







PCA
主成分分析(Principal Component Analysis,简称PCA ),是常用的降维方法。PCA是一种线性的降维方法,线性变换的直观表示为:
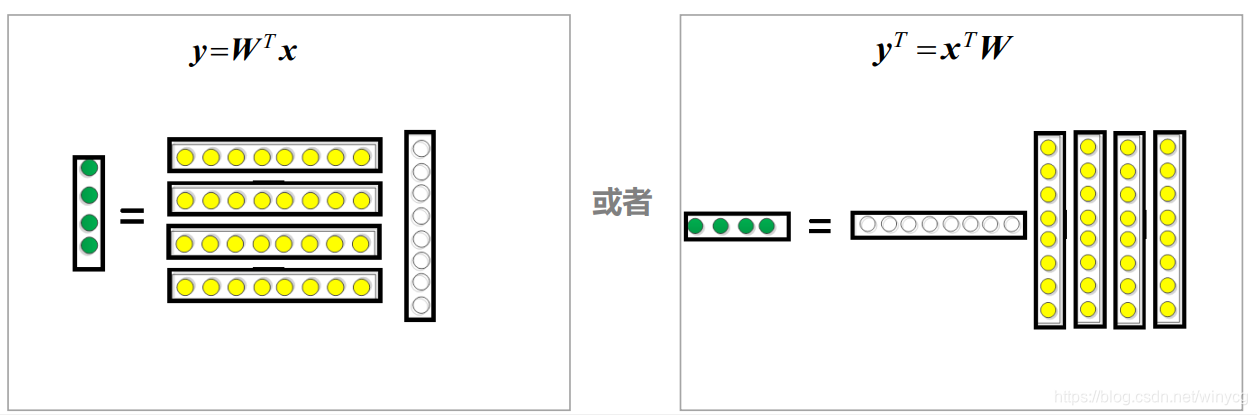
其中,
x
\bm{x}
x是原始的样本,
y
\bm{y}
y是降维后的样本,
W
\mathbf{W}
W是转换矩阵。PCA的主要目标就是求解转换矩阵,我们需要预先定义目标函数,在PCA中,有以下两个优化目标:
(1)最小化重构误差
(2)最大化投影后的方差。
最小化重构误差
有趣的是,上述两个目标能够得到等价的推导。
首先对所有样本进行中心化处理,使得
∑
i
x
i
=
0
;
\sum_{i}{\bm{x}}_{i}=0;
∑ixi=0;
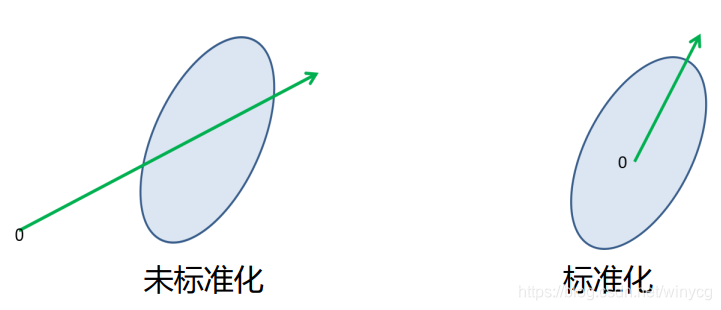
上图中可以看出,左图对应为未标准化的结果,所求的投影方向不能正确反映方差最大的方向。标准化后,更能正确反映方差最大的方向。
无损转换矩阵
W
=
(
w
1
,
w
2
,
.
.
.
