bm{x}_{i}+b)^{2}
J(w,b)=21i=1∑N(yi−h(xi))2=21i=1∑N(yi−wTxi+b)2
参数的优化:(入门人士只需掌握(1)即可,实用简单)
(1)可以使用梯度下降来优化误差,每一步的更新为:
w
j
:
=
w
j
−
η
∂
J
(
w
,
b
)
∂
w
j
=
w
j
−
η
∑
i
=
1
N
(
y
i
−
h
(
x
i
)
)
x
i
j
,
j
=
1
,
2
,
.
.
.
d
b
:
=
b
−
η
∂
J
(
w
,
b
)
∂
b
=
w
j
−
η
∑
i
=
1
N
(
y
i
−
h
(
x
i
)
)
,
j
=
1
,
2
,
.
.
.
d
w_{j}:=w_{j}-\eta \frac{\partial J(\bm{w},b)}{\partial w_{j}}=w_{j}-\eta \sum_{i=1}^{N}(y_{i}-h(\bm{x}_{i}))\bm{x}_{i}^{j},j=1,2,...d \\ b:=b-\eta \frac{\partial J(\bm{w},b)}{\partial b}=w_{j}-\eta \sum_{i=1}^{N}(y_{i}-h(\bm{x}_{i})),j=1,2,...d
wj:=wj−η∂wj∂J(w,b)=wj−ηi=1∑N(yi−h(xi))xij,j=1,2,...db:=b−η∂b∂J(w,b)=wj−ηi=1∑N(yi−h(xi)),j=1,2,...d
(2)最小二乘估计:
将
w
\bm{w}
w和
b
b
b合起来写为
w
^
=
(
w
;
b
)
,
\hat{\bm{w}}=(\bm{w};b),
w^=(w;b),把数据集表示为
N
×
(
d
+
1
)
N\times (d+1)
N×(d+1)的矩阵,前
d
d
d个元素对应属性值,最后一个数为
1
1
1对应参数
b
b
b。
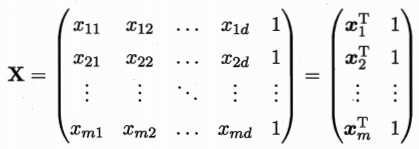
标记也写为向量的形式:
y
=
(
y
1
;
y
2
;
.
.
.
;
y
N
)
\bm{y}=(y_{1};y_{2};...;y_{N})
y=(y1;y2;...;yN),则求最小化误差的参数
w
^
\hat{\bm{w}}
w^可表示为:
w
^
∗
=
min
w
^
J
(
w
^
)
=
min
w
^
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
\hat{\bm{w}}^{*}=\min_{\hat{\bm{w}}}J(\hat{\bm{w}})=\min_{\hat{\bm{w}}}(\bm{y}-\mathbf{X}\bm{\hat{w}})^{T}(\bm{y}-\mathbf{X}\bm{\hat{w}})
w^∗=w^minJ(w^)=w^min(y−Xw^)T(y−Xw^)
∂
J
(
w
^
)
∂
w
^
=
0
⇒
2
X
T
(
X
w
^
−
y
)
=
0
\frac{\partial J(\hat{\bm{w}})}{\partial\hat{\bm{w}}}=0 \\ \Rightarrow 2\mathbf{X}^{T}(\mathbf{X}\hat{\bm{w}}-\bm{y})=0
∂w^∂J(w^)=0⇒2XT(Xw^−y)=0
当
X
T
X
\mathbf{X}^{T}\mathbf{X}
XTX为满秩矩阵(判断矩阵是否可逆的充要条件)或正定矩阵时,上式可解为:
w
^
=
(
X
T
X
)
−
1
X
T
y
\hat{\bm{w}}=(\mathbf{X}^{T}\mathbf{X})^{-1}\mathbf{X}^{T}\bm{y}
w^=(XTX)−1XTy
此时的回归模型为:
h
(
x
i
)
=
x
i
T
(
X
T
X
)
−
1
X
T
y
h(\bm{x}_{i})=\bm{x}_{i}^{T}(\mathbf{X}^{T}\mathbf{X})^{-1}\mathbf{X}^{T}\bm{y}
h(xi)=xiT(XTX)−1XTy
当
X
T
X
\mathbf{X}^{T}\mathbf{X}
XTX不是满秩矩阵时,相当于求线性方程组
(
X
T
X
)
w
^
=
X
T
y
(\mathbf{X}^{T}\mathbf{X})\hat{\bm{w}}=\mathbf{X}^{T}\bm{y}
(XTX)w^=XTy,此时可能解出多个
w
^
\hat{\bm{w}}
w^,它们都能使得误差均方误差最小化(所得到的误差都是相同的)。选择哪个将由算法决定,通常引入正则化项来解决。
当加入正则项时,误差为:
w
^
∗
=
min
w
^
J
(
w
^
)
=
min
w
^
[
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
+
λ
2
∣
∣
w
^
∣
∣
2
]
\hat{\bm{w}}^{*}=\min_{\hat{\bm{w}}}J(\hat{\bm{w}})=\min_{\hat{\bm{w}}}[(\bm{y}-\mathbf{X}\bm{\hat{w}})^{T}(\bm{y}-\mathbf{X}\bm{\hat{w}})+\frac{\lambda}{2}||\hat{\bm{w}}||^{2}]
w^∗=w^minJ(w^)=w^min[(y−Xw^)T(y−Xw^)+2λ∣∣w^∣∣2]
w
^
=
(
X
T
X
+
λ
I
)
−
1
X
T
y
\hat{\bm{w}}=(\mathbf{X}^{T}\mathbf{X}+\lambda \mathbf{I})^{-1}\mathbf{X}^{T}\bm{y}
w^=(XTX+λI)−1XTy
(3)最大似然估计
设
ϵ
(
i
)
\epsilon^{(i)}
ϵ(i)为样本
i
i
i的误差,则有:
y
(
i
)
=
w
T
x
(
i
)
+
ϵ
(
i
)
,
i
=
1
,
2
,
.
.
.
,
N
y^{(i)}=\bm{w}^{T}\bm{x}^{(i)}+\epsilon^{(i)},i=1,2,...,N
y(i)=wTx(i)+ϵ(i),i=1,2,...,N
ϵ
(
i
)
\epsilon^{(i)}
ϵ(i)与
ϵ
(
j
)
,
i
≠
j
\epsilon^{(j)},i \neq j
ϵ(j),i̸=j之间独立同分布,都满足正态分布
ϵ
(
i
)
∼
N
(
0
,
σ
2
)
,
i
=
1
,
2
,
.
.
.
,
N
\epsilon^{(i)}\sim \mathcal{N}(0,\sigma^{2}),i=1,2,...,N
ϵ(i)∼N(0,σ2),i=1,2,...,N
p
(
ϵ
(
i
)
)
=
1
2
π
σ
exp
(
−
(
ϵ
(
i
)
)
2
2
σ
2
)
p(\epsilon^{(i)})=\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(\epsilon^{(i)})^{2}}{2\sigma^{2}})
p(ϵ(i))=2πσ1exp(−2σ2(ϵ(i))2)
因为
ϵ
(
i
)
=
y
(
i
)
−
w
T
x
(
i
)
\epsilon^{(i)}=y^{(i)}-\bm{w}^{T}\bm{x}^{(i)}
ϵ(i)=y(i)−wTx(i),
ϵ
(
i
)
\epsilon^{(i)}
ϵ(i)的概率就是
x
(
i
)
\bm{x}^{(i)}
x(i)能映射到
y
(
i
)
y^{(i)}
y(i)的概率。
p
(
y
(
i
)
∣
x
(
i
)
;
w
)
=
1
2
π
σ
exp
(
−
(
y
(
i
)
−
w
T
x
(
i
)
)
2
2
σ
2
)
p(y^{(i)}|\bm{x}^{(i)};\bm{w})=\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(y^{(i)}-\bm{w}^{T}\bm{x}^{(i)})^{2}}{2\sigma^{2}})
p(y(i)∣x(i);w)=2πσ1exp(−2σ2(y(i)−wTx(i))2)
最大化似然函数:
L
(
w
)
=
∏
i
=
1
N
p
(
y
(
i
)
∣
x
(
i
)
;
w
)
L(\bm{w})=\prod_{i=1}^{N}p(y^{(i)}|\bm{x}^{(i)};\bm{w})
L(w)=i=1∏Np(y(i)∣x(i);w)
取对数似然:
log
L
(
w
)
=
∑
i
=
1
N
log
(
p
(
y
(
i
)
∣
x
(
i
)
;
w
)
=
∑
i
=
1
N
log
[
1
2
π
σ
exp
(
−
(
y
(
i
)
−
w
T
x
(
i
)
)
2
2
σ
2
)
]
=
∑
i
=
1
N
[
−
1
2
log
(
2
π
)
−
log
σ
−
(
y
(
i
)
−
w
T
x
(
i
)
)
2
2
σ
2
]
=
−
N
1
2
log
(
2
π
)
−
N
log
σ
−
1
2
σ
2
∑
i
=
1
N
(
y
(
i
)
−
w
T
x
(
i
)
)
2
\log{L(\bm{w})}=\sum_{i=1}^{N}\log(p(y^{(i)}|\bm{x}^{(i)};\bm{w}) \\ =\sum_{i=1}^{N}\log[\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(y^{(i)}-\bm{w}^{T}\bm{x}^{(i)})^{2}}{2\sigma^{2}})]\\ =\sum_{i=1}^{N}[-\frac{1}{2}\log{(2\pi)-\log{\sigma}-\frac{(y^{(i)}-\bm{w}^{T}\bm{x}^{(i)})^{2}}{2\sigma^{2}}}]\\ =-N\frac{1}{2}\log{(2\pi)-N\log{\sigma}-\frac{1}{2\sigma^{2}}}\sum_{i=1}^{N}(y^{(i)}-\bm{w}^{T}\bm{x}^{(i)})^{2}
logL(w)=i=1∑Nlog(p(y(i)∣x(i);w)=i=1∑Nlog[2πσ1exp(−2σ2(y(i)−wTx(i))2)]=i=1∑N[−21log(2π)−logσ−2σ2(y(i)−wTx(i))2]=−N21log(2π)−Nlogσ−2σ21i=1∑N(y(i)−wTx(i))2
最大化对数似然函数等价于最小化均方误差。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