,
w
d
)
\mathbf{W}=(\bm{w}_{1},\bm{w}_{2},...,\bm{w}_{d})
W=(w1,w2,...,wd),
w
i
\bm{w}_{i}
wi是标准正交基向量,
∣
∣
w
i
∣
∣
2
2
=
1
||\bm{w}_{i}||_{2}^{2}=1
∣∣wi∣∣22=1,
w
i
T
w
j
=
0
(
i
≠
j
)
\bm{w}_{i}^{T}\bm{w}_{j}=0(i\neq j)
wiTwj=0(i=j)。注意,在这里
W
\mathbf{W}
W是
d
d
d阶方阵,所以
W
\mathbf{W}
W为正交矩阵,满足
W
T
=
W
−
1
\mathbf{W}^{T}=\mathbf{W}^{-1}
WT=W−1,
W
T
W
=
I
\mathbf{W}^{T}\mathbf{W}=I
WTW=I,
W
W
T
=
I
\mathbf{W}\mathbf{W}^{T}= I
WWT=I。
W
\mathbf{W}
W为编码矩阵,
W
T
\mathbf{W}^{T}
WT为解码矩阵。此时实现了无损压缩过程:
z
i
=
W
T
x
i
编
码
x
^
i
=
W
z
i
解
码
x
^
i
=
W
W
T
x
i
=
x
i
\bm{z_{i}}=\mathbf{W}^{T}\bm{x}_{i}\ 编码\\ \bm{\hat{x}_{i}}=\mathbf{W}\bm{z}_{i}\ 解码\\ \bm{\hat{x}}_{i}=\mathbf{W}\mathbf{W}^{T}\bm{x}_{i}=\bm{x}_{i}
zi=WTxi 编码x^i=Wzi 解码x^i=WWTxi=xi
舍弃部分坐标向量,维度降到
d
′
<
d
d'<d
d′<d,有损转换矩阵
W
=
(
w
1
,
w
2
,
.
.
.
,
w
d
′
)
\mathbf{W}=(\bm{w}_{1},\bm{w}_{2},...,\bm{w}_{d'})
W=(w1,w2,...,wd′),则样本点
x
i
\bm{x}_{i}
xi在低维坐标系中的投影是
z
i
=
(
z
i
1
,
z
i
2
,
.
.
.
,
z
i
d
′
)
T
\bm{z}_{i}=(z_{i1},z_{i2},...,z_{id'})^{T}
zi=(zi1,zi2,...,zid′)T。即为编码过程:
z
i
=
W
T
x
i
,
z
i
j
=
w
j
T
x
i
\bm{z}_{i}=\mathbf{W}^{T}\bm{x}_{i},z_{ij}=\bm{w}_{j}^{T}\bm{x}_{i}
zi=WTxi,zij=wjTxi
基于
z
i
\bm{z}_{i}
zi,使用转换矩阵
W
T
\mathbf{W}^{T}
WT来重构
x
i
\bm{x}_{i}
xi(注意:在这里
W
\mathbf{W}
W不再是正交矩阵,只满足
W
T
W
=
I
\mathbf{W}^{T}\mathbf{W}=I
WTW=I,
W
W
T
≠
I
\mathbf{W}\mathbf{W}^{T}\neq I
WWT=I,所以重构后的
x
i
^
\hat{\bm{x}_{i}}
xi^不等于原样本
x
i
\bm{x}_{i}
xi):
x
i
^
=
W
z
i
=
∑
j
=
1
d
′
z
i
j
w
j
\hat{\bm{x}_{i}}=\mathbf{W}\bm{z}_{i}=\sum_{j=1}^{d'}z_{ij}\bm{w}_{j}
xi^=Wzi=j=1∑d′zijwj
原样本点与重构的样本点之间的距离为
d
i
=
∣
∣
W
z
i
−
x
i
∣
∣
2
2
d_{i}=||\mathbf{W}\bm{z}_{i}-\bm{x}_{i}||^{2}_{2}
di=∣∣Wzi−xi∣∣22:
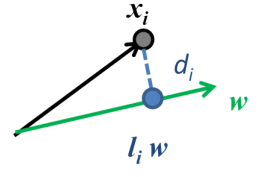
图中
l
i
=
z
i
\bm{l}_{i}=\bm{z}_{i}
li=zi,我们的目标是最小化
d
i
d_{i}
di,所以误差函数的意义也表示样本点到投影方向的距离都尽量近。
∑
i
=
1
m
∣
∣
W
z
i
−
x
i
∣
∣
2
2
=
∑
i
=
1
m
[
(
W
z
i
)
T
(
W
z
i
)
−
2
z
i
T
W
T
x
i
]
+
c
o
n
s
t
=
∑
i
=
1
m
z
i
T
z
i
−
2
∑
i
=
1
m
z
i
T
W
T
x
i
+
c
o
n
s
t
=
−
∑
i
=
1
m
z
i
T
z
i
+
c
o
n
s
t
\sum_{i=1}^{m}||\mathbf{W}\bm{z}_{i}-\bm{x}_{i}||^{2}_{2}=\sum_{i=1}^{m}[(\mathbf{W}z_{i})^{T}(\mathbf{W}z_{i})-2\bm{z}_{i}^{T}\mathbf{W}^{T}\bm{x}_{i}]+const\\ =\sum_{i=1}^{m}\bm{z}_{i}^{T}\bm{z}_{i}-2\sum_{i=1}^{m}\bm{z}_{i}^{T}\mathbf{W}^{T}\bm{x}_{i}+const\\ =-\sum_{i=1}^{m}\bm{z}_{i}^{T}\bm{z}_{i}+const
i=1∑m∣∣Wzi−xi∣∣22=i=1∑m[(Wzi)T(Wzi)−2ziTWTxi]+const=i=1∑mziTzi−2i=1∑mziTWTxi+const=−i=1∑mziTzi+const
t
r
(
⋅
)
tr(\cdot)
tr(⋅)表示矩阵的迹,即对角线值的和。由于
z
i
T
z
i
=
t
r
(
z
i
z
i
T
)
\bm{z}_{i}^{T}\bm{z}_{i}=tr(\bm{z}_{i}\bm{z}_{i}^{T})
ziTzi=tr(ziziT)
带入之后可以得到:
∝
−
t
r
(
W
T
(
∑
i
=
1
m
x
i
x
i
T
)
W
)
=
−
t
r
(
W
T
X
X
T
W
)
\propto -tr(\mathbf{W}^{T}(\sum_{i=1}^{m}\bm{x}_{i}\bm{x}_{i}^{T})\mathbf{W})=-tr(\mathbf{W}^{T}\mathbf{XX}^{T}\mathbf{W})
∝−tr(WT(i=1∑mxixiT)W)=−tr(WTXXTW)
此时,可以得到优化目标为:
min
W
−
t
r
(
W
T
X
X
T
W
)
s
.
t
.
W
T
W
=
I
\min_{\mathbf{W}}-tr(\mathbf{W}^{T}\mathbf{XX}^{T}\mathbf{W}) \\ s.t. \ \mathbf{W^{T}W}=\mathbf{I}
Wmin−tr(WTXXTW)s.t. WTW=I
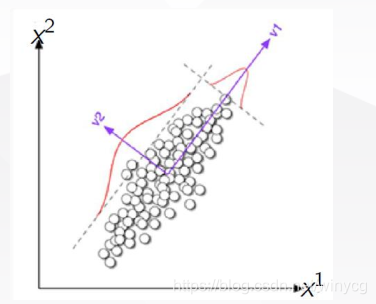
最大化投影后的方差
中心思想: 寻找一个方向向量, 使得数据投影到其上后方差最大;如果能找到, 继续寻找下一个方向向量, 该向量正交于之前的方向向量, 并且尽可能保持数据方差
我们的目标是最大化投影之后的方差,即为(假设样本已中心化):
max
∑
i
=
1
m
z
i
T
z
i
=
max
W
t
r
(
W
T
X
X
T
W
)
s
.
t
.
W
T
W
=
I
\max\sum_{i=1}^{m}\bm{z}_{i}^{T}\bm{z}_{i}=\max_{\mathbf{W}} tr(\mathbf{W}^{T}\mathbf{XX}^{T}\mathbf{W})\\ s.t. \ \mathbf{W^{T}W}=\mathbf{I}
maxi=1∑mziTzi=Wmaxtr(WTXXTW)s.t. WTW=I
PCA目标函数求解
寻找
W
∈
R
d
×
d
′
\mathbf{W}\in R^{d\times d'}
W∈Rd×d′,使得满足
max
∑
i
=
1
m
z
i
T
z
i
=
max
W
t
r
(
W
T
X
X
T
W
)
s
.
t
.
W
T
W
=
I
\max\sum_{i=1}^{m}\bm{z}_{i}^{T}\bm{z}_{i}=\max_{\mathbf{W}} tr(\mathbf{W}^{T}\mathbf{XX}^{T}\mathbf{W})\\ s.t. \ \mathbf{W^{T}W}=\mathbf{I}
maxi=1∑mziTzi=Wmaxtr(WTXXTW)s.t. WTW=I
对于带有约束的优化问题,采用拉格朗日乘数法:
引入拉格朗日因子
λ
i
,
i
=
1
,
2
,
.
.
.
,
d
′
\lambda_{i},i=1,2,...,d'
λi,i=1,2,...,d′,拉格朗日方程为:
L
(
W
)
=
t
r
(
W
T
X
X
T
W
)
−
λ
(
W
T
W
−
I
)
λ
=
d
i
a
g
(
λ
1
,
λ
2
,
.
.
.
,
λ
d
′
)
λ
(
W
T
W
−
I
)
=
∑
i
=
1
d
′
λ
i
(
w
i
T
w
i
−
1
)
L(\mathbf{W})=tr(\mathbf{W}^{T}\mathbf{XX}^{T}\mathbf{W})-\bm{\lambda}(\mathbf{W^{T}W}-I) \\ \bm{\lambda}=diag(\lambda_{1},\lambda_{2},...,\lambda_{d'})\\ \bm{\lambda}(\mathbf{W^{T}W}-I)=\sum_{i=1}^{d'}\lambda_{i}(\bm{w}_{i}^{T}\bm{w}_{i}-1)
L(W)=tr(WTXXTW)−λ(WTW−I)λ=diag(λ1,λ2,...,λd′)λ(WTW−I)=i=1∑d′λi(wiTwi−1)
由矩阵迹的性质:
∂
t
r
(
W
A
W
T
)
∂
W
=
2
W
A
,
A
=
A
T
\frac{\partial{tr(\mathbf{WA}\mathbf{W}}^{T})}{\partial \mathbf{W}}=\mathbf{2WA},\mathbf{A}=\mathbf{A}^{T}
∂W∂tr(WAWT)=2WA,A=AT
令
∂
L
∂
W
=
0
⇒
X
X
T
W
=
λ
W
X
X
T
w
i
=
λ
i
w
i
,
i
=
1
,
2
,
.
.
.
,
d
′
\frac{\partial{L}}{\partial{\mathbf{W}}}=0\Rightarrow \mathbf{XX^{T}W}=\bm{\lambda}\mathbf{W}\\ \mathbf{XX}^{T}\bm{w}_{i}=\lambda_{i}\bm{w}_{i},i=1,2,...,d'
∂W∂L=0⇒XXTW=λWXXTwi=λiwi,i=1,2,...,d′
w
i
,
i
=
1
,
2
,
.
.
.
,
d
′
\bm{w}_{i},i=1,2,...,d'
wi,i=1,2,...,d′所组成标准正交基,所以可得到
λ
i
,
w
i
\lambda_{i},\bm{w}_{i}
λi,wi为
X
X
T
\mathbf{XX}^{T}
XXT的特征值和特征向量。
由
X
X
T
W
=
λ
W
⇒
W
T
X
X
T
W
=
λ
\mathbf{XX^{T}W}=\bm{\lambda}\mathbf{W}\Rightarrow \mathbf{W}^{T}\mathbf{XX^{T}W}=\bm{\lambda}
XXTW=λW⇒WTXXTW=λ
此时等价于最大化
max
W
t
r
(
λ
)
\max_{\mathbf{W}} tr(\bm{\lambda})
maxWtr(λ)。此时取前
d
′
d'
d′个最大的特征值对应的特征向量组成
W
=
(
w
1
,
w
2
,
.
.
.
,
w
d
′
)
\mathbf{W}=(\bm{w}_{1},\bm{w}_{2},...,\bm{w}_{d'})
W=(w1,w2,...,wd′)。注意,对于
n
n
n阶协方差矩阵,其为半正定阵,即必定对应
n
n
n个非负的特征值。由此可总结出PCA算法的一般流程:
PCA算法过程:
================================================
输入:样本集
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D=\{\bm{x}_{1},\bm{x}_{2},...,\bm{x}_{m}\}
D={x1,x2,...,xm}和低维空间为数
d
′
d'
d′
过程:
1.样本中心化:
x
i
←
x
i
−
1
m
∑
j
=
1
m
x
j
\bm{x}_{i}\leftarrow \bm{x}_{i}-\frac{1}{m}\sum_{j=1}^{m}\bm{x}_{j}
xi←xi−m1∑j=1mxj
2.求解样本的协方差矩阵
X
X
T
\mathbf{XX^{T}}
XXT并进行特征值分解。
3.取前
d
′
d'
d′大的特征值对应的特征向量
w
1
,
w
2
,
.
.
.
,
w
d
′
\bm{w}_{1},\bm{w}_{2},...,\bm{w}_{d'}
w1,w2,...,wd′
输出:投影矩阵
W
∗
=
(
w
1
,
w
2
,
.
.
.
,
w
d
′
)
\mathbf{W}^{*}=(\bm{w}_{1},\bm{w}_{2},...,\bm{w}_{d'})
W∗=(w1,w2,...,wd′)
=============================================
在实际应用中,通常会使用SVD来求代替协方差分解:

PCA超参数确定
PCA的好处是超参数很少,只需确定低维空间的维数
d
′
d'
d′即可。有如下三种方法:
(1)用户事先指定
(2)使用不同的值降维形成的样本对k近邻分类器(或者其他开销较小的分类器)进行交叉验证。
(3)设置重构阈值:
∑
i
=
1
d
′
λ
i
∑
i
=
1
d
λ
i
≥
t
\frac{\sum_{i=1}^{d'}\lambda_{i}}{\sum_{i=1}^{d}\lambda_{i}}\geq t
∑i=1dλi∑i=1d′λi≥t
取特定阈值下最小的
d
′
d'
d′。
优缺点分析
优点:特征向量方法;没有额外要调节的超参数,且
d
′
d'
d′无局部最小值。
缺点:只用了二阶统计量(偏差和方差),不能处理高阶依赖。如所有特征向量两两独立,没有做到多个特征组合之间相互独立;只能用于线性投影。
T-SNE
PCA是一种线性降维方法,t-SNE(t-distributed Stochastic Neighbor Embedding)则是一种非线性降维方法,它将数据点的相似度转换为联合概率并优化低维数据和高维数据之间的KL误差。
SKlearn库对t-SNE函数使用:https://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html?highlight=t%20sne#sklearn.manifold.TSNE
下面给出PCA和t-SNE的使用例子,对iris数据集进行降维:
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
iris = load_iris()
X_tsne = TSNE(learning_rate=1000.0).fit_transform(iris.data)
X_pca = PCA().fit_transform(iris.data)
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=iris.target)
plt.subplot(122)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=iris.target)
plt.show()
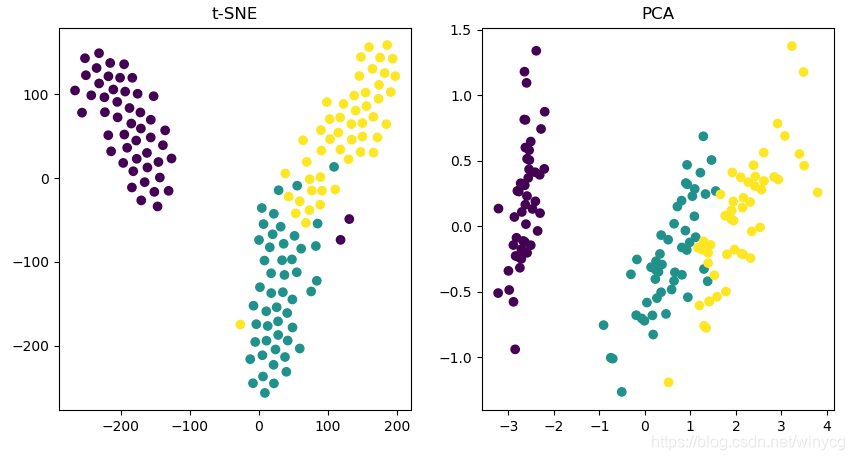
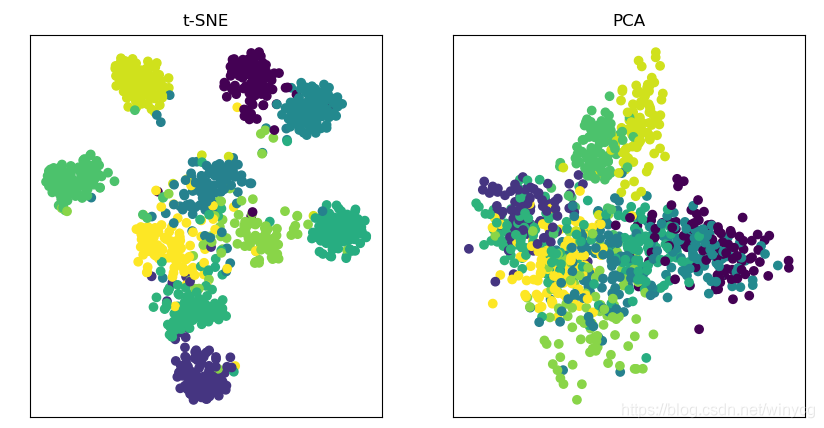
t-SNE降维CIFAR-100的embeddings
给定一个预训练的分类网络,例如resnet32,提取出global average polling前的embeddings,采用t-SNE进行降维可视化:
(1)任意选取10类,提取embeddings和标签target并保存为npy文件:
import torch
import torch.backends.cudnn as cudnn
import os
import numpy as np
import models
import torchvision
import torchvision.transforms as transforms
# dataset
num_classes = 100
device = 'cuda' if torch.cuda.is_available() else 'cpu'
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
testset = torchvision.datasets.CIFAR100(root=get_data_folder(),
train=False, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5071, 0.4867, 0.4408],
[0.2675, 0.2565, 0.2761]),
]))
testloader = torch.utils.data.DataLoader(testset, batch_size=1, shuffle=False,
pin_memory=(torch.cuda.is_available()))
# --------------------------------------
model = getattr(models, 'resnet32')
net = model(num_classes=num_classes).cuda()
net = torch.nn.DataParallel(net)
cudnn.benchmark = True
def test():
net.eval()
classes = np.random.choice(np.arange(100), 10, replace=False)
embeddings_list = []
target_list = []
with torch.no_grad():
for batch_idx, (inputs, target) in enumerate(testloader):
inputs, target = inputs.to(device), target.to(device)
if np.sum(classes == target.item()) == 1:
_, embeddings = net(inputs)
embeddings_list.append(embeddings.squeeze(0).cpu().numpy())
target_list.append(target.item())
embeddings_list = np.asarray(embeddings_list)
target_list = np.asarray(target_list)
print(embeddings_list.shape)
print(target_list.shape)
np.save('embeddings.npy', embeddings_list)
np.save('target.npy', target_list)
if __name__ == '__main__':
checkpoint = torch.load('./checkpoint/' + model.__name__ + '_best.pth.tar',
map_location=torch.device('cpu'))
net.load_state_dict(checkpoint['net'])
test()
(2)从文件中提取embeddings和对应的target信息,进行t-SNE可视化:
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
embeddings = np.load('embeddings.npy')
target = np.load('target.npy')
X_tsne = TSNE(learning_rate=200.0, perplexity=50).fit_transform(embeddings)
X_pca = PCA().fit_transform(embeddings)
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=target)
plt.title('t-SNE')
plt.xticks([])
plt.yticks([])
plt.subplot(122)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=target)
plt.title('PCA')
plt.xticks([])
plt.yticks([])
plt.show()
可以每一个类指定不同的颜色:
embeddings = np.load('baseline_embeddings.npy')
target = np.load('baseline_target.npy')
target_value = list(set(target))
color_dict = {}
colors = ['black', 'red', 'yellow', 'green', 'orange', 'blue', 'magenta', 'slategray', 'cyan', 'aquamarine']
for i, t in enumerate(target_value):
color_dict[t] = colors[i]
print(color_dict)
X_tsne = TSNE(learning_rate=200.0, perplexity=30).fit_transform(embeddings)
plt.figure(figsize=(10, 5))
for i in range(len(target_value)):
tmp_X = X_tsne[target==target_value[i]]
plt.scatter(tmp_X[:, 0], tmp_X[:, 1], c=color_dict[target_value[i]])
plt.title('t-SNE')
plt.xticks([])
plt.yticks([])
plt.show()


















 3330
3330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









